Introduction
Retinaface란 singleshot, multi-level face localization을 고안한 방법으로 point regression을 이용하여 face box prediction, 2D facial landmark localization, 3D vertices regression 이렇게 3가지의 task를 통합한 모델이다. 즉 여기서 multi-level 이라는 것은 face box, 2D, 3D를 모두 한번에 처리한다는 뜻이다. 기존의 face localization이라고 한다면 어떠한 위치정보 없이 face bounding box를 찾아내는 것이였다. 하지만 이번 Retinaface에서는 face detection 뿐만 아니라 face pose estimation, face alignment , face segmentation ,3D face reconstruction로 더 광범위하게 재정의 하였다.
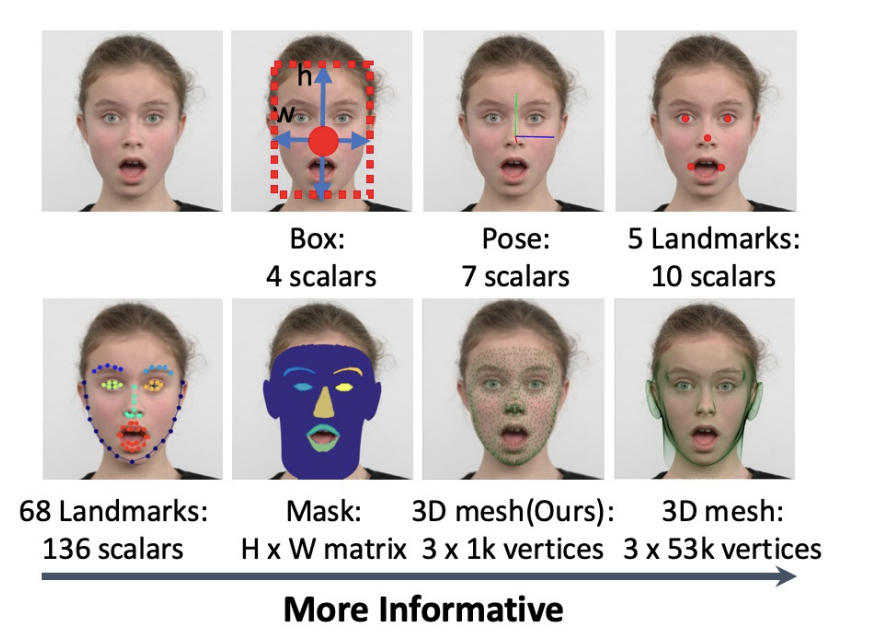
face localisation의 다양한 task들
Proposed Approach
3D Face Reconstruction
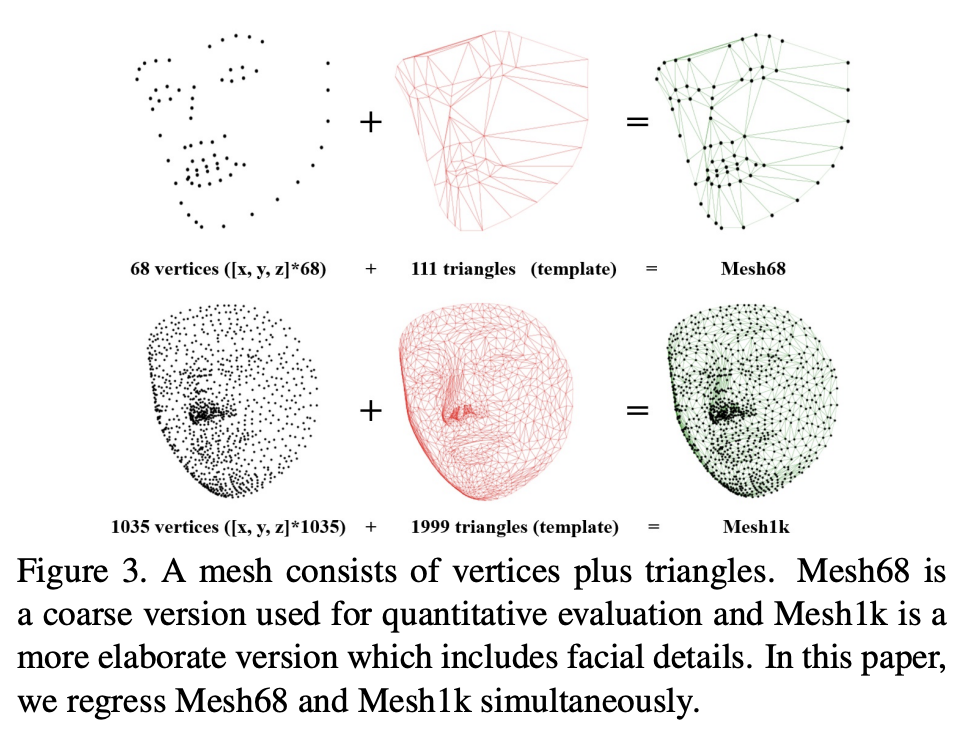
위의 사진은 얼굴을 3d 표면상에서 나타낸 것인데, 68개의 vertices와 1035개의 vertices를 비교하면 당연히 1035개의 점으로 표현한 3d 얼굴이 훨씬 정교하다는 것을 알 수 있다. 즉 vertices가 많을수록 더 정교한 3d 얼굴을 얻을 수 있다는 얘기인데, 만약 최종 output인 vertices가 많아지게 된다면, 당연히 파라미터수도 많아지기 때문에 Retinaface에서는 가장 적절한 1035 + 68 개의 vertices를 사용하였다.
