Abstract
- Pose-Guided Person Image Generation에서 기존 방식들의 제한점.
- generating multiple target images with different poses simultaneously
- generating target images from multi-view source images.
- 이를 해결하기 위해 IMAGPose 제안. (unified conditional framework)
- Feature-Level Conditioning (FLC):
- low-level texture feature (from VAE)
- high-level semantic feature(from image encoder)
- 이 둘을 결합시켜 information missing 문제를 해결. (person image feature extractor 부재)
- Image-Level Conditioning (ILC):
- n개 쌍의 이미지와 포즈 간의 alignment를 얻는 모듈.
- n개의 condition을 이미지에 주입. + masking 전략 도입
- Cross-View Attention (CVA):
- global / local Cross attention을 분해하는 기법
- n개의 소스 이미지가 들어와도 결과 영상의 local fidelity and global consistency 를 보장함
- Feature-Level Conditioning (FLC):
Introduction
Pose-guided Person Generation?
- 정의: 소스 이미지의 사람을 특정 포즈로 변환하되, 외관 일관성을 유지하는 기술
- GAN으로 연구되었었으나 고품질 이미지 생성이 어렵고 GAN자체의 학습이 너무 어려움.
- 이에 Diffusion으로 트렌드가 바뀜
- condition 넣기 더 용이하고 in/out consistency가 더 좋아짐
- PIDM: 소스 이미지의 특징을 UNet의 여러 단계에 삽입
- PoCoLD: 3D Densepose 정보 추가, appearance 특징과 상호작용
- PCDMs: 3단계 diffusion (전역 특징 예측 → 조잡한 이미지 생성 → 텍스처 세밀화)
- 그러나 여전히 문제인 점
- 텍스처 디테일 정보 손실 (CLIP 같은 general image encoder는 low-level texture 추출불가.)
- 다양한 유저 인풋 (multi source, multi condition 지원이 안됨)
- condition 넣기 더 용이하고 in/out consistency가 더 좋아짐
IMAGPose의 제안
