Introduction
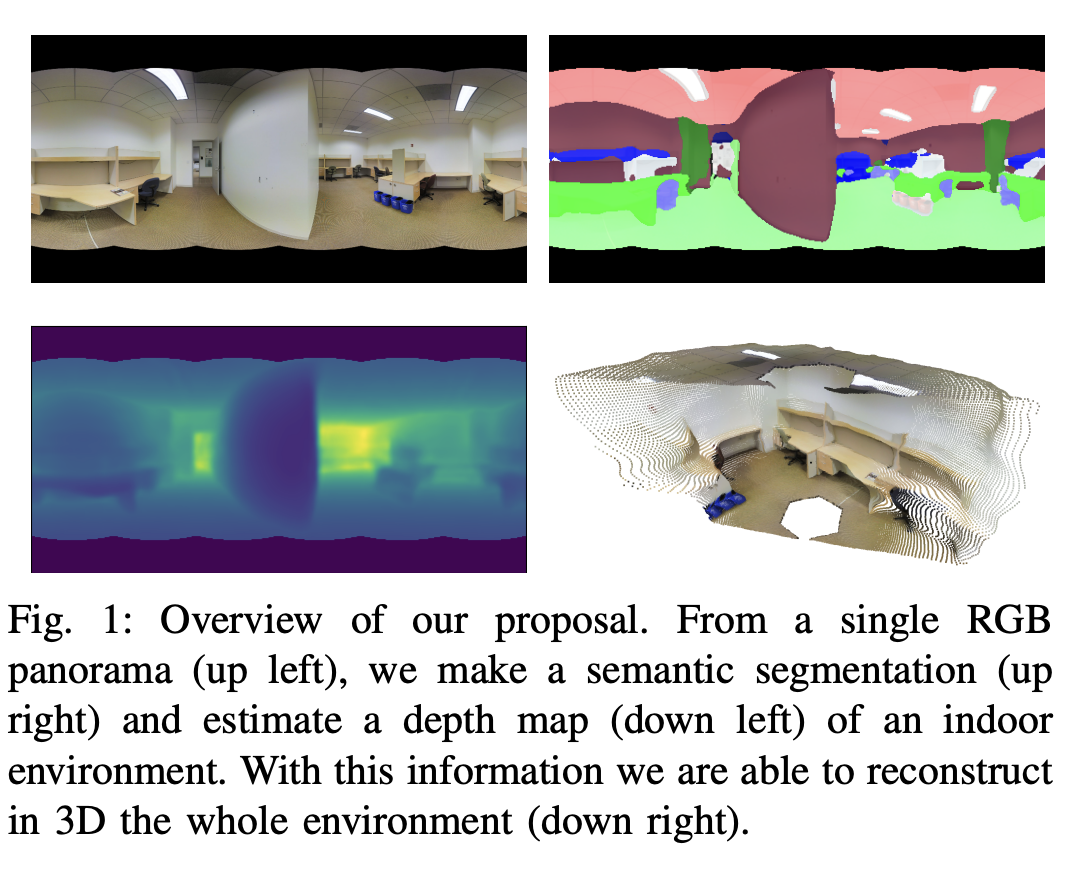
최근 3차원의 공간을 인식하는 분야가 최근 컴퓨터 비전과 로보틱스 분야에서 각광을 받고 있다. 전통적인 카메라로 3차원 공간을 인식하는 방법은 좋은 결과를 보여주었지만, 좁은 범위만을 알 수 밖에 없다는 한계가 존재한다. 따라서 최근 지도 투영 방법 중 하나인 equirectangular projection 방법이 3차원 공간을 인식하는 데 사용되어 지고 있다.
본 논문에서는 이러한 equirectangular projection 방법으로 촬영한 사진을 통해 semantic segmentation과 depth estimation을 진행할 수 있는 딥러닝 모델을 제안하였다. 위의 사진을 보면 알 수 있듯이 파노라마 형태의 이미지를 통해 semantic segmentation map과 depth map을 FreDSNet을 통해 얻을 수 있다.
