1. Spring AI + Ollama + RAG 아키텍처
전체 아키텍처
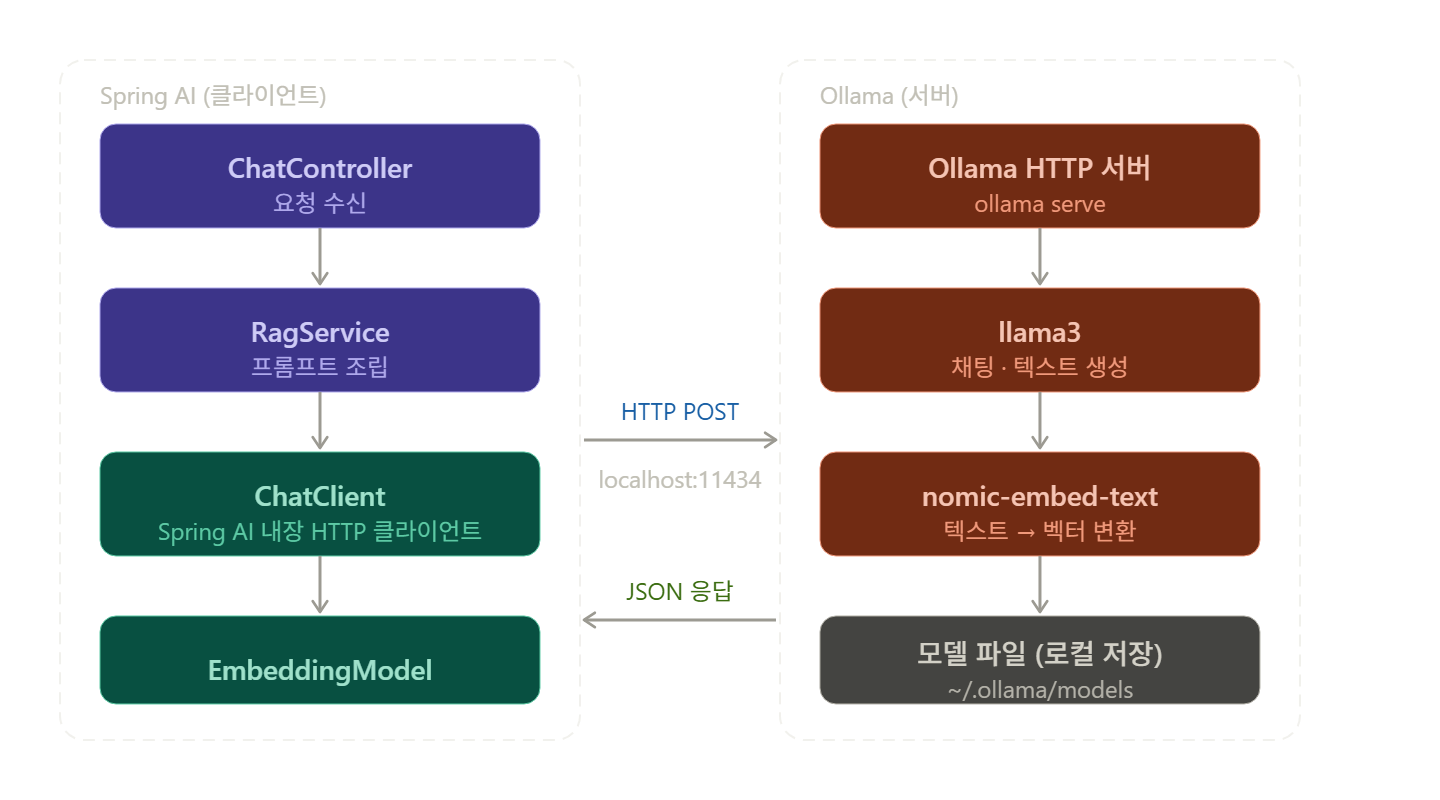
기존의 Spring + Vue 프레임워크에 API로 이식 가능한 형태로 구축하여야 한다.
기존 서비스에서 프롬프트 요청을 POST 요청한 경우 이 요청에 대한 응답 JSON을 반환하도록 한다.
