
Elasticsearch의 Index는 도큐먼트들이 모여 있는 논리적인 데이터의 집합입니다. Index는 하나의 노드에만 존재하지 않고 샤드 단위로 구분되어 여러 노드에 걸쳐 저장되어 데이터 무결성의 보장과 검색 성능의 향상을 실현합니다. 이번 블로그에서는 인덱스의 단위에서 이루어지는 설정들과 데이터 명세인 인덱스 매핑에 대해 알아보도록 하겠습니다.
Settings & Mappings
모든 Index는 settings와 mapping의 두 개의 정보 단위를 가지고 있습니다. Index를 처음 처음 생성한 뒤 GET Index명으로 조회하면 Index의 초기 settings와 mappings을 확인할 수 있습니다.
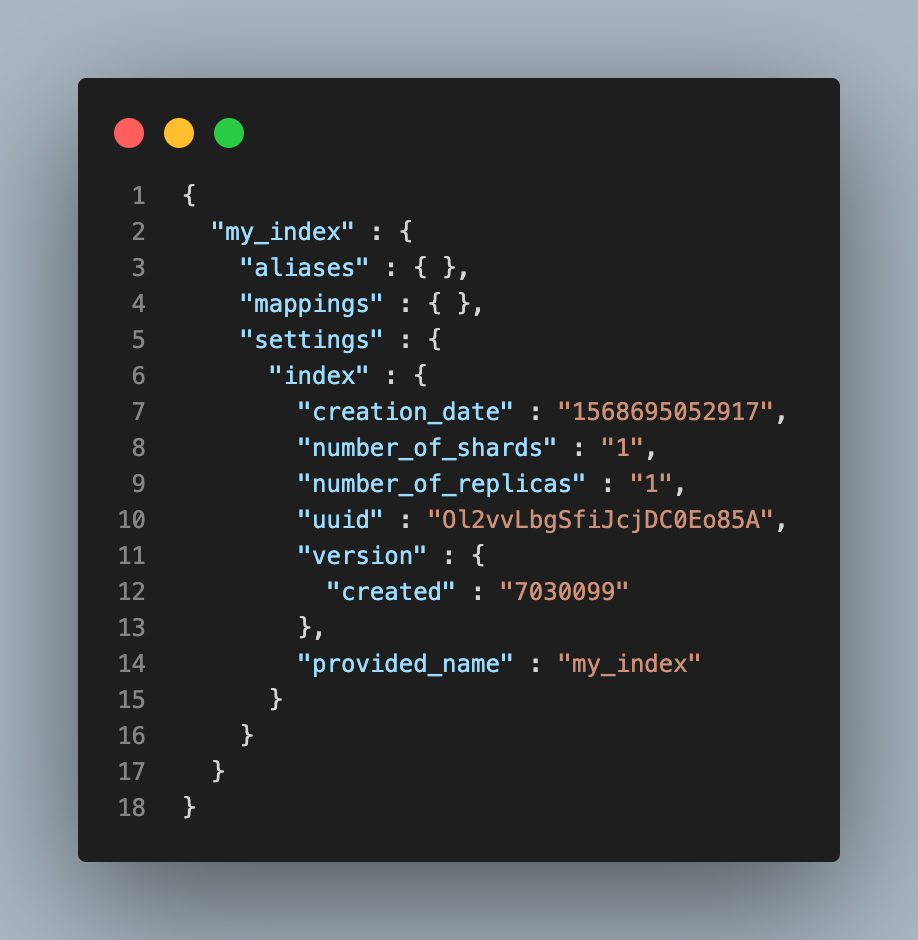
Settings
Elasticsearch Index의 Settings는 쉽게 말해 Index 정보 설정을 확인할 수 있는 단위입니다. 처음 인덱스를 정의하면 Shard, Replica(복제본)의 수 같은 정보가 자동으로 생성됩니다. 어떤 설정은 운영 도중에도 변경할 수 있지만 대부분의 설정들은 생성시 한번 지정되면 변경되지 않습니다.
지난 블로그에서 Full-Text Search를 하기 위하여 Analyzer를 사용해 Data의 역색인을 한다고 말씀드렸습니다. 지난번 살펴본 Analyzer, Tokenizer, Filter 역시 Index의 Settings에서 정의해줍니다!
Settings에서 정의하는 Analyzer의 기본 구조는 다음과 같습니다.
