
Logstash를 활용해 Mysql의 Data를 Elasticsearch로 전송하면서 색인과 검색에 활용할 Analyzer를 적용하는 Mapping을 설정했습니다. 이제 NestJS에서 Elasticsearch를 활용해 Full-Text Search 기능을 구현하는 법에 대해 알아보겠습니다.
Set up NestJS and Elasticsearch
우리는 이미 NestJS에서 사용하는 Data를 Indexing하여 Elasticsearch에서 Index로 작성하는 과정을 살펴봤습니다. 이제 NestJS에서 Elasticsearch를 연동하여 Index에 접근하고, 접근한 Index에 색인되어 있는 Data로 Search하는 Service를 작성해주면 됩니다.
먼저 NestJs에서 Elasticsearch를 사용하기 위해 Module을 Install합니다.
npm i --save @nestjs/elasticsearch @elastic/elasticsearch
이제 Search Module을 생성하여 Elasticsearch와 연동하기 위한 설정을 해줍니다.
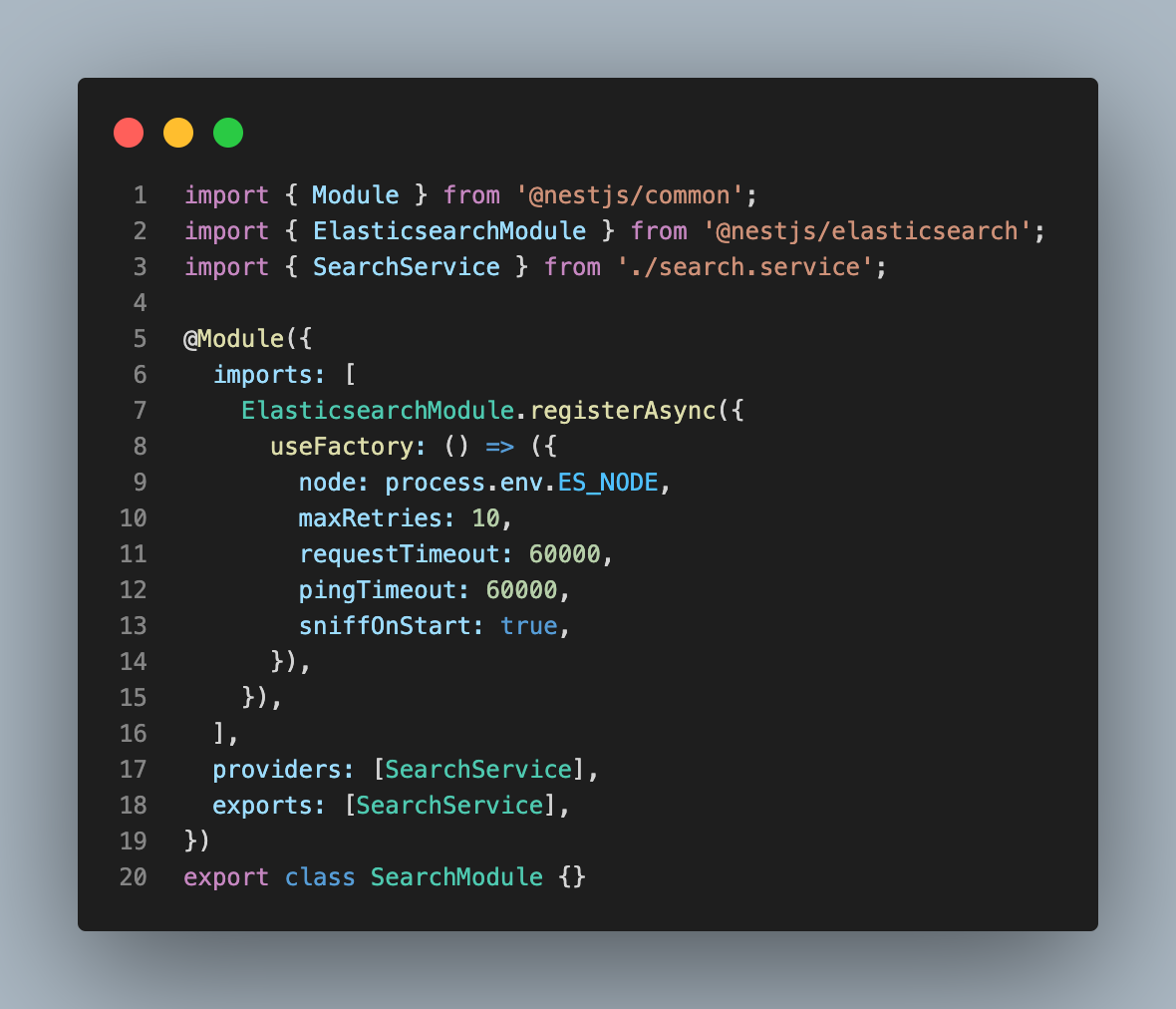
node는 Elasticsearch의 호스트 주소입니다. 별다른 설정 없이 Local에서 Elasticsearch를 실행했다면 node는 localhost:9200 입니다. 이제 search.service.ts에서 search 함수를 작성해보도록 하겠습니다.
