논문리뷰
1.[논문 리뷰] Null-text Inversion for Editing Real Images using Guided Diffusion Models
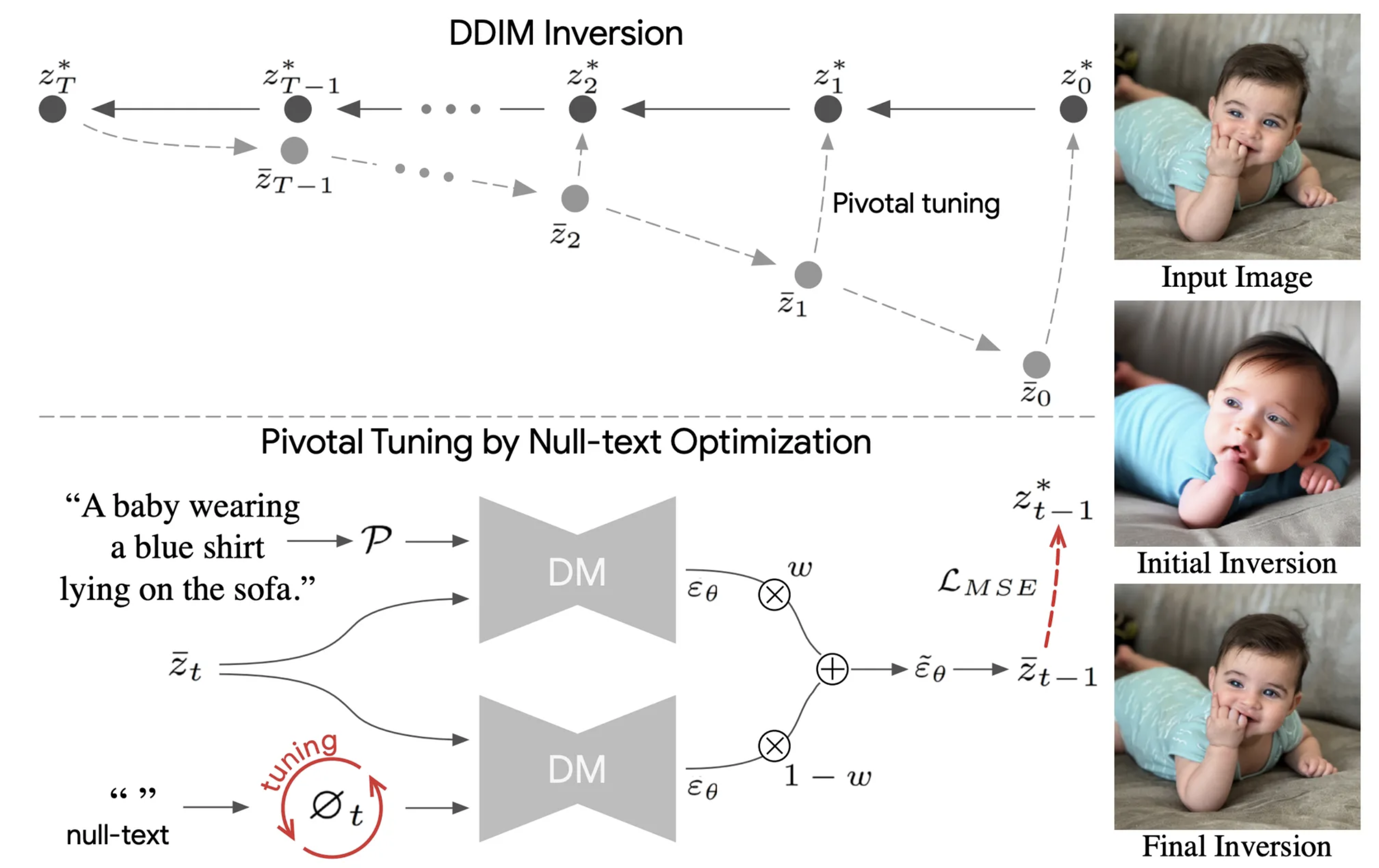
제목: Null-text Inversion for Editing Real Images using Guided Diffusion Models학술지: CVPR 2023저자: Ron Mokady, Amir Hertz et al.연구그룹: Google Research, Te
2.[논문 리뷰] Describe Anything Model