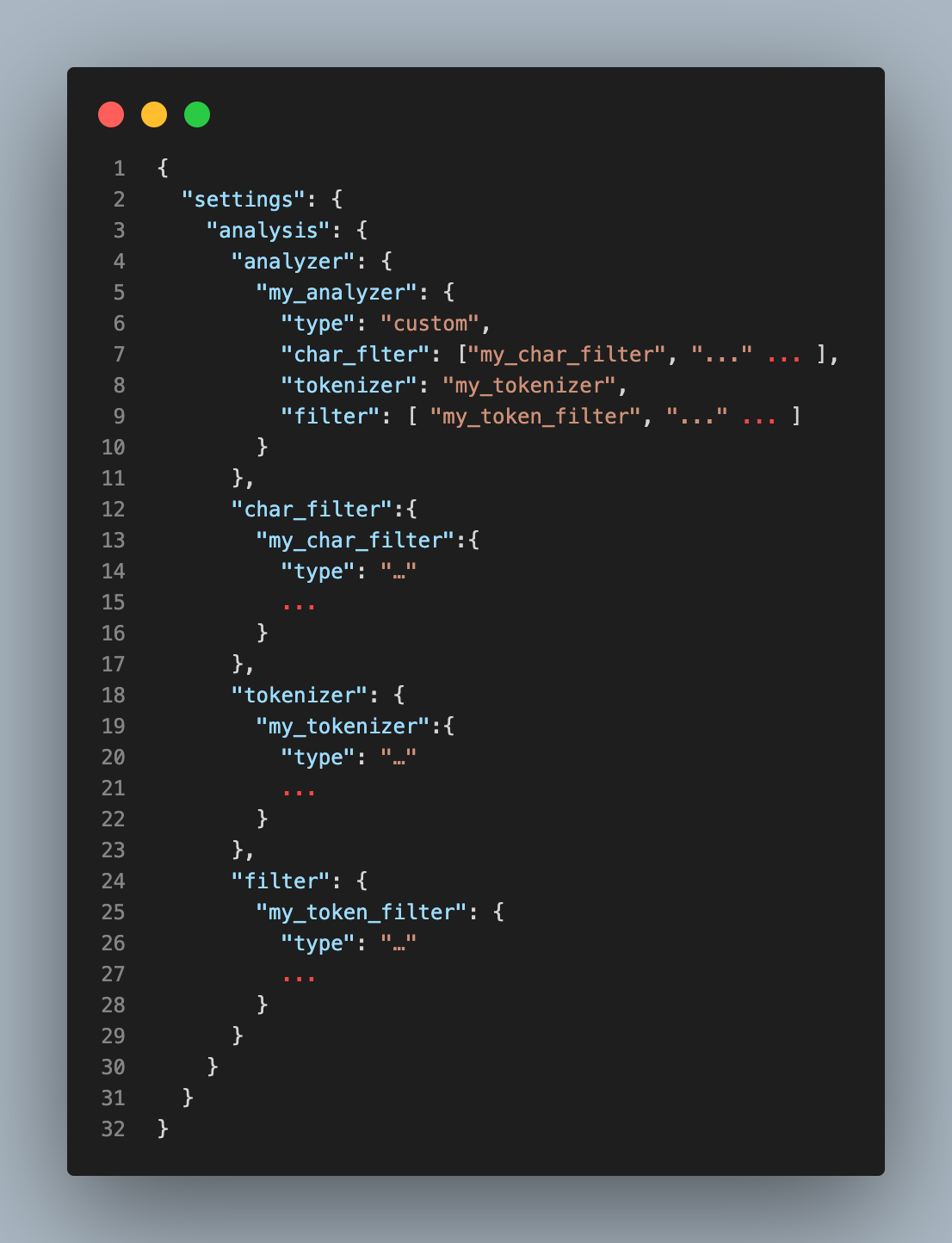
"analysis" 내부에서 analyzer, char_filter, tokenizer, token_filter를 생성하고 정의하여 사용합니다. 처음 볼 때는 복잡해 보이지만
1. char_filter, tokenizer, filter 내부에 사용자가 정의한 기능들을 작성하고
2. 작성한 사용자 정의 기능을 analyzer에서 적용하여 사용하는 구조 입니다.
한 번 적용된 analysis 내용은 변경이 불가능하고, 이미 만들어진 Index에 Analyzer를 변경하거나 추가하기 위해서 Index를 _close한 후에 변경하고 다시 _open해주어야 합니다.
Mappings
우리는
Settings에서 Index가 사용할 수 있는analyzer를 정의해주었을 뿐, 아직 Data 역색인 과정에서 적용하지는 않았습니다. 사용할 수 있는 도구를 등록했으니,Mappings에서 사용해보도록 합시다!
Elasticsearch를 활용하며 가장 손이 많이 가고 중요한 작업이 Mapping 설정입니다. Elasticsearch는 Dynamic Mapping을 지원하기 때문에, 미리 정의하지 않아도 Index를 추가하면 자동으로 Mapping이 정의됩니다. 인덱스 설정없이 books라는 Index에 다음 doc를 입력하면 아래와 같이 Mapping이 정의되는 것을 확인할 수 있습니다.
