
Requests
Requests는 파이썬에서 HTTP 요청을 보내기 위한 간단하고 직관적인 라이브러리다. HTTP 요청을 보내고 응답을 처리하는 과정을 간단하게 만들고 Requests 사용하면 GET, POST, PUT, DELETE 등의 HTTP 요청을 손쉽게 보낼 수 있으며, 응답으로 돌아오는 데이터(HTML, JSON 등)을 편리하게 처리할 수 있다.
requests 패키지를 사용하여 서버에 HTTP request 보내기
import requests
from urllib.request import urlopen
url = 'http://www.google.com'
html = urlopen(url)
html.read()requests 실습 문제
[문제] 파이썬의 requests 모듈을 사용하여 구글의 HTML 코드를 출력하시오
url = 'http://www.google.com'
r = requests.get(url)변수를 선언하고 구글 주소를 담아서 GET 방식으로 요청 해서 가져왔다.
이제 출력을 해보자
r.status_code >>> 200
r.text >>> '<!doctype html><html itemscope=""... 이후 생략여기서 200은 요청 상태를 나타내는 메세지 코드다.
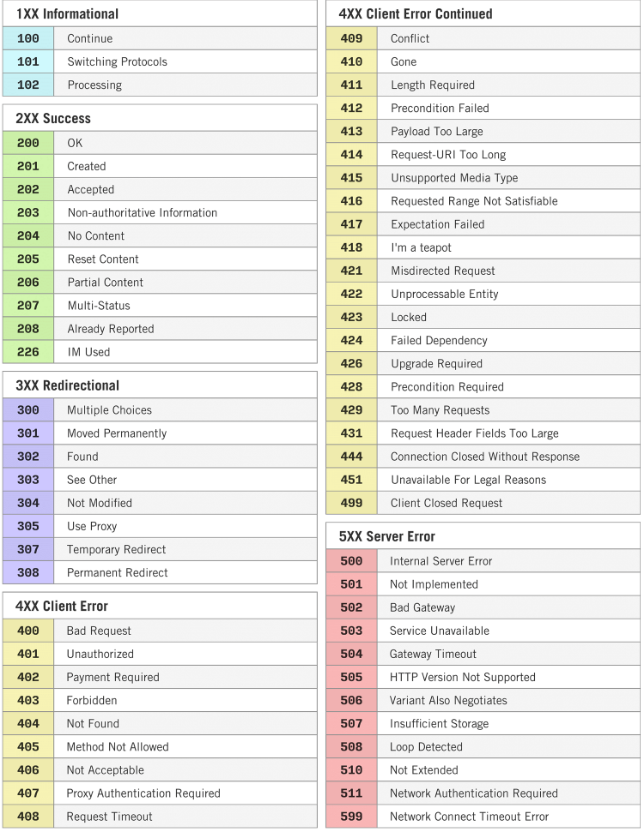
HTTP 상태 코드 종류 총정리
[TIP] 헤더(Headers)인자에 User-Agent 정보를 추가로 입력
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}
r = requests.get(url, headers=headers)헤더는 왜 쓰는데?
-
접근 허용
일부 웹사이트는 봇이나 스크립트의 접근을 제한하고, 실제 브라우저에서 오는 요청만 허용한다. 헤더에 브라우저 정보를 추가하면, 요청이 실제 브라우저에서 온 것처럼 보이게 할 수 있어 접근이 허용될 가능성이 높아진다.
-
크롤링 및 웹 스크래핑
웹 스크래핑 작업을 수행할 때, 더 안정적으로 데이터를 수집할 수 있습니다. 많은 서버가 스크래핑을 감지하고 차단하는데, 이러한 차단을 우회 할 수 있다.
[문제] 파이썬의 requests 모듈을 사용하여 구글 메인 페이지에 표시된 이미지를 출력하세요
import requests url = 'https://www.google.co.kr/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png' r = requests.get(url) r.status_code >>> 200역시 리퀘스트 불러와서 변수에 담아 주고 확인부터 해주었다.
from PIL import Image from io import BytesIO Image.open(BytesIO(r.content))

코드 실행 결과
‘PIL’는 파이썬에서 이미지를 처리하고 ‘IO’는 바이트 데이터를 다루기 위한 도구라고 생각하면 된다. 여기서 모듈에 대해 자세히 설명해 보겠다.
### PIL(Python Imaging Library) / Pillow
PIL은 파이썬에서 이미지를 다루는 라이브러이 중 하나로 지금은 업데이트가 멈추었지만 Pillow가 대신하고 있고 호환도 된다.
