
Elasticserach는 모든 유형의 데이터에 대한 수집, 분석 및 시각화를 위한 도구로서 머신러닝, 애플리케이션 모니터링, 보안 분석 등 다양한 분야에서 사용됩니다. 그러나 우리의 목적은 검색 기능 강화를 위해 Full-Text Search를 활용하는 것이므로, 방대한 Elasticsearch의 기능을 모두 살펴보지는 않고 필수적인 요소만 살펴보도록 하겠습니다.
현재 진행하고 있는 기업협업 프로젝트도 마찬가지이지만, 현업에서 대부분의 Data는 Mysql과 같은 Database에서 저장하고 처리되고 있습니다. 이러한 상황에서 점차적으로 Data의 검색, 집계, 분석 및 시각화 작업을 Database 자체에서 처리하는 것보다 Elasticsearch가 제공하는 강력한 기능을 활용하기 위해 Database에 저장된 데이터 중 검색 및 분석하고 싶은 Data만 Elasticsearch로 Indexing하고, Kibana를 활용해 분석 및 reporting을 시각화하는 것이 추세입니다.
이러한 시나리오상에서, 연결된 관계형 데이터베이스에 저장된 Data와 Elasticsearch로 Indexing한 Data의 동기화를 유지하는 것이 검색기능을 활용하기 위한 필수 요건입니다. Introduction에서 소개했듯이 이러한 Data를 가공하고 변환하여 Elasticsearch에 제공하는 것이 바로 Logstash입니다. 이번 블로그에서는 Logstash로 Mysql에서 검색기능을 위해 필요한 Data만 가져와 Elasticsearch의 Index와 동기화하는 과정을 살펴보겠습니다.
Install ELK Stack
Java 8
Elasticsearch는 Java 기반 오픈소스 분산엔진이기에 Java가 반드시 설치되어야 합니다. 다만 Elasticsearch 7.0 버전 부터는 기본 배포판에 open-jdk 가 포함되어 있어 따로 Java를 설치 해주지 않아도 된다고 합니다. 저는 처음에 이 사실을 모르고 brew package 관리자를 사용해 ELK Stack을 설치했기에 우선 오라클 홈페이지에서 Java를 설치했습니다. Java 9 이상 Version부터는 제대로 실행이 안된다고 하는 글들을 많이 보아 Java8 macOs 버젼을 설치했습니다.
Java 설치가 완료되면 /Library/Java/JavaVirtualMachines 아래 설치한 자바들이 존재하게 됩니다. Java 환경 변수 설정을 위해 bash_profile 파일을 작성하고 설치한 Java Version을 설정파일을 반영해줍니다.
vi ~/.bash_profile
#.bash_profile
JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_291.jdk/Contents/Home
export JAVA_HOME
export PATH=${PATH}:${JAVA_HOME}/bin
source ~/.bash_profile설정파일을 반영해주고 환경변수가 제대로 적용되었는지 확인해봅니다.

Elasticsearch
Elasticsearch Download 사이트 최신 Version(7.15.0)을 다운받아 압축을 풀고 설치해줍니다.
다운로드한 파일의 압축을 풀었다면 Elasticsearch의 실행이 바로 가능합니다. 압축을 푼 경로에서 터미널로 bin/elasticsearch를 실행하거나 bin 폴더로 이동하여 ./elasticsearch를 실행하면 다음과 같이 Elasticsearch가 실행되는 것을 확인할 수 있습니다.


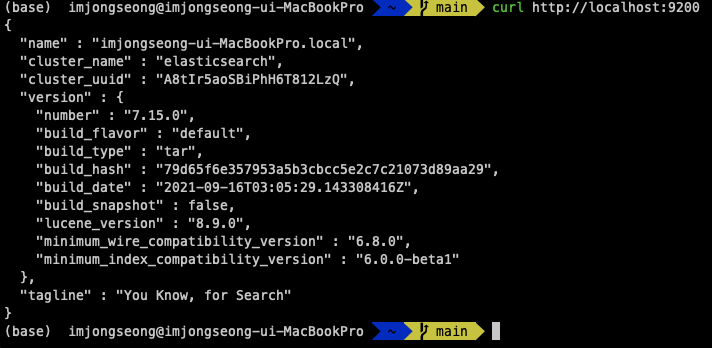
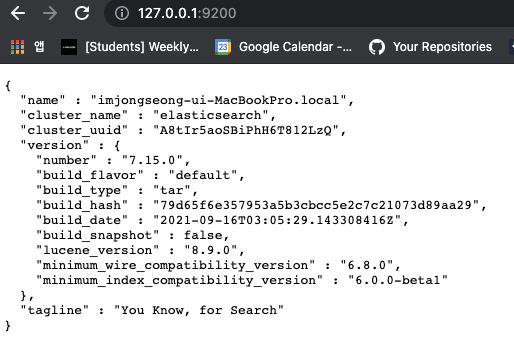
별도로 설정하지 않으면 처음 실행하는 Elasticsearch Port는 9200입니다. Elasticsearch는 curl 명령어로 REST Api를 사용할 수 있는데, curl 명령어로 현재 실행중인 엘라스틱서치 프로세스의 정보를 조회해봅시다. 물론 웹브라우저 상에서도 확인할 수 있습니다.