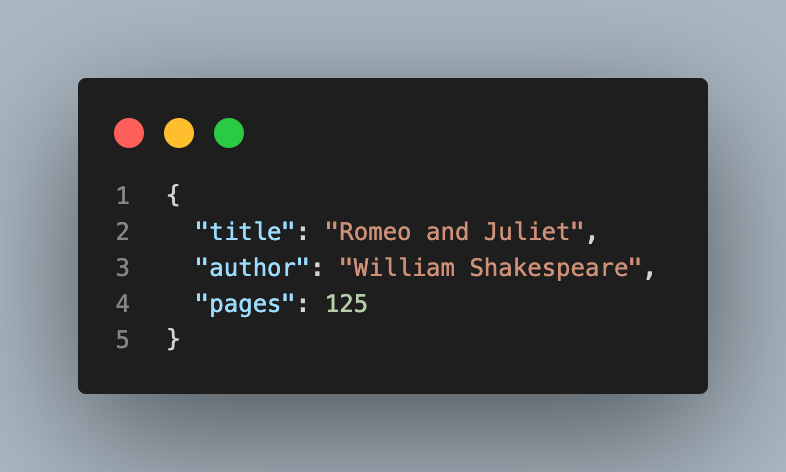
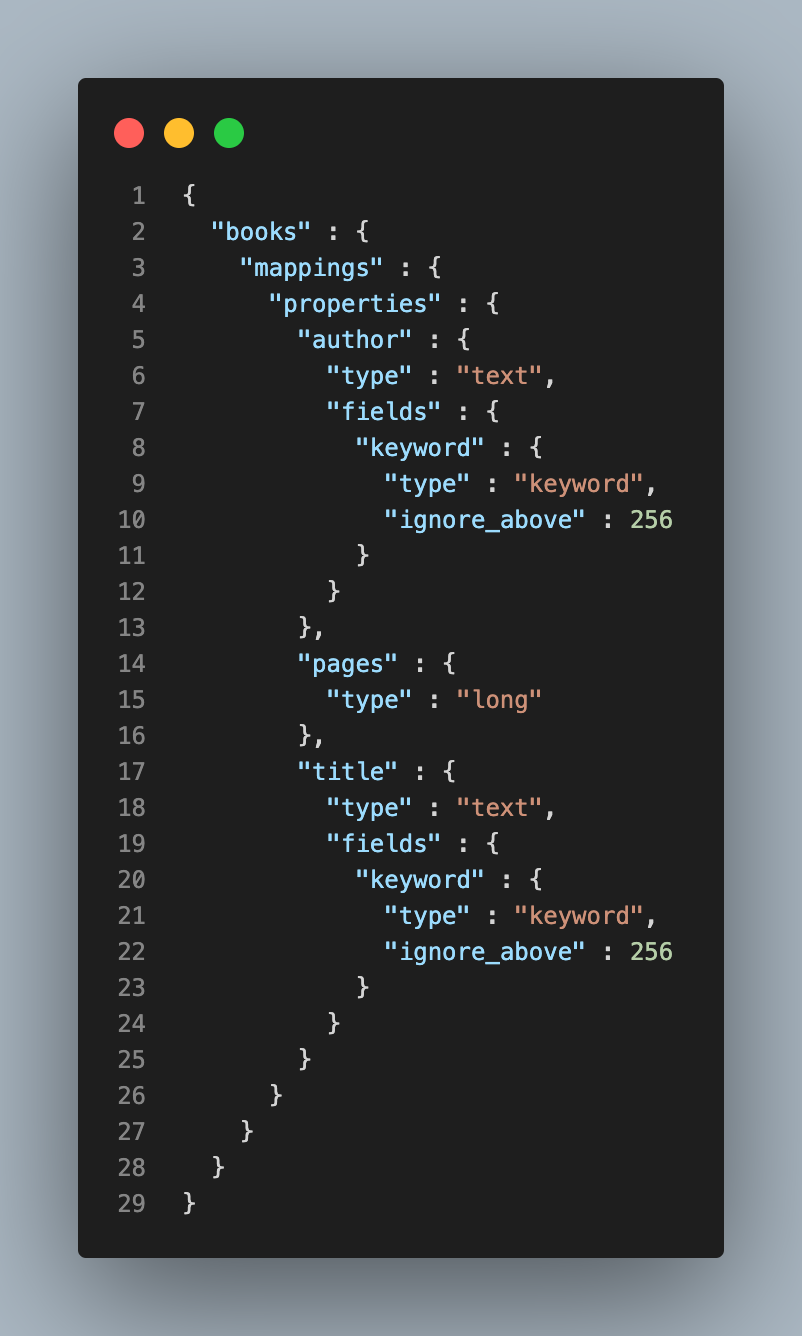
Index Mapping의 Field는 Property 항목 아래 지정됩니다. 위 예시를 보면 입력된 doc 데이터 형식에 맞게 title은 text와 keyword, page는 long Type으로 자동 지정되는 것을 확인할 수 있습니다.
이미 만들어진 mapping에 필드를 추가하는 것은 가능하지만, 필드를 삭제하거나 변경하는 것은 불가능합니다. 따라서 필드 변경이 필요한 경우 인덱스를 새로 정의하고 재색인해주어야 합니다.
Multi Field
Elasticsearch Document는 하나의 필드값만 존재하지만, 이 필드값을 여러 개의 Field로 지정하여 색인할 수 있습니다. 위 예시에서 title을 text와 keyword 두 개의 type으로 지정한 것이 바로 이런 경우입니다.
text 타입은 입력된 문자열을 term 단위로 쪼개 역색인 구조를 만들어주기 때문에 보통 Full-Text Search에 사용할 문자열 필드를 text로 지정합니다. 반면 keyword 타입은 입력된 문자열 자체를 하나의 token으로 저장합니다.
textType에는 우리가 settings에서 정의한 Analyzer를 적용하여 어떻게 색인할 것인지 정의할 수 있습니다! Multi Field를 사용해 하나의 field에 서로 다른 analyzer를 적용할 수도 있습니다.