### IO 모듈
IO 모듈은 바이트 데이터를 메모리에서 파일처럼 다루는 객체를 제공하는데 이미지와 같은 바이너리 데이터를 직접 조작하게 해준다.
### [TIP] 이미지 저장하기
```python
import requests
url = 'https://www.google.co.kr/images/branding/googlelogo/1x/googlelogo_color_272x92dp.png'
r = requests.get(url)
# url에서 image 이름에 해당하는 부분('/'이후 가장 마지막) 추출
import os
image_name = os.path.basename(url)
image_name
# 이미지 저장을 위한 폴더 생성
image_folder = f"{os.getcwd()}/image"
if not os.path.isdir(image_folder):
os.mkdir(image_folder)
# 이미지 저장 경로 지정: image_folder/image_name
image_path = os.path.join(image_folder, image_name)
# 이미지 저장
image = open(image_path, 'wb')
image.write(r.content)
image.close()
```BeautifulSoup
beautifulsoup 설치
pip install BeautifulSoup4
from bs4 import BeautifulSoup기본 실습
filename = "index.html"
html = ""
with open (filename, 'r', encoding='UTF-8') as file:
for line in file:
html += line
html >>> '<!DOCTYPE html>\n<html lang="en">\n\n<head>\n\n <meta charset="utf-8">\n
--- 이후 생략from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
soup >>>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1, shrink-to-fit=no" name="viewport"/>
<meta content="" name="description"/>
<meta content="" name="author"/>
<title>Clean Blog - 곰돌이 Theme</title>
<!-- Bootstrap core CSS -->
<link href="vendor/bootstrap/css/bootstrap.min.css" rel="stylesheet"/>
<!-- Custom fonts for this template -->
<link href="vendor/fontawesome-free/css/all.min.css" rel="stylesheet" type="text/css"/>
<link href="https://fonts.googleapis.com/css?family=Lora:400,700,400italic,700italic" rel="stylesheet" type="text/css"/>
<link href="https://fonts.googleapis.com/css?family=Open+Sans:300italic,400italic,600italic,700italic,800italic,400,300,600,700,800" rel="stylesheet" type="text/css"/>
<!-- Custom styles for this template -->
<link href="css/clean-blog.min.css" rel="stylesheet"/>
</head>
<body>
<!-- Navigation -->
<nav class="navbar navbar-expand-lg navbar-light fixed-top" id="mainNav">
<div class="container">
<a class="navbar-brand" href="index.html">Home</a>
</div>
</nav>
<!-- Page Header -->
...
</div>
</div>
</footer>
</body>
</html>주요 메서드와 속성
BeautifulSoup객체인 soup뒤에 사용할 수 있는 주요 메서드와 속성들을 살펴보자
- .find()
- 특정 HTML 요소를 찾고 첫 번째 매칭되는 요소만 반환하고 뒤에 인자를 붙여 태그 이름과 선택적으로 속성들을 받을 수 있다.
soup.find('h2') >>>
<h2 class="post-title">
단풍구경가자~~
</h2>
soup.find('h2').text >>>
'\n 단풍구경가자~~\n
soup.find('h2').text.strip() >>>
'단풍구경가자~~'- .find_all()
- 특정 HTML 요소를 모두 찾아 리스트로 반환하고 뒤에 인자로 태그 이름과 선택적으로 속성 받을 수 있다.
soup.find_all('h2') >>>
[<h2 class="post-title">
단풍구경가자~~
</h2>,
<h2 class="post-title">
다이어트 시작!
</h2>,
<h2 class="post-title">
꽃놀이간다!
</h2>,
<h2 class="post-title">
내 꿀은 누가 다 먹었나?
</h2>]
title_list = soup.find_all('h2')
for title in title_list:
print(title.text.strip()) >>>
단풍구경가자~~
다이어트 시작!
꽃놀이간다!
