
Chapter 06 - SQL 기본
SELECT문의 형식과 사용법
ORDER BY
결과물에 대해 영양을 미치지는 않지만, 결과가 출력 되는 순서를 조절하는 구문
기본적으로 오름차순(ASCENFING)정렬
SELECT NAME, mDate FROM usertbl ORDER BY mdate ASC;내림차순(DESCENFING)로 정렬 열 이름 뒤에 DESC 적어줄 것
SELECT NAME, mDate FROM usertbl ORDER BY mdate DESC;- 중복된 것은 하나만 남기는 DISTINCT
중복된 것을 1개씩만 보여주면서 출력 해주는 구문
- 출력하는 개수를 제한하는 LIMIT
일부를 보기 위해 여러 건의 데이터를 출력하는 부담을 줄인다 주로 악성 쿼리문을 개선할 때 사용한다.
테이블을 복사하는 CREATE TABLE … SELECT
테이블을 복사해서 사용할 경우 주로 사용되며 지정된 일부 열만 테이블로 복사하는 것도 가능하다.
- GROUP BY
말 그대로 그룹으로 묶어주는 역할
집계 함수(Aggregate Function)함께 사용되며 읽기 좋게 하기 위해 별칭(Alias)사용
- GROUP BY와 함께 자주 사용되는 집계 함수
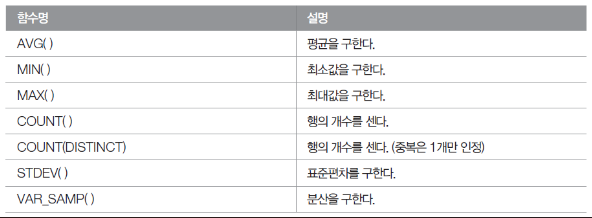
서브 쿼리와 함께 조합
GROUP BY 및 HAVING 그리고 집계 함수
- HAVING
WHERE와 비슷한 개념으로 조건 제한 집계 함수에 대해서 조건 제한하는 편리한 개념 HAVING절은 꼭 GROUP BY절 다음에 나와야 한다.
- ROLLUP
종합 또는 중간 합계가 필요할 경우 사용된다.
GROUP BY절과 함께 WITH ROLLUP문 사용
SQL의 분류
SQL문의 분률는 크게 DML, DDL, DCL로 분류한다.
- DML(Data Manipulation Language)
데이터 조작 언어
데이터를 조작(선택(SELECT), 삽입(INSERT), 수정(UPDATE), 삭제(DELETE))하는 데 사용되는 언어
- DDL(Data Definition Language)
데이터 정의 언어
데이터베이스, 테이블, 뷰, 인덱스 데이터베이스 객체를
생성(CREATE)/삭제(DELETE)/변경(ALTER)하는 역할
- DCL(Data Control Language)
데이터 제어 언어(사용자 제어에 가깝다)
사용자에게 어떤 권한을 부여하거나 빼앗을 때 주로 사용하는 구문
GRANT/REVOVKE/DENY 등이 이에 해당한다.
데이터의 삽입: INSERT
- INSERT문의 기본
테이블 이름 다음에 나오는 열 생략 가능
- 자동으로 증가하는 AUTO_INCREMENT
INSERT에서 해당 열이 없다고 생각하고 입력하며 1부터 증가하는 값을 자동 입력 해주며 적용할 열이 PRIMARY KEY 또는 UNIQUE일 때만 사용 가능하고 데이터 형식은 숫자만 사용 가능하다.
- 대량의 샘플 데이터 생성

다른 테이블의 데이터를 가져와 대량으로 입력하는 효과
데이터의 수정: UPDATE
기존에 입력되어 있는 값 변경하기 위해서는 UPDATE문을 다음과 같이 사용한다.