총 1103개의 vertices에 대한 loss function은 다음과과 같이 구현하였다.
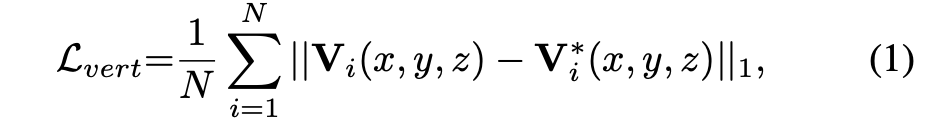
하지만 input 되는 이미지가 2D상의 이미지 이기 때문에 z축, 즉 깊이에 대한 정보가 없다. 따라서 이러한 부분이 3D face reconstrucion에서 어려운 부분인데, Retinaface에서는 이러한 문제를 triangle topology를 사용하여 해결하였다. 즉, triangle topology에 대한 loss function을 설정하여 z축에 대한 정보를 잃지않도록 한 것 이다.
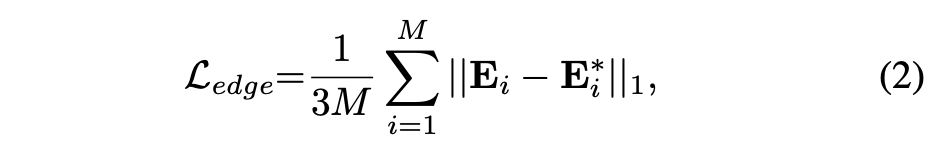
여기서 M은 111개의 triangle과 1999개의 triangle이 합쳐진 2110개 이다. 최종적으로 3D mesh에 대한 loss function은 다음과 같다.
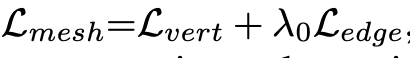
Multi-level Face Localization
Retinaface의 큰 특징이 바로 face box prediction, 2D facial landmark localization, 3D vertices regression 을 한번에 진행한다는 것 이다. 따라서 하나의 anchor i에 대한 최종적인 loss function은 다음과 같다.
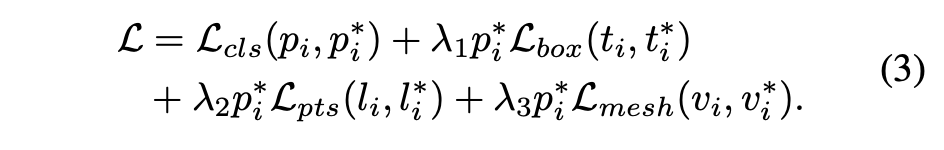
여기서 는 해당 anchor가 얼굴인지 아닌지에 대한 확률을 나타낸다. 1이면 해당 anchor가 얼굴이라는 뜻이고, 0이면 해당 anchor가 얼굴이 아니라는 뜻이다. 는 bounding box, 는 landmark, 는 3D vertices를 뜻한다.