Mappings에서 적용할 수 있는 filed type은 text, keyword, long 외에도 수 많은 종류가 있습니다. 이러한 다양한 필드 타입은 공식 문서에서 확인할 수 있습니다.
Custom Setting & Mapping
지금까지 Elasticsearch의 Index의 settings와 mapping을 통해 어떻게 Data 역색인을 위해 Analyzer를 적용할 수 있는지 확인해 봤습니다. 이를 토대로 이제 우리가 Project에서 사용할 Custom Analyzer를 정의하고 적용해보도록 하겠습니다.
Analyzer
Analyzer를 작성하기 위해 먼저 생각해야 할 것은 우리가 사용할 Data가 어떻게 Indexing 되어야 하는가 입니다. Project에서 Full-Text Search에 사용되는 Filed는 product_unit으로, 302_pk_lux_princess_pink, 302_WH_LUX_WHITE와 같은 양식으로 관리되고 있습니다.
여기서 알아볼 수 있는 product_unit의 특징은 다음과 같습니다.
_로 각 term이 구분되고 있다.- 숫자가 포함되어 있다.
- 영어 대, 소문자가 모두 포함되어 있다.
my_tokenizer
standard, letter, whitespace 토크나이저 중 적용할 수 있는 적절한 토크나이저가 있나 고려해봤을 때, standard 토크나이저는 _를 기준으로 분리하지 않고, letter 토크나이저는 숫자를 기준으로 term을 분리하기에 적절하지 않습니다. whitespace 또한 애초에 product_unit에 공백이 존재하지 않기에 유의미한 term 분리가 될 것 같지는 않습니다.
따라서 우리는 _로만 term을 분리하는 my_tokenizer를 정의해주었습니다.

ngram_filter
Elasticsearch는 빠른 검색을 위해 검색에 사용될 term을 미리 분리해 역색인하여 저장하는데, Term이 아닌 일부 단어로 검색해야 하는 기능이 필요할 때가 있습니다. 주로 자동완성 기능에 유용한데, RDBMS의 LIKE 검색과 비슷한 기능을 하는 wildcard 나 regexp Query도 지원하지만 이런 쿼리는 메모리 소모가 많고 느리기 때문에 빠른 검색을 지향하는 Elasticsearch의 장점을 활용하지 못합니다.
이런 상황을 위해 Query가 아니라 처음 Indexing을 할 때 검색 Term의 일부를 분리하여 저장할 수 있는데, 이렇게 단어를 나눈 부위를 Ngram이라 합니다. min_gram과 max_gram으로 최소, 최대 문자 수 Token을 정의할 수 있는데, house라는 text를 최소 2, 최대 3의 gram으로 설정하면 아래와 같이 총 7개의 token을 저장합니다.

우리는 min_gram과 max_gram을 각각 2, 5로 설정하여 다음과 같이 ngram_filter를 정의해주었습니다.

