Learning Continuous Image Representation with Local Implicit Image Function
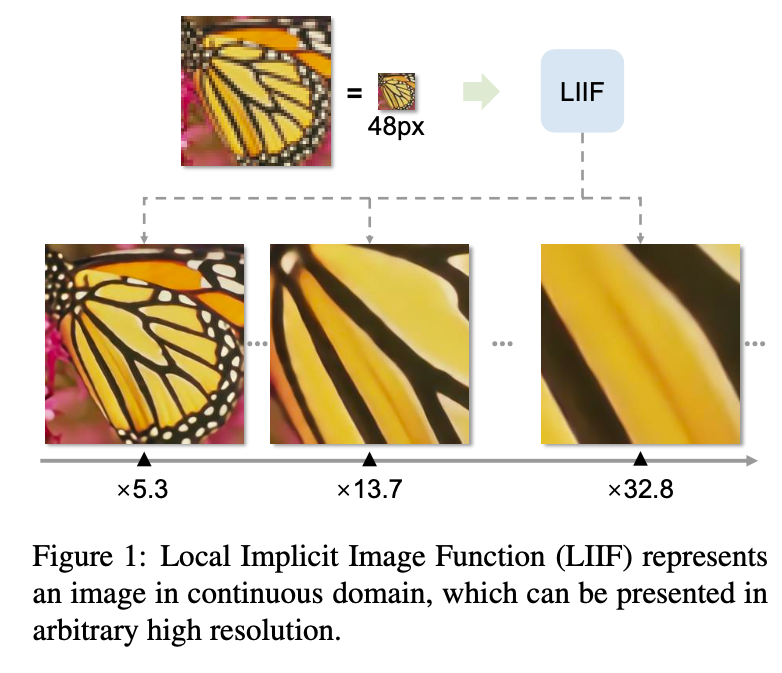
본 논문은 self-supervised하게 학습하는 Super Resolution에 관련된 내용이다. 그런데 일반적인 Super resolution 모델의 경우 4 upsampling 모델, 8배 upsampling 모델 등 각각의 sampling 배수에 대한 모델이 존재해야지만 해당 배수만큼의 super resolution이 가능하다. 본 논문의 모델은 continous한 function으로 이미지를 표현하기 때문에 4배 upsampling 모델을 학습하더라도 8배,16배,13.7배 등 다양한 배수의 upsampling을 진행할 수 있다는 장점이 존재한다.
1. Introduction
기존의 컴퓨터 비전에서는 이미지를 고정된 픽셀 grid로 취급하기 때문에 입력 크기를 통일하기 위해 resize를 거치기도 한다. 그러나 이러한 과정은 이미지의 세부 정보가 손실되기 쉽다. 특히 다양한 해상도의 이미지를 한 모델로 처리애야할 때는 이러한 현상이 더 심해지게 된다. 따라서 본 논문에서는 이미지를 "continuous function"으로 해석하는 방법론을 제시하였다. 이미지를 어떤 해상도로든 원하는 좌표에 대응하여 RGB 값을 출력하는 함수로 간주함으로써, 한 번 학습된 모델로 임의 배율의 해상도를 매끄럽게 구현해낼 수 있다. 본 논문에서는 Local Latenet Code와 MLP decoder를 결합하여 Local Implicit Image Function 이라는 연속적 이미지 표현을 설계하고, 이를 통해 학습되지 않은 배율의 super-reslution도 가능하다는 것을 보여준다.
이렇게 이미지를 "continuous function"으로 mapping 하는 neural network방법론은 이전부터 존재해 왔는데 이걸 Implici Neural Representation(INR) 방법론 이라고한다.
이처럼 이미지를 픽셀 그리드로 표현하는게 아니라 좌표로 변경한 뒤, 해당 좌표의 RGB값을 학습함으로써 이 Neural Network는 이미지를 implicit하게 표현할 수 있다는게 이 INR 방법론의 핵심 개념이다.
