
Elasticsearch는 텍스트, 숫자, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 오픈 소스 검색 및 분산 엔진입니다. 전문검색엔진 (Full-text search engine)으로 개발되었으나 단순히 검색엔진을 넘어 보안, 로그분석, 전문분석 등 다양한 영역에서 중요한 역할을 하고 있는 Elasticsearch에 대해 간단히 소개하겠습니다.
기업협업 Project로 SCM Admin Tool의 백엔드를 개발하며, 필수적인 제품 및 생산관리 API 구현을 어느정도 마치게 되었습니다. 대표님과 Office hour를 통해 피드백을 받던 중 검색 기능은 보통 Elasticsearch로 구현하지만 활용하는 것이 어려울 수 있기에 단순 Query로 구현해도 된다고 하셨습니다. 마침 앞으로의 개발 방향성에 대해 Excel Data Input과 Jenkins를 활용한 CI/CD 개발환경 구축 등을 고민하고 있었고, 논의 결과 Elasticsearch를 활용하여 검색 기능을 구현해보기로 했습니다.
Overview
Elasticsearch는 현재는 세상에서 가장 인기가 있는 오픈소스 검색엔진으로 수많은 개인 개발자, 기업 그리고 공공기관들로부터 사랑을 받고 있습니다. 간단한 REST API, 분산형 특징, 속도, 확장성으로 유명한 Elasticsearch는 데이터 수집, 보강, 저장, 분석, 시각화를 위한 무료 개방형 도구 모음인 Elastic Stack의 핵심 구성 요소입니다. 보통 ELK Stack(Elasticsearch, Logstash, Kibana)이라고 하는 Elastic Stack에는 이제 데이터를 Elasticsearch로 전송하기 위한 경량의 다양한 데이터 수집 에이전트인 Beats가 포함되어 있습니다.
ELK Stack
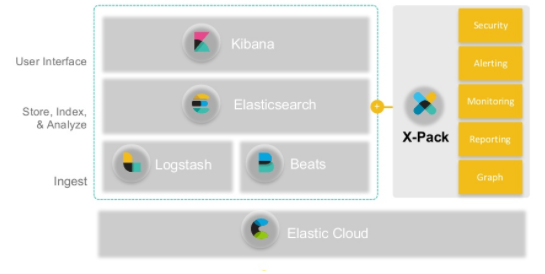
Elasticsearch는 Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진입니다. Elasticsearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있게 되었으며, 방대한 양의 데이터를 신속하게, NRT(Near Real Time)으로 저장, 검색, 분석할 수 있습니다. 위에서 설명한 바와 같이 Elasticsearch는 검색을 위해 단독으로 사용되기도 하지만, ELK Stack으로 사용되기도 합니다.
단독 프로젝트인 Logstash와 Kibana와 함께 사용되며 ELK Stack으로 불려왔으나, 2013년 두 프로젝트를 정식으로 흡수하여 ELK Stack 대신 제품명을 Elastic Stack이라고 정식 명명하며 모니터링, 클라우드 서비스, 머신러닝 등의 기능을 계속해서 개발, 확장 해 나가고 있습니다.
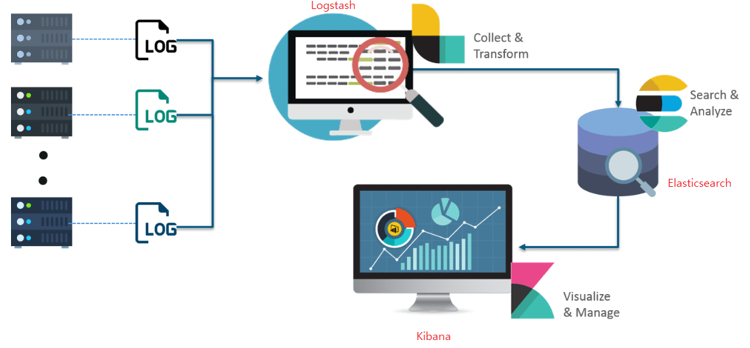
Logstash
Logstash는 원래 Elasticsearch와 별개로 다양한 데이터 수집과 저장을 위해 개발된 프로젝트였습니다. 기존의 Elasticsearch는 데이터의 색인, 검색 기능만을 제공했으나 Logstash가 Elasticsearch의 입력수단으로 사용되기 시작하면서 통합되었습니다. Logstash가 처리하는 Data Flow는 크게 세 단계로 볼 수 있습니다.
입력(Inputs) ➡️ 필터(Filters) ➡️ 출력(Outputs)
입력 기능에서 Beats, RDBMS 등 다양한 데이터 저장소로부터 데이터를 입력 받고 필터 기능을 통해 데이터를 확장, 변경, 필터링 및 삭제 등의 처리를 통해 가공을 합니다. 그 후 출력 기능을 통해 ES, Email, Kafka와 같은 다양한 데이터 저장소로 데이터를 전송하게 됩니다.
😱 우리가 Elasticsearch를 이용해 구현할 기능은 단순검색기능으로 모니터링, 머신러닝 등의 복잡한 기능은 처리하지 않기 때문에 Logstash를 활용해 이미 존재하는 RDBMS(MariaDB)의 Data를 알맞게 변환하여 ES에 제공하는 것이 핵심입니다!