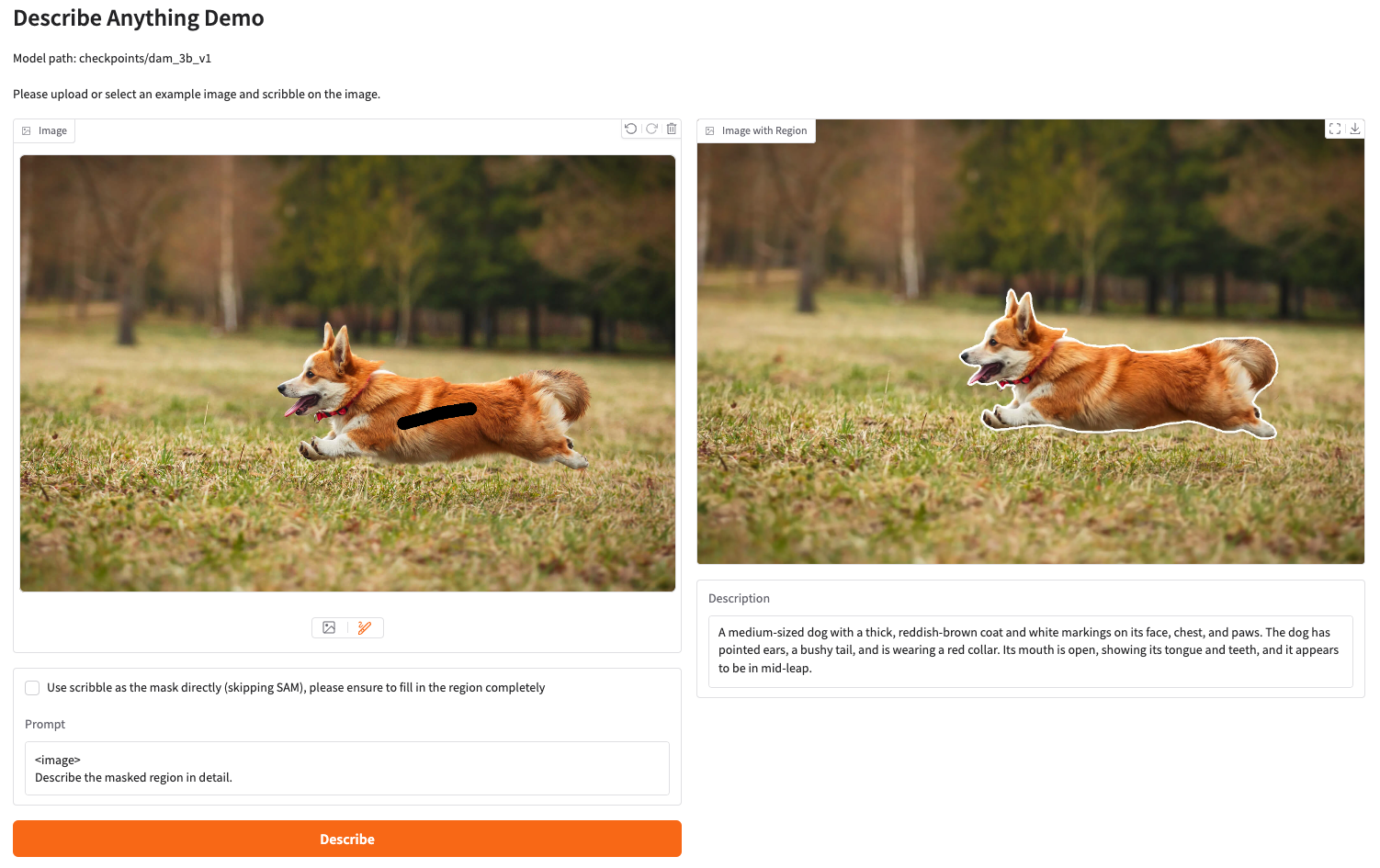
DAM 모델은 DLC 문제를 해결하기 위해 Nvidia에서 제안한 인공지능 모델Code / Paper PDF / Quick Demo User prompt로 지정한 영역에 대해서 Captioning을 수행하는 task.본 논문이 제안됨과 동시에 같이 정의된 task로 보
3.[논문리뷰] Scalable Diffusion Models with Transformers (DiT)
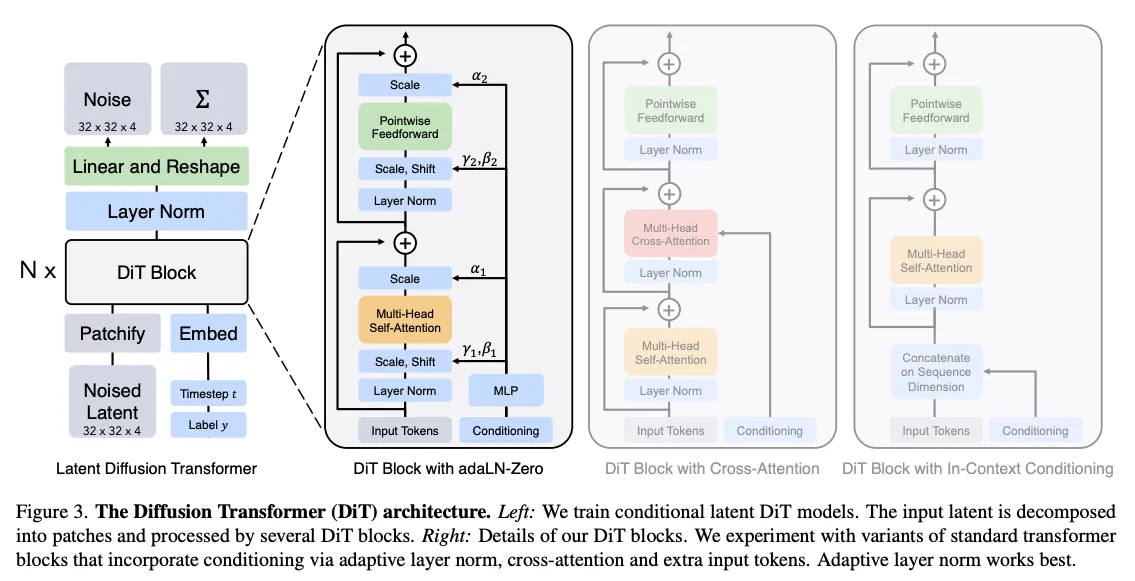
DM, LDM들 백본으로 대부분 CNN으로 구성된 U-Net을 사용함그러나 저자들은 U-Net의 