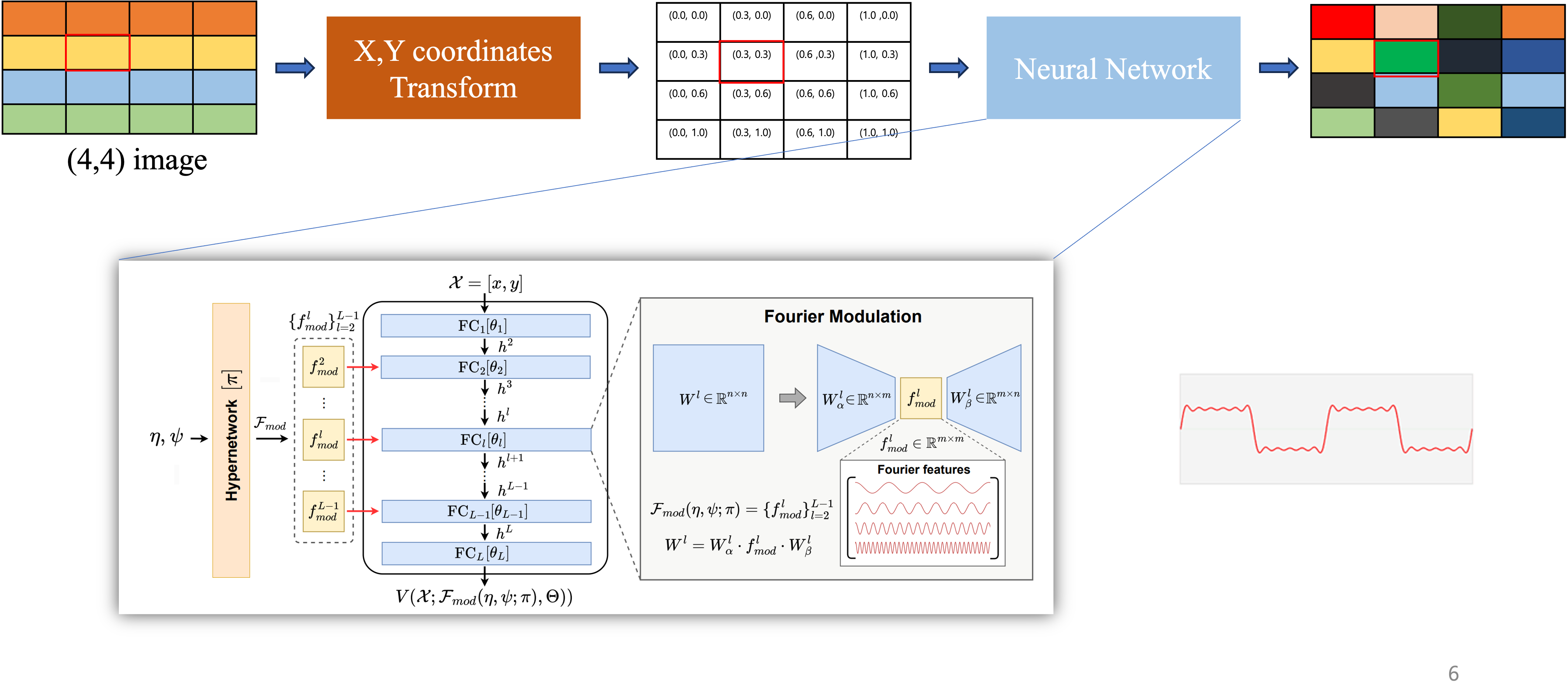
2. Method
2.1 Feature extraction
입력 이미지 를 CNN 기반의 encoder 에 통과시키면 다음과 같은 feature map을 얻게 된다.
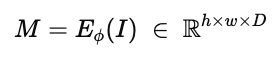
여기서 로 이 r은 downsampling factor이다. 이러한 feauture map에서 각 공간 위치 에 대응하는 latent code는 다음과 같이 표현한다.