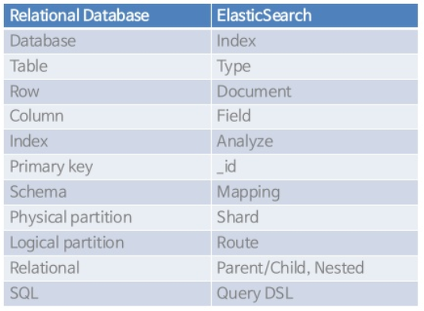
Elasticsearch vs RDBMS
우리가 흔히 사용하는 관계형 Database와 Elasticsearch는 매우 유사한 구조를 가지고 있습니다. 아래의 표로 간단하게 비교하고 다음에 자세히 다뤄보도록 하겠습니다.
Elasticsearch Architecture

Elasticsearch가 사용하는 대부분의 개념은 RDBMS에도 존재하는 개념들입니다. 위 사진이 Elasticsearch Architecture로 크게 Cluster와 Node, Index 그리고 Shard로 구성되어있습니다.
1) 클러스터(Cluseter)
클러스터란 Elasticsearch에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합입니다. 서로 다른 클러스터는 데이터의 접근, 교환을 할 수 없는 독립적인 시스템으로 유지되며, 여러 대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러 개의 클러스터가 존재할수도 있습니다.
2) 노드(Node)
Elasticsearch를 구성하는 하나의 단위 프로세스를 의미합니다. 그 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있습니다.
- Master Node는 Index의 생성 및 삭제, Cluster Node의 추적과 관리등 Cluster를 제어하는 노드입니다.
- Data Node는 Data와 관련된 CRUD 작업과 관련있는 노드로, CPU와 메모리 등 자원을 많이 소모하므로 모니터링이 필요합니다.
- Inget Node는 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할을 합니다
3) 인덱스(Index) / 샤드(Shard)
Elasticsearch에서 Index는 RDBMS에서 Database와 대응하는 개념입니다. Sharding은 데이터를 분산하여 저장하는 방법을 의미하는데, 기본적으로 1개가 존재하며 검색 성능 향상을 위해 Cluster의 샤드 개수를 조정하기도 합니다.
Elasticsearch 환경설정
Elasticsearch 는 각 노드 별로 실행될 설정들을 적용함으로써 노드들의 역할을 나누거나 클러스터의 속성을 결정하게 됩니다. Elasticsearch 의 실행 환경을 설정하는 방법은 크게 Config 경로의 파일을 수정하거나 시작 명령으로 설정하는 2가지 방법이 존재합니다.
jvm.options 파일은 Java 힙메모리 및 환경변수를 수정하고 변경할 수 있습니다. 대부분의 Elasticsearch 환경설정은 elasticsearch.yml에서 설정합니다. YAML 문법으로 설정하기에 옵션을 설정할 경우 들여쓰기에 유의해야 합니다. elasticsearch.yml을 통해 클러스터명, 노드명, 색인된 데이터를 저장하는 경로, 포트번호 등 다양한 옵션을 설정해줄 수 있습니다.
현 단계에서는 아직 옵션을 따로 손보지 않고 Dafult 설정으로 Elasticsearch를 사용하도록 하겠습니다.
Logstash
Logstash는 엘라스틱 스택에서 일종의 ETL(Extract, Transform an Load)의 역할을 담당하는 컴포넌트입니다. 크게 인풋(Input), 필터(Filter), 아웃풋(Output)의 세 가지 플러그인 구조로 되어 있어서 데이터 처리를 위한 파이프라인을 계속 연결해서 처리한 다음에 최종적으로 아웃풋을 엘라스틱 서치로 지정해서 인덱싱하는 구조입니다.