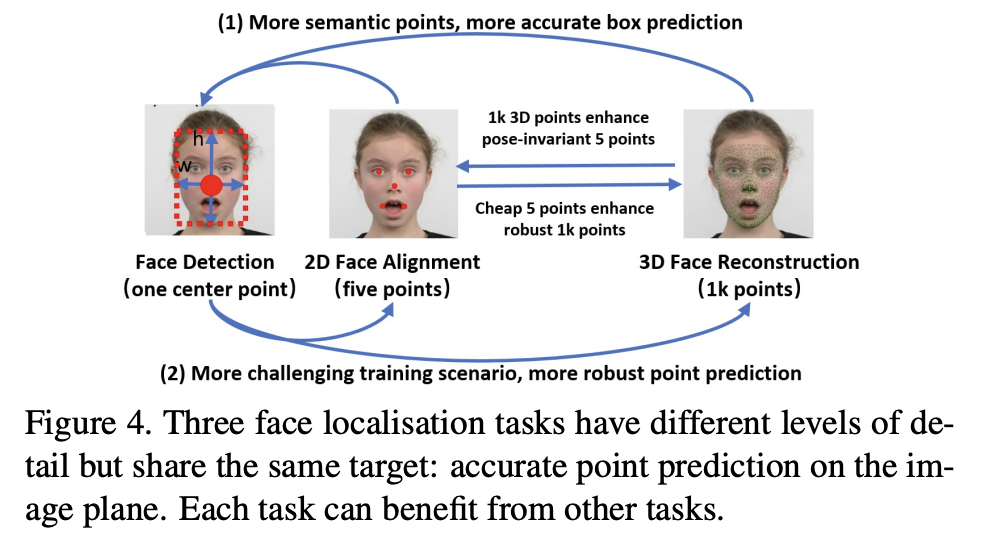
이렇게 설명에 나와있듯, face box prediction, 2D facial landmark localization, 3D vertices regression 이렇게 3가지 task는 하나의 목표 즉 point regression이라는 지향점을 가지고 있기 때문에 학습과정에서 각각의 task들이 서로의 성능을 향상시킨다.
Single-shot Multi-level Face Localization
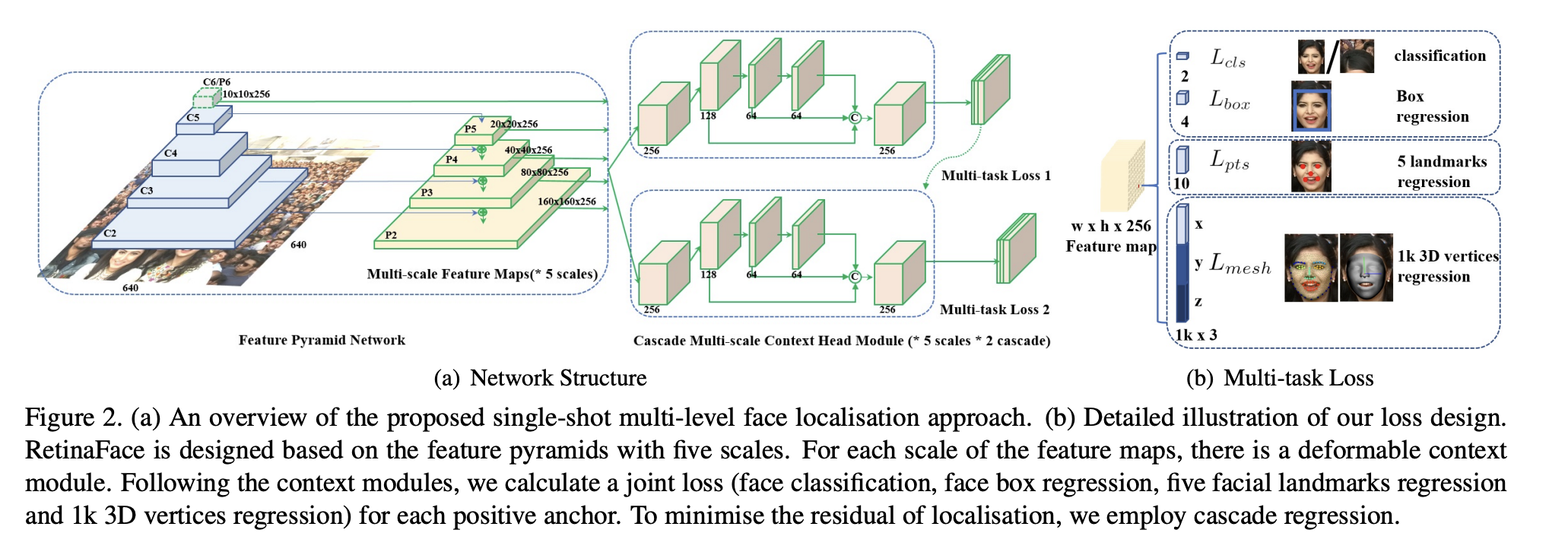
Retinaface모델의 구조는 feature pyramid network, the context head