PICK-O를 개발하던 중, 사용자들이 원하는 정보를 더 쉽게 찾을 수 있도록 톡픽(게시글) 검색 기능을 구현해야 하는 과제가 주어졌습니다.
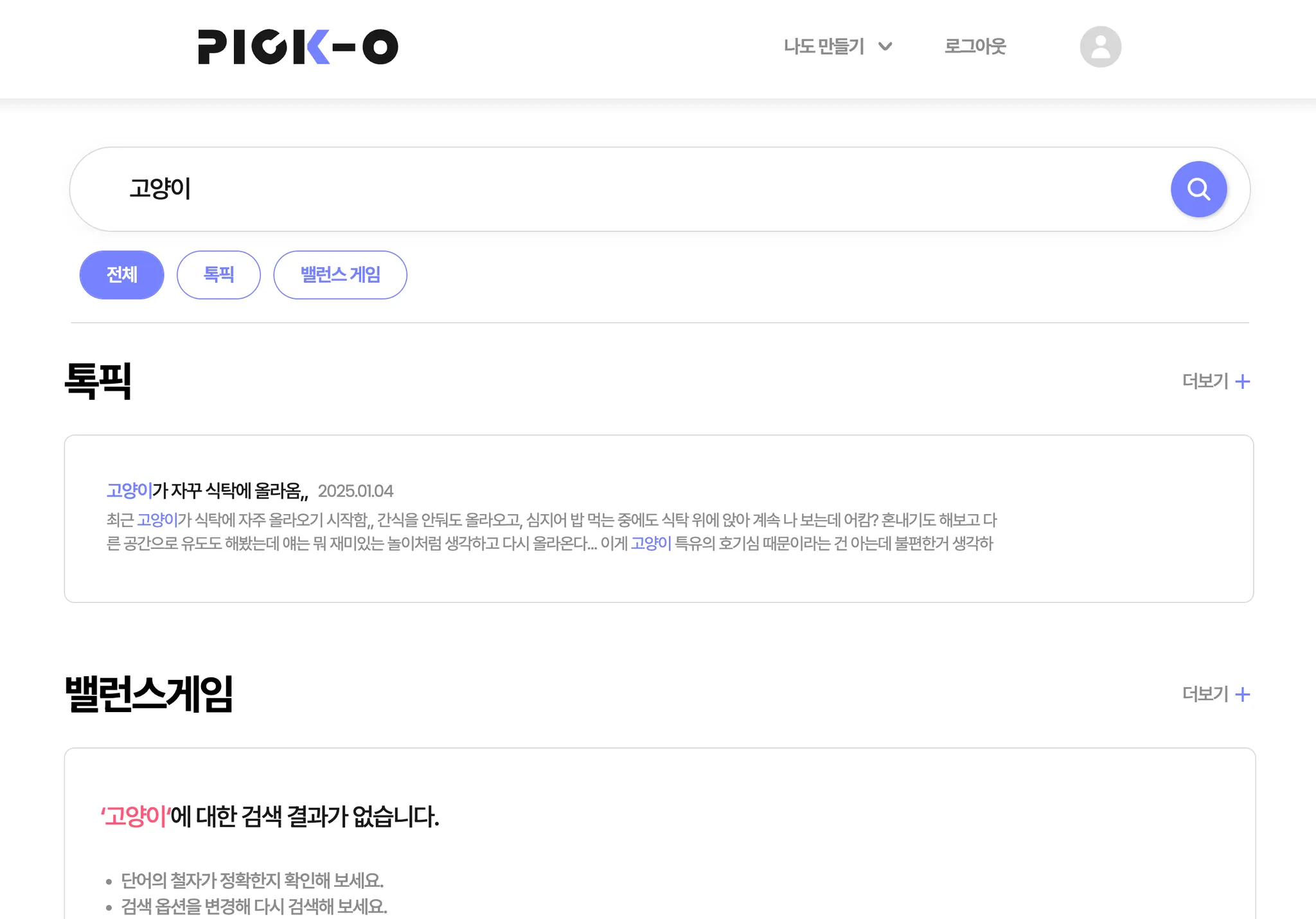
우리는 먼저 요구사항을 분석하고, 검색 기능의 핵심 요소를 다음과 같이 정의했어요.