FreDSNet의 특이한 점은 fast Fourier Convolution(FFC)를 사용하여 receptive field를 더 넓게 만들어 파노라마 이미지를 이해하는 유리하게 작용한다. 또한 segmentation과 depth estimation을 동시에 진행함으로써 각각의 task가 서로 학습을 하는데 도움을 준다.
FreDSNet: monocular depth and semantic segmentation
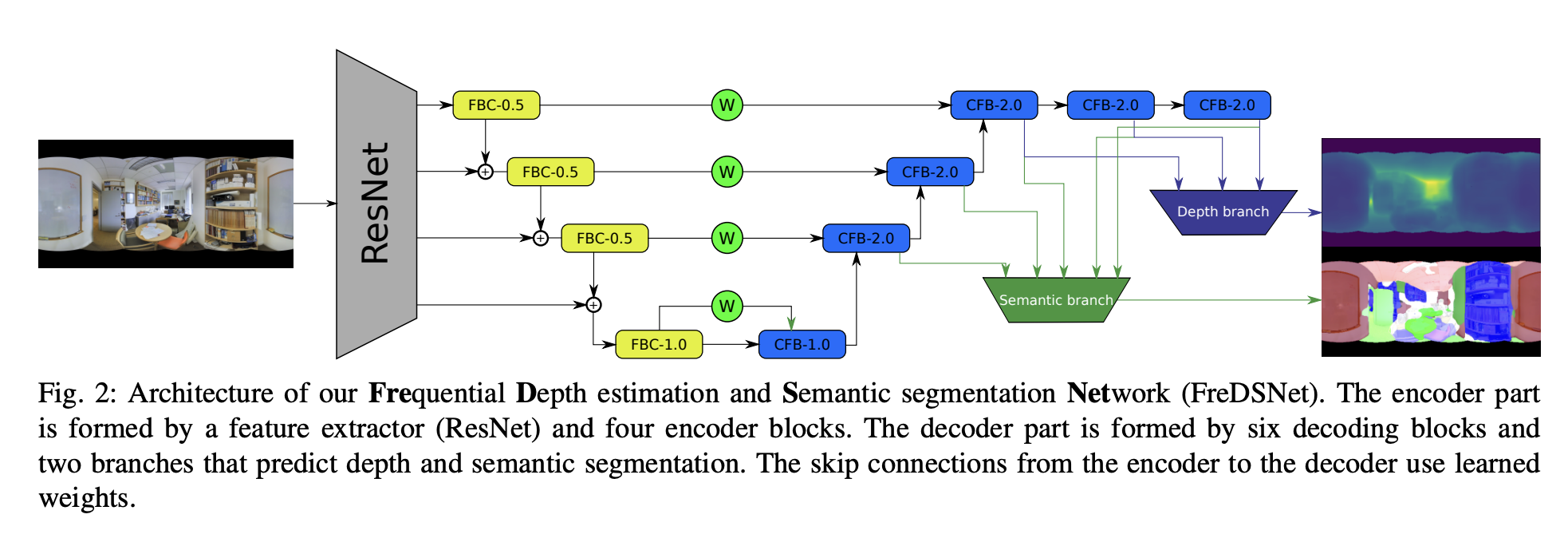
FreDSNet의 구조를 살펴보면 크게 Resnet 기반의 encoder decoder 구조로 나눌 수 있다. 앞서 Introduction에서 설명했듯이, depth와 segmentation map을 얻기 위한 depth branch와 semantic branch이 존재한다. 기존의 논문들과 비슷한 구조를 가졌지만 FresDSNet의 특징은 encoder decoder의 세부 구조들의 연결 구조 이다. 더 자세한 구조를 살펴보자.