module 그리고 the cascade multi-task loss의 3가지로 나눌 수 있다. feature pyramid에서는 input으로 2D 이미지가 들어오고 최종적으로 5개의 feature map을 output으로 내뱉는다. 그 후 context head moudel 에서는 각각의 feature map들에 대해 multi-task loss를 계산해 낸다. 각각의 과정을 자세히 살펴보자.
Feature Pyramid
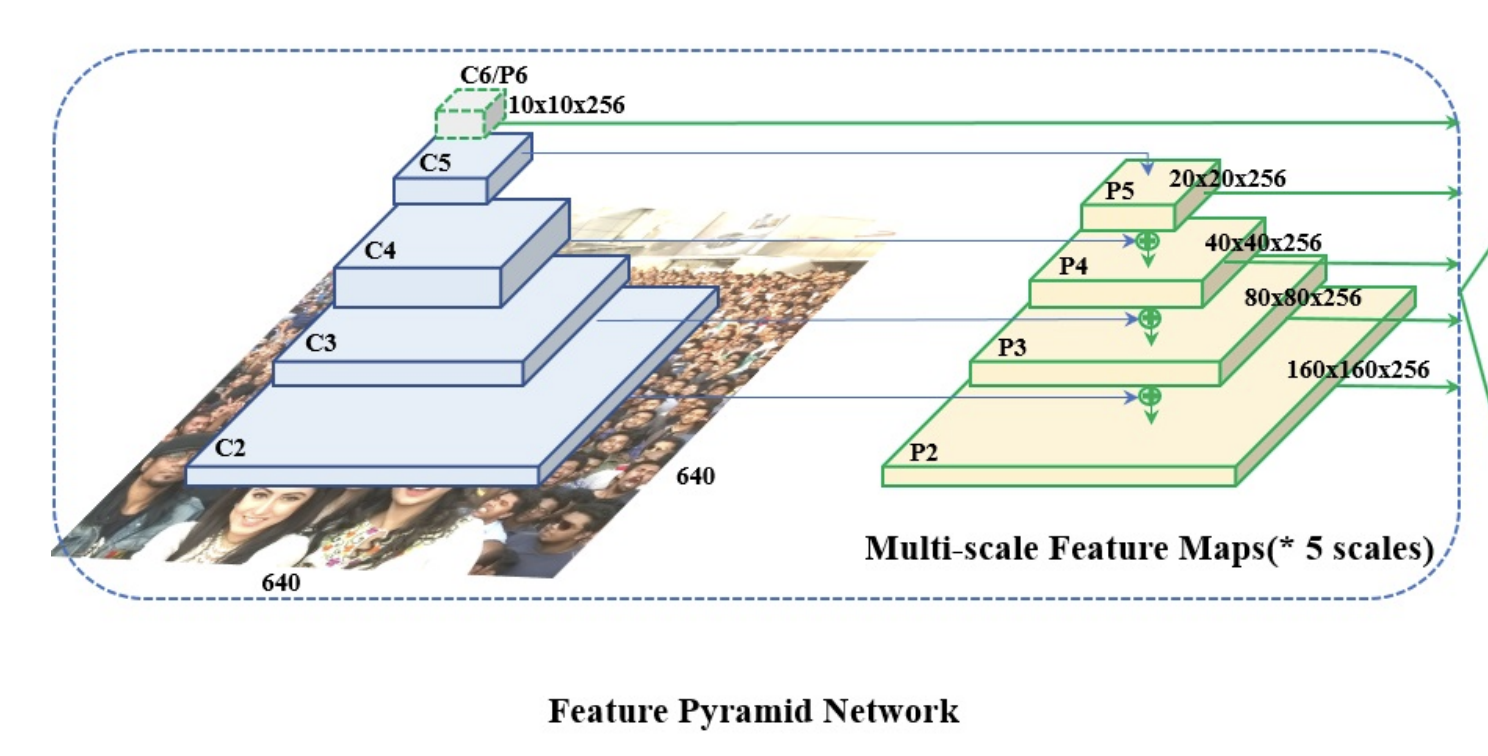
Retinaface에서는 P2부터 P6까지의 feature map을 사용하고 각각의 feature map은 residual connection을 통해 만들어 진다. 