본 논문에서의 문제제기
- DM, LDM들 백본으로 대부분 CNN으로 구성된 U-Net을 사용함
- 그러나 저자들은 U-Net의 inductive-bias가 DM의 성능 향상에 필수적인 요소가 아니라고 주장함.
- inductive bias: 모델이 학습하고 일반화하는 방식에 영향을 미치는 모든 종류의 가정이나 제약.
- 저자들은, ViT default 세팅으로 기존의 DM, LDM들의 성능을 넘을 수 있다고 함.
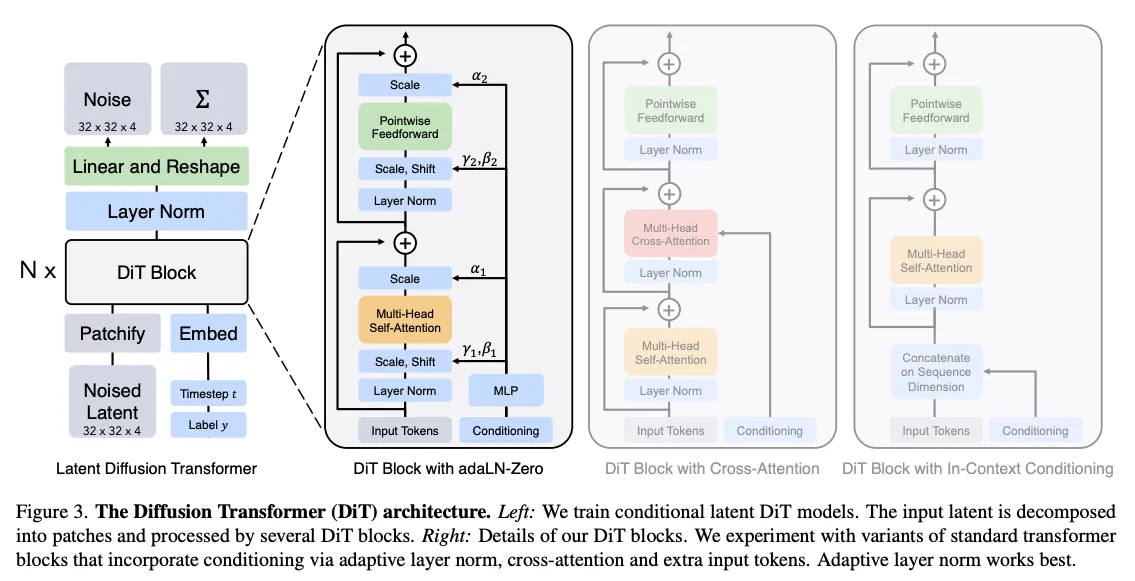
DiT Architecture
- Patchify Layer
- VAE로 인코딩된 latent를 패치 크기(p)로 뜯어 tokenizing 하는 부분
- p는 hyper-param. ( 이 연구에서는 p=2, 4, 8 로 실험)
- p가 작아질수록 token sequence 길이 증가→ Gflops 증가 (Scalability 시사.)
- DiT Block
- Figure 3.에 나오는 것과 같이 4가지 Block을 구성하여 실험함
- In-context conditioning:
- time embedding과 condition을 임베딩한 벡터 tokenize하여 latent input sequence에 추가
- 표준 ViT 를 수정 없이 그대로 사용가능.
- 모델 Gflops가 증가하나 무시할 수 있는 수준.
- Cross-attention block:
- t, c를 이어서 길이 2짜리 토큰 시퀀스로 만들고 latent sequence에 cross attention 시킴
- 실험한 4개 종류의 구조 중 가장 Gflops를 크게 증가시킴 (약 15%의 오버헤드)
- 근데 성능은 별로임 (FID가 높아짐)
- Adaptive layer norm (adaLN) block:
- Transformer의 LN을 adaptive LN (adaLN)으로 교체
- t와 c의 임베딩 벡터 합으로부터 Scale, Shift를 위한 parameter (γ, β) regression
- 본래는 그냥 learnable param이며 input token으로 학습됨.
- 세 가지 구조 중 가장 적은 Gflops가 증가하는 구조임.
- adaLN-Zero block:
- adaLN 변형. 각 res block 직전에 scaling용 파라미터 α를 두고 t와 c로 학습되게 함.
- dimension-wise scale factor로써 사용되는 파라미터임.
- α의 초기값을 0 벡터로 두어 전체 DiT 블록이 항등 함수가 되도록 만듦.
- Gflops 증가 수준이 무시할 만함. (adaLN과 비슷)
- Decoder
- img token seq로부터 out noise 예측 및 co-var 예측.
- plain ViT 디코더를 그대로 사용.
- Normalization 후 각 토큰을 공간 입력과 동일한 모양의 텐서로 재배열하는 역할.
- Model Size
- N개의 DiT 블록으로 구성되며 각 블록은 hidden state 크기를 d로 사용.
- N, d의 크기에 따라 모델 사이즈는 DiT-S, DiT-B, DiT-L, DiT-XL 로 분류됨.
- 크기에 따라 Gflops는 0.3 ~118.6 사이의 크기를 보였음.
Experiments
- 크게 7가지 실험에 대해 주목할 필요가 있어보임
- DiT 블록 구조에 따른 성능 비교:
- 크기는 DiT-XL/2 로 고정하여 FID 비교함.