- 검색 범위는 톡픽의 제목, 선택지, 본문, 요약 내용을 모두 포함한다.
- ‘은’, ‘는’, ‘이’, ‘가’와 같은 불용어를 처리해야 한다.
- 검색 우선순위는 기본적으로 정확도를 기준으로 하고, 세부적으로 빈도수를 고려해 정렬한다.
- 키워드와 완전히 일치하는 단어를 가지는 톡픽
- 공백을 제거한 키워드와 완전히 일치하는 단어를 가지는 톡픽
- 키워드에 부분적으로 포함된 단어를 가지는 톡픽
뭐로 구현하지?
정의한 요소들을 모두 만족하는 검색 기능을 개발하는 데 사용할 기술을 선택하기 위한 고민이 시작됐습니다.
PICK-O의 데이터베이스로 MySQL을 이미 사용하고 있었는데요. 그래서 MySQL을 활용할지, ElasticSearch와 같은 전문 검색 엔진을 도입할지를 두고 고민에 빠졌습니다.
MySQL LIKE 키워드는 어떨까..
일단 MySQL의 LIKE 키워드는 설정이나 학습 없이 바로 활용할 수 있는 간단한 방법이었습니다. 하지만 "검색 패턴이 와일드카드로 시작하거나 중간에 포함된 패턴을 검색할 경우, MySQL의 인덱스를 활용할 수 없다는 점"이 가장 큰 걸림돌이었어요.
결국 LIKE 키워드만으로는 우리의 요구사항을 만족하기 어렵다고 판단했고, MySQL의 Full-Text Index와 ElasticSearch 중에서 더 적합한 대안을 선택하기 위한 논의가 이어졌습니다.
MySQL Full-Text Index vs ElasticSearch
ElasticSearch는 뛰어난 성능과 유연성을 제공하지만, 몇 가지 현실적인 제약이 있었습니다. 팀 내에서 이를 다뤄본 경험이 전혀 없었기 때문에, 학습과 설정에 상당한 시간이 소요될 가능성이 높았어요. 게다가 ElasticSearch를 도입하기 위해서는 추가적인 인프라 작업과 관리가 필요한데, 프로젝트 초기 단계에서는 이러한 리소스를 감당하기 어려웠습니다.
반면, MySQL의 Full-Text Index는 다음과 같은 이유로 더 현실적인 대안이었습니다.
- 추가적인 인프라를 도입하지 않고, 현재 사용 중인 MySQL 데이터베이스에서 바로 적용 가능함
- 이전 프로젝트에서 적용해 본 경험을 통해 학습 곡선이 짧고, 빠른 개발이 가능함
- 정확도 기반 정렬, 불용어 처리 등 주어진 요구사항은 Full-Text Index로도 충분히 구현 가능함
결과적으로, 우리는 효율적인 리소스 활용과 빠른 요구사항 충족을 위해 MySQL Full-Text Index를 선택했습니다.
이어서 주어진 요구사항을 하나씩 충족하기 위해 검색 범위 설정, 불용어 처리, 그리고 정렬 로직을 구체화했습니다.
검색 범위 설정
“검색 범위는 톡픽의 제목, 선택지, 본문, 요약 내용을 모두 포함한다.”
다음과 같이 사용자가 작성한 톡픽에는 제목, 선택지, 본문, 요약 내용이 포함되는데요. 이 모든 필드가 검색 범위에 포함되도록 구현해야 했습니다.


사실 이를 만족하는 것은 굉장히 쉬웠어요.
검색 범위에 포함되는 필드들을 대상으로 인덱스를 생성하기만 하면 되기 때문입니다.
