Abstract
- Diffusion 모델은 이미지 generation 분야에서 큰 혁신을 일으켰음.
- 그러나 복잡한 아키텍쳐, 큰 계산량, 반복되는 샘플링 → 느림
- 이를 해결하기 위해 2가지 접근 제안.
- Model miniaturization
- knowledge distillation을 활용한 U-Net과 image decoder 아키텍처 간소화
- 샘플링 단계 줄이기.
- feature matching과 score distillation을 활용한 one-step DM 학습 기법
- Model miniaturization
- SDXS-512 / 1024 2가지 사이즈 제시
- 단일 GPU에서 각각 약 100 FPS (SD v1.5보다 30배 빠름)와 30 FPS (SDXL보다 60배 빠름)
- image-conditioned control에서 유망한 응용을 제공
Introduction
- DM의 Latency를 줄이고 싶어요!
- 기존 DM들이 latency를 줄이기 위해 한 접근법들
기법 설명 참고문헌 Pruning 불필요한 파라미터 제거 [15] Distillation 큰 모델 → 작은 모델로 지식 전달 [16, 17] Quantization 파라미터 precision 낮춤 (FP32 → INT8) [18, 19, 20] - 그외 transformer 기반 DM들은 아래와 같은 transformer 특화 최적화 레이어가 도움될 수 있음.
- Flashattention (NeurIPS 2022)
- xformers
- 그외 transformer 기반 DM들은 아래와 같은 transformer 특화 최적화 레이어가 도움될 수 있음.
- text-to-image DM은 보통 Number of Evaluation (샘플링 횟수)으로 latency를 계산함.
- 이러니 저러니 해도 NFE를 줄이는 게 제일 핵심
- NFE reduction 연구
- 1세대:
Progressive Distillation[23, 24, 25]Consistency Distillation[26, 27, 28]
- 2세대:
- Rectified Flow → Sampling trajectory를 직선화하여 최단경로 생성
→ NFEs = 1 까지 달성
- Rectified Flow → Sampling trajectory를 직선화하여 최단경로 생성
- 1세대:
- NFE reduction 연구
- 그러나 모델 크기도 줄이고, NFE도 줄이는게 필요한데 그걸 한 연구가 없음
- 게다가 ControlNet이라던가 LoRA같은 걸 쓴다 치면, 모델의 feature 분포도 달라지고 성능이 더 낮아짐
- 기존 DM들이 latency를 줄이기 위해 한 접근법들
- 그래서 우리는…
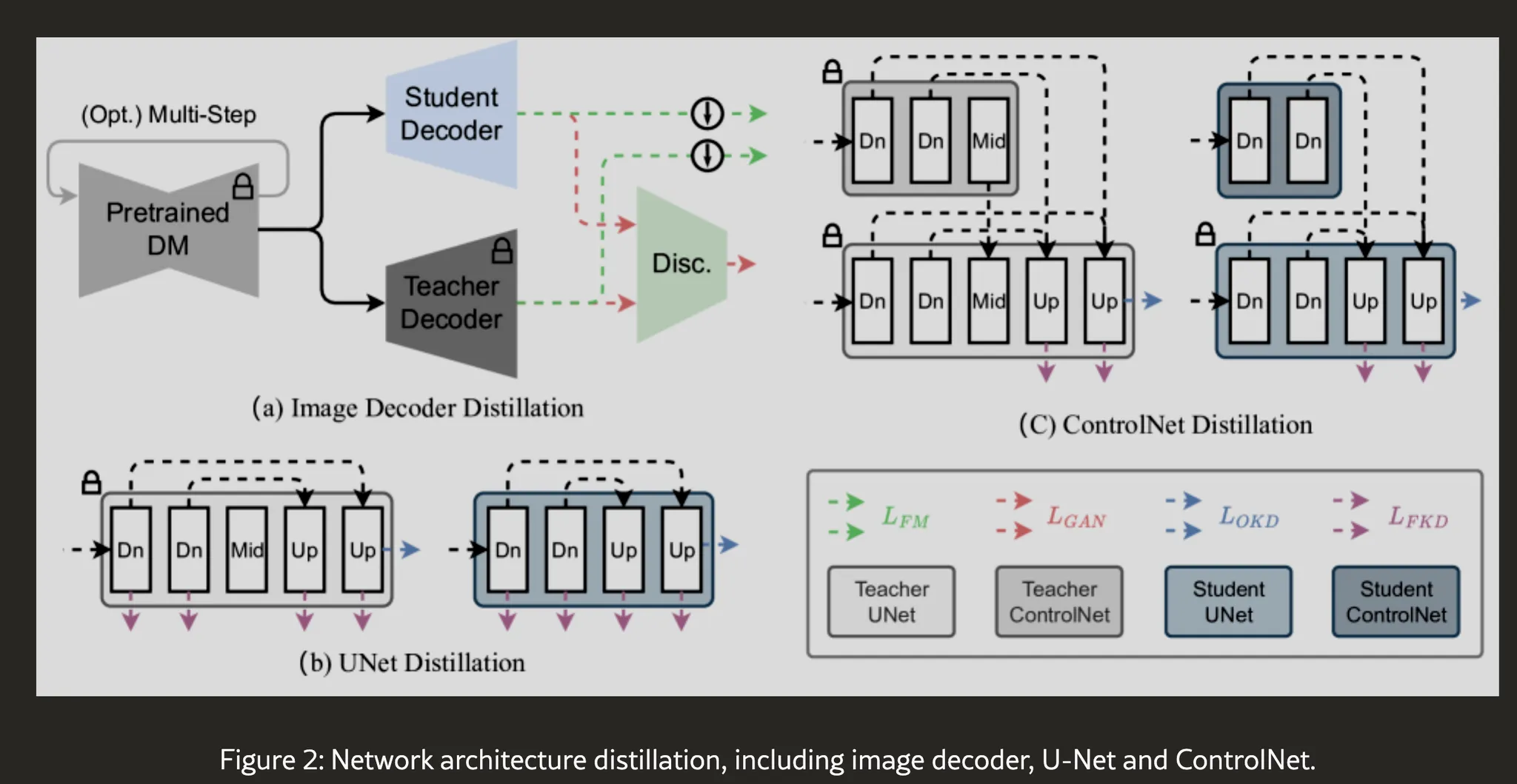
- LDM의 VAE [35] decoder와 U-Net [36]의 크기를 줄임
- output distillation loss와 GAN loss 사용 → 원본 VAE decoder의 출력을 모방