inductive-bias가 DM의 성능 향상에 필수적인 요소가 아니라고 주장함.inductive bias: 모델이 학습하고 일반화하는 방식에 영향을 미치는 모든 종류의 가
4.[논문리뷰] One-Minute Video Generation with Test-Time Training (TTT)

text-2-video(T2V) 도 Diffusion으로 많이 풀림하지만 짧은 동영상만 가능. (그것도 single scene story의 simple context의 동영상만 생성가능함.)Sora (OpenAI): 20초, MovieGen (Meta): 16초,Ray
5.DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing

Drag-based image editing을 해결하고 싶음.선행연구로 DragGAN이 있음.DragGAN의 한계: GAN 의 Capacity에 의해 성능이 제한됨LDM 적용은? → GAN 만큼 정밀한 spatial control을 보여준 사례가 없음대부분의 연구가 t
6.Improving Diffusion Models for Authentic Virtual Try-on in the Wild
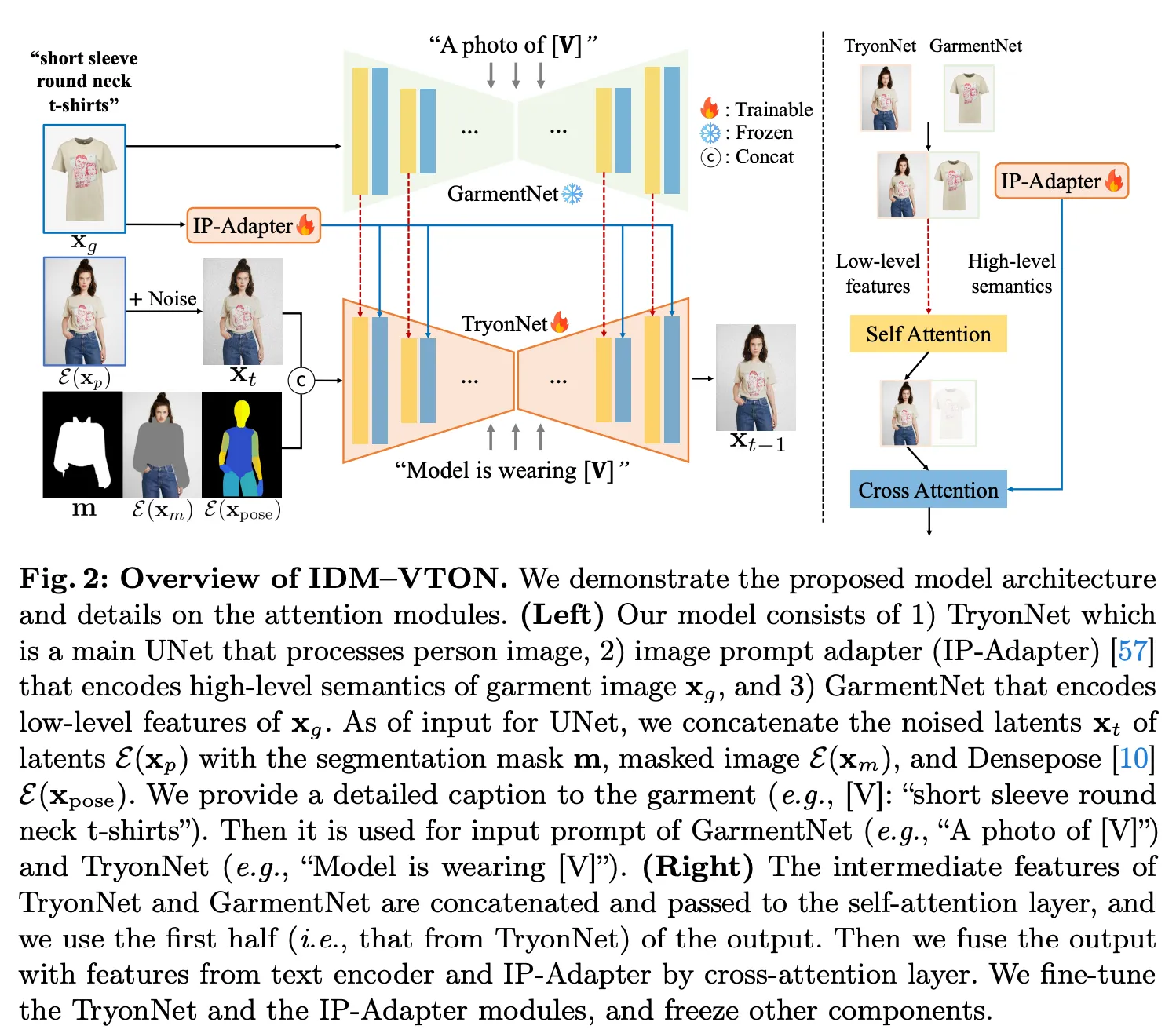
