개요
기존의 Monocular video로부터 3D human pose estimation을 얻는 모델들은 모호성과 self-occlusion 문제를 갖는다는 한계점이 존재한다. 이러한 문제를 해결하기 위해서 시간적 공간적 관계를 파악하려는 연구들이 많았다. 하지만 이 또한 가능한 많은 가설들을 무시했다는 문제점을 가지고 있다. 이 한계점을 해결하기 위해 등장한 모델이 MHformer라는 모델이다.
MHformer란 Multi-Hypothesis Transformer 즉 여러 개의 그럴듯한 pose가설들은 시공간적으로 표현한 것이다.
모델 설명
MHformer란 monocular 영상으로부터 3D human pose를 생성하는 Transformer 기반의 모델이다.
Input
MHformer는 크게 두 가지 task로 나뉘는데 하나는 2D pose detection으로 이미지의 keypoints들을 구하는 것이고 다른 하나는 2D-to-3D lifting을 통해 2D keypoints 로부터 3D공간상의 joint들로 나타내는 과정이다.
Overview
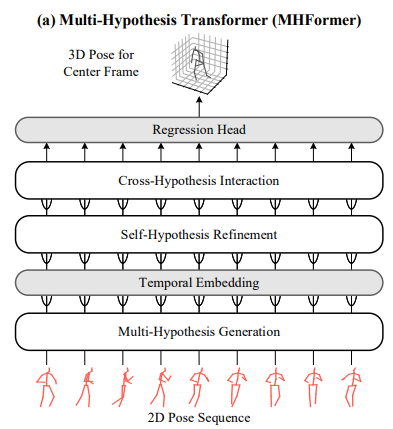
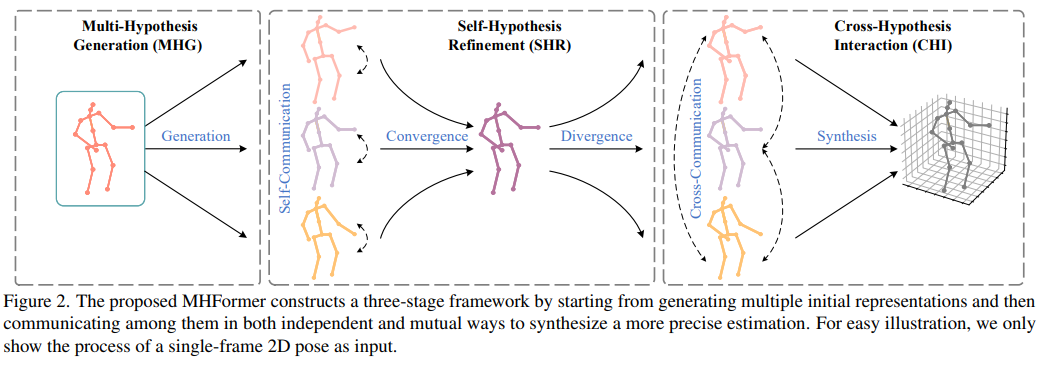
MHformer는 총 5단계를 거치며 3D human pose를 생성하게 된다. MHG, Temporal Embedding, SHR, CHI, Regression Head의 과정들을 자세히 알아보도록 하자.
MHG(Multi-Hypothesis Generation)
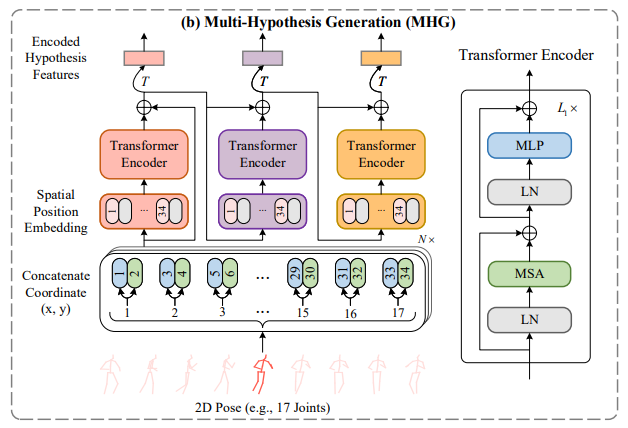
MHG 단계에서는 2D pose keypoint에서 joint들의 x,y좌표를 각각의 프레임과 연결 시킨다. 그 후 spatial position embedding을 통해 공간정보를 유지한다. 이런 공간정보를 포함한 특징들을 MHG의 encoder에 보내진다. 또한 gradient vanishing 문제를 막기 위해 encoder 내에서 skip residual connection을 적용하였다. 이렇게 MHG의 output은 multi-level feature를 포함한 정보를 가지게 된다. 따라서 이러한 특징은 더 향상되어야 하는 초기의 다중 가설 표현이 된다.
Temporal Embedding
MHG 단계에서는 비록 강하지 않더라고 multi-hypothesis 공간상의 features를 만들어 낸다. 이를 해결하기 위해 시간상의 개념을 활용하여 SHR과 CHI와 같은 방법을 활용하였다. 그러기 위해서 우선 temporal한 정보 즉, 시간상의 정보를 얻어야 한다. 그러기 위해서는 spatial domain에서 temporal domain으로의 변경이 우선시 되어야 한다. 이를 위해서는 우선 encode된 hypothesis인 X를 teansposition operation과 linear embedding을 통해 더 높은 차원의 feature인 Z에 내장한다.