CREATE FULLTEXT INDEX ft_talk_pick
ON talk_pick(
title,
summary_first_line,
summary_second_line,
summary_third_line,
content,
option_a,
option_b
) with parser ngram;Full-Text Index는 다중 필드를 지원하기 때문에, 이들을 결합해 하나의 검색 범위로 처리할 수 있었습니다. 덕분에 검색 키워드가 제목, 본문, 선택지, 요약 중 어디에 있든 쉽게 검색 결과로 나타날 수 있도록 설계할 수 있었어요.
ngram parser
여기서 중요한 점은, 한국어 기반 자연어 검색을 사용하기 위해 ngram parser를 사용했다는 건데요.
parser는 텍스트를 특정 기준에 따라 분리(토큰화)하고, 인덱싱할 단위를 결정합니다. MySQL에서 기본으로 설정되는 parser는 띄어쓰기와 특수문자를 기준으로 단어를 구분합니다. 이 때문에 영어처럼 띄어쓰기로 단어를 구분할 수 있는 언어에서는 잘 작동하지만, 한국어처럼 띄어쓰기가 불규칙하거나 조사와 어미 변화가 많은 언어에서는 정확한 검색 결과를 제공하기 어려워요.
따라서, 한국어와 같은 언어에서는 인덱스 생성 시 WITH PARSER ngram을 명시하여 ngram parser를 사용해야 합니다. ngram parser는 텍스트를 일정 길이(n개)의 연속된 문자로 분리하기 때문에, 단어 경계나 띄어쓰기에 구애받지 않고 검색이 가능합니다.
자세한 내용이 궁금하다면 여기를 참고해주세요!
실제로 검색해보자
Full-Text Index를 생성한 뒤에 정말로 모든 필드가 검색 범위에 포함되는지 확인해봤습니다.

select id, views, title, content, summary_first_line, summary_second_line, summary_third_line, option_a, option_b from talk_pick
where match(title, summary_first_line, summary_second_line, summary_third_line, content, option_a, option_b) against('PICK-O');6번을 제외한 모든 row의 필드에서 “PICK-O”를 포함하고 있는 테이블을 대상으로 검색 쿼리를 실행했습니다.

위와 같이 어떤 필드에서도 “PICK-O”를 포함하지 않는 6번을 제외한 모든 row가 반환되는 것을 확인할 수 있었습니다.
불용어 처리
“‘은’, ‘는’, ‘이’, ‘가’와 같은 불용어를 처리해야 한다.”
우리는 다음과 같은 목적을 가지고 불용어를 처리하기로 했어요.
- 사용자가 입력한 검색어에서 핵심적인 단어에만 집중하도록 하기 위함
- 불필요한 단어들이 인덱스에 포함되는 것을 방지해 Full-Text Index의 크기를 줄이기 위함
- DB가 처리해야 할 단어의 수를 줄이고, 검색 속도를 향상시키기 위함
MySQL의 default 불용어?
먼저, MySQL에서 default 불용어들을 제공한다고 해서 확인해봤는데요.
select * from INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;INNODB_FT_DEFAULT_STOPWORD를 통해 MySQL이 기본으로 지원하는 불용어 목록을 확인할 수 있었습니다.