💡 조합 선정의 이유
폐쇄망 운영 + 내부 데이터 활용 + 기존 시스템의 최소 침습
-
Ollama — LLM 서버
선정 이유: 폐쇄망에서 LLM을 돌릴 수 있는 가장 현실적인 방법
자동화창고(WCS)는 보안 요구사항이 높다. 설비 제어 데이터, 입출고 이력, 재고 정보가 외부로 나가면 안 된다. OpenAI나 Claude 같은 외부 API는 질문 내용이 인터넷을 통해 외부 서버로 전송된다. Ollama는 LLM을 완전히 로컬에서 실행하기 때문에 데이터가 서버 밖으로 나가지 않는다.
추가로 설치가 단순하고, ollama pull llama3 한 줄로 모델을 받아 즉시 HTTP 서버로 서비스할 수 있어 운영 부담이 낮다. GPU 없이 CPU만으로도 경량 모델(llama3.2:3b)을 돌릴 수 있어 서버 제약이 있는 환경에도 적합하다.OpenAI API : 인터넷 및 데이터 외부 전송이 필요
vLLM : 고성능 GPU 기반 및 운영 복잡도 High
LM Studio : 개발자 로컬용 (서버 배포 부적합) -
Spring AI — AI 통합 프레임워크
선정 이유: 기존 Spring 생태계와 자연스럽게 통합되는 유일한 선택지
WCS 시스템은 이미 Spring Boot 기반으로 운영 중이다. Python 기반 LangChain이나 LlamaIndex를 도입하면 언어가 달라지고 팀이 Python을 새로 익혀야 하며, 기존 Java 코드베이스와 연동하는 별도 레이어가 생긴다. Spring AI는 Java/Spring 생태계 안에서 LLM 호출, 임베딩, 벡터 검색을 모두 처리할 수 있다.
특히 QuestionAnswerAdvisor 하나로 검색 → Context 주입 → LLM 호출을 자동 처리해줘서 RAG 파이프라인 구현 코드가 극적으로 줄어든다. 팀의 기존 Spring 역량을 그대로 활용할 수 있다는 점도 중요하다.① LangChain or LlamaIndex (Python) : 언어 전환 필요, 기존 Java 시스템과 이질적
② 직접 구현 (RestTemplate)Ollama : API 직접 호출 가능하지만 RAG 파이프라인 전체를 수동 구현해야 함 -
RAG — 검색 증강 생성
선정 이유: WCS 특화 지식을 LLM에게 주입할 수 있는 유일한 구조
일반 LLM은 WCS 시스템의 내부 업무 지식을 모른다. 우리 창고의 입출고 프로세스, 설비 코드, SOP 문서는 모델 학습 데이터에 없다. 이를 해결하는 방법은 크게 두 가지인데, Fine-tuning은 데이터 준비·학습 비용이 크고 문서가 바뀔 때마다 재학습이 필요하다. RAG는 문서를 벡터 DB에 넣어두고 질문 시마다 관련 문서를 검색해서 LLM에 주입하는 방식이라, 문서 추가가 실시간으로 반영되고 구현 비용이 훨씬 낮다.
WCS 환경에서는 문서가 지속적으로 업데이트되기 때문에 RAG가 압도적으로 적합하다.① Fine-tuning : 재학습 비용, 문서 변경 대응 어려움
② Prompt에 직접 삽입 : 문서량이 많으면 토큰 한계 초과, 비효율
③ 키워드 검색만 사용의미 기반 검색 불가, 동의어·문맥 처리 안 됨 -
Chroma DB — 벡터 데이터베이스
선정 이유: 베타 도입 단계에서 가장 빠르게 띄울 수 있는 벡터 DB
벡터 DB는 텍스트를 숫자 벡터로 저장하고 의미적으로 유사한 문서를 찾아주는 역할이다. Chroma는 pip 하나로 설치되고 별도 클라우드 계정 없이 로컬에서 바로 실행된다. Spring AI 1.1.6과 공식 연동이 검증되어 있어 초기 도입 마찰이 가장 낮다.