Image-based virtual try on 문제를 diffusion 모델로 해결하고자 함.사람과 의류 영상이 주어지면 사람에게 의류를 입히는 문제.기존 method 4, 9, 23, 28, 31, 35 들의 한계점두 가지로 분류되며 공통적인 문제점은 의류의 ide
7.[논문리뷰] You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
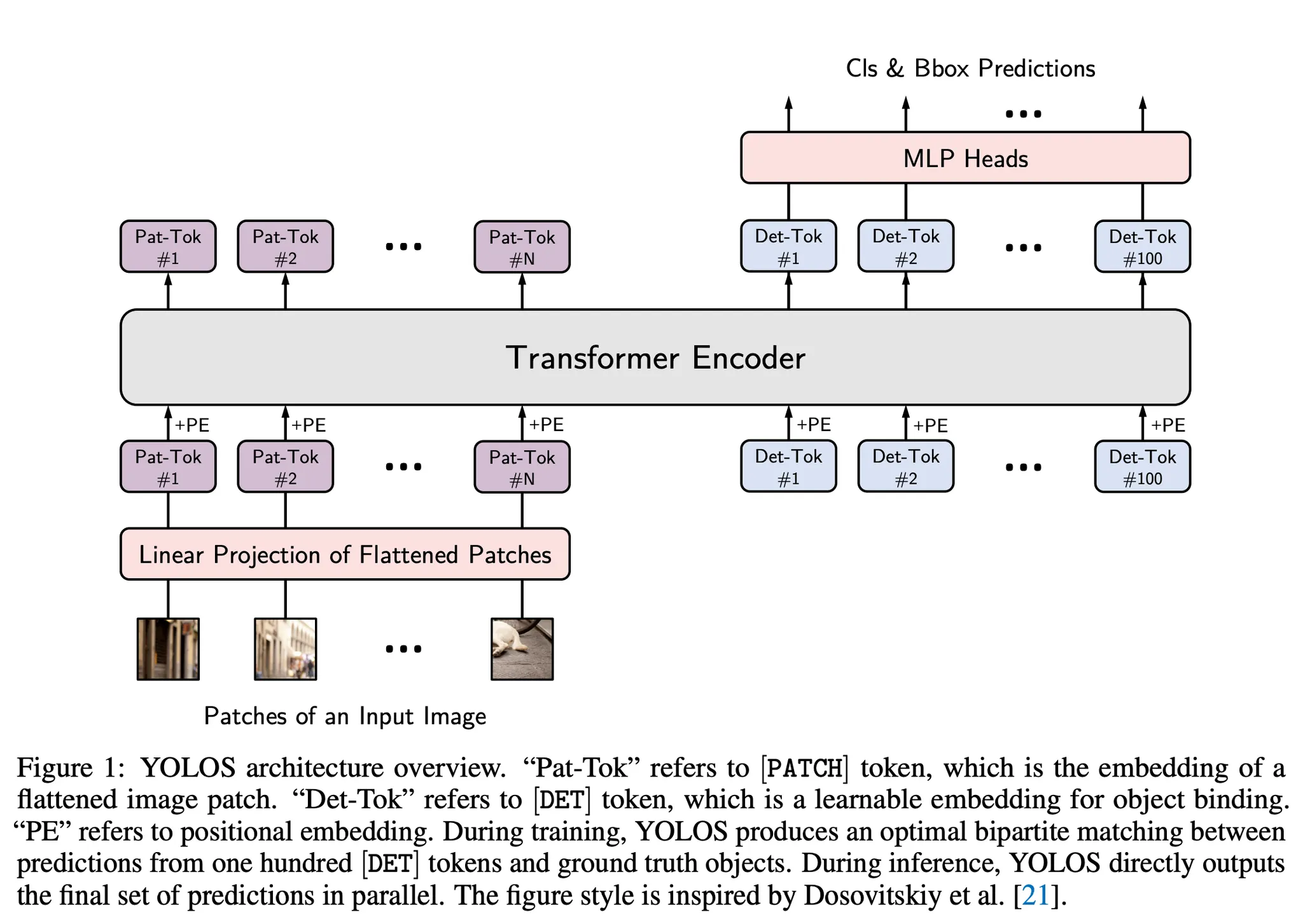
Transformer가 순수한 sequence-to-sequence만으로 2D Detection을 수행할 수 있을까?