Query DSL
Elasticsearch 는 검색을 위한 쿼리 기능을 제공합니다. 이런 데이터 시스템에서 제공하는 쿼리 기능을 Query DSL (Domain Specific Language) 이라고 이야기 하며 Elasticsearch 의 Query DSL 은 모두 json 형식으로 입력해야 합니다.
Search 함수를 작성하기에 앞서 먼저 Elasticsearch의 주요 쿼리들을 살펴보겠습니다.
match
match Query는 Full-Text Search에서 가장 일반적으로 사용되는 쿼리입니다.
GET my_index/_search
{
"query": {
"match": {
"message": "dog"
}
}
}위와 같이 message field에서 dog가 포함된 모든 문서를 검색합니다. 여러 개의 검색어를 집어넣는다면 default로 OR 조건으로 검색을 실행하여 검색어 별로 하나라도 포함된 모든 문서를 검색합니다.
검색에 사용되는 Text 또한 Analyzer의 영향을 받습니다. 예를 들어 mapping에서 별다른 설정을 해주지 않는다면 standard analyzer가 default로 작용하여
quick dog로 검색을 한다면quick과dog로 Term이 분리되어 각각의 검색어로 검색을 실행합니다.
match_phrase
match_phrase Query는 입력된 검색어와 정확히 일치하는 field를 검색합니다. 예를 들어 위의 예시에서 quick dog로 검색을 한다면 정확히 quick dog가 포함되어 있는 field만 결과로 반환합니다.
bool
본문 검색에서 여러 쿼리를 조합하기 위해 상위에 bool Query를 사용하고 그 안에 다른 쿼리를 넣는 식으로 사용합니다. must, must_not, should, filter의 4개 인자와 함께 사용합니다.
Should
bool 쿼리의 should는 검색 점수를 조정하기 위해 사용할 수 있습니다. should는 match_phrase 와 함께 유용하게 사용할 수 있습니다. 검색 결과 중에서 입력한 검색어와 전체 문장이 정확히 일치하는 결과에 가중치를 두어 사용자가 정확하게 원하는 높은 수준의 검색 결과를 제공할 수 있습니다.
Searchservice
이제 Query DSL을 바탕으로 Search 함수를 작성해보겠습니다.