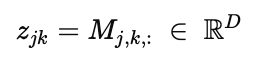
각 latent code는 에, 그 주변 3x3 이웃의 feature를 연결하여 local context를 강화하는 과정을 거친다.
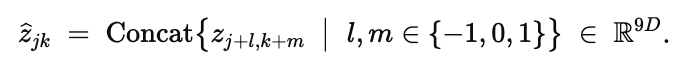
이후 MLP가 이 차원의 latent code를 다시 차원으로 변경한다.
2.2 Local Implicit Decoding
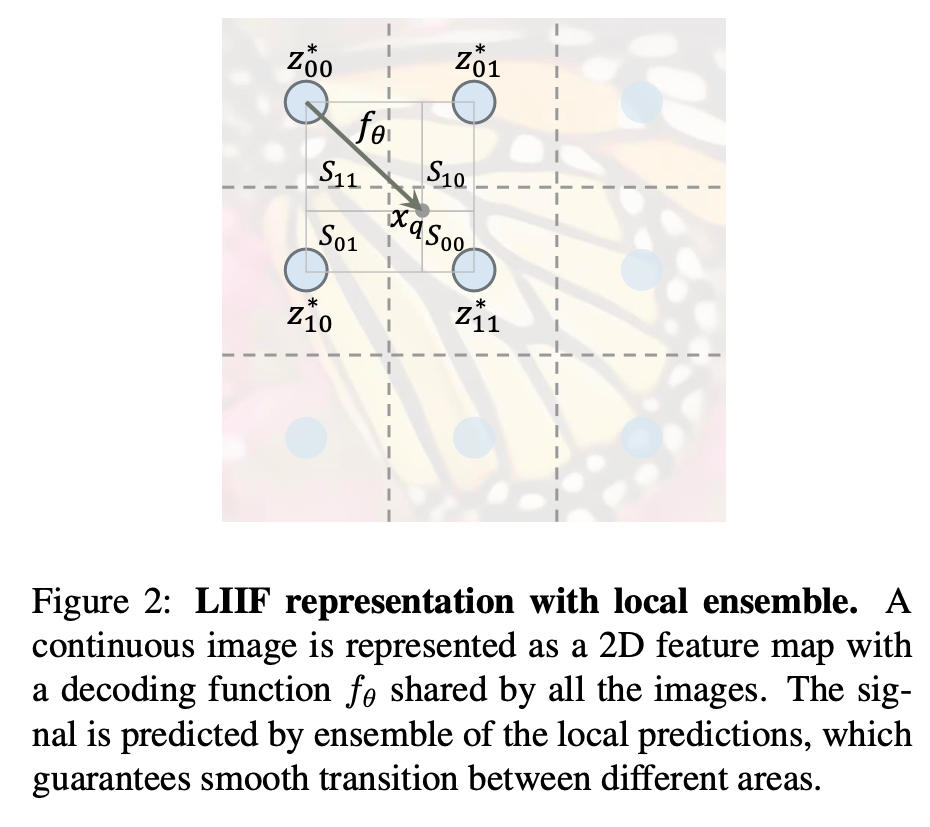
입력으로 받은 이미지의 해상도보다 높은 해상도를 가진 query 좌표 가 주어지게 되면, 가장 가까운 grid좌표 와 해당 latent code 을 찾은뒤 다음과 같은 방식으로 RGB를 예측하게 된다.
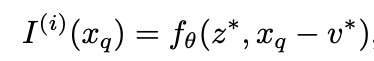
경계부분의 불연속을 줄이기 위해 고해상도의 좌표 주위 네 셀의 latent code를 모두 사용하여 최종적인 RGB를 예측한다.