settings
단순하지만 my_tokenizer, ngram_filter를 작성한 후 아래와 같이 my_anlyzer와 ngram_analyzer를 정의해주었습니다.
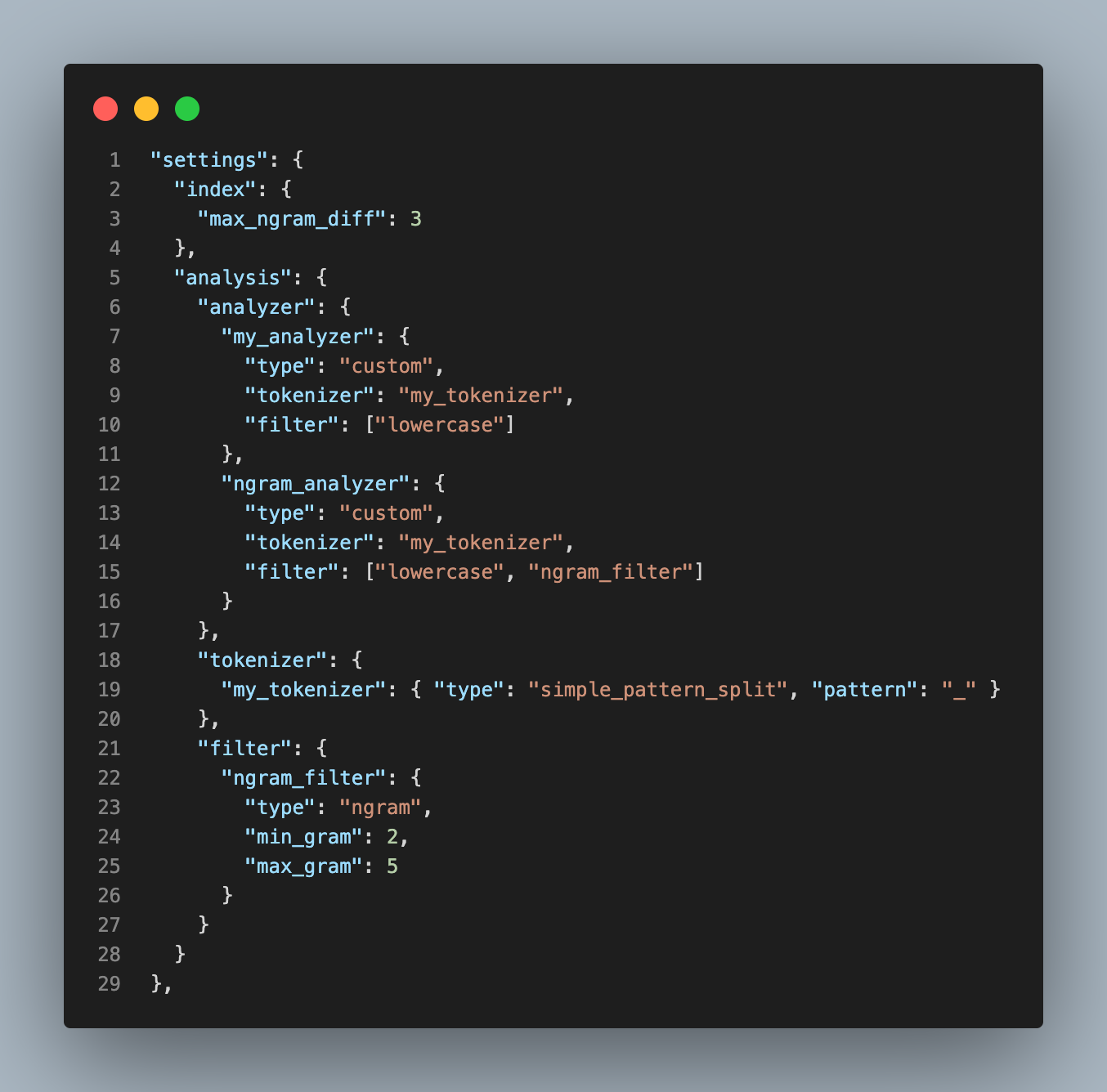
mgax_ngram_diff는 min_gram과 max_gram의 허용된 최대 Difference로, 정의해주지 않으면 Error가 발생하였습니다. Analyzer를 my_analzyer와 ngram_analyzer 2개를 정의해주었는데, 우리는 product_unit에 multi_field를 적용하여 Indexing할 것입니다. 추가 filter는 단순히 lowercase만 적용했습니다.
mappings
이제 우리가 정의한 analyzer를 mapping에서 적용하겠습니다. Index 설정 없이 자동으로 생성되는 mapping에 추가적으로 ngram field와 analyzer, search_analyer를 적용하였습니다.
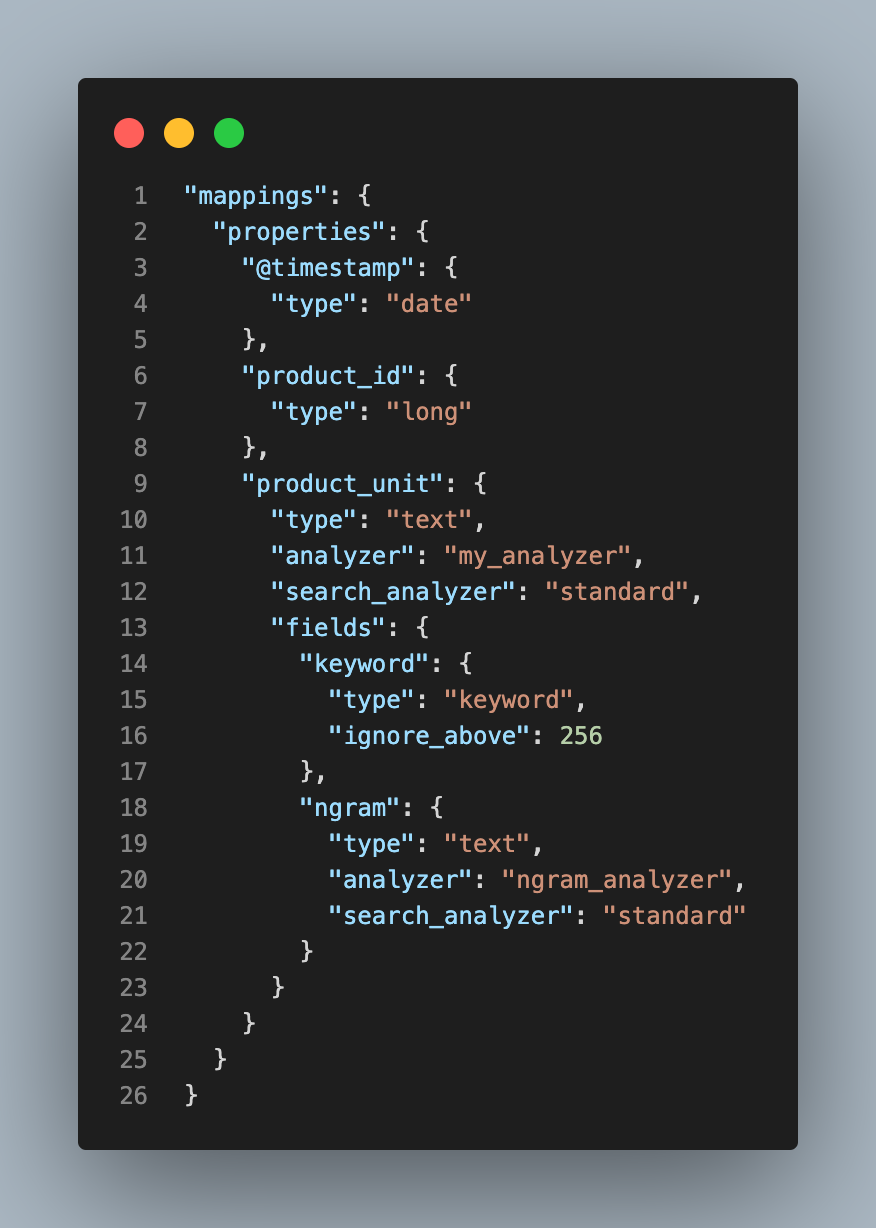
Analyzer는 기본적으로 Elasticsearch에 역색인하여 저장하는 과정에서 적용되지만, 검색을 하는 text 자체에도 적용이 됩니다. 그래서 만약