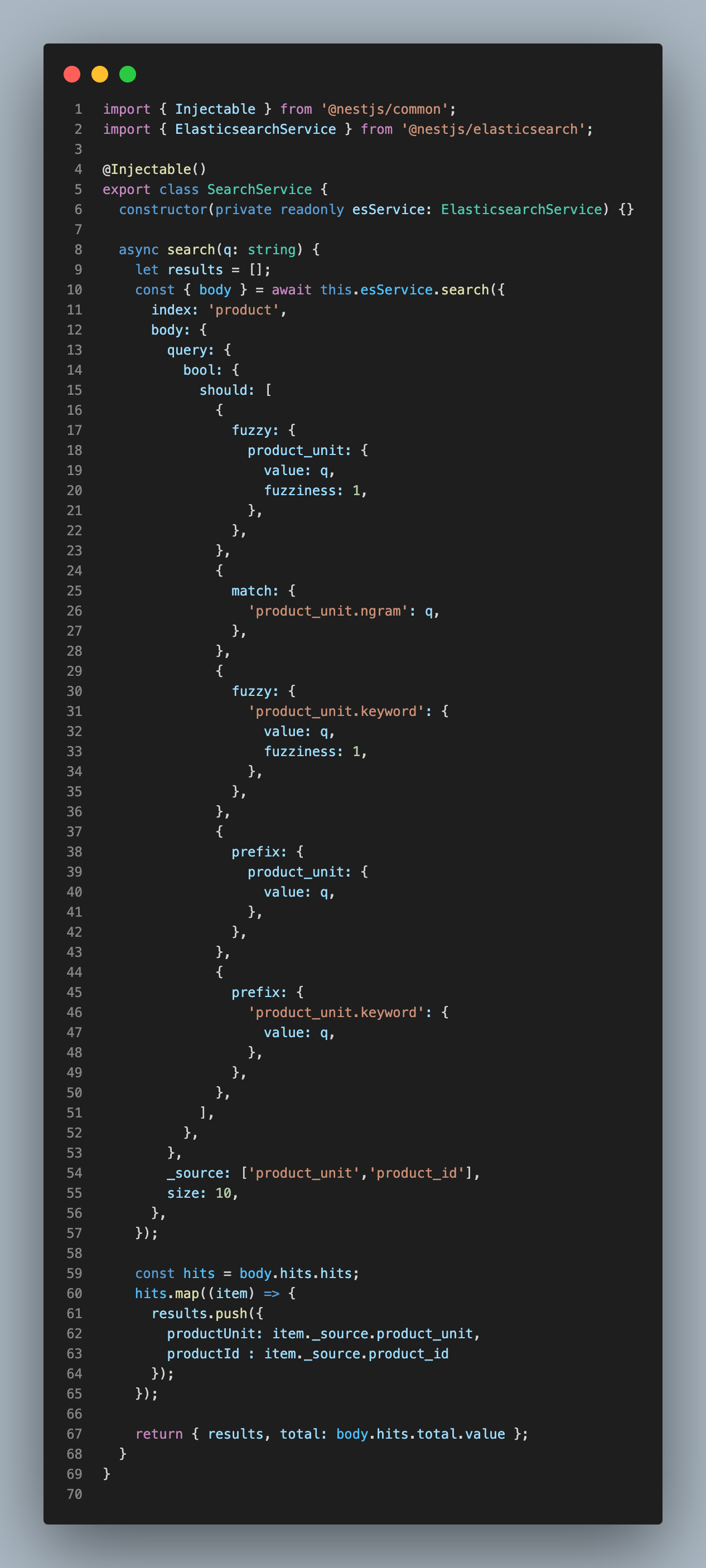
should Query를 사용해 Query 가중치를 두어 검색 결과의 신뢰성을 높일 수 있도록 했습니다. ngram field에 대해 match Query를 사용하고, fuzzy와 prefix의 사용으로 검색어에 근접하거나 검색어로 시작하는 Term에 대한 가중치를 높였습니다.