운영 규모가 커지면 Elasticsearch나 Milvus로 교체하면 되는데, Spring AI의 VectorStore 인터페이스 덕분에 코드 변경 없이 벡터 DB만 교체할 수 있다.① Pinecone : 클라우드 서비스, 폐쇄망 불가
② Milvus : 대규모 운영에 적합하지만 초기 설정 복잡
③ Elasticsearch : 기존 시스템 있으면 좋지만 벡터 검색 설정 추가 필요
④ pgvector : (PostgreSQL)DB가 이미 있다면 좋은 선택, 단 벡터 전용 기능은 ⑤ Chroma보다 제한적
Ollama → 폐쇄망 LLM 실행 (데이터 보안)
Spring AI → Java 생태계 통합 (팀 역량 활용)
RAG → WCS 특화 지식 주입 (도메인 정확도)
Chroma → 빠른 벡터 검색 (베타 도입 속도)
단계별 구현안
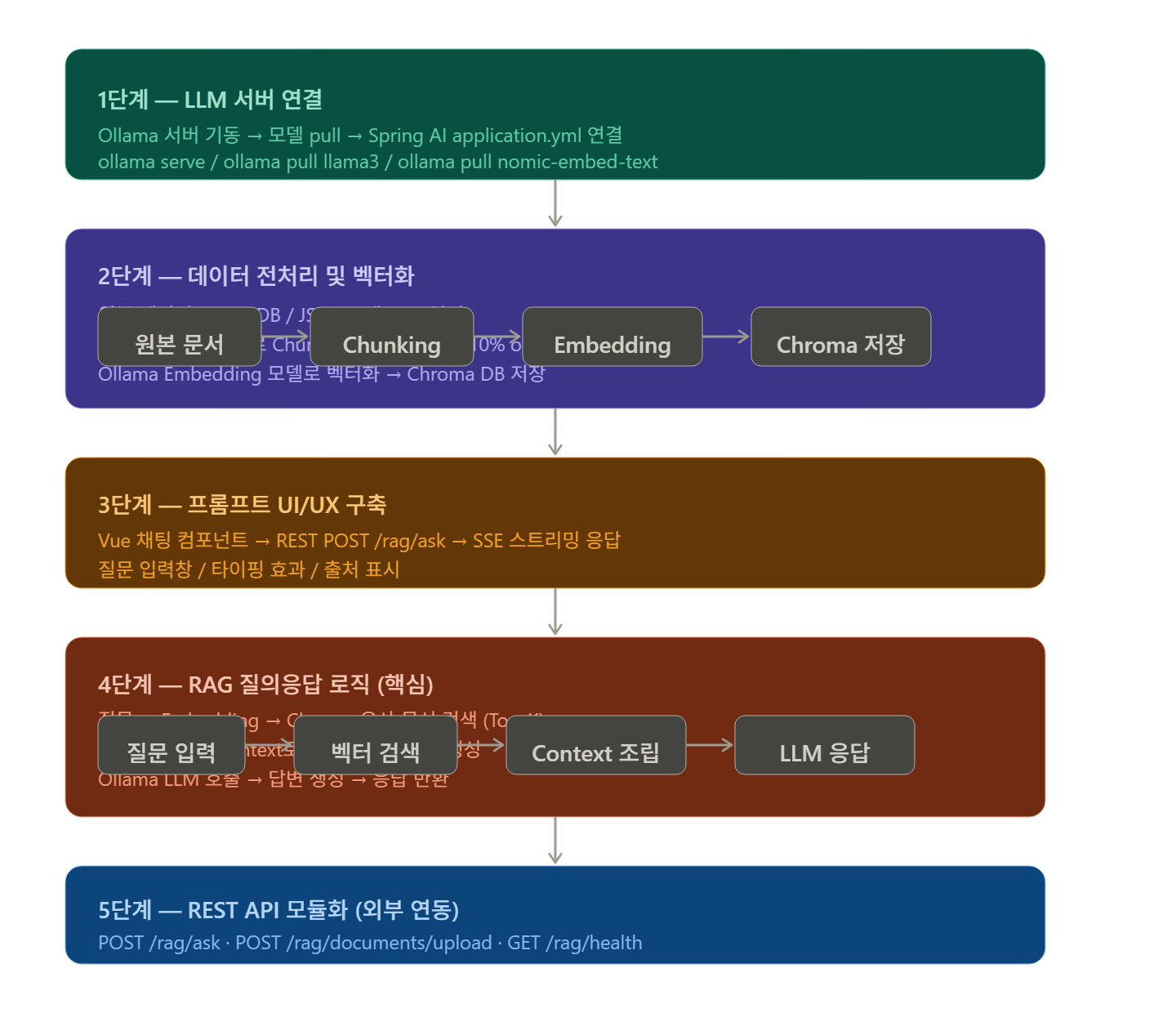
✔️ 대략적인 플로는 다음과 같다. ✔️
[사용자 질문] (IMS 프롬프트)
↓
Spring Boot API
↓
Spring AI
↓
(1) Embedding 생성
↓
Chroma(Vector DB) 검색
↓
관련 문서 조각 반환
↓
Ollama(LLM)에 context 포함 질문
↓
최종 답변 반환
1. Spring AI Project 생성
Rag Service를 구현할 프로젝트를 생성한다.