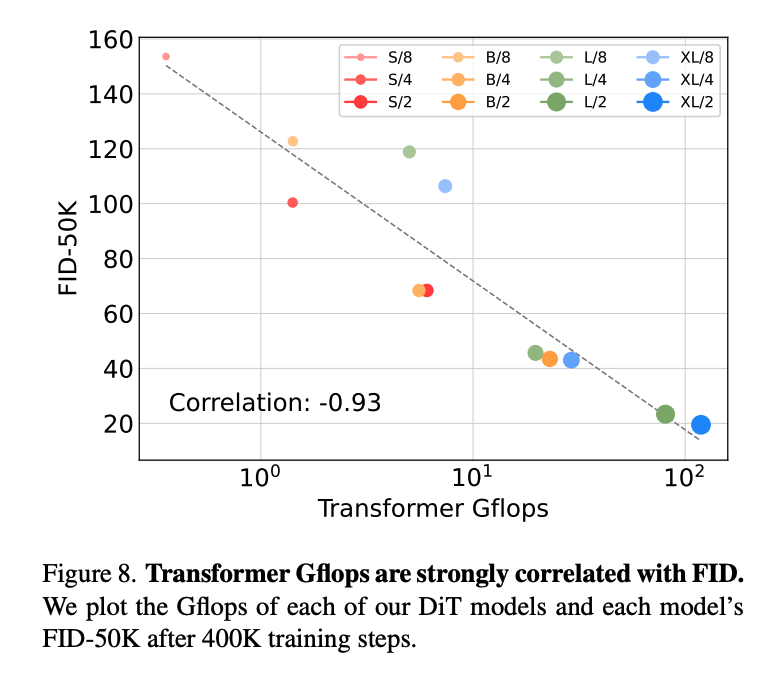
- 결과: 결과: adaLN-zero가 가장 좋았음.
- 주목할 점: 4가지 블록 구조 중 가장 Gflops를 사용하는 구조임
- 따라서 이후의 실험은 모두 adaLN-Zero DiT 블록을 사용.
- Scalability:
- 모델 크기(S, B, L, XL) 및 패치 크기(8, 4, 2)에 따른 Scalability가 있는지에 대한 실험.
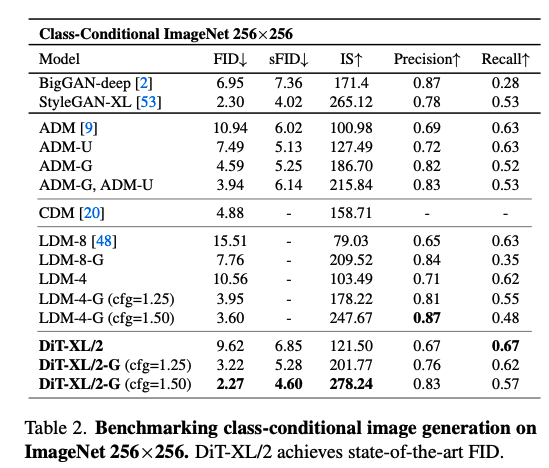
- 결과: 모델 크기가 커질수록, 동시에 패치 크기가 작아질수록 성능향상. (Scalabilty 타당.)
- 모델 크기를 고정했을 때에도 비슷한 결과를 보임
- Patch size를 줄이면(총 토큰 수 증가)
→ # of Param 은 거의 같은 수준이나 Gflops는 증가.
- 즉, Gflops 증가와 성능향상의 연관성을 확인할 수 있음.
- 모델 Gflops와 FID-50K의 반비례 관계도 확인가능 (sFID, Inception score에서도 이런 추세 발견됨)
- DiT 모델크기, Patch Size 별 연산 효율성:
- 같은 학습량 (train step batch model Gflops) 여도 모델 크기가 큰게 더 좋은 성능을 보임.
- Patch size가 작아질수록 더 좋은 성능이 보임 (Gflops는 커지지만)
- 결론적으론 XL/2가 제일 좋았음.
- 모델 연산량 대 Sampling 연산량:
- 가설: Gflops를 높이면 성능이 좋아지니 샘플링을 통해서 Gflops를 더 높이면 성능 좋아지나?
- DiT-L/2로 T=1000 잡고 돌릴 때 80.7Tflops / FID = 23.7
- DiT-XL/2로 T=128 잡고 돌릴 때 15.2 Tflops / FID = 25.9
- 즉 상관관계 없으니 애초에 모델 크게 만드는게 맞음
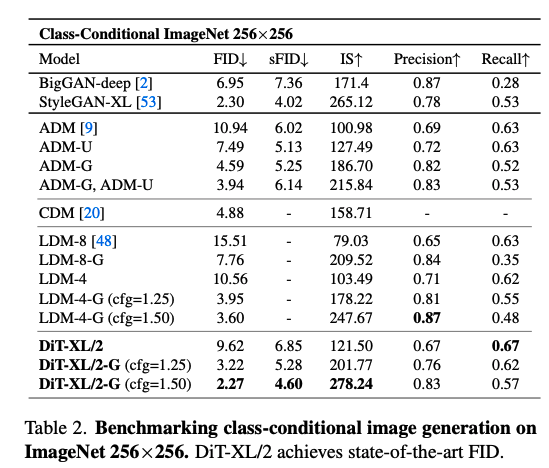
- 최첨단 성능 달성:
- DiT-XL/2를 ImageNet 256x256에 대해 700만 step, 512x512는 300만 step까지 학습.
- DiT-XL/2는 classifier-free guidance 쓰면 SOTA임
![업로드중..]()
- Loss and Scalability
- DiT 모델 Gflops가 커질수록 loss가 더 빠르게 떨어질 뿐만 아니라 더 낮은 곳에서 satu 됨
- LLM에서도 비슷한 현상 관찰됨.
- VAE, 디코더 절제 연구 (Ablation Study):
- VAE는 pretrain 된거 사용함.
- LDM original VAE 디코더 / Stable Diffusion 디코더(ft-MSE 혹은 ft-EMA)를 비교했습니다.
- 성능 좋았다 함.