이에 YOLOS를 고안하여 실험.vanilla Vision Transformer 기반으로 구성한 object detection 모델.target task
8.SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
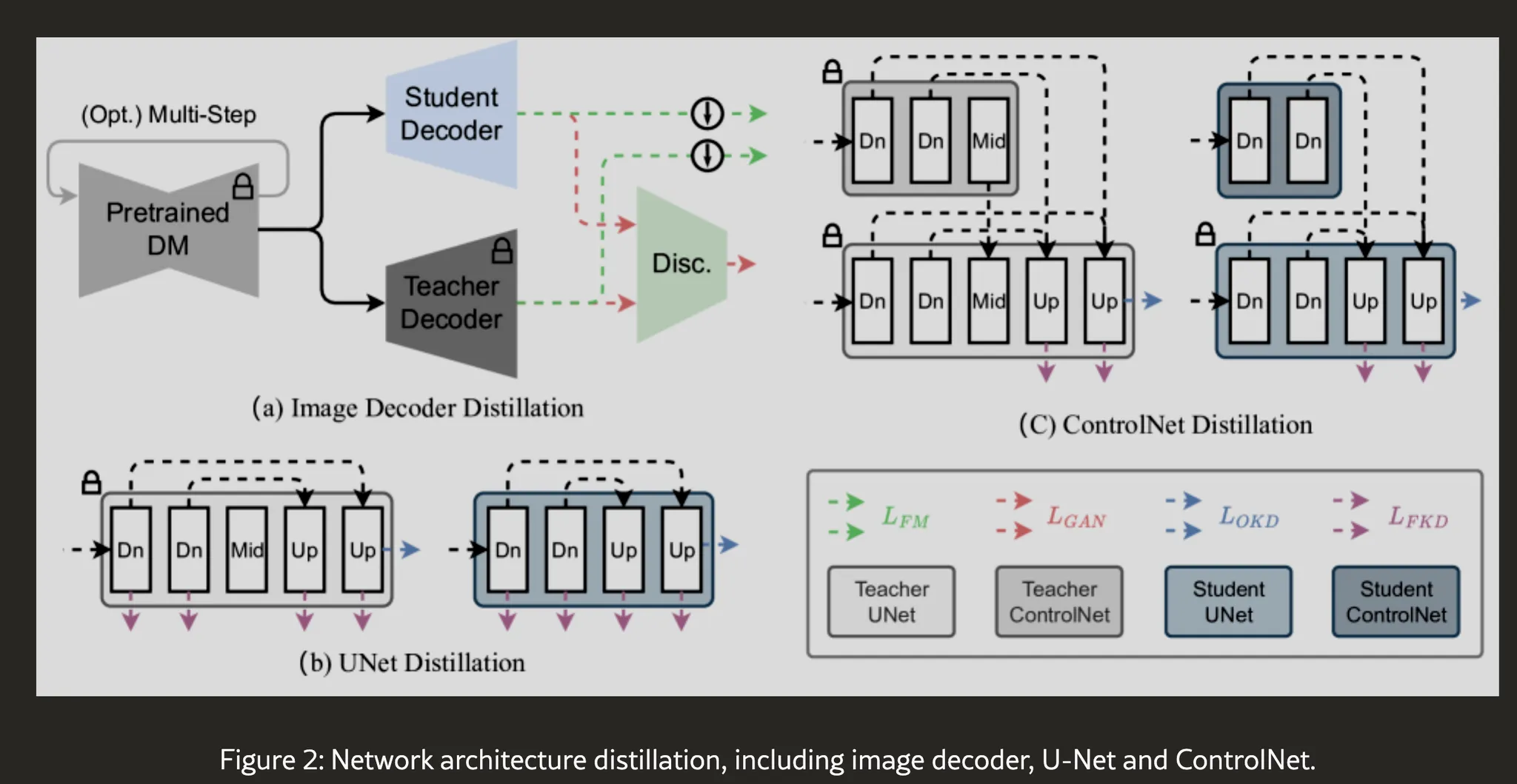
Diffusion 모델은 이미지 generation 분야에서 큰 혁신을 일으켰음.그러나 복잡한 아키텍쳐, 큰 계산량, 반복되는 샘플링 → 느림이를 해결하기 위해 2가지 접근 제안.Model miniaturizationknowledge distillation을 활용한 U