JAVA VERSION
PS C:\Project\wms-rag-service> java --version
java 21.0.10 2026-01-20 LTS
Java(TM) SE Runtime Environment (build 21.0.10+8-LTS-217)
Java HotSpot(TM) 64-Bit Server VM (build 21.0.10+8-LTS-217, mixed mode, sharing)
Gradle VERSION
PS C:\Project\wms-rag-service> ./gradlew --version
gradle 8.7
Build time: 2024-03-22 15:52:46 UTC
Revision: 650af14d7653aa949fce5e886e685efc9cf97c10
Kotlin: 1.9.22
Groovy: 3.0.17
Ant: Apache Ant(TM) version 1.10.13 compiled on January 4 2023
JVM: 21.0.10 (Oracle Corporation 21.0.10+8-LTS-217)
OS: Windows 10 10.0 amd64
OLLAMA VERSION
PS C:\Project\wms-rag-service> ollama --version
ollama version is 0.23.2
Spring Boot VERSION
id 'org.springframework.boot' version '3.2.5'
“Spring AI는 뭘 쓰고 Chroma가 꼭 필요한가?”
그냥 로컬 LLM 채팅 -> Ollama만
문서 기반 QA/RAG -> Ollama + Chroma + Spring AI
대화 기억 없는 단순 챗봇 -> Chroma 불필요
PDF/매뉴얼 검색형 챗봇 -> Chroma 필요
여러 시도 끝에 현재(26.05.12) 호환 가능한 버전, deprecated 되지 않은 버전의 조합은 다음과 같다.
build.gradle
plugins {
id 'java'
id 'org.springframework.boot' version '3.2.5'
id 'io.spring.dependency-management' version '1.1.4'
}
group = 'com.github.hjyang.rag'
version = '0.0.1-SNAPSHOT'
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
repositories {
mavenCentral()
maven { url 'https://repo.spring.io/milestone' }
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.ai:spring-ai-ollama-spring-boot-starter:1.0.0-M6'
implementation 'org.springframework.ai:spring-ai-chroma-store-spring-boot-starter:1.0.0-M6'
// Lombok
compileOnly 'org.projectlombok:lombok:1.18.38'
annotationProcessor 'org.projectlombok:lombok:1.18.38'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}application.yml
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY:dummy-key-for-build-test}
chroma:
client:
host: localhost
port: 80001. Ollama 모델 준비
ollama pull llama3
ollama pull nomic-embed-text
ollama serve
2. Chroma 실행
chroma run --path ./chroma-data --port 8000
3. 빌드
./gradlew build -x test
4. 실행
./gradlew bootRun
5. 테스트
curl -X POST http://localhost:8081/rag/ask \
-H "Content-Type: application/json" \
-d '{"question":"출고 프로세스 알려줘"}'
-
현재의 Spring AI(1.0.0-M6)는 내부적으로 무조건 http://localhost:8000/api/v1/... 경로를 호출하도록 코딩되어 있습니다.
-
현재 chromadb는 /api/v1 -> /api/v2로 전환
-
이 둘간의 불일치로 Connection Refused 발생@
라이브러리 버전 파편화의 문제..
파이썬 패키지 충돌이 발생한다...
★ 2026.05 기준 추천 조합 재정리
Spring AI , chromaDB 의 안정적인 조합을 찾아보도록 한다.
구성요소 버전
Spring Boot3.4.0
Spring AI1.1.6 (stable)
Java21
Chroma최신 (pip 재설치)
Ollama현재 설치된 버전 유지
PS C:\Project\wms-rag-service> Invoke-RestMethod -Method POST -Uri "http://localhost:8000/api/v2/tenants" `
-ContentType "application/json" `
-Body '{"name":"SpringAiTenant"}'
PS C:\Project\wms-rag-service> Invoke-RestMethod -Method POST -Uri "http://localhost:8000/api/v2/tenants/SpringAiTenant/databases" `
-ContentType "application/json" `
-Body '{"name":"SpringAiDatabase"}'
PS C:\Project\wms-rag-service> Invoke-RestMethod -Method POST -Uri "http://localhost:8000/api/v2/tenants/SpringAiTenant/databases/SpringAiDatabase/collections" `
-ContentType "application/json" `
-Body '{"name":"wms-rag"}'
id : 669647c3-1fae-423c-a517-6dd77ec63f7a
name : wms-rag
configuration_json : @{hnsw=; spann=; embedding_function=}
schema : @{defaults=; keys=}
metadata :
dimension :
tenant : SpringAiTenant
database : SpringAiDatabase
log_position : 0
version : 0
2. ChromaDB 와 MsSQL 연동
MsSQL 소스 데이터(텍스트, JSON, 메타 데이터 etc) 를 벡터화하여 RAG 을 위한 ChromaDB에 저장하는 과정이 필요하다.