Architecture
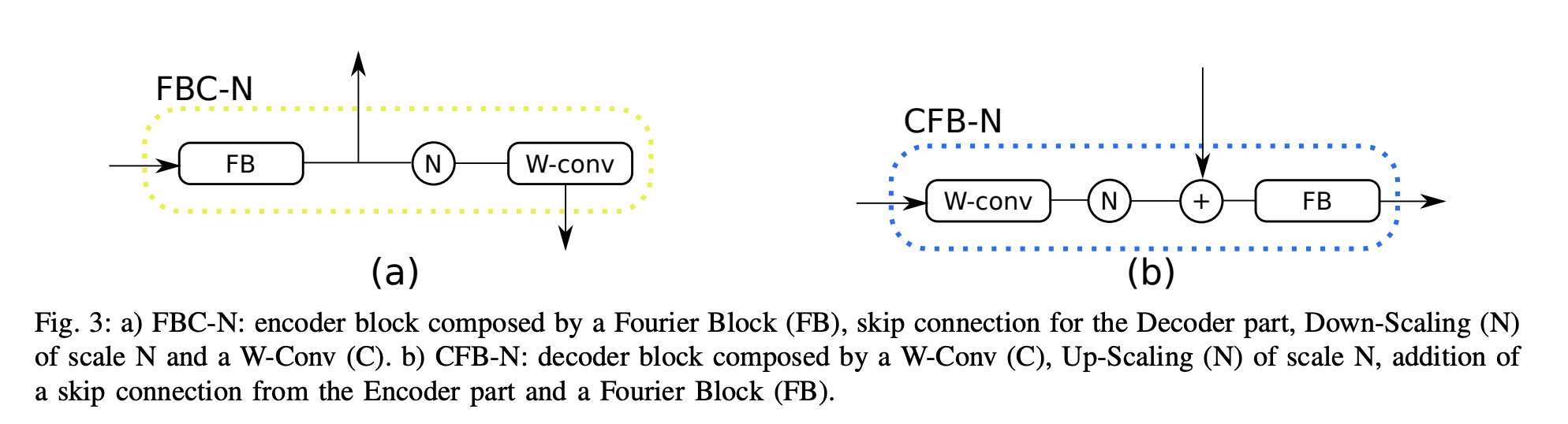
FBC block과 CFB block에서 FB가 뜻하는 건 Fourier Block이다. 또한 N은 nn.Module의 Upsampling의 scale_factor를 뜻하는데, N == 0.5 이라면 down-scaling이고 N == 2이라면 up-scaling이다. W-conv가 의미하는 것은 standard convolution 이다.
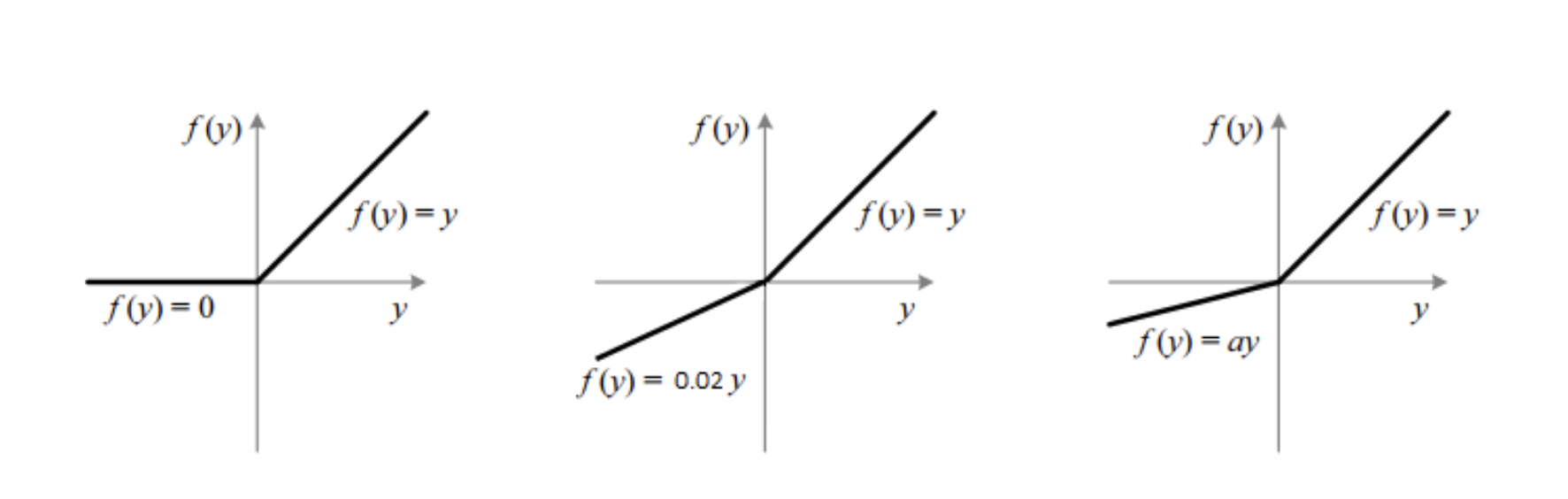
기존의 FB 을 사용할 때 활성화 함수로 ReLU함수를 사용하였지만, 최근 depth estimation을 진행함에 있어서 ReLU함수가 gradient vanishing 문제를 발생시켜 FreDSNet에서는 PReLU함수를 사용하였다. PReLU함수란, Leaky ReLU와 같이 음수인 부분에 대해서도 기울기를 가지지만, 이러한 기울기를 일정한 값으로 정하는 것이 아니라 하나의 파라미터로써 학습을 통해 정해지는 함수이다.
FB 를 통과한 값은 추후 decoder에 skip connection으로 연결되고 FB 를 통과하고 난 뒤, down sampling을 진행하고, w-conv 까지 통과하게 된다. 여기서 특이한 점은 output이 concatenate 되는 것이 아니라, add 된다는 것 이다. Decoder 부분은 Encoder 부분의 정확히 반대과정을 똑같이 거치게 된다.
class Encoder(nn.Module):
def __init__(self,features_depth,latent_depth):
super().__init__()
#Params
self.features_depth = features_depth
self.num_maps = len(features_depth)
self.latent_depth = latent_depth
#Layers
self.FB1 = FourierBlock(1,self.features_depth[0],False)
self.down1 = nn.Upsample(scale_factor=0.5,mode='bilinear',align_corners=False)
self.convB1 = WConv(self.features_depth[0],self.features_depth[1],AF='prelu',BN=True, p=0.4)
self.FB2 = FourierBlock(1,self.features_depth[1],False)