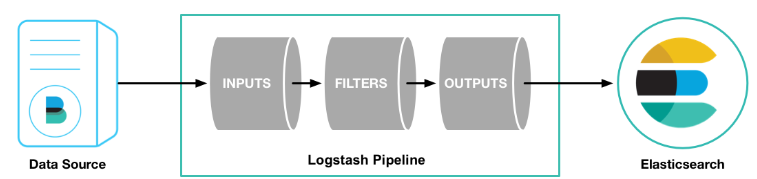
Logstash Download 사이트에서 설치된 Elasticsearch Version에 맞는 Logstash를 다운받아 설치합니다.
Start Logstash
Logstash를 기동하기 전에는 conf 파일을 생성하여 Input, Filter, Output 설정을 해줘야 합니다. Logstash 테스트를 하기 위해 기본적인 input, output만 설정하고 진행해보겠습니다.

원하는 경로에 conf 파일을 생성하고, 아래의 명령어를 통해 Logstash를 실행해줍니다. 명령어를 실행하는 현재 경로는 Logstash를 설치한 파일입니다. 명령어 자체는 절대경로를 입력할 수 있지만 저는 상대경로로 실행해보았습니다.

정상적으로 Logstash가 실행되었음을 확인하기 위해 터미널에 Hello World!를 입력해보면 다음과 같이 Output이 출력되는 것을 확인할 수 있습니다.

이제 Elasticsearch와 Logstash를 설치했으니 Logstash를 이용하여 Mysql Database와 연동해보겠습니다!
Logstash - Mysql Synchronize
Data를 가져오기 위한 Database는 Mysql입니다. 제대로 연동이 되는지 테스트하기 위해 test4라는 Database를 생성하고 product Table에 아래와 같이 Data를 집어넣어 봤습니다. product_name, product_id, product_color 등의 Column이 존재합니다. 이제 Logstash 설정을 통해 Elasticsearch의 Index로 변환해보겠습니다.
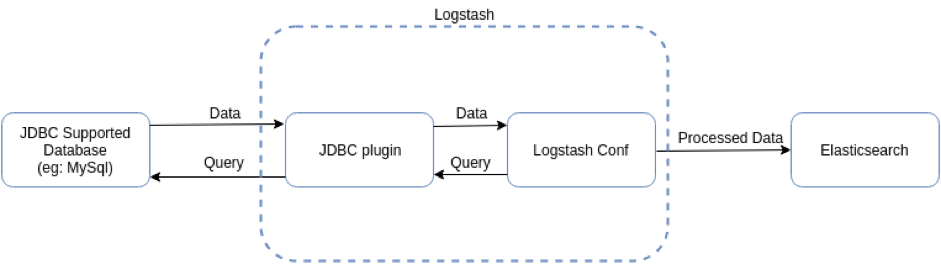
JDBC Input Plugin
JDBC Input Plugin은 Logstash의 많은 내장 인풋 플로그인중 하나입니다. Mysql처럼 기본적으로 JDBC Interface를 지원하는 모든 데이터베이스는 이 인풋 플러그인을 통해 Elasticsearch로 Indexing할 수 있습니다. 개념적으로 Logstash의 JDBC 인풋 플러그인은 주기적으로 MySQL을 폴링하는 루프를 실행합니다.
Logtstash는 크론 문법을 통해 주기적으로 데이터를 가져올 수 있고, 한 번만 실행시켜 데이터를 로딩하도록 설정할 수도 있습니다. Database에 원하는 JDBC Query를 던지고, Return한 결과에서 각 Row가 하나의 이벤트로 맵핑되며 Column이 Elasticsearch의 Field로 대응되는 형태로 Indexing합니다. 기본적인 Data Flow는 아래와 같습니다.
Logstash를 설치한 경로에서
./bin/logstash-plugin install logstash-input-jdbc명령어를 통해 JDBC Input Plugin을 설치합니다.
Mysql-Connector
JDBC Plugin을 설치한 후 자신이 사용하는 RDBMS의 Connector jar 라이브러리를 설치해야 합니다. Mysql 의 경우 Mysql Connector/J 라이브러리를 설치해줍니다. 마찬가지로 경로는 상관이 없지만 보통 lib 폴더에 넣어두는 편입니다. 저는 다양한 이슈로 Logstash Home 디렉토리에 이동해두고, mysql-connector-java-5.1.48-bin.jar를 설치했습니다.