- 대신 극도로 경량된 크기의 decoder를 만들어 학습.
- block removal distillation strategy [16]를 활용.
- 원본 U-Net에서 knowledge distilation + latency를 늘리는 모듈을 제거.
- output distillation loss와 GAN loss 사용 → 원본 VAE decoder의 출력을 모방
- 샘플링 스텝 수 (NFE)를 줄이기 위해,
- sampling trajectory를 직선화 후
- distillation loss function으로 feature matching loss를 사용
- → multi-step 모델을 one-step 모델로 빠르게 finetuning 할 수 있게끔.
- 그런 다음, Diff-Instruct training strategy [37]를 확장하여, timestep의 후반부에서 score distillation이 제공하는 gradient를 제안된 feature matching loss의 gradient로 대체합니다.
- 추가로, ControlNet 적용을 위해
- ControlNet [5]에 대해 block removal distillation strategy를 적용 후
- pretrained ControlNet을 score function에 추가하여 제안된 방법을 Controlnet으로 확장.
- LDM의 VAE [35] decoder와 U-Net [36]의 크기를 줄임
M&M
VAE.
- LDM 프레임워크에서 input을 latent로 보내는 역할
- Loss: reconstruction(재구성), Kullback-Leibler (KL) divergence, GAN loss
- 아래 수식에서 G를 VAE decoder로 이해할 것
-
attention, normalization 레이어는 제거하고 residual block, upsample만 남김
-
8배 다운샘플링한 이미지를 recon하는 것을 학습하도록함
-
U-Net.
- BK-SDM [16]의 block removal training strategy에서 영감을 받은 knowledge distillation 전략 사용.
- U-Net에서 residual block과 Transformer block을 선택적으로 제거
- 원본 모델의 중간 feature map과 출력을 재현할 수 있는 더 작은 모델을 학습시키는 기법.
- 2개의 Knowledge distillation loss 사용
- output knowledge distillation (OKD) loss
-
teacher 모델의 output과 student 모델 output의 L2 loss
-
- feature knowledge distillation (FKD) loss
-
teacher, student 의 각 layer 별 Feature map의 L2 loss
-
- 최종 loss
- 단 원본의 BK-SDM과 달리 denoising loss는 제외함.