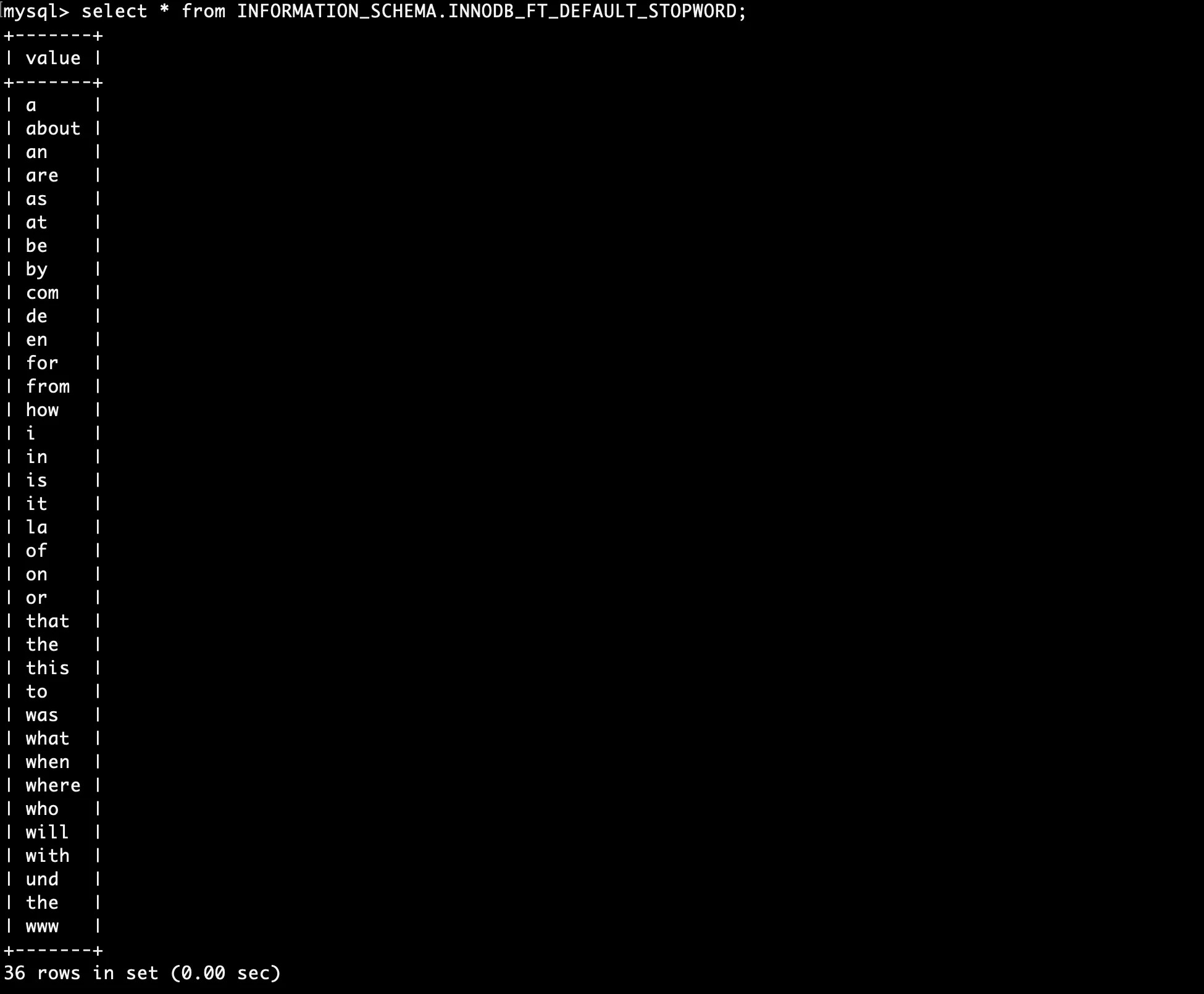
네... 역시나 예상대로 영어밖에 없더라구요.
한국어 기반 검색에서 불용어를 처리하기 위해서는, 한국어 맞춤 불용어 목록을 직접 설정해야 합니다.
불용어를 직접 정의해보자
따라서 우리는 불용어를 정의할 테이블을 만들고, 이를 Full-Text Index에서 사용하도록 설정하기로 했습니다.
우선, 다음과 같이 불용어 전용 테이블을 생성한 뒤에 "은", "는", "이", "가"와 같은 단어들을 해당 테이블에 삽입합니다.
create table PICK_O_STOPWORD(
value VARCHAR(30) unique not null
);
insert pick_o_stopword values ('은'), ('는'), ('이'), ('가'), ('을'), ('를'), ('의'), ('그'), ('저'), ('그것'), ('이것'), ('저것'), ('에서'), ('부터'), ('까지');그리고나서 정상적으로 데이터가 입력되었는지 확인합니다.