9.IMAGPose: A Unified Conditional Framework for Pose-Guided Person Generation
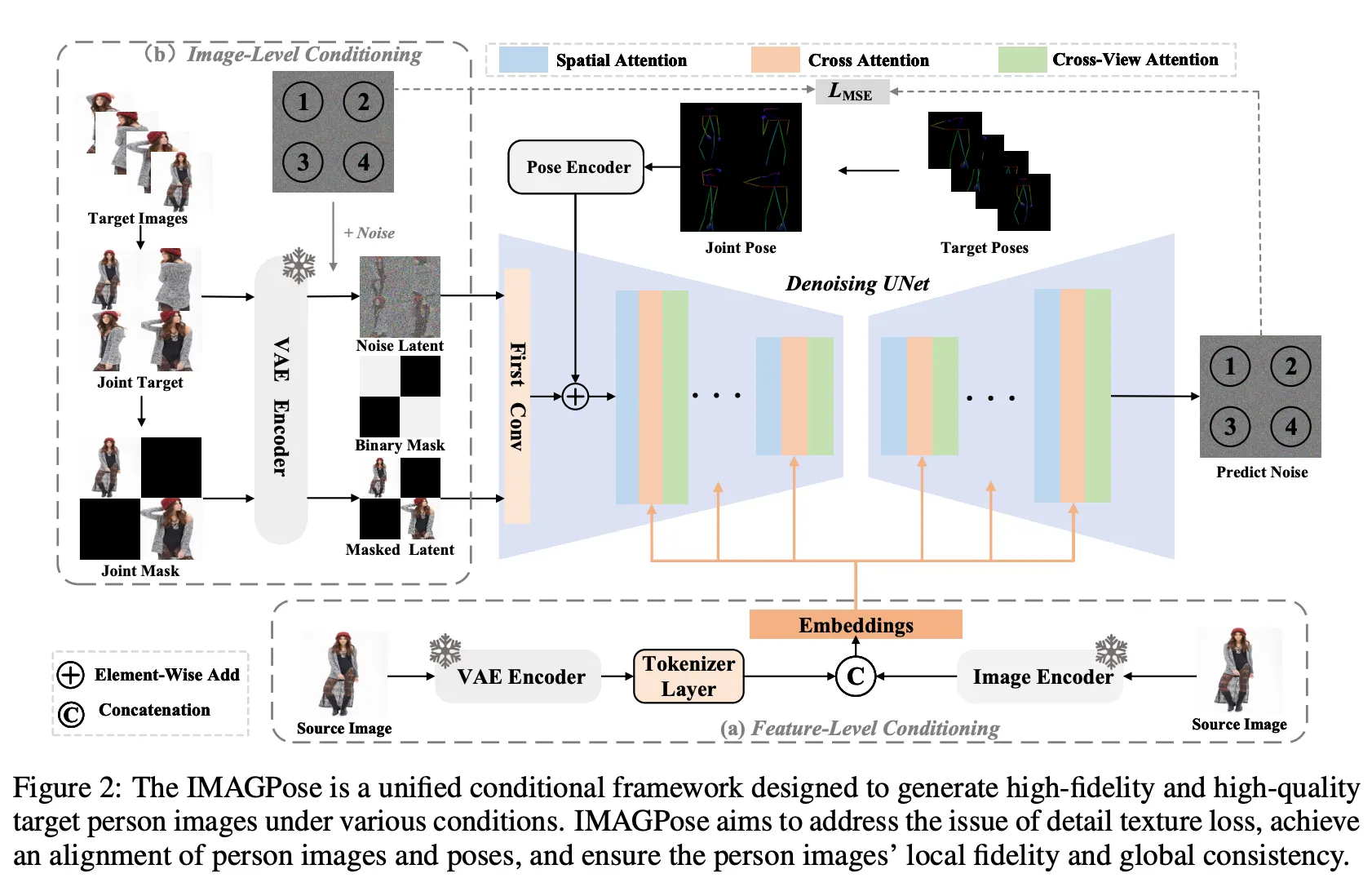
Pose-Guided Person Image Generation에서 기존 방식들의 제한점.generating multiple target images with different poses simultaneouslygenerating target images from m
10.매우 쉬운 직관으로 이해해보는 Rectified Flow
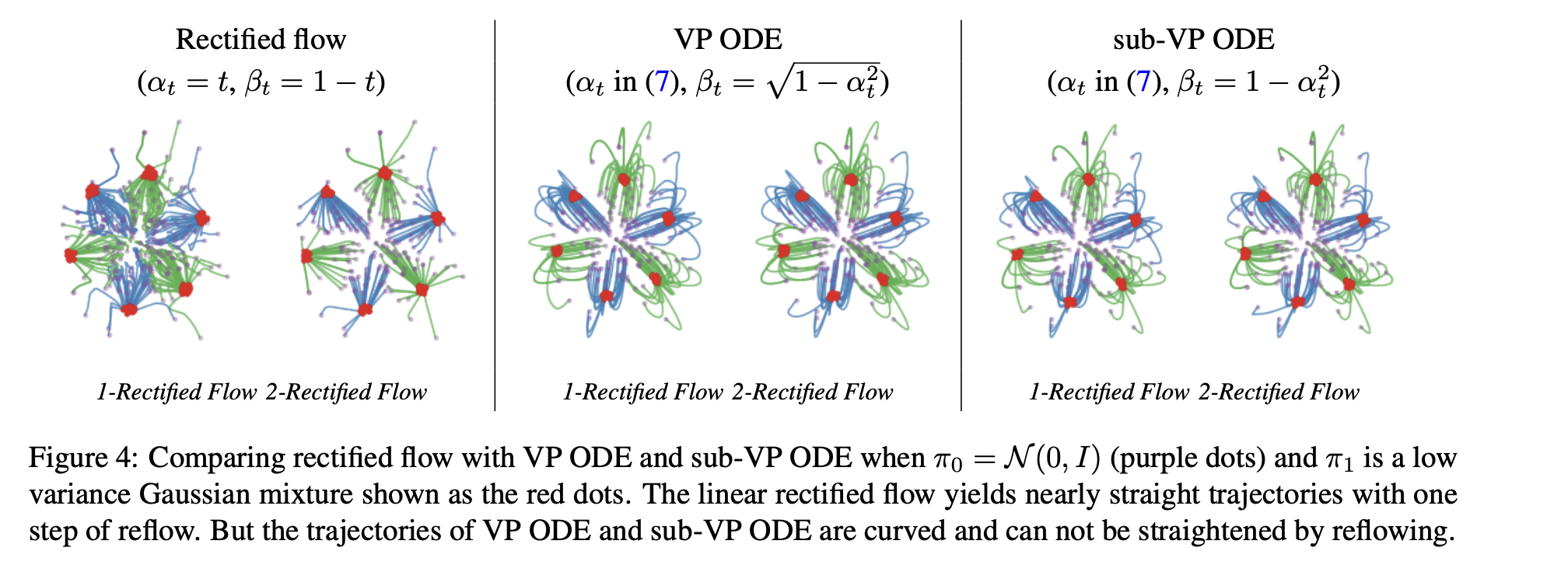
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow Latent Diffusion Model에서 Sampling 가속화를 논할 때 거의 빠지지 않는 논문. 최대한 직관으로
11.논문리뷰 - Masked Autoencoders Are Scalable Vision Learners

masked autoencoders (MAE) → expandible self-supervised learning 방법임.MAE 학습방법: input의 random patch에 대해 masking 후 recon하도록 학습한다.구체적으로 아래와 같은 구조를 제안함.asy