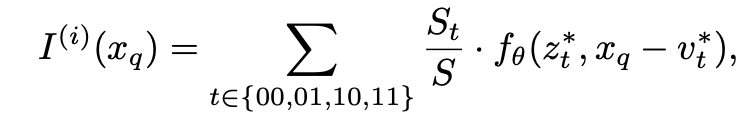
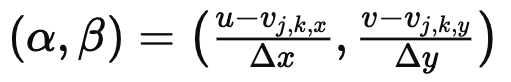
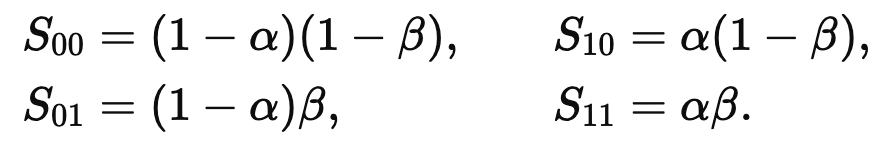
만약 픽셀의 면적 정보를 추가로 준다면 픽셀의 높이,너비를 입력에 포함시켜 RGB를 예측할 수도 있다.
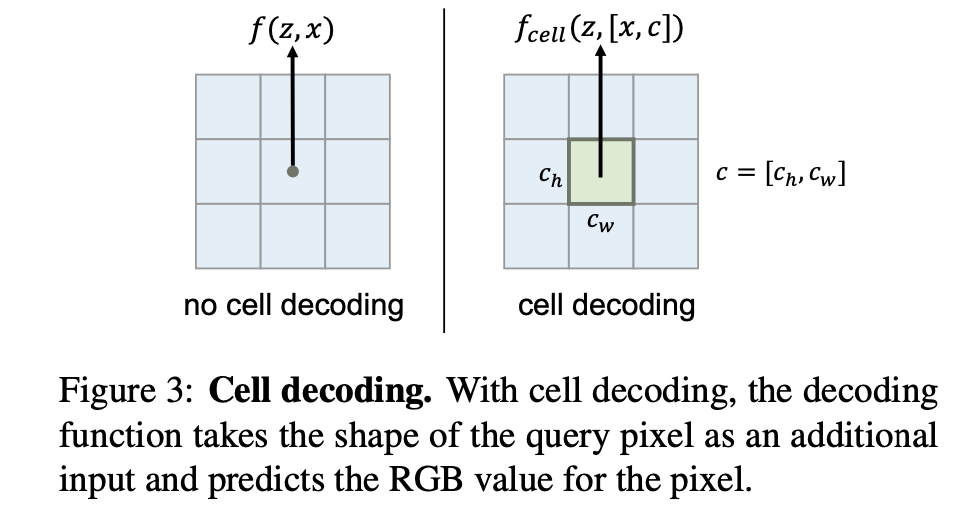
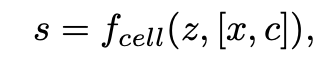
2.3 Training Procedure
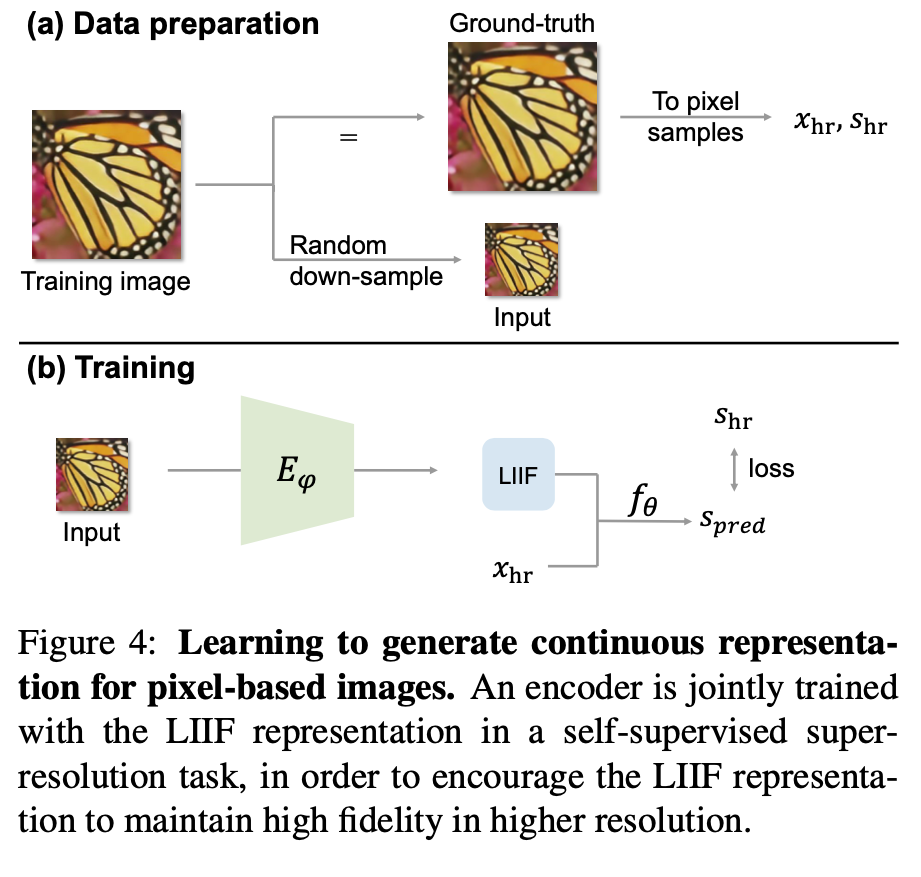