- unified conditional Framework를 만들어 해결하겠음
- Feature Level Conditioning
- VAE 인코더 → 저수준 텍스처 특징을 추출하여 보강
- Image 인코더 → 고수준 의미 특징을 그대로 사용
- Image Level Conditioning
- 모든 타겟 이미지를 joint target으로 결합 후 random masking (user scenario에 맞게)
- src에서 포즈 추출 → target 포즈와 결합 → joint pose
- Cross View Attention
- Local & Global Cross-Attention을 분해하여 여러 src가 들어와도 consistency를 높임
Methods
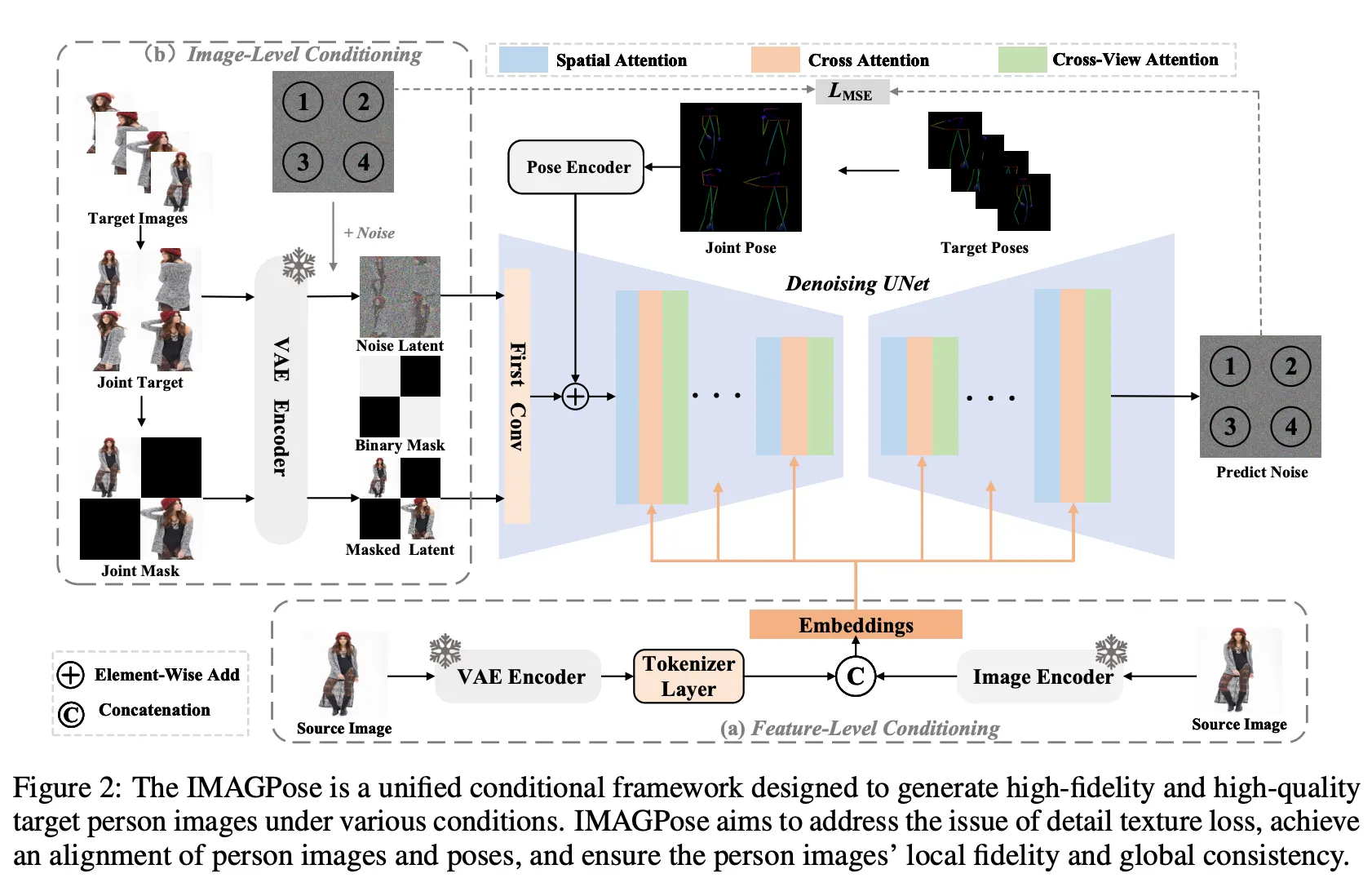
3.1 Preliminaries (기초 개념)
Diffusion 과정:
- 고정된 Markov chain을 통해 데이터에 Gaussian noise를 순차적으로 추가
Denoising 과정:
- Gaussian noise에서 시작하여 샘플 생성
- 학습된 모델이 제거할 noise량을 예측.
학습 목표 (Training Objective)
Loss:
Noise 정의:
Sampling
Classifier-Free Guidance 사용:
모듈 1: FLC (Feature-Level Conditioning)
문제:
- 전용 person image feature extractor 부재로 인한 텍스처 디테일 손실.
- CLIP 과 같은 image encdoer들은 General 한 용도이므로 상대적으로 low-level feature 추출에 불리.
해결책:
- Image encoder는 high level을, VAE encoder는 low level feature를 추출하게 하여 결합시킴.
- VAE encoder → 이미지 텍스쳐를 인코딩
- Image encoder → 이미지 내 맥락을 인코딩.
모듈 2: ILC (Image-Level Conditioning)
목표:
- 이미지와 condition으로 들어온 포즈의 정렬
- 다양한 사용자 시나리오 적응
순서:
- joint target 생성 (이미지를 width, height 방향으로 concat)
- 랜덤 마스킹을 활용하여 주어진 source 이미지들 중 몇개만 마스킹, VAE에 feeding.
- 이미지가 1개만 들어올 수도 있고, 여러개가 들어올 수 있으므로, 그걸 시뮬하기 위해….
- 이때 joint target의 latent에만 diffusion 모델이 예측한 noise를 더하여 다시 diffusion모델로 들어감.