SHR(Self-Hypothesis Refinement)
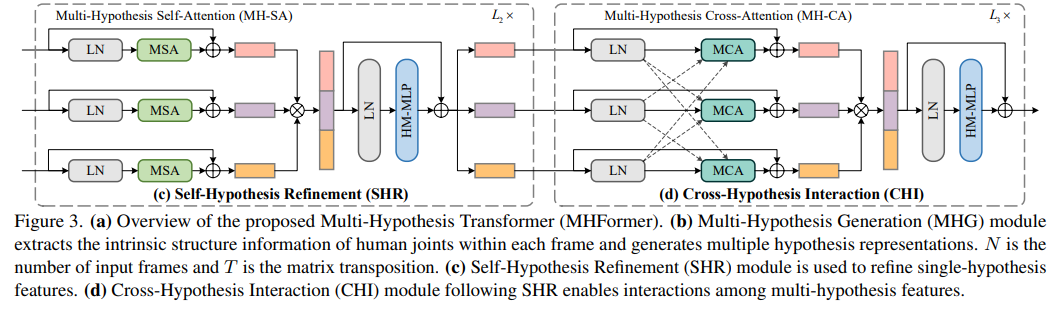
SHR을 거치며 sigle-hypothesis feature들은 정교해 진다. 각각의 SHR layer들은 MH-SA block과 HM-MLP block로 구성되어 있다.
MH-SA(multi-head self attention)
Tansformer 모델에서 MSA가 핵심적인 역할은 한다. MSA는 임의의 두 요소가 서로 상호작용할 수 있어 long-range dependecies를 갖게 된다. 그 대신에 MH-SA는 서로 다른 두 hypothesis를 연결하는 것이 아니라 각각의 hypothesis들을 독립적으로 single-hypotehsis의 독립성을 파악하는데 중점을 두었다. 이전에 temporal informaion을 가진 Z를 몇 개의 (multi-head-self-attention)MSA 에 들어가게 된다.
HM-MLP(Hypothesis-mixing MLP)
MH-SA를 통과하며 각각 독립적으로 생성된 hypotheses들은 서로 정보를 교환하지 않았다. 따라서 hypothesis-mixing MLP를 MH-SA이후에 추가하며 이를 해결해 주었다. MH-SA를 거친 hypothesis들은 합쳐진 후 HM-MLP block을 거치게 된다. 이후 겹치지 않게 다시 각각 할당해 준다. 이러한 일련의 과정들을 통해 서로다른 hypothesis들의 관계를 알 수 있게 된다.
CHI(Cross-Hypothesis Interaction)
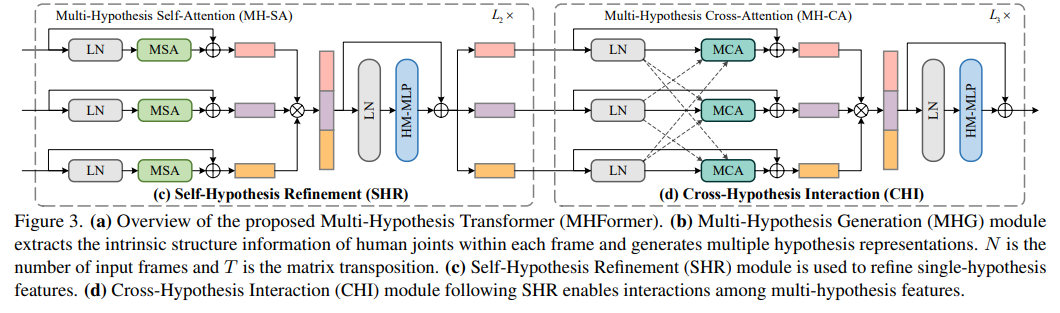
MH-SA block에서는 hypothesis들간의 관계에 중점을 두지 않았다. 따라서 multi-hypothesis의 상관관계를 파악하기 위해 MH-CA block을 사용하게 된다.
MH-CA(mlti-head cross attention)
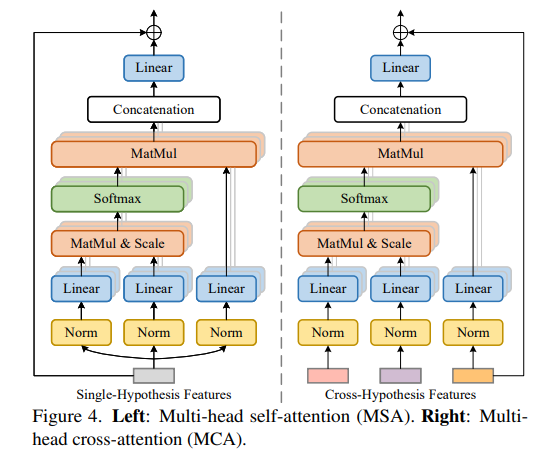
MH-CA block에는 multi-head-cross attention(MCA)요소가 평행하게 놓여있다. 원래 MCA는 MSA와 같은 방식으로 진행 되지만 그렇게 되면, hypothesis의 개수보다 MCA의 개수가 많아지게 된다. 따라서 이를 해결하기 위해 서로 다른 input을 사용하여 MCA의 개수를 줄였다.
HM-MLP(Hypothesis-mixing MLP)
CHI에서도 마찬가지로 SHR과 동일한 HM-MLP를 사용하여 3개의 hypothesis를 합친 후 다시 재분배 하였다.
Regression Head
Linear transformation layer가 최종 output을 3D pose sequence로 변경시켜 준다.
출처
MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation