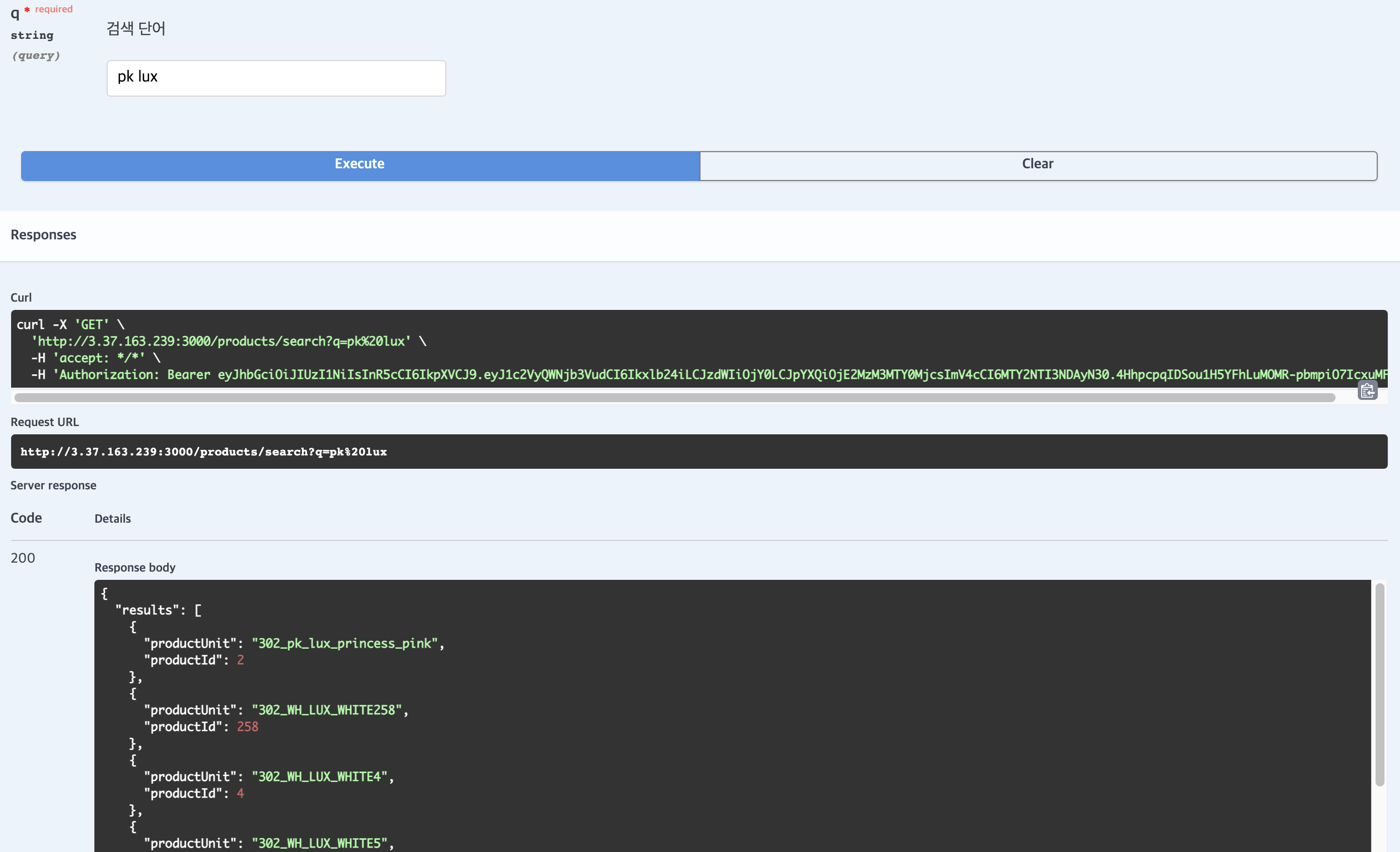
또한 검색 결과에 대해 _source는 product_unit과 product_id만 뽑아내어 {productUnit, productId} 형태의 객체로 이루어진 배열과 전체 검색 결과 개수를 반환할 수 있도록 했습니다. Swagger로 검색을 해보면 다음과 같이 신뢰있는 결과가 나타납니다.
Setup Docker For Project
지금까지 ELK Stack은 개별적으로 다운받아 설정을 하여 실행했습니다. 이제 Project 환경에서 배포해야 하기 때문에 개별적으로 관리하는 것보다 Docker Container를 활용해 ELK Stack과 NestJS를 관리해보겠습니다.