product_unit.ngram으로 검색을 할 경우analyzer를ngram_analyzer만 적용한다면 검색 text를 ngram으로 분해해 검색하기 때문에 검색 범위가 넓어져 원하지 않는 결과가 나올 수 있습니다. 따라서search_analyzer를 추가하여 검색에 적용하는analzyer를standard로 정의해주었습니다.
Index Template in Logstash
지난 번 Logstash를 활용해 Mysql에 존재하는 Data를 동기화하여 Elasticsearch로 전송하는 과정을 살펴봤습니다. Logstash를 활용해 우리가 작성한 Index Setting과 Mapping을 적용하기 위해서 Template을 작성해 logstash.conf에서 설정해주어야 합니다.
Logstash - Mysql Synchronize
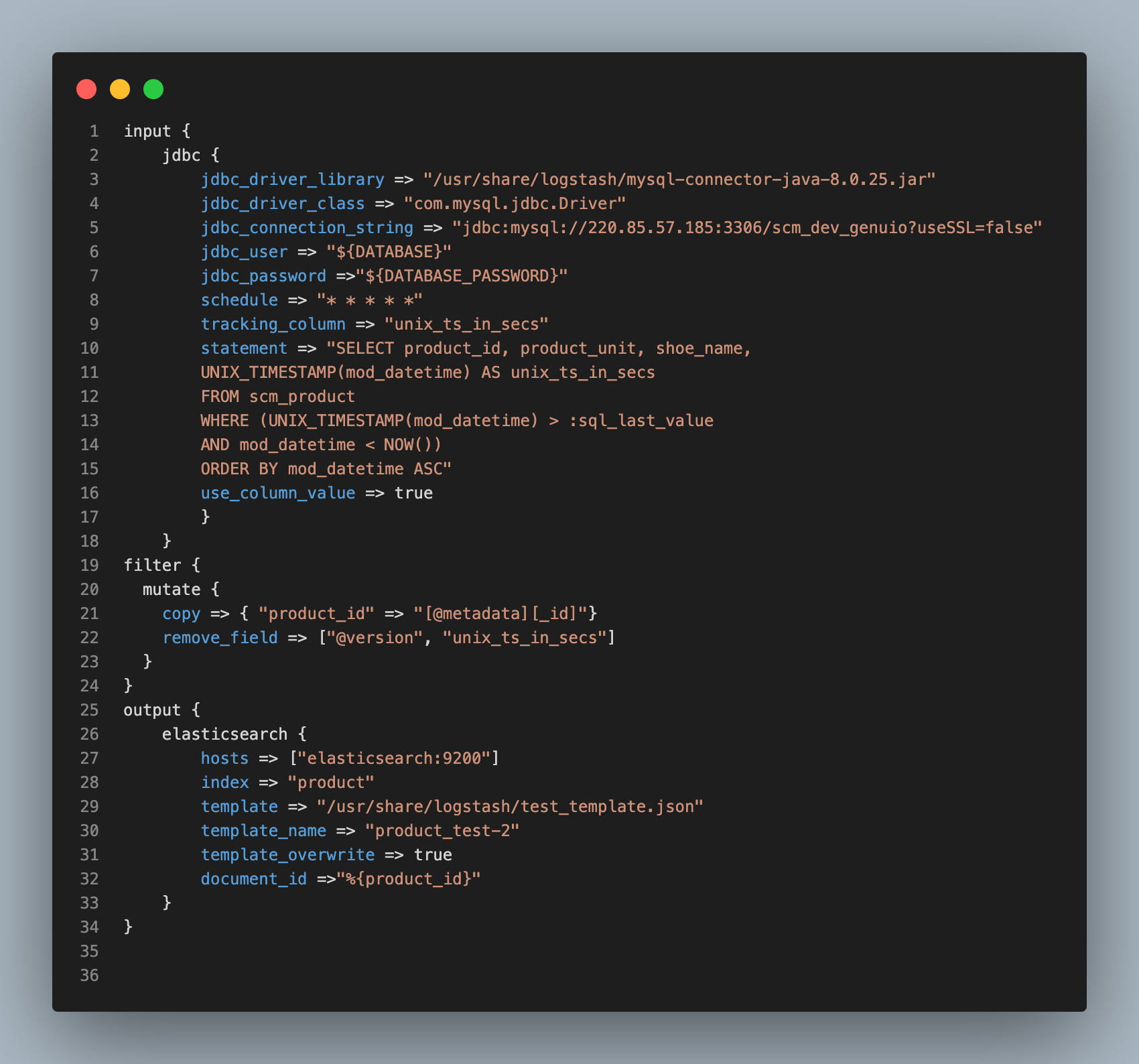
지난 블로그에서 소개했던 logstash.conf와 조금 달라진 점을 확인할 수 있습니다. Elasticsearch와 Mysql의 동기화를 유지하기 위해 JDBC Input Plugin이 주기적으로 Mysql을 폴링 루프를 실시하는데, 이 루프는 마지막 계산이 실행된 이후 삽입되거나 수정된 레코드만을 폴링 해야 합니다. 아니라면 매 번 모든 Data를 Indexing하기 때문에 사실상 새로운 Index를 만드는 것과 다른 점이 없습니다.