이때 C2부터 C5 까지는 ImageNet으로 pretrained된 weight들을 사용하였고 P6는 Xavier 초기화 방법을 사용하여 weight를 초기화 하였다.
Context Module
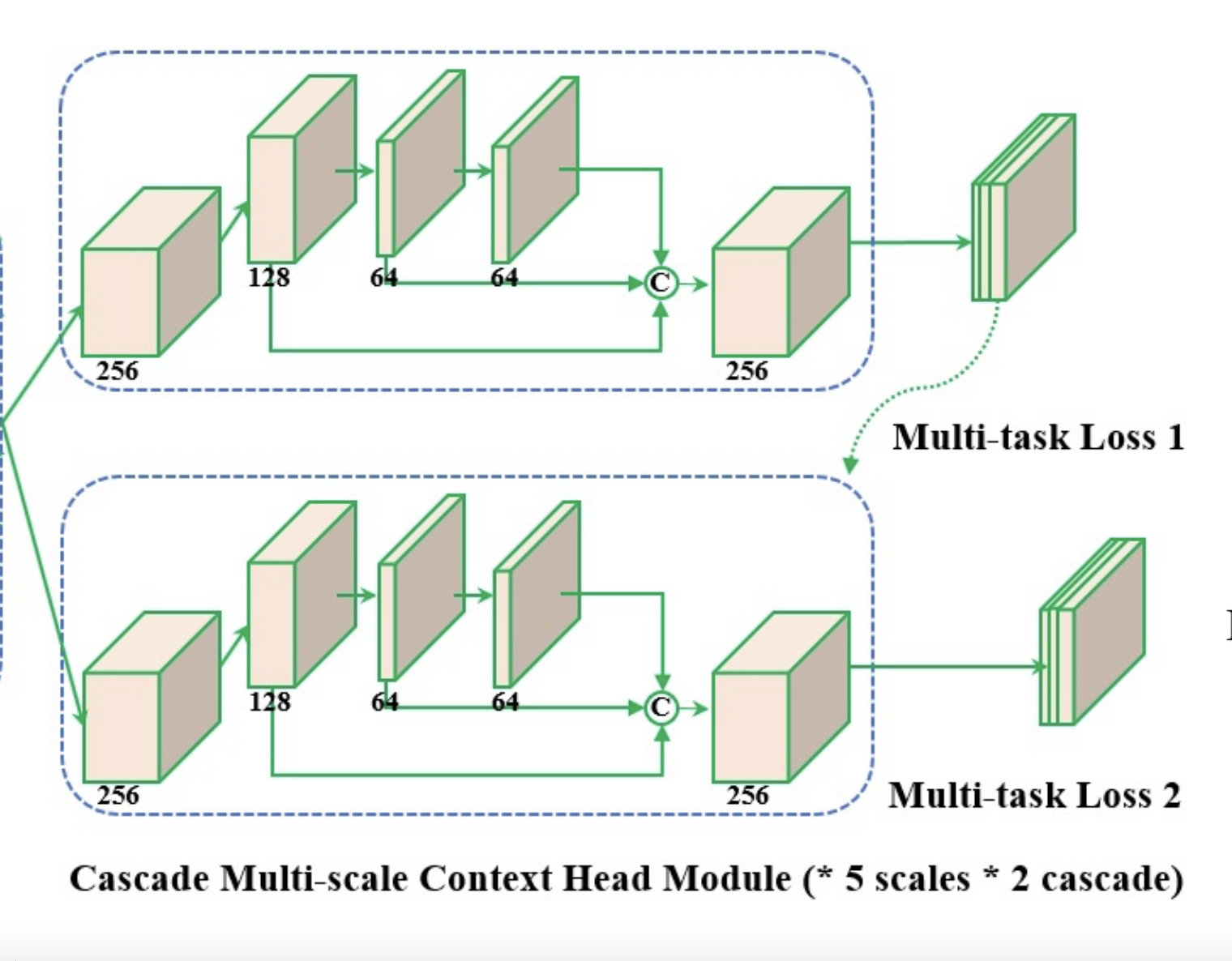
Context module의 특징은 2개의 단계로 나누어져 있다는 것이다. 첫 번째 context module에서는 regular anchor 로부터 bounding box를 예측하고, 이후 두 번째 context module을 통과하며 수정된 anchor로 부터 더욱 더 정교한 bounding box를 얻을 수 있다.
Cascade Multi-task Loss