데이터의 삭제: DELETE FROM
DELETE는 행 단위로 삭제하는데, 형식은 다음과 같다.
DELETE FROM 테이블이름 WHERE 조건;Chapter 07 - SQL 고급
- MySQL에서 지원하는 데이터 형식의 종류
Data Type으로 표현되며 데이터 형식, 데이터형, 자료형, 데이터 타입등 다양하게 불린다.
MySQL에서 데이터 형식의 종류는 30개쯤 되지만 주로 쓰는 걸 중점 학습 해보자
데이터 형식
- 숫자 데이터 형식
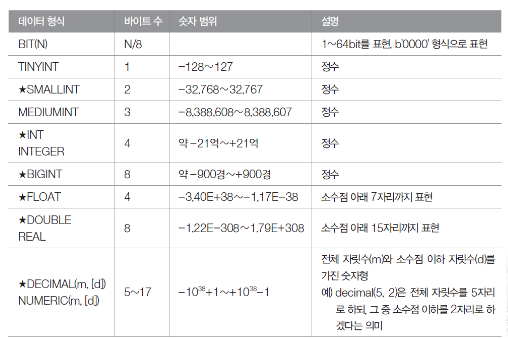
- 문자 데이터 형식
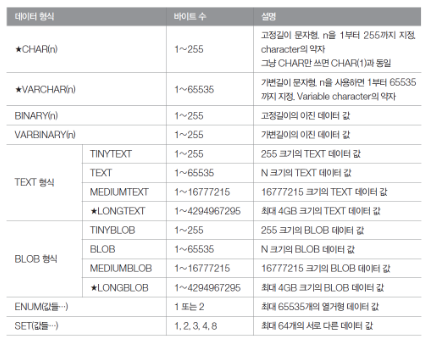
- 날짜와 시간 데이터 형식
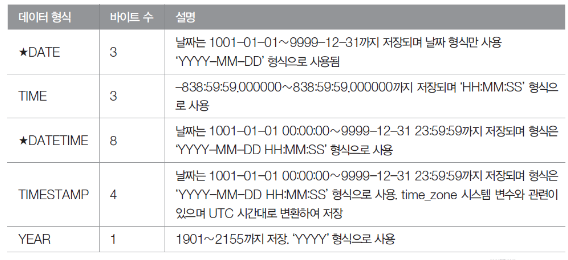
- 기타 데이터 형식

- LONGTEXT, LONGLOB
MySQL은 LOB(Large Object)를 저장하기 위해 위와 같은 데이터 형식을 지원 하는데
지원되는 데이터 크기는 약 4GB로 예를 들면 장편소설, 영화 동영상, 대본 전체가 들어갈 수 있으며 실무에서도 이러한 방식도 종종 사용되니 잘 기억해 놓으면 된다.
데이터 형식과 형 변환
Chapter 08 - 테이블과 뷰
제약 조건
- 제약 조건(Constraint)
데이터의 무결성을 지키기 위한 제한된 조건을 의미함
특정 데이터를 입력할 때 어떠한 조건을 만족했을 때에 입력되도록 제약
- 데이터 무결성을 위한 제약조건
- PRIMAY KEY 제약 조건(기본 키의 개념)
테이블에 존재하는 많은 행의 데이터를 구분하는 식별자며 중복되어서도 안되고 비어서도 안된다