2-1) ChromaDB 라이브러리 설치
📍 build.gradle
/* ChromaDB Vector Store 의존성 추가 */
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
// ❗ Spring AI 1.1.6 stable
implementation 'org.springframework.ai:spring-ai-starter-model-ollama'
// ❗ Chroma Vector Store
implementation 'org.springframework.ai:spring-ai-starter-vector-store-chroma'
// ❗ MSSQL JDBC Driver
implementation 'com.microsoft.sqlserver:mssql-jdbc:12.6.3.jre11'
// ❗ JPA
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// Lombok
compileOnly 'org.projectlombok:lombok:1.18.38'
annotationProcessor 'org.projectlombok:lombok:1.18.38'
// Java 21 + ClosedChannelException 해결
implementation 'com.squareup.okhttp3:okhttp:4.12.0'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}2-2) ChromaDB 서버 실행
✔️ Docker 도입 ✔️
ChromaDB는 원래 Python 기반이라:
(Docker 안 쓰면 Python 설치,pip 설치,dependency 충돌버전 관리이슈가 생김)
즉, ChromaDB 실행 환경으로서 도입하고자 한다.
- 추후 배포시에도 로컬 EXE든 도커 컨테이너 이미지든 전체 구조는 변화 ❌
📍 docker 설치 확인
PS C:\Project\wms-rag-service> docker --version
Docker version 29.4.2, build 055a478📍 Chroma 실행
docker run -d --name chromadb -p 8000:8000 chromadb/chroma
(도커에 띄운 ChromaDB)
2-3) MsSQL 연결 설정
📍 application.yml
연결할 데이터베이스 접속 정보를 등록
spring:
datasource:
url: [HOST]:[PORT];databaseName=[DBNAME];encrypt=true;trustServerCertificate=true;loginTimeout=30
username: **[USERID]**
password: **[PASSWORD]**
driver-class-name: com.microsoft.sqlserver.jdbc.SQLServerDriver
hikari:
maximum-pool-size: 10
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
(Spring 서버 실행 결과)
2-4) Spring Boot 서버 기동 및 Spring AI 연동
PS C:\Project\wms-rag-service> curl http://localhost:8081/rag/ping
StatusCode : 200
StatusDescription :
Content : 안녕하세요! 나의 이름은 [AI]이며, 인공지능 기술을
사용하여 사람들과 대화하는 AI입니다. tôi의 목적은
사람들을 도와주고, 정보를 제공하는 것입니다.
RawContent : HTTP/1.1 200
Content-Length: 202
Content-Type: text/plain;charset=UTF-8
Date: Wed, 13 May 2026 04:09:46 GMT
안녕하세요! 나의 이름은 [AI]이며, 인공지능 기술을
사용하여 사람들과 대화하는 AI입니다. tôi의 목적은
사람들을 도와주고, 정보를 제공하는 것입니...