Setup ELK Stack
Docker와 Docker-compose가 설치된 Server에서 다음 Github Repository를 통해 ELK Stack을 Clone합니다. ELK Stack을 Docker Compose로 배포하기 간편하도록 만들어진 구조입니다.
git clone https://github.com/teichae/docker-elk
Clone한 ELK Stack 구조를 NestJS Project에서 사용합니다. Directory Tree는 다음과 같습니다.
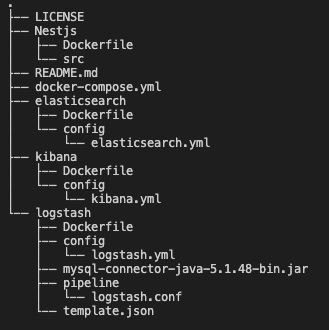
Docker Compose를 하기 위해 먼저 ELK Stack의 환경설정과 Dockerfile을 작성해주어야 합니다. Elasticsearch, Logstash, Kibana의 Config는 이 웹사이트를 참고하여 X-Pack 관련 내용만 주석처리 해줍니다.
Setup Logstash
Mapping을 위해 지난 블로그에서 작성했던 Template과 logstash.conf를 위의 트리 구조처럼 logstash 폴더 안에 작성해줍니다. Elasticsearch의 Host 주소는 이제 Localhost가 아니라 elasticsearch:9200으로 수정합니다.
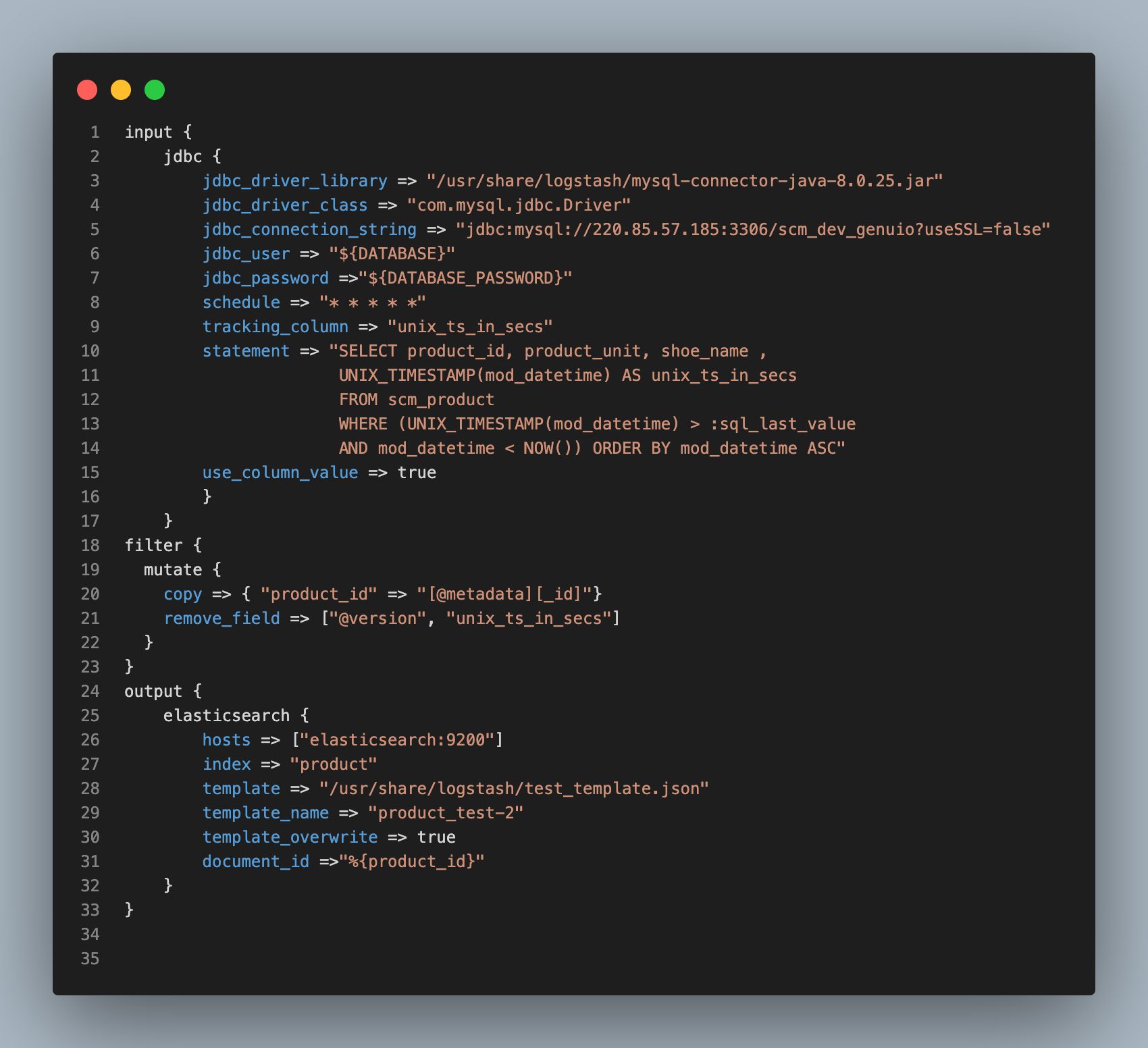
Logstash와 Mysql의 연동을 위한 MysqlConnector 또한 포함시킵니다. 이제 Logstash Dockerfile을 다음과 같이 수정하여 Logstash Container가 MysqlConnector, Template, logstash.conf를 카피하도록 합니다. Directory 경로를 정확하게 입력해주어야 에러가 나지 않습니다.