기본 키 생성 방법
- FOREIGN KEY 제약 조건
두 테이블 사이의 관계 선언과 데이터의 무결성을 보장해 주는 역할
외래 키 관계를 설정하면 하나의 테이블이 다른 테이블에 의존하게 되며 기준 테이블의 데이터가 변경되면 외래 키로 연결된 테이블도 자동으로 적용 된다.
- UNIQUE 제약 조건
‘중복되지 않은 유일한 값’을 입력해야 하는 조건
여기서 PRIMARY KEY와 거의 비슷하나 차이점은 UNIQUE는 NULL값을 허용 한다
Ex) 회원 테이블에 Email 주소를 UNIQUE로 설정한다.
- DEFAULT 정의
값을 입력하지 않았을 때 자동으로 입력되는 기본 값을 정의하는 방법
- NULL값 허용
말 그대로의 의미로 NULL값은 ‘아무 것도 없다’라는 의미로 공백(’’)이나 0과 같은 값과는 다르다는 점에 주의해야한다.
테이블
- 테이블 삭제
테이블 삭제는 간단하게 다음과 같은 형식이다.
DROP TABLE 테이블 이름;주의할 사항은 외래 키로 묶여 있는 테이블은 삭제할 수가 없다.
예를 들어 구매 테이블이 아직 존재 하는데 회원 테이블을 삭제할 수 없다.
또, 여러 개의 테이블을 동시에 삭제 하려면 다음과 같은 형식이다.
DROP TABLE 테이블 이름1, 테이블 이름2, 테이블 이름3, ...;뷰
- 뷰의 작성과 활용
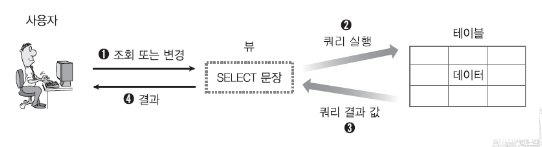
뷰의 작동 방식
- 뷰의 장점
- 보안에 도움 사용자가 중요한 정보에 바로 접근하지 못한다.
예시로 회원의 이름과 주소를 확인하는 작업을 시킨다면 개인정보(키, 가입 등)까지 모두 볼 수있을 것이다. 이를 방지하지 위해 테이블의 데이터를 전부 분할할 수도 있겠지만 데이터의 일관성과 관리가 복잡해져 배보다 배꼽이 커지는 결과를 낳을 수도 있다.
이런 경우 뷰를 생성해서 특정 테이블에는 접는하지 못하도록 권한을 제한하고 뷰에만 접근 권한을 준다면 쉽게 해결 된다.
- 복잡한 쿼리를 단순화 시켜 줄 수 있다.
긴 쿼리를 뷰로 작성해 뷰를 테이블처럼 사용한며 간단하게 테이블이라 생각하고 접근하면 편하다.
Chapter 09 - 인덱스
인덱스의 개념
<찾아보기>의 개념으로
인덱스는 ‘데이터를 좀 더 빠르게 찾을 수 있도록 해주는 도구’정도로 생각하자

인덱스의 장단점
- 장점
검색 속도가 무척 빨라질 수 있음(항상 그런 것은 아님)
결과적으로 해당 쿼리의 부하가 줄어 시스템 전체의 성능 향상으로 이어진다.
- 단점
인덱스가 데이터베이스 공간을 차지해 추가적인 공간 필요(대략 데이터베이스 크기의 10% 정도의 추가 공간 필요) 하며 처음에 인덱스를 생성하는데 시간 소요가 많으며
데이터의 변경 작업(INSERT, UPDATE, DELETE)가 자주 일어날 경우 오히려 성능이 나빠질 수도 있다.
인덱스의 종류와 자동 생성
인덱스의 종류
- 클러스터형 인덱스(Clustered Index)
‘영어 사전’과 같은 책 테이블 당 한 개만 지정 가능하며 인덱스로 지정한 열에 맞춰서 자동으로 정렬도 가능하다.
- 보조 인덱스(Sceondary Index)
책 뒤에<찾아보기>가 있는 일반 책 테이블당 여러 개도 생성 가능하다.
Chapter 10 - 스토어드 프로그램
스토어드 프로시저
트리거
GUI 데이터 입력 프로그램 실습
- ORM(Object Relational Mapping)
‘ORM(Object Relational Mapping)’은 ‘객체로 연결을 해준다’는 의미로, 어플리케이션과 데이터베이스 연결 시 SQL언어가 아닌 어플리케이션 개발 언어로 데이터베이스를 접근할 수 있게 해주는 툴 입니다.
ORM은 SQL문법 대신 어플리케이션의 개발 언어를 그대로 사용할 수 있게 함으로써, 개발 언어의 일관성과 가독성을 높여준다는 장점을 갖고 있습니다.
ORM 실습
from sqlalchemy.engine.url import URL
from sqlalchemy import create_engine
import pymysql
from tkinter import *
from tkinter import messagebox
mysql_db = {
"username" : "root",
"password" : "",
"host" : "localhost",
"port" : 3306
}
# print(URL(**mysql_db))
mysql = {"drivername": 'mysql', 'database': 'localhost'}
# print(URL(**mysql))
db_url = "mysql://localhost:3306/test"
engine = create_engine(db_url)
print(engine)
import sys
sys.exit()DDL, DML, DCL 부분은 중요하다 꼭 알고 넘어가자 정리 잘해놓자