Logstash.conf
Logstash Data Flow를 이해하고 Database에서 데이터를 가져오기 위해 Logstash Config 파일인 Logstash.conf를 작성해보겠습니다. 이 conf 파일은 위에서 설명했듯이 어디에 작성해도 상관없지만 실행할 때 경로를 정확히 입력해주어야 합니다. Logstash와 Mysql을 연동하기 위해 최소한의 설정만 하고, 다양한 Option에 대해서는 다음에 다뤄보도록 하겠습니다.
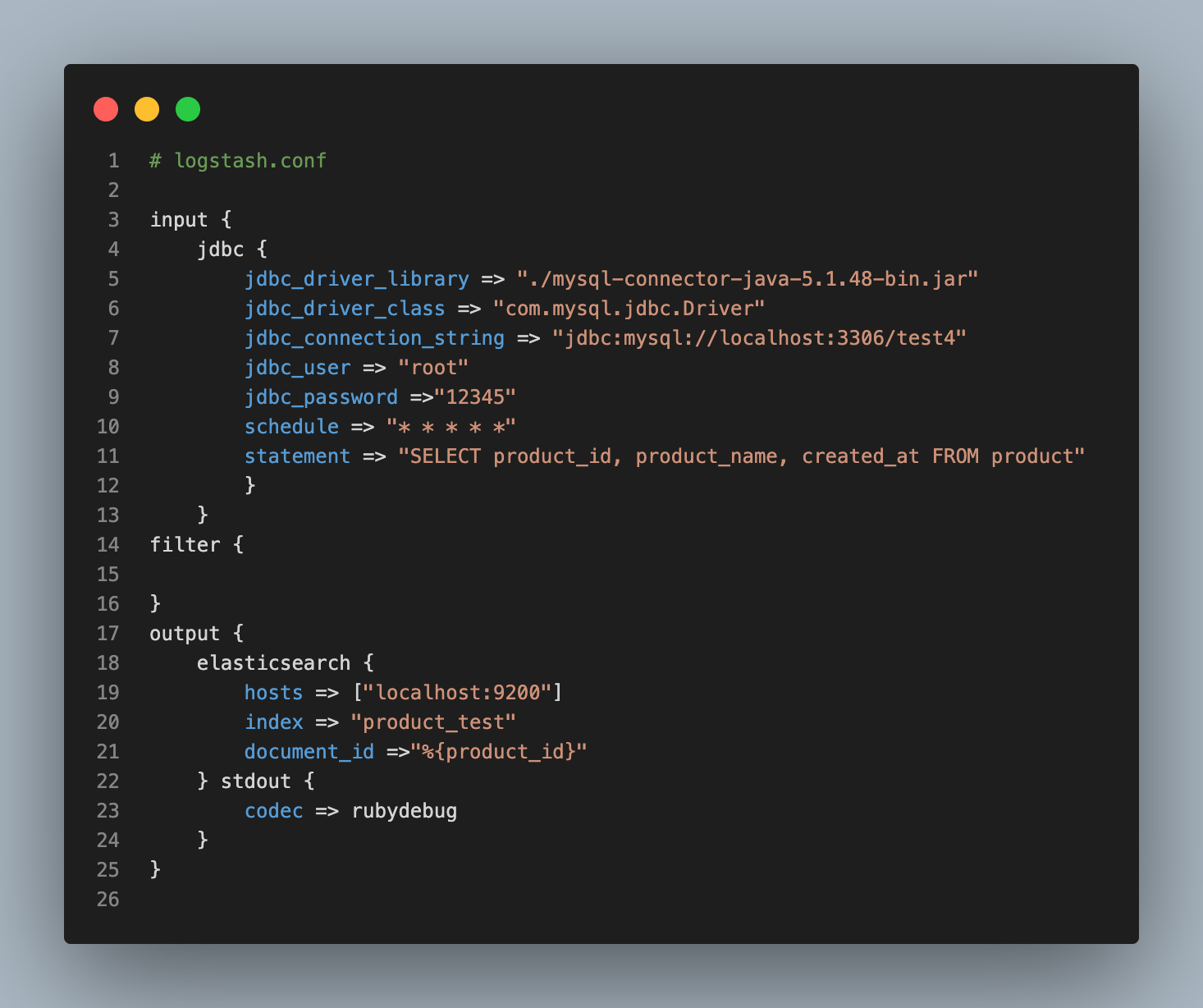
Input Option
- jdbc_driver_library : Mysql Connector jar 라이브러리가 설치된 경로를 지정해줍니다.