self.down2 = nn.Upsample(scale_factor=0.5,mode='bilinear',align_corners=False)
self.convB2 = WConv(self.features_depth[1],self.features_depth[2],AF='prelu',BN=True, p=0.4)
self.FB3 = FourierBlock(1,self.features_depth[2],False)
self.down3 = nn.Upsample(scale_factor=0.5,mode='bilinear',align_corners=False)
self.convB3 = WConv(self.features_depth[2],self.features_depth[3],AF='prelu',BN=True, p=0.4)
self.FB4 = FourierBlock(1,self.features_depth[3],False)
self.convB4 = WConv(self.features_depth[3],self.latent_depth ,AF='prelu',BN=True, p=0.4)
def forward(self,x):
flow = x[0]
f1 = self.FB1(flow)
# 이런 방식으로 torch.cat을 사용하지 않고, torch.add를 사용하여 서로다른 feature_map을 더한다.
flow = torch.add(self.convB1(self.down1(f1)),x[1])
f2 = self.FB2(flow)
flow = torch.add(self.convB2(self.down2(f2)),x[2])
f3 = self.FB3(flow)
flow = torch.add(self.convB3(self.down3(f3)),x[3])
f4 = self.FB4(flow)
out = self.convB4(f4)
inter_features = [f4,f3,f2,f1]
return out,inter_featuresSemantic segmentation branch
Semantic segmentation 정보는 decoder 마지막 5개의 feature map에서 추출한다. 이 때 5개의 feature map을 단순히 concatenate 하는게 아니라, weighted sum 방식을 통해 합친다. 마지막 conv layer를 통과할 때, 이전에 사용하던 PReLu 활성화 함수가 아닌 ReLU 활성화 함수를 사용하는데 그 이유는 최종적인 output값이 음수가 나오지 않아야 하기 때문이다.