- 본 연구에서는 SD2.1 base, SDXL-1.0 base 2개 모델을 사용
- SD-2.1 base
- middle stage, downsampling stage의 마지막 단계, upsampling stage의 1번째 layer 제거
- 가장 높은 resolution stage의 Transformer block을 제거
- SDXL-1.0 base 대부분의 Transformer block을 제거
- SD-2.1 base
- output knowledge distillation (OKD) loss
ControlNet.
- 기존 text-to-image 프레임워크에 spatial guidance를 내장시키는 모듈
- sketch-to-image translation, inpainting, super-resolution 에서 많이 사용.
- U-Net의 encoder 아키텍처와 파라미터를 복사하여 conv layer를 추가하여 spatial guidance를 줌.
- 문제점?
- 기존 파라미터 상속 후 안정성을 위해 zero convolution을 사용함
- 그러나 여전히 학습 비용이 많이 들고 데이터셋 품질에 의해 크게 좌지우지 됨
- 원본의 Controlnet은 당연하게도 distil된 U-Net과 호환 안됨.
- 해결방법
- 원본 U-Net의 ControlNet을 distil 된 U-Net의 ControlNet으로 distillation 하는 것 제안
- ControlNet의 zero convolution 상태로부터 distil 하지 않고,
- ControlNet을 U-Net과 결합한 후 U-Net의 중간 feature map과 최종 output을 distil 함.
- teacher도 똑같이 구해서 L2.
- ContolNet은 U-Net 인코더에 영향 안주므로 decoder에 대해서만 적용.
3.2 One-Step Training
다중 샘플링 문제를 해결하기 위해, one-step만으로 고품질 이미지를 생성하는 train 방법론 제안.
- Feature Matching Warmup
- 기존 ODE 샘플러로 생성한 영상은 노이즈-이미지 대응 관계가 불안정(crossing trajectories) → 학습이 불안정해지고 흐릿한 결과가 나옴.
- 해결방법: 기존 DM에서 생성한 (noise, image) 쌍으로 student model을 warmup
- Rectified Flow 와 같이 경로를 직선화 →ㅜ대신 Feature Matching Loss 를 도입하여 명확한 매칭을 수행함.
- loss 는 DISTS(Differentiable Structural Similarity) 기반 SSIM으로 warmup. → 각 layer의 feature map 간 구조적 유사도를 유지.
- Rectified Flow 와 같이 경로를 직선화 →ㅜ대신 Feature Matching Loss 를 도입하여 명확한 매칭을 수행함.
- 기존 ODE 샘플러로 생성한 영상은 노이즈-이미지 대응 관계가 불안정(crossing trajectories) → 학습이 불안정해지고 흐릿한 결과가 나옴.
- Segmented Score Distillation
- Feature Matching만으론 distribution matching이 완벽히 될 수 없음.
- 이를 보완하기 위해 Diff-Instruct 기법을 개선한 Segmented Score Distillation 제안.
- vanila Score distillation sampling에 text guidance를 추가한 것.
- 시간축 timestep 을 두 구간으로 나눔:
-
[0, αT]: 고주파(high-frequency) 정보를 담는 초기 구간
→ Score Distillation 사용 (teacher가 예측한 noise를 맞추기)
-
(αT, T]: 저주파(low-frequency) 구간
→ **Feature Matching Loss (LFM)** 사용→ α는 1에 가깝게 시작하고 점차 줄임.
-
- 초반에는 score based training, 후반엔 feature based matching으로 안정화.
- LoRA 기반 파인튜닝
- 훈련된 1-step DM에 대해 LoRA를 사용해 스타일 edit이 가능하도록 학습.
- LoRA는 offline DM(teacher) 과 teacher DM 에만 삽입.
- Online DM(student)은 그대로 유지.
- Score Distillation과 Feature Matching을 함께 사용해 LoRA의 효과를 SDXS에 전이(distill)시킴.
- ControlNet 확장
- 기존 ControlNet과 Tiny U-Net을 함께 사용해 image-conditioned 1-step generation 가능.
- Teacher ControlNet은 학습 중 tiny controlnet 학습을 위한 정답 추출기 역할만.
- U-Net decoder에만 feature distillation을 적용.
- 또한 일부 noise를 새로 초기화(re-init)하여 제어 성능을 강화함.