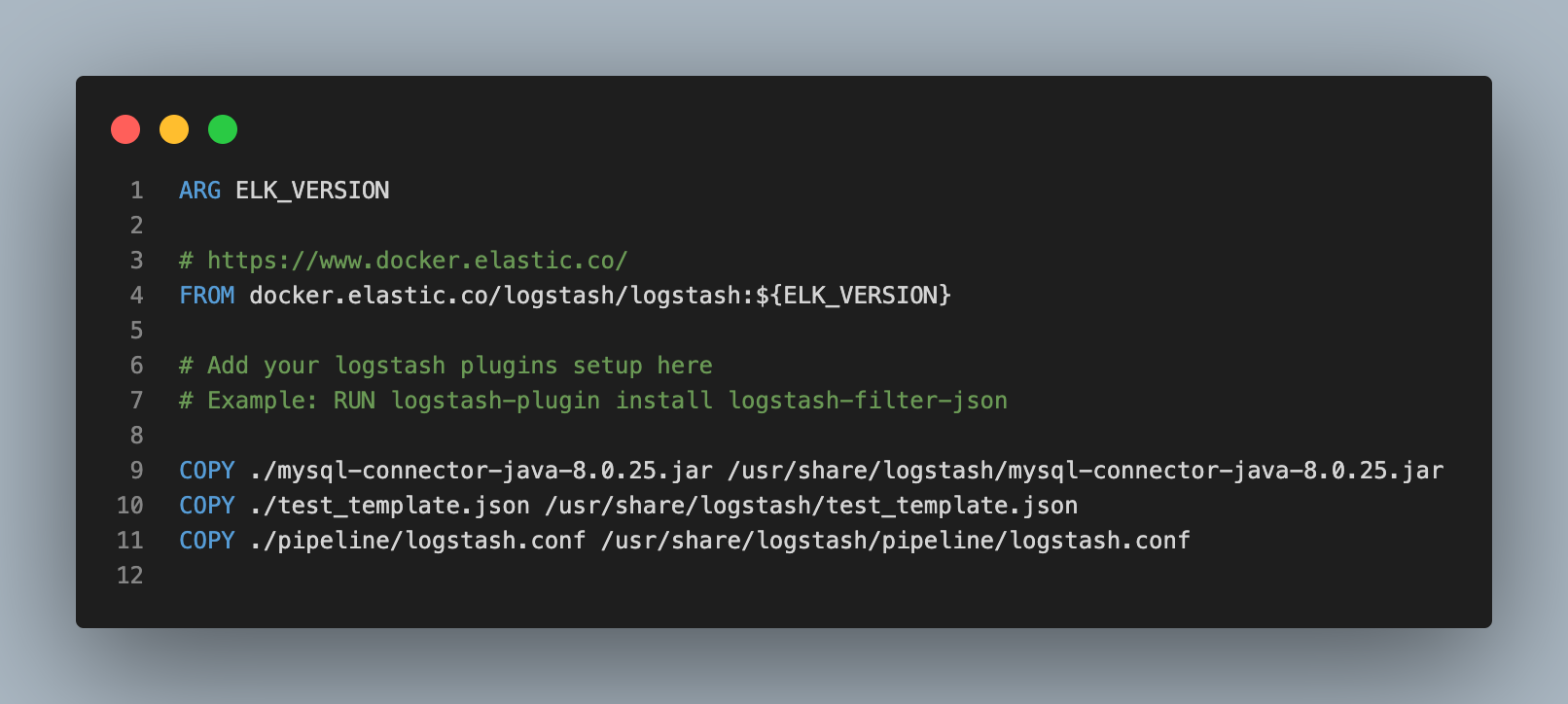
docker-compose.yml
이제 Docker Compose를 위한 yml 파일을 다음과 같이 작성해줍니다. 기본적으로 ELK Stack을 clone하여 생성된 docker-compose.yml에 NestJS API 내용을 추가하였습니다.
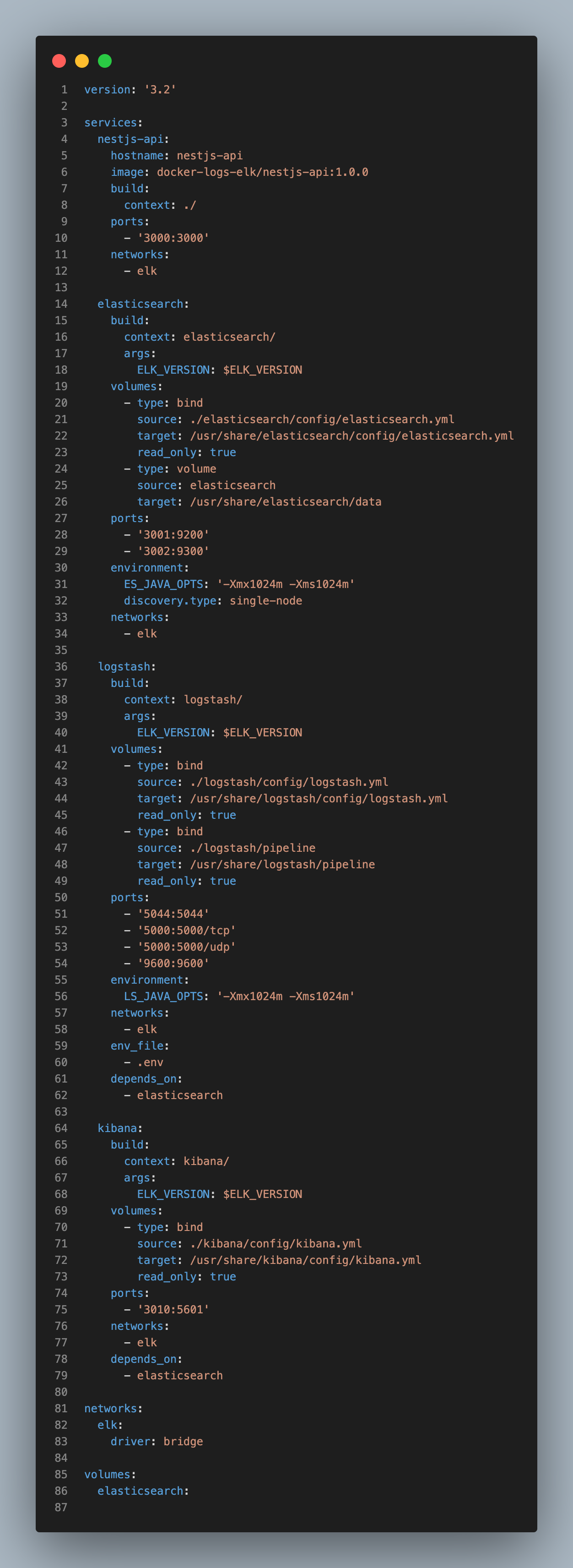
Docker로 배포할 AWS EC2 Instance의 포트가 3000~3010까지 오픈되어 있었기 때문에 Elasticsearch와 Kibana의 Host Port를 3001과 3010으로 변경해주었습니다. NestJS Project의 Dockerfile은 다음과 같습니다.