Depth estimation branch
Depth estimation branch도 Semantic segmentation branch와 구조가 동일하지만 마지막 3개의 feature map을 사용한다는 것이 다르다.
class DepthBranch(nn.Module):
def __init__(self,inter_depth,features_depth):
super().__init__()
#Params
self.inter_depth = inter_depth
self.feat_depths = features_depth
self.num_feat_maps = len(self.feat_depths)
#Layers
self.alphas = nn.ParameterList()
self.ScaleMediator = nn.ModuleList()
for i in range(self.num_feat_maps):
self.alphas.append(nn.Parameter(torch.randn(1)))
self.ScaleMediator.append(nn.Sequential(WConv(self.feat_depths[i],self.inter_depth,AF='prelu',BN=True),
nn.UpsamplingBilinear2d(scale_factor=(2**(self.num_feat_maps-i-1)))))
#최종적인 마지막 Conv layer에는 ReLU를 사용하는 것을 확인할 수 있다.
self.outDepthConv = CircConv(self.inter_depth,1,'relu',False)
def forward(self,feat_list):
out = self.ScaleMediator[0](feat_list[0])
for i in range(1,self.num_feat_maps):
out += self.ScaleMediator[i](feat_list[i]) * self.alphas[i]
out = self.outDepthConv(out)
return outLoss function
Depth estimation loss는 기존의 많은 논문들에서 사용하는 loss를 그대로 사용하였다.
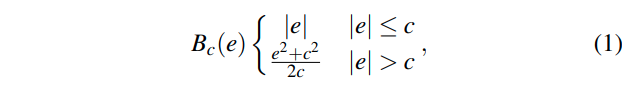
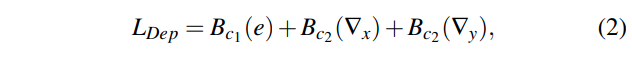
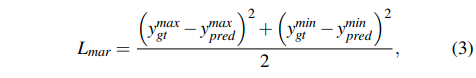
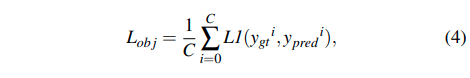
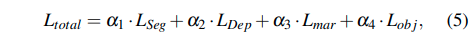
Discussion
장점
- Fast Fourier Convolution(FBC) 코드가 나와 있어 추후 사용하기에 용이하다.
- Depth estimation과 Semantic segmentation을 동시에 진행할 수 있다는 아이디어가 매우 좋은 것 같다.
- 만약 우리가 충분히 많은 데이터셋을 가지고 있다면 vision transformer를 기반으로 한 depth estimation 과 semantic segmentation을 진행하는 모델도 만들어 볼 수 있지 않을까 생각된다.
단점
- 현재 제공되어 있는 코드는 이미 pretrained된 model_path를 이용한 inference만 가능하다. 이때 pretrained된 모델은 파노라마 방 이미지를 이용하여 학습된 걸로, 만약 우리 task에 적용하려고 한다면 따로 학습을 진행해야 한다. 하지만 학습을 진행하는 코드는 제공되어 있지 않아 직접 data를 불러오고 train 시키는 코드를 만들어야 한다.(loss함수도)
- depth estimation과 semantic segmentation 모두를 한번에 제공하는 자율주행 데이터셋이 존재할까 라는 의문이 든다. 데부분 semantic segmentation과 함께 meta data로 라이다, 레이더, gps 등등을 제공하는 것 같은데,,, 해결해야할 과제 중 하낙 될 것 같다.