내 꿀은 누가 다 먹었나?
date_list = soup.find_all('p')
for date in date_list:
print(date.text.strip()) >>>
September 24, 2021
June 18, 2021
March 24, 2021
July 8, 2020
Copyright © My Website 2021
date_list = soup.find_all('p', {'class': 'post-meta'})
date_list >>>
[<p class="post-meta">September 24, 2021</p>,
<p class="post-meta">June 18, 2021</p>,
<p class="post-meta">March 24, 2021</p>,
<p class="post-meta">July 8, 2020</p>]
for date in date_list:
print(date.text.strip()) >>>
September 24, 2021
June 18, 2021
March 24, 2021
July 8, 2020import pandas as pd
title_list = []
subtitle_list = []
date_list = []
#1. 포스트 리스트
post_list = soup.find_all('div', {'class': 'post-preview'})
#2. 제목, 소제목, 날짜 리스트
for post in post_list:
title = post.find('h2', {'class' : 'post-title'}).text.strip()
subtitle = post.find('h3', {'class' : 'post-subtitle'}).text.strip()
date = post.find('p', {'class' : 'post-meta'}).text.strip()
title_list.append(title)
subtitle_list.append(subtitle)
date_list.append(date)
#3. 데이터프레임 만들기
df = pd.DataFrame({'title': title_list, 'subtitle': subtitle_list, 'date': date_list})
df >>>

여기서 pd.DataFrame은 마치 엑셀처럼 만들어 주는 기능이다.