Elasticsearch
Elasticsearch는 기본적으로 모든 데이터를 색인(indexing)하여 저장하고 검색, 집계 등을 수행하며 결과를 클라이언트 또는 다른 프로그램으로 전달하여 동작하게 합니다. 뛰어난 검색 능력과 대규모 분산 시스템을 구축하는 다양한 기능을 제공하지만 설치 과정과 사용방법은 비교적 쉽고(..?) 간편하다고 합니다.. ES의 특징은 다음과 같습니다.
오픈소스
Elasticsearch Github을 통해 소스코드를 확인할 수 있고, 또한 기여도 가능합니다. Lucene이 Java로 만들어졌기에 ES도 마찬가지로 Java로 코딩되어있습니다. 따라서 반드시 Java를 설치해주어야 합니다..
실시간 분석(NRT)
Elasticsearch의 가장 큰 특징 중 하나로, Hadoop이라는 배치 기반 분산 시스템과 달리 ES 클러스터가 실행되고 있는 동안에는 계속해서 데이터가 입력 - 색인(indexing)되고, 동시에 실시간에 가까운 속도(Near Real-Time)로 색인된 데이터의 검색, 집계가 가능합니다.
전문검색엔진 (Full-text search engine)
Lucene은 기본적으로 역파일 색인(inverted file index)라는 구조로 데이터를 저장하고, Lucene을 사용하고 있는 Elasticsearch도 동일한 방식으로 저장하여 가공된 텍스트를 검색합니다. 이러한 특성을 Full-Text Search라고 하며, Elasticsearch의 검색이 빠른 이유가 바로 Inverted Index에 있습니다.

Index는 책에서 맨 앞에서 볼 수 있는 목차라고 할 수 있고, Inverted Index는 책 맨 뒤에서 키워드마다 찾아볼 수 있도록 도와주는 찾아보기 기능이라고 할 수 있습니다. Index를 사용한다면 앞에서부터 순차적으로 키워드를 찾아가겠지만, Inverted Index는 Text를 Parsing한 키워드에 대해 indexing하기 때문에 훨씬 빠른 성능을 가져옵니다.
Elasticsearch에서 Query나 반환되는 결과는 모두 JSON 형식으로 전달되기 때문에, 사전에 입력할 데이터를 JSON 형태로 가공하는 과정이 필요합니다. 물론 이 과정은 Logstash가 변환을 지원해줍니다!
RESTFul API
Elasticsearch는 REST API를 기본으로 지원하며 모든 데이터 조회, 입력 삭제를 HTTP 프로토콜을 통해 Rest API로 처리합니다.
Kibana
Elasticsearch는 RESTFul하고, JSON 형식 Data로 통신하기 때문에 HTTP Protocol을 이용해 어떤 클라이언트와도 손쉽게 연동이 가능합니다. 따라서 개발자들이 ES와 연동되는 다양한 시각화 도구를 개발하였고, 그 중 가장 널리 쓰이는 것이 바로 Kibana입니다.
Kibana는 검색과 Aggregation의 집계 기능을 이용해 Elasticsearch로 부터 문서, 집계 결과 등을 불러와 웹 도구로 시각화 및 모니터링을 합니다. Discover, Visualize, Dashboard 3개의 기본 메뉴와 다양한 App 들로 구성되어 있고, 플러그인을 통해 App의 설치가 가능합니다.
TIL
처음 대표님이 Elasticsearch에 언급할 때, 구현하기 좀 어려울거라고 하시면서 잘 안되면 4자 이상 Text로 Query 검색하는 기능을 구현하라고 하셨습니다. 당시에는 ES가 단순히 Module이나 Library정도라고 여기고 금방할 것 같다고 생각했는데, 막상 Elasticsearch에 대해 알아보니 오픈소스 검색엔진이었습니다..
추석연휴에 돌입할 때 ES를 하기로 마음먹고 조금씩 알아봤는데, 보면 볼수록 정말 양이 방대하고 실제로 NestJS Project에 적용하려면 Elasticsearch Architecture와 Logstash에 대해 제대로 이해해야 가능하다고 생각했습니다. 아무리 봐도 소귀에 경읽는 것처럼 개념이 이해가 잘 안되고, NestJS를 처음 접했을때보다 훨씬 막막했습니다.
그래도 꾸준히 공식문서를 읽고, 직접 설치하고 부딪혀가며 하다보니 지금은 DB Data를 Logstash로 변환하여 ES로 전송하고, NestJS Project에서 아주 간단한 데이터 처리는 가능한 정도가 되었습니다. 아직 Logstash Option과 Mapping, Query DSL 활용을 못했고 실제로 배포하기 위해서 Docker Compose까지 고려해야 되기에 갈길이 멀지만 기업협업이 끝날때까지 제대로 Elasticsearch 구현이 가능하도록 노력하려 합니다.
다음 블로그는 Elasticsearch 설치 및 간단한 실행과 Logstash로 Elasticsearch Mysql 동기화하는 것을 작성해보겠습니다.