우선 기존의 이미지를 downsampling 한뒤, downsampling된 이미지에 대해서 이미지 encoder를 통과하고, 통과한 feature map과 고해상도 이미지의 좌표를 통해, RGB값을 예측하며 학습을 진행하게 된다. 즉 feature map의 공간과 실제 고해상도 영상의 좌표를 맞추어가는 과정이 바로 2.2 local implicit decoding 과정이다.
3. Results
3.1 Qualitative results


3.2 Quantitative results
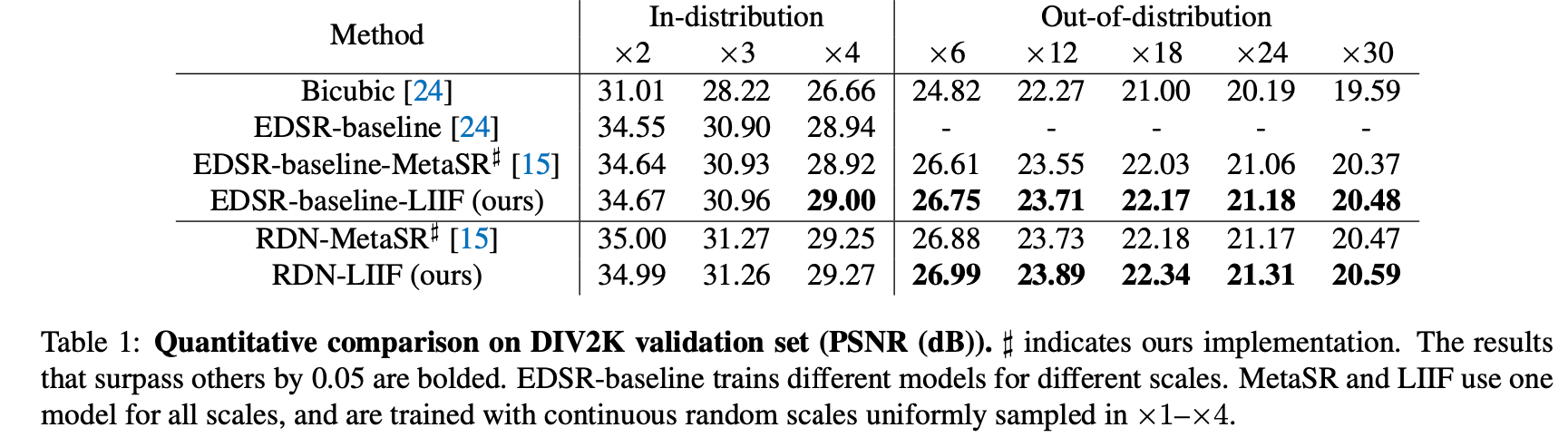