[TIP] CSS Selector를 활용한 태그 선택
soup.select('a > h2') # soup.select('a h2') 로 작성해도 동일하게 동작함
>>>
[<h2 class="post-title">
단풍구경가자~~
</h2>,
<h2 class="post-title">
다이어트 시작!
</h2>,
<h2 class="post-title">
꽃놀이간다!
</h2>,
<h2 class="post-title">
내 꿀은 누가 다 먹었나?
</h2>]soup.select('body > div > div > div > div:nth-child(1) > a > h2') >>>
[<h2 class="post-title">
단풍구경가자~~
</h2>]이렇게 .select()를 사용하면 리스트로 반환을 해준다.
BeautifulSoup 실습 문제 - 쇼핑몰 가격 데이터
[문제] 상품 정보가 포함된 하나의 페이지를 파싱하여 상품 정보가 포함된 데이터 프레임을 생성하시오
from bs4 import BeautifulSoup
import requests
import pandas as pd
# http://www.neweracapkorea.com/shop/shopbrand.html?xcode=031&mcode=002&type=Y&gf_ref=Yz1vU0FlS3M=
base_url = "http://www.neweracapkorea.com"
cap_total_url = "/shop/shopbrand.html?xcode=031&mcode=002&type=Y&gf_ref=Yz1vU0FlS3M="
base_url + cap_total_url >>>
'http://www.neweracapkorea.com/shop/shopbrand.html?xcode=031&mcode=002&type=Y&gf_ref=Yz1vU0FlS3M='pass
실습 예제 주소
에 접속 - F12(개발자 도구) 까지 들어와서
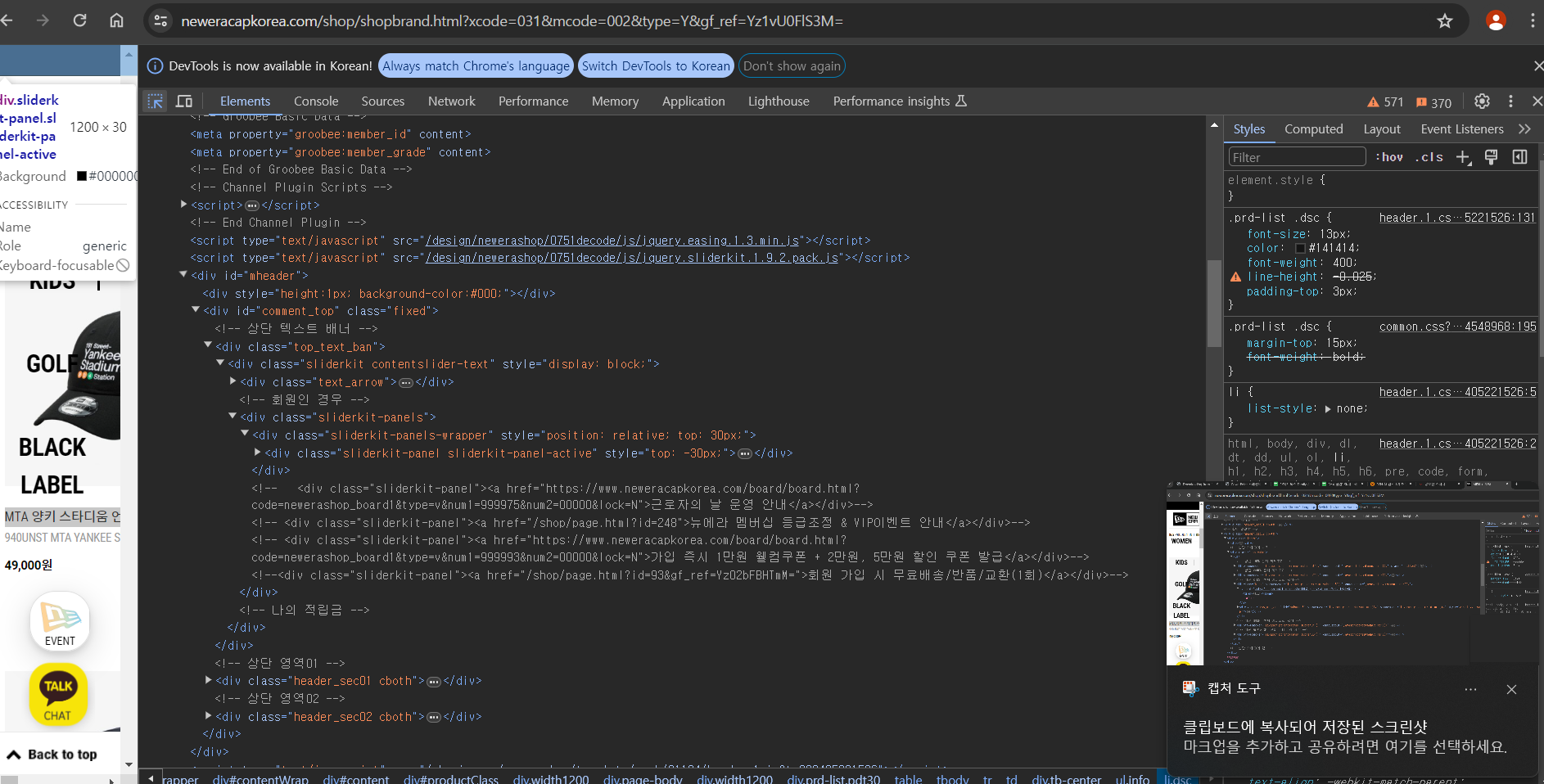
왼쪽 상단에 Selector를 누르고 내가 가져오고 싶은 데이터를 눌러주면 알아서 위치까지 이동 해준다
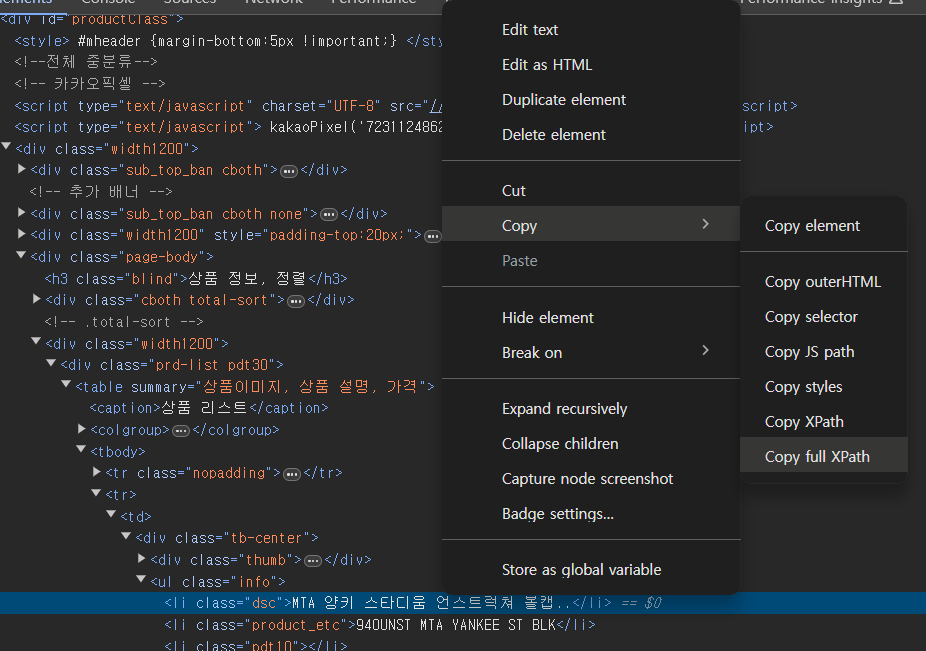
예제에서 모자의 이름이 있는걸 Selct 하고 오른쪽 클릭으로 Copy - Copy 하고 싶은 주소를 하면 된다.