Reitnaface 에서는 모델의 성능을 높이기 위해 Cascade regression을 사용한 Multi-task loss를 추출하였다. 즉 위의 context module의 사진을 보면 두 가지 단계로 나누어서 정교한 bounding box를 얻었다고 했는데 바로 이러한 방식이 cascade regression이다.
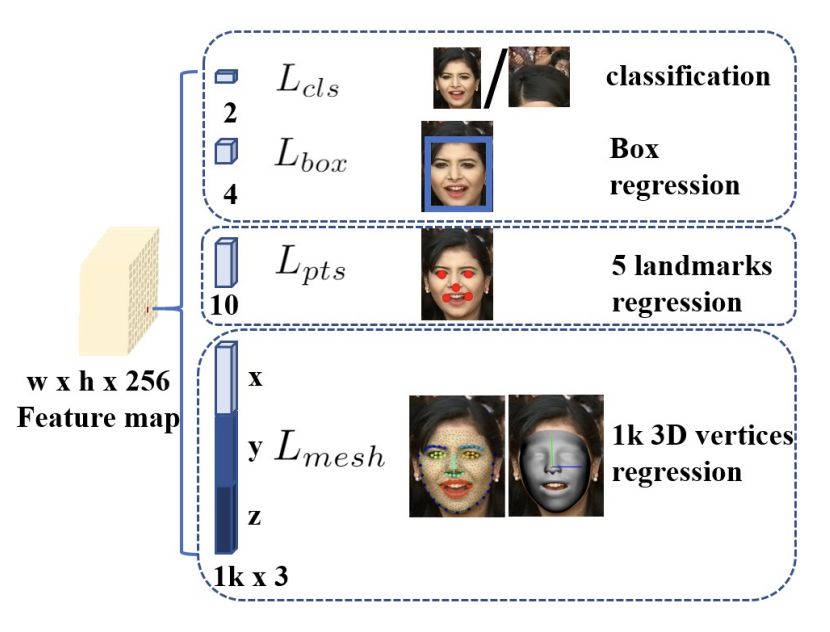
최종적인 multi-class loss는 feature pyramid가 context module을 거쳐 최종적인 h x w x 256사이즈의 layer가 나오게 되는데 여기서 1x1 convolution 을 진행해 최종적인 h x w x 256사이즈의 output을 얻게 된다.