Forms : {}
Headers : {[Content-Length, 202], [Content-Type, text/plain;
charset=UTF-8], [Date, Wed, 13 May 2026 04:09:46 G
MT]}
Images : {}
InputFields : {}
Links : {}
ParsedHtml : mshtml.HTMLDocumentClass
RawContentLength : 202✅ Spring Boot :8081 — 기동 완료
✅ Chroma DB :8000 — Docker 컨테이너 실행 중
✅ Ollama :11434 — llama3 응답 확인
✅ Spring AI 연동 — ChatClient → Ollama 호출 성공
1. Ollama — LLM 서버 :11434
# 서버 실행
ollama serve
# 모델 확인 (새 터미널에서)
ollama list
# 모델 없으면 pull
ollama pull llama3
ollama pull nomic-embed-text
# 실행 확인
curl http://localhost:11434/api/tags2. Chroma DB — 벡터 DB :8000
# 최초 1회 — 컨테이너 생성 및 실행
docker run -d `
--name chromadb `
-p 8000:8000 `
-v C:\Project\wms-rag-service\chroma-data:/chroma/chroma `
chromadb/chroma
# 이후 재시작할 때
docker start chromadb
# 종료
docker stop chromadb
# 실행 확인
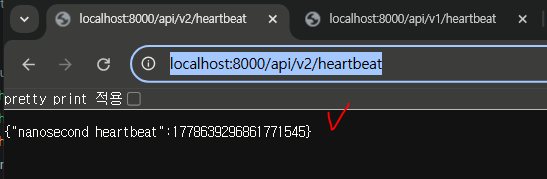
curl http://localhost:8000/api/v2/heartbeat3. Spring Boot — RAG 서비스 :8081
# 프로젝트 디렉토리에서
cd C:\Project\wms-rag-service
# 실행 (개발 중)
./gradlew bootRun
# 또는 jar 빌드 후 실행 (운영용)
./gradlew clean build -x test
java -jar build/libs/wms-rag-service-0.0.1-SNAPSHOT.jar
# 실행 확인
curl http://localhost:8081/rag/ping📍 실행 여부 확인
# 세 개 다 살아있는지 한 번에 체크
Write-Host "=== Ollama ===" -ForegroundColor Cyan
curl http://localhost:11434/api/tags 2>$null | Select-Object -First 1
Write-Host "=== Chroma ===" -ForegroundColor Cyan
Invoke-RestMethod http://localhost:8000/api/v2/heartbeat
Write-Host "=== Spring Boot ===" -ForegroundColor Cyan
curl http://localhost:8081/rag/ping이제 모든 준비가 되었고, 프로젝트 구성을 시도해보자.
2-4) RAG 연동 테스트
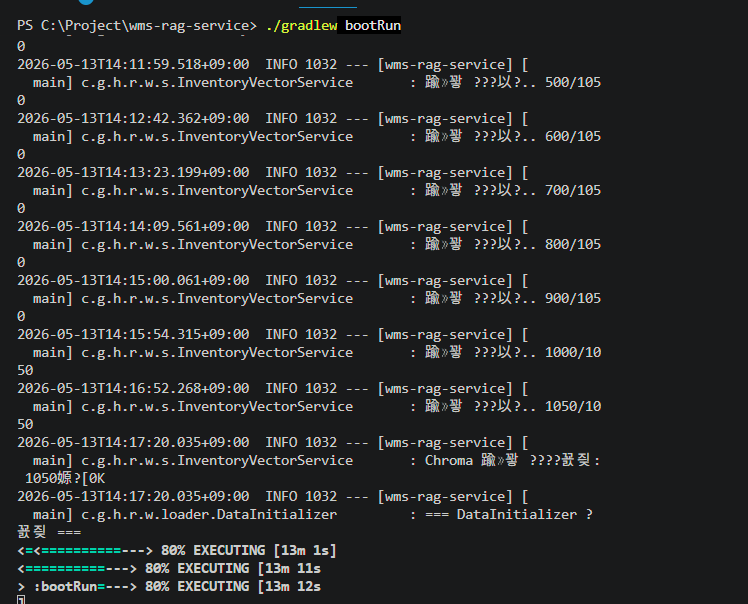
1050 행 데이터를 벡터화하는데 약 8분이 소요된다.
➡ 수천수만 건의 데이터 실시간 처리가 불가능한 수준

질의응답은 당연히 더더 오래걸린다.
➡샘플 테이블 데이터(1000건 가량) 벡터화하는데에 수분 이상 소요된다. 이 작업을 주기적으로 수행하여 동기화하여 임베딩하는 데에는 무리가 있을 듯하다.
❗ 결론 ❗
테이블 데이터는 벡터화 대상이 아니다. 벡터화 대상은 PDF, PPTX 등 한 번 INPUT되면 계속 읽어오지 않아도 되는 데이터 대상이며, 테이블 데이터의 경우 DB 직접 조회 방식으로 수정하도록 한다.
사용자 질문
│
├─ 재고/위치/수량 관련 → DB 직접 조회 (JdbcTemplate)
│
└─ 매뉴얼/규정/FAQ 관련 → Chroma 벡터 검색 (PDF, PPTX 등)
→ 두 결과를 합쳐서 LLM에 주입 → 답변 생성