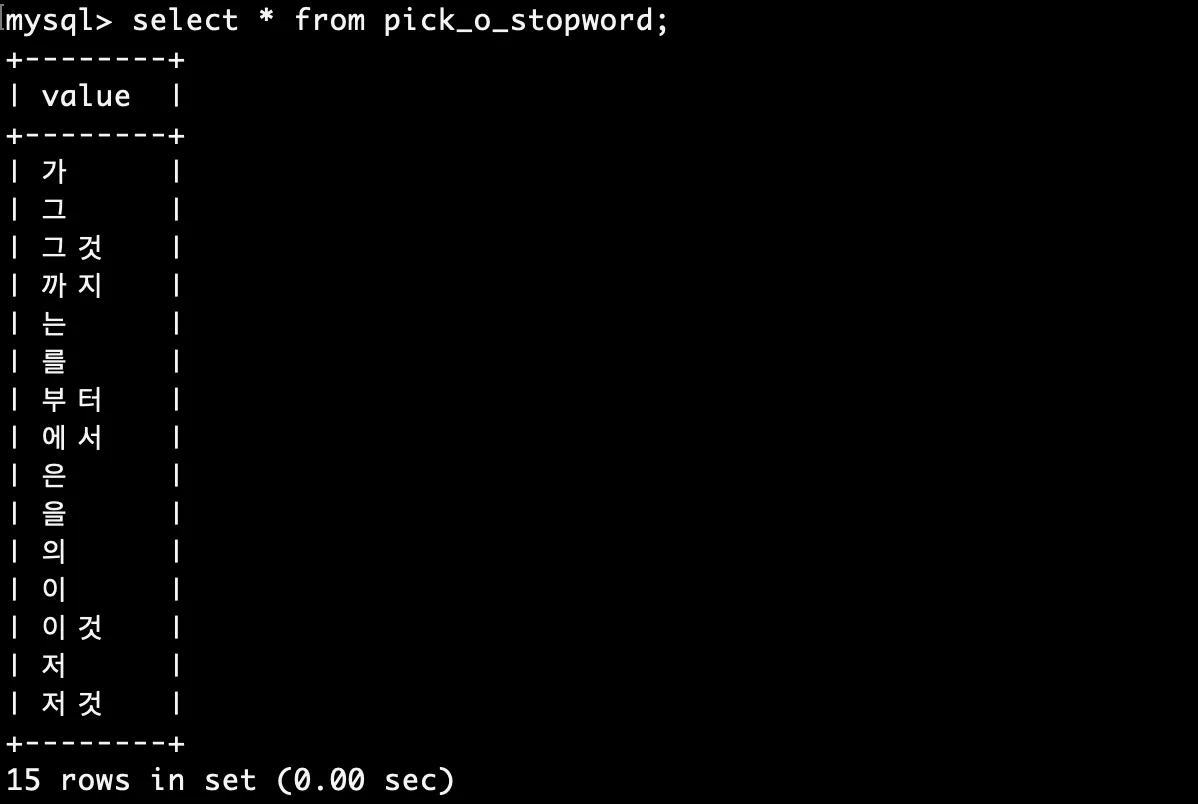
정상적으로 입력되었다면, 아래 명령어를 실행하여 Full-Text Index가 전역적으로 사용자 정의 불용어 테이블을 사용하도록 설정합니다.
SET GLOBAL innodb_ft_server_stopword_table = 'DB명/테이블명';(등록한 불용어가 정상적으로 처리되기 위해서는 Full-Text Index를 다시 생성해야 합니다.)
정의한 불용어 테이블이 제대로 동작하는지 확인해보기 위해, 아래 테이블을 대상으로 “그것”이라는 단어를 검색해봤습니다.


이처럼 검색 결과에서 해당 키워드가 무시된 것을 확인할 수 있었습니다.