Experiments
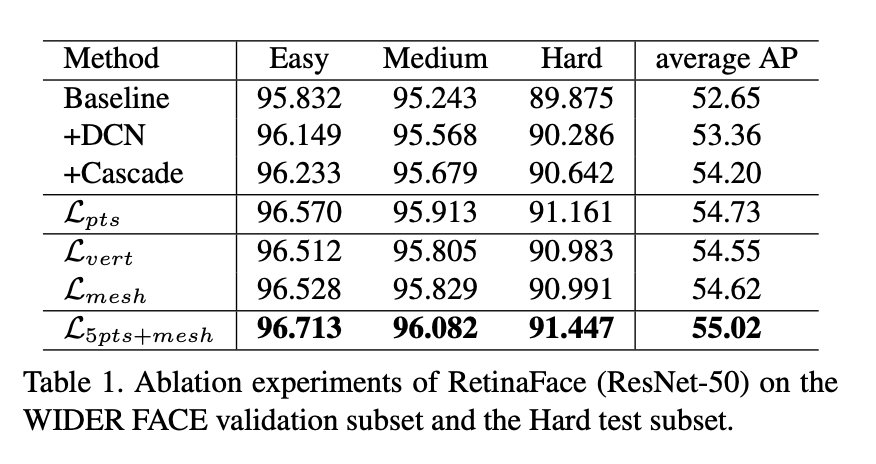
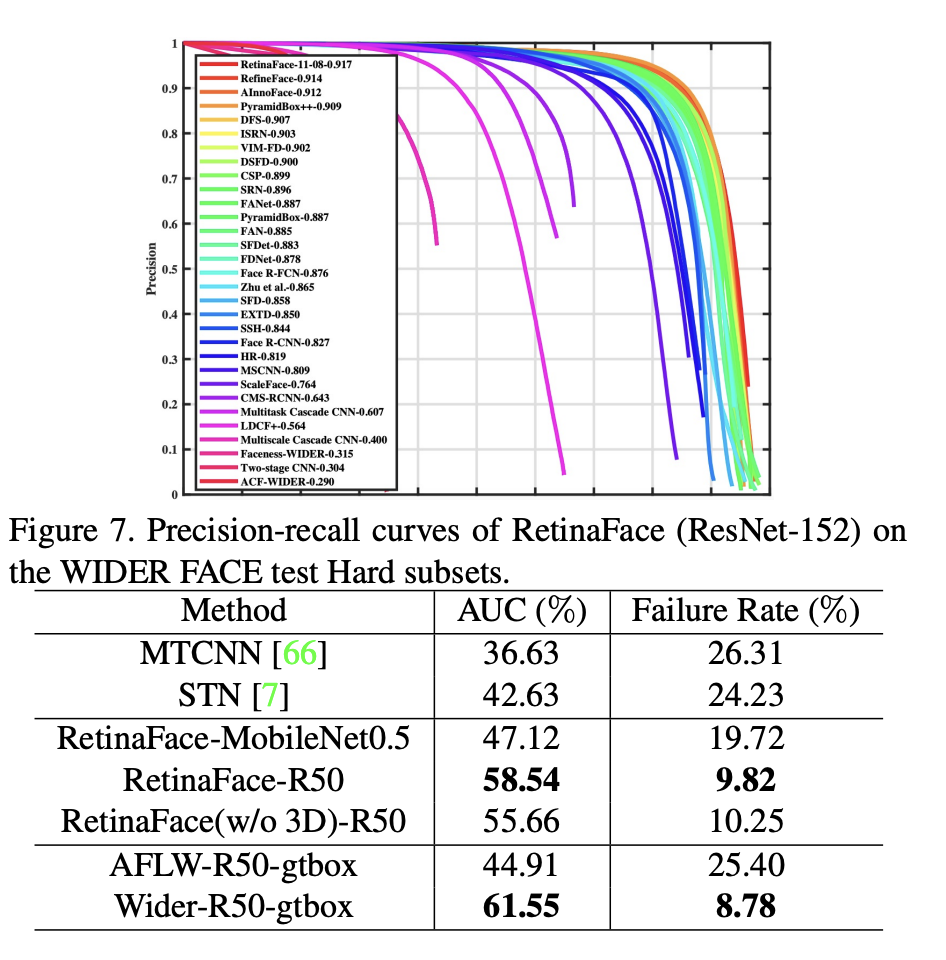
Face Detection
Five Facial Landmark Localisation