- jdbc_driver_class : 로드할 mysql 드라이버 클래스를 지정합니다.
- jdbc_connection_string : Data를 가져오기 위한 Mysql Database를 지정합니다.
- jdbc_user, password : Database의 user와 비밀번호를 지정합니다.
- schedule : Sql Query를 실행하는 주기를 지정합니다. 크론 문법에 따라 원하는 대로 지정할 수 있습니다. 이 예제에서는 매 분마다 주기적으로 실행하도록 되어있고, schedule을 설정하지 않으면 한 번만 실행됩니다.
- statement: 위 예시처럼 직접 Sql문을 지정할 수도 있지만, 보통 SQL문을 파일로 지정한 다음 파일을 읽어 실행할 수도 있습니다. 우리는
productTable의id,name,create_at만 Input으로 사용할 것입니다.
Output Option
- host: Elasticsearch의 호스트 주소를 설정합니다. 우리는 ES 설정을 건드리지 않았기에 기본값인 9200 포트로 설정합니다.
- index: Elasticsearch에서 생성할 index의 이름을 설정합니다. 이 Index는 RDBMS에서의 Database명이라고 생각하면 됩니다.
- document_id: ES에서 document는 RDBMS에서의 Row입니다. Input Database의 Primary Key를 지정해준다고 보시면 됩니다.
product_id로 설정해줍니다.
Start Logstash
Logstash 폴더에서 아래 명령어를 통해 Logstash를 실행합니다. 이제 Scheduler가 돌아가며 우리가 설정한 주기마다 반복하여 Mysql의 Database에 저장된 Data를 Elasticsearch의