검색 결과 정렬
“검색 우선순위는 기본적으로 정확도를 기준으로 하고, 세부적으로 빈도수를 고려해 정렬한다.”
검색 결과를 올바르게 정렬하기 전에, 우선 세 가지 주요 조건에 따라 데이터를 조회할 방법을 고민했습니다.
예제로 사용할 데이터 목록
아래는 검색 테스트에 사용한 톡픽 데이터입니다. 각 톡픽에는 title, content, summary, option_a, option_b 등의 필드가 포함되어 있습니다.
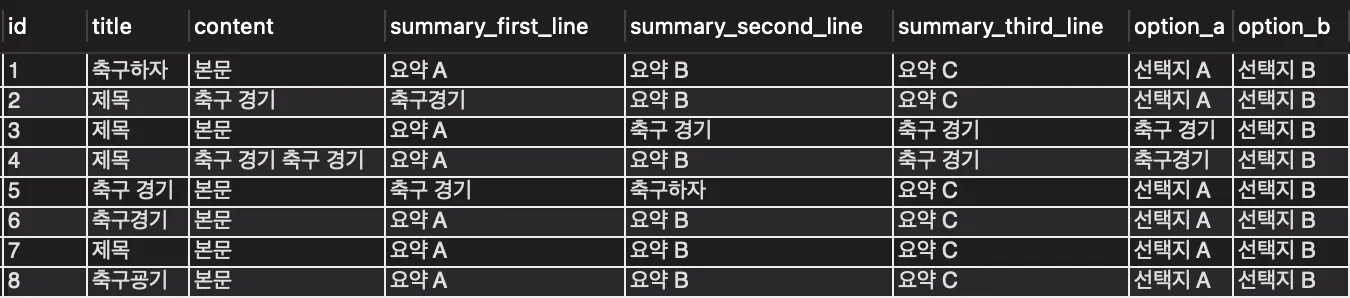
키워드와 완전히 일치하는 단어를 가지는 톡픽
이 조건은 사용자가 입력한 키워드와 정확히 일치하는 단어가 포함된 데이터를 반환하는 것을 목표로 합니다. 이를 위해 **불린 모드 검색의 "" 연산자**를 사용했어요.
select id, views, title, content, summary_first_line, summary_second_line, summary_third_line, option_a, option_b from talk_pick
where match(title, summary_first_line, summary_second_line, summary_third_line, content, option_a, option_b)
against('"축구 경기"' in boolean mode);이렇게 “” 안에 키워드를 넣어 검색하면, 정확히 일치하는 단어를 포함하는 데이터만 반환합니다.
여기서는 “축구 경기”를 넣었으므로, 다음과 같은 결과가 나타납니다.

“축구 경기"가 가장 많이 포함된 4번 톡픽이 가장 상위에 배치되며, 2번 톡픽은 "축구 경기"가 단 1회만 포함되어 있어 가장 하위에 배치되었습니다.
공백을 제거한 키워드와 완전히 일치하는 단어를 가지는 톡픽
이 조건은 톡픽 작성자와 (검색을 수행하는) 사용자가 입력한 단어 형식이 다르더라도 의미적으로 동일한 데이터를 반환할 수 있도록 지원하기 위해 추가한 기능입니다.
예를 들어, 톡픽 작성자가 실수로 “축구 경기”를 “축구경기”라고 작성했을 경우, 사용자가 “축구 경기”라고 검색하면 해당 단어가 반환되지 않을 수 있습니다.
이를 구현하기 위해 키워드에서 공백을 제거한 뒤 Boolean 모드의 “” 연산자에 넣어 검색을 수행하도록 했고, 결과는 다음과 같이 나왔습니다.

6번 톡픽의 경우, 사용자가 입력한 키워드인 “축구 경기”는 포함하지 않지만 “축구경기”를 포함하고 있으므로 결과에 제시됩니다. 반면에 5번 톡픽은 “축구 경기”는 포함하지만, “축구경기”를 포함하지 않으므로 결과에서 제외된 것을 확인할 수 있습니다.