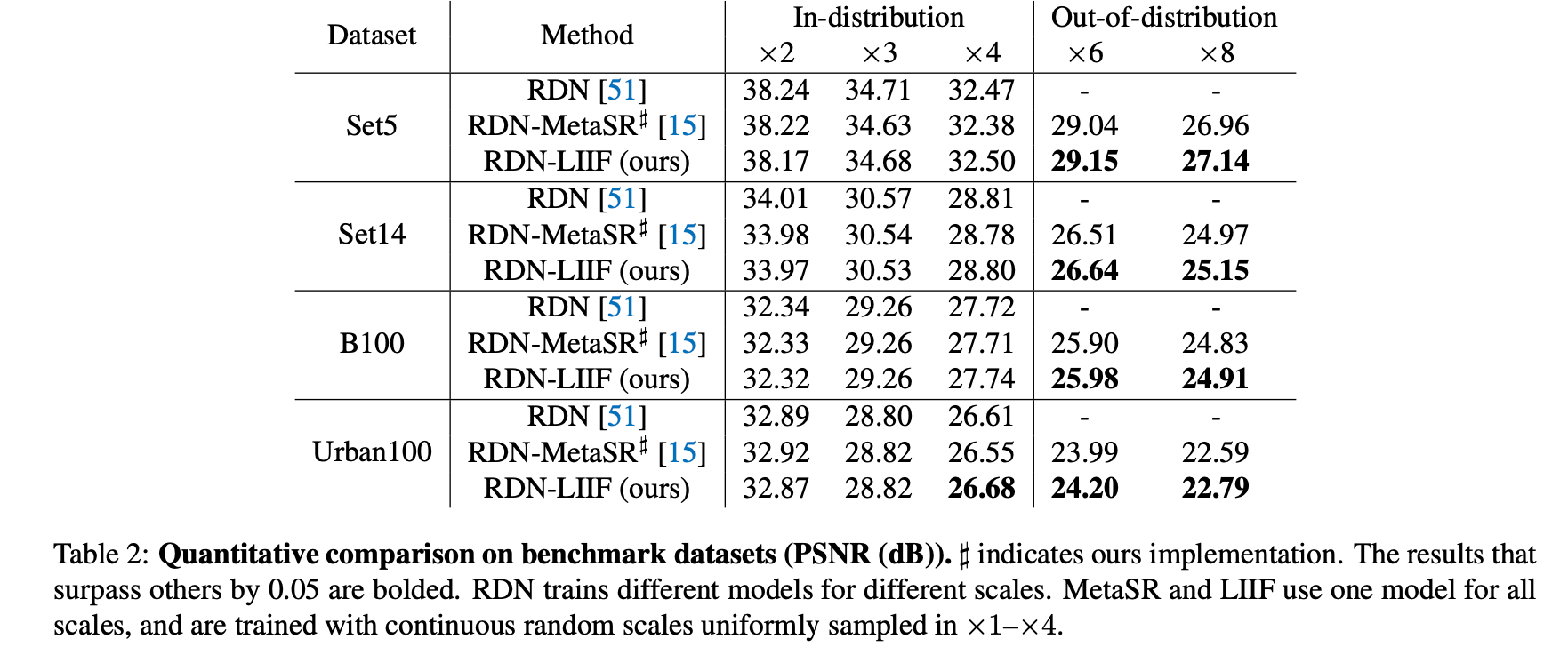
결과에서 알 수 있듯이 out-of-distribution, 즉 학습되지 않은 upsampling scale에 대해서도 모델이 inference가능한 것을 보여주고 있다.
현재 나와있는 baseline들은 기존의 Supervised SR들이 아닌, 본 논문과 유사하게 continuous function을 통해 이미지를 표현하는 모델들과의 비교이다. 이 논문의 가장 큰 novelty가 바로 LIIF 즉, 주변 맥락을 이용하여 decoding하는 것이기 때문에 본인들의 decoding 방법의 성능을 보여주고자 이러한 baseline을 짠 것 같다.