product_testIndex로 넣어주게 됩니다.

실행결과, 터미널에서 다음과 같이 Output을 반환하는 시간과 결과값을 JSON 형태로 출력합니다. 아래는 Kibana의 DevTool에서 GET product_test/_search 명령어를 사용해 product_test Index가 가지고 있는 정보를 출력한 결과입니다. Kibana에 대해서 다음에 다뤄보도록 하겠습니다.
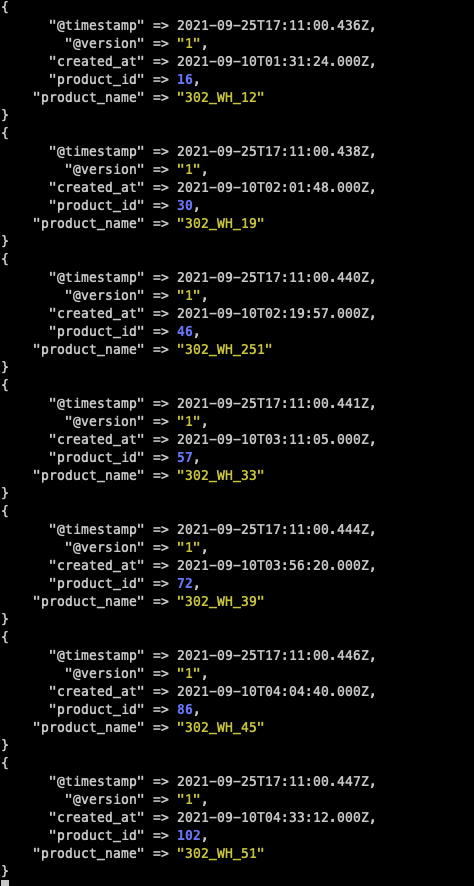
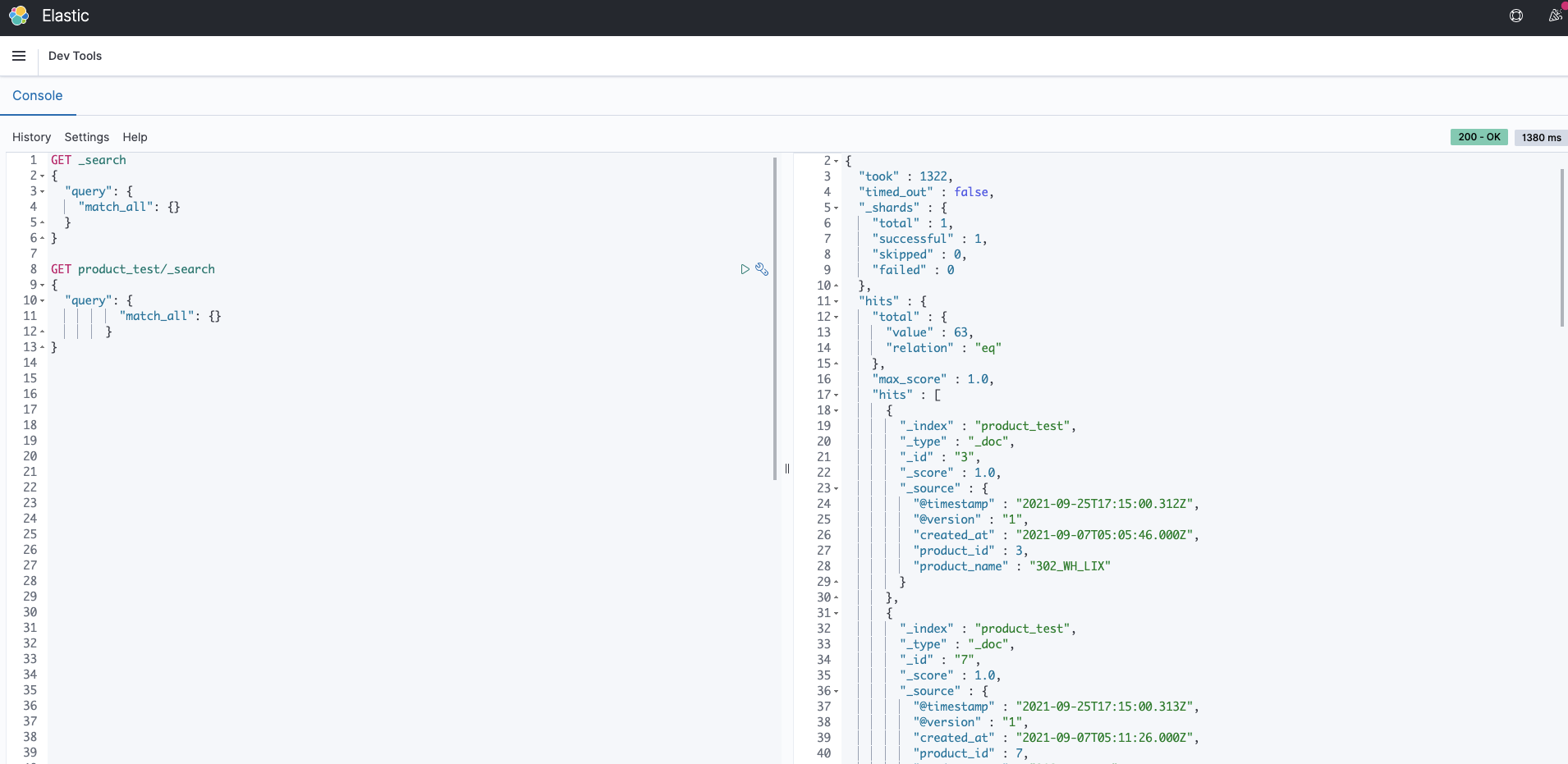
보는 바와 같이 Logstash를 사용해 Mysql의 Data를 Elasticsearch로 변환하여 입력하는 것을 확인할 수 있었습니다. 이번 예시는 정말 기본적인 설정만 하여 동기화하는 것만 확인했지만, Full Text Search 기능을 사용하기 위해서는 Elasticsearch의 Index 설정과 Mapping, 그리고 Query DSL을 활용해야 하고 Logstash의 Config 파일을 좀 더 정밀하게 작성해주어야 할 것입니다.
다음 블로그는 Kibana를 활용한 분석 및 시각화와 Logstash를 통해 처리하여 Elasticsearch로 전달한 Data를 어떻게 NestJS에서 연동하여 사용하는지 살펴보겠습니다.
참고자료
Elatsicsearch 입문하기
Elasticsearch Ebook
Logstash로 엘라스틱서치 Mysql 동기화하기
엘라스틱서치와 로그스태시로 Mysql에서 필요한 데이터만 가져오기
Logstash와 JDBC를 사용해 Elasticsearch와 관계형 데이터베이스의 동기화를 유지하는 방법
Elasticsearch Velog
로그스태시 설치하기