키워드에 부분적으로 포함된 단어를 가지는 톡픽
마지막으로, 검색어와 부분적으로 일치하거나 유사한 단어를 포함하는 톡픽을 검색하는 기능을 구현했습니다. 이는 사용자가 키워드를 정확히 입력하지 않더라도 관련 결과를 반환하기 위한 조건입니다.
이를 구현하기 위해, Full-Text Index에서 지원하는 자연어 검색을 사용했는데요. 자연어 검색 모드는 키워드를 정확히 입력하지 않아도 부분 일치나 유사도를 기반으로 의미 있는 결과를 제공할 수 있기 때문입니다.
Full-Text Index 생성 시 ngram parser를 지정해줬다면, 쿼리는 단순합니다. 다음과 같이 검색 모드는 생략해도 되며, 키워드만 넣으면 됩니다.
select id, views, title, content, summary_first_line, summary_second_line, summary_third_line, option_a, option_b from talk_pick
where match(title, summary_first_line, summary_second_line, summary_third_line, content, option_a, option_b)
against('축구 경기');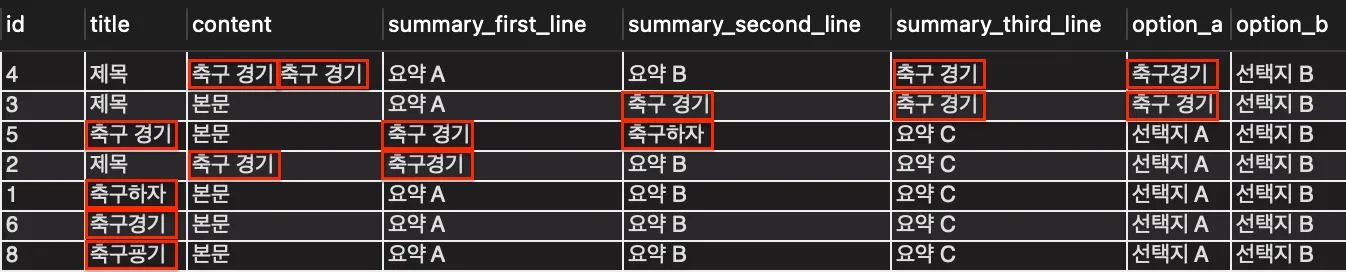
“축구 경기”를 검색하면, 위와 같이 “축구 경기”와 “축구경기” 뿐만 아니라 “축구”가 포함된 모든 톡픽이 조회되는 것을 확인할 수 있었습니다.
마무리
이번 검색 기능 구현을 통해, 팀원들과 논의하며 기술적인 제약 속에서도 효율적인 해결책을 찾아내는 과정을 경험할 수 있었습니다.
하지만 여전히 해결하지 못한 점들도 있었는데요, 이는 다음과 같습니다.
- Full-Text 검색은 기본적으로 단어 매칭을 기반으로 하기 때문에, 요구사항이 복잡할수록 한계가 명확해짐
- 파티션 테이블에서는 Full-Text Index를 사용할 수 없음
- Full-Text Index는 데이터 변경 시마다 색인을 업데이트해야 하기 때문에, 대규모 데이터에서 색인 업데이트는 매우 오랜 시간이 걸릴 것으로 예상됨
- 토큰화된 데이터를 저장하기 때문에 메모리와 디스크 공간을 많이 차지함. 데이터가 많아질수록 디스크 I/O 및 스토리지 비용이 상승할 것으로 예상됨
- Full-Text Index는 단일 서버 내에서만 작동하므로, 분산 처리 기능을 지원하지 않는다고 함
이러한 문제들로 봐서는… 고도화된 검색 요구사항이 주어지거나 대량의 데이터를 처리해야 할 경우, 캐싱 전략을 도입하거나 ElasticSearch와 같은 전문 검색 엔진으로 전환해야 할 것으로 생각됩니다.