모듈 3: CVA (Cross-View Attention)
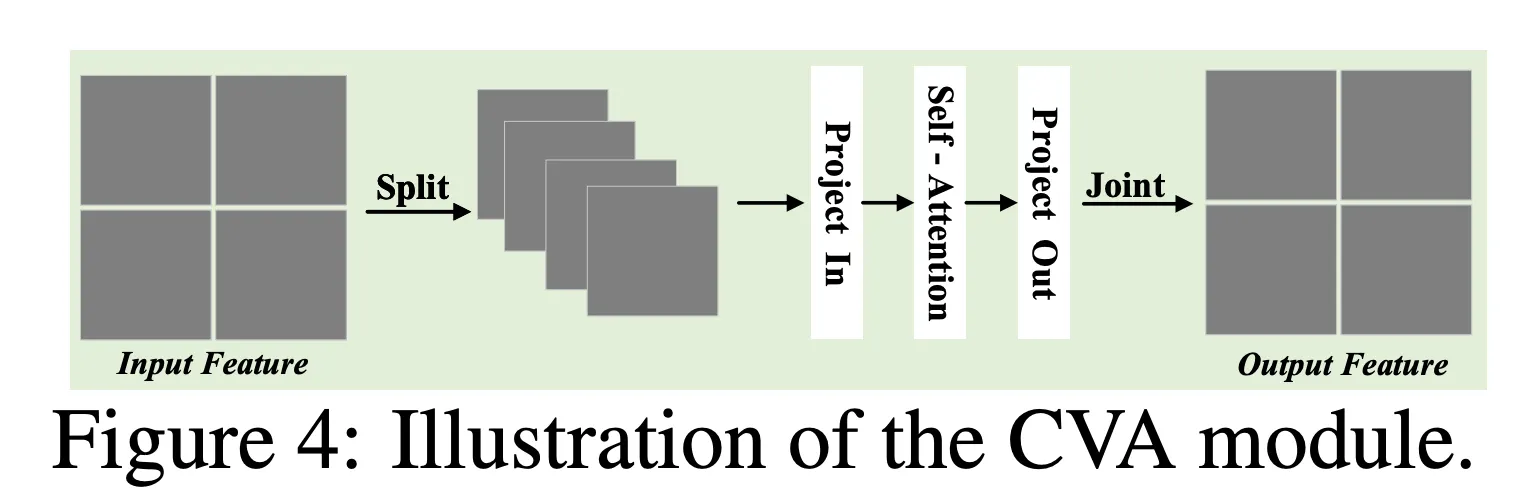
- Cross Attention을 분리하여 Global Cross-attention, Local Cross-attention으로 분해.
- Local fidelity와 Global consistency를 얻기 위함.
- n개로 모여있는 joint target의 noise 상태를 다시 쪼개는 거임…
- 다 모인걸 global, 쪼개놓은걸 Local이라 하는거였음
- 그래놓고 다시 self-attention 적용한 것.
전체 아키텍처 워크플로우
입력 단계:
- 소스 이미지들 → VAE Encoder + Image Encoder
- 타겟 포즈들 → Pose Encoder → Joint Pose
- 타겟 이미지들 → Joint Target + Joint Mask
처리 단계:
[ILC] Image-Level Conditioning
↓ (Masked Latent + Noise)
[Denoising UNet]
├─ [FLC] Feature-Level 특징 주입
└─ [CVA] Cross-View Attention
↓
Predict Noise → MSE Loss
↓
반복적 denoising
↓
최종 타겟 이미지
Contributions
- 최초로 다양한 조건 하에서 pose-guided 이미지 생성 탐구
- FLC 모듈: 텍스처 특징 손실 문제 해결
- ILC 모듈: 가변 개수 소스 이미지 + 마스킹 전략
- CVA 모듈: 다중 뷰에서 지역/전역 일관성 보장
- 통합 프레임워크: 하나의 모델로 모든 시나리오 처리
- 2개 도전적 데이터셋에서 기존 모델 능가
- 사용자 연구 및 downstream 작업 적용 검증