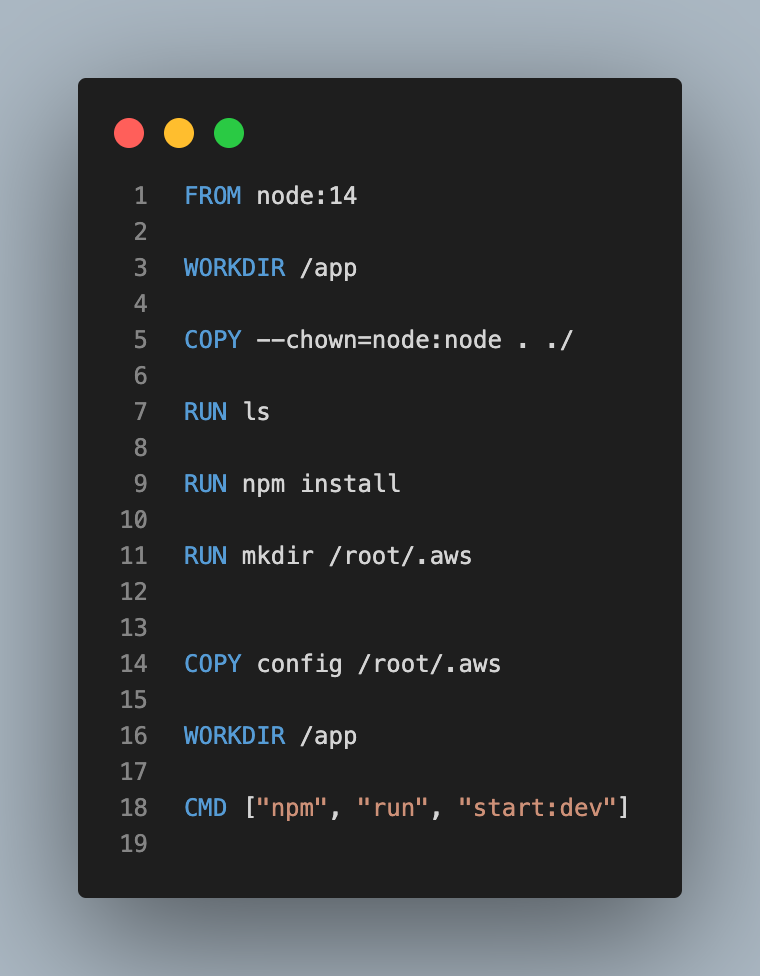
NestJS로만 Docker를 사용했을 경우와 다른 점은 COPY를 할 경우 --chown=node:node를 추가하여 권한을 부여했다는 점입니다. ELK Stack과 compose하기 때문에 권한을 부여하지 않으면 에러가 발생하여 Container Build 단계에서 에러가 발생합니다.
Docker Compose
이제 Docker로 배포하기 위한 환경설정과 Dockerfile 작성이 끝났으니 Docker Compose를 통해 서버를 배포할 수 있습니다!
# Docker 실행 $ docker-compose up # Background 실행 $ docker-compose up -d # Docker 중지 $ docker-compose down
참고자료
Docker-Compose를 이용하여 ELK Stack 시작하기
Autocomplete Search with NestJS and Elasticsearch
Elasticsearch 가이드북