이렇게 동기화를 유지하기 위해서 레코드의 업데이트 시간이 필요하고, Logstash가 Mysql에서 읽은 마지막 레코드의 업데이트 시간을 기록하고 다음 번 폴링시 마지막 기록보다 새로운 업데이트나 삽입이 있는 레코드만을 가져오게 됩니다.
tracking_column: 이 필드는 Logstash가 Mysql로부터 읽은 마지막 문서를 추적하는 데 사용됩니다.unix_ts_in_secs는.logtsash_jdbc_last_run파일에 저장되는데, 이는 마지막 폴링이 적용된 시간으로서SELECT문에서 레코드 업데이트 시간을 비교하여 폴링할 레코드에 Access하도록 도와줍니다.sql_last_value: Logstash의 폴링 루프의 현재 반복 계산을 위한 시작점을 포함하는 기본 매개 변수입니다.unix_ts_in_secs의 가장 최근 값으로 설정되며, 쿼리에 이 변수를 포함하여 이전 변경사항이 이미 Elasticsearch에 적용되었으면 다시 전송되지 않도록 해줍니다.
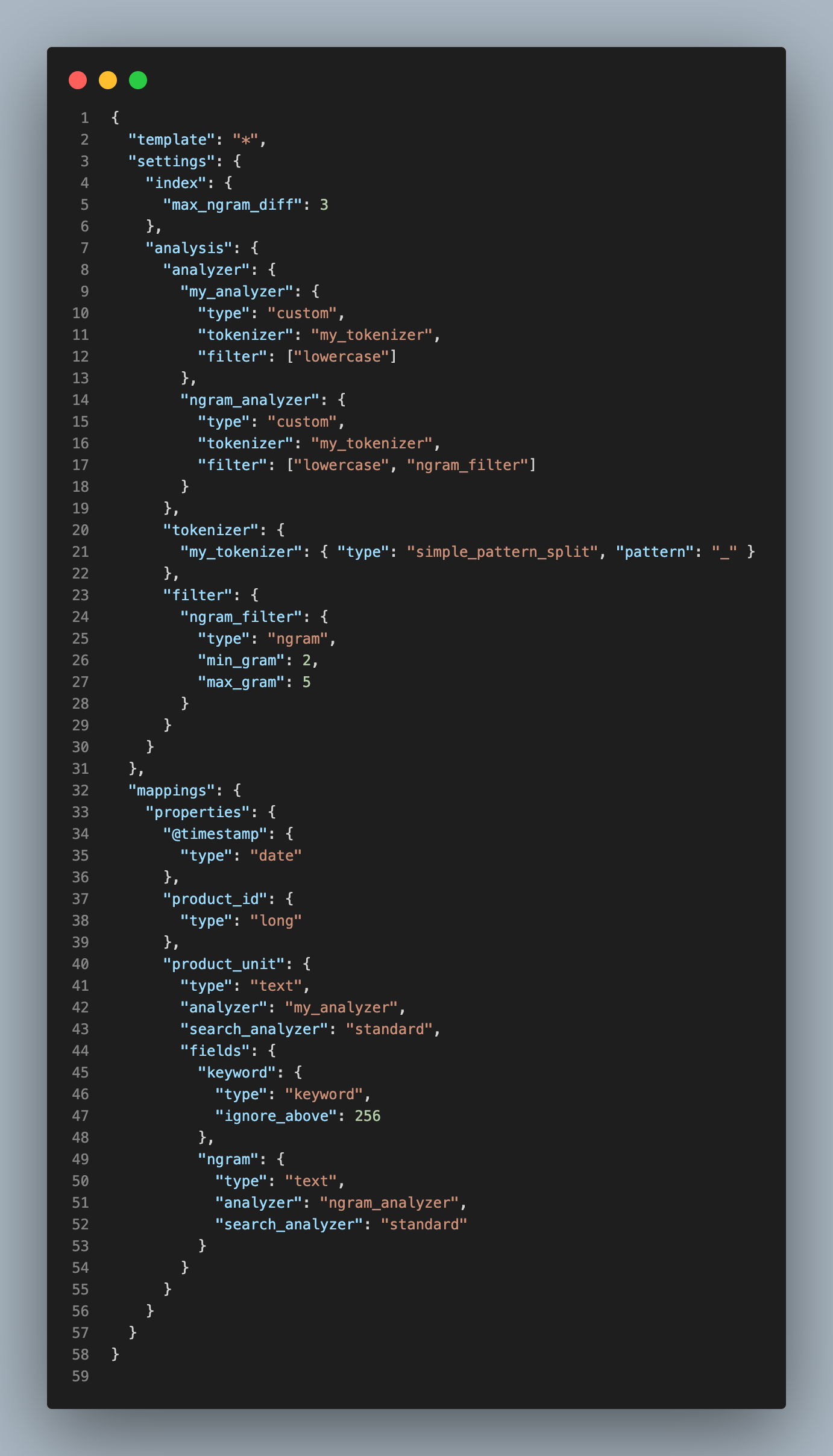
template
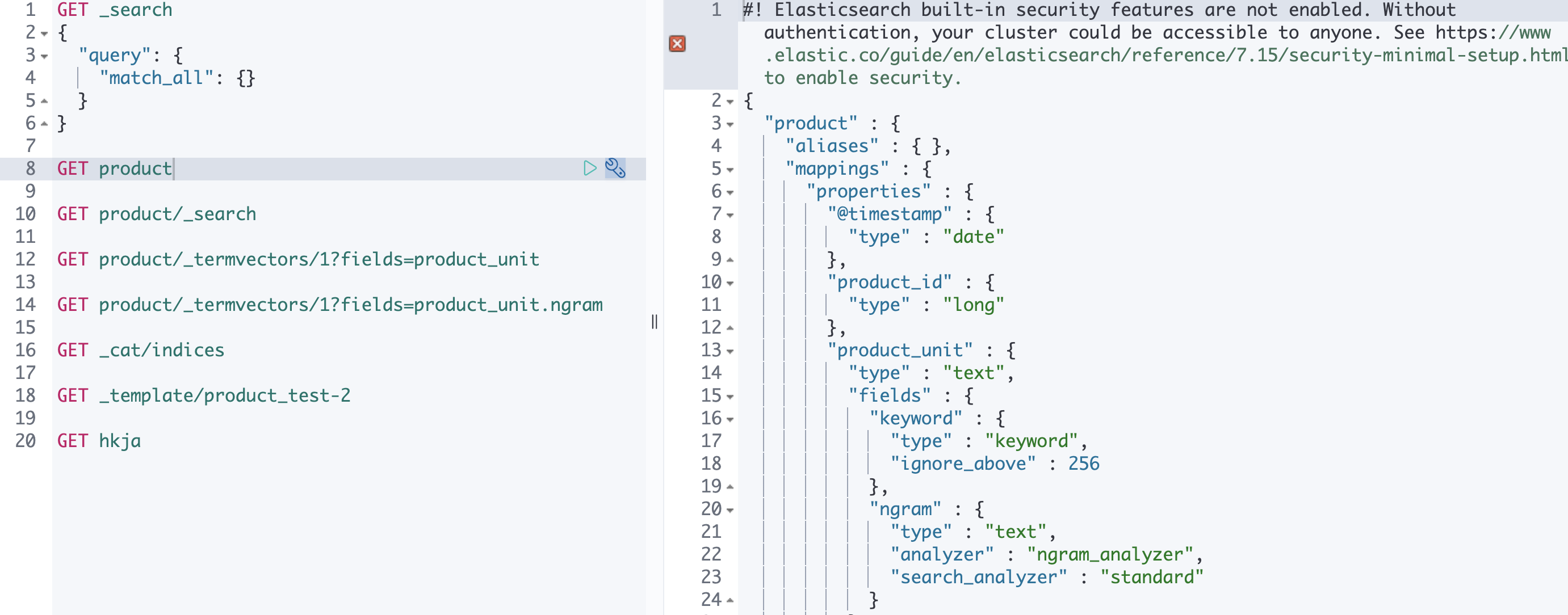
output에서 product 인덱스를 생성하기 위해 Index 설정을 한 Template의 경로와 이름을 설정해줍니다. 우리가 test_template.json 파일에 정의한 Setting과 Mapping은 다음과 같습니다.
이제 Setting을 적용한 Index를 Kibana Dev Tools에서 확인할 수 있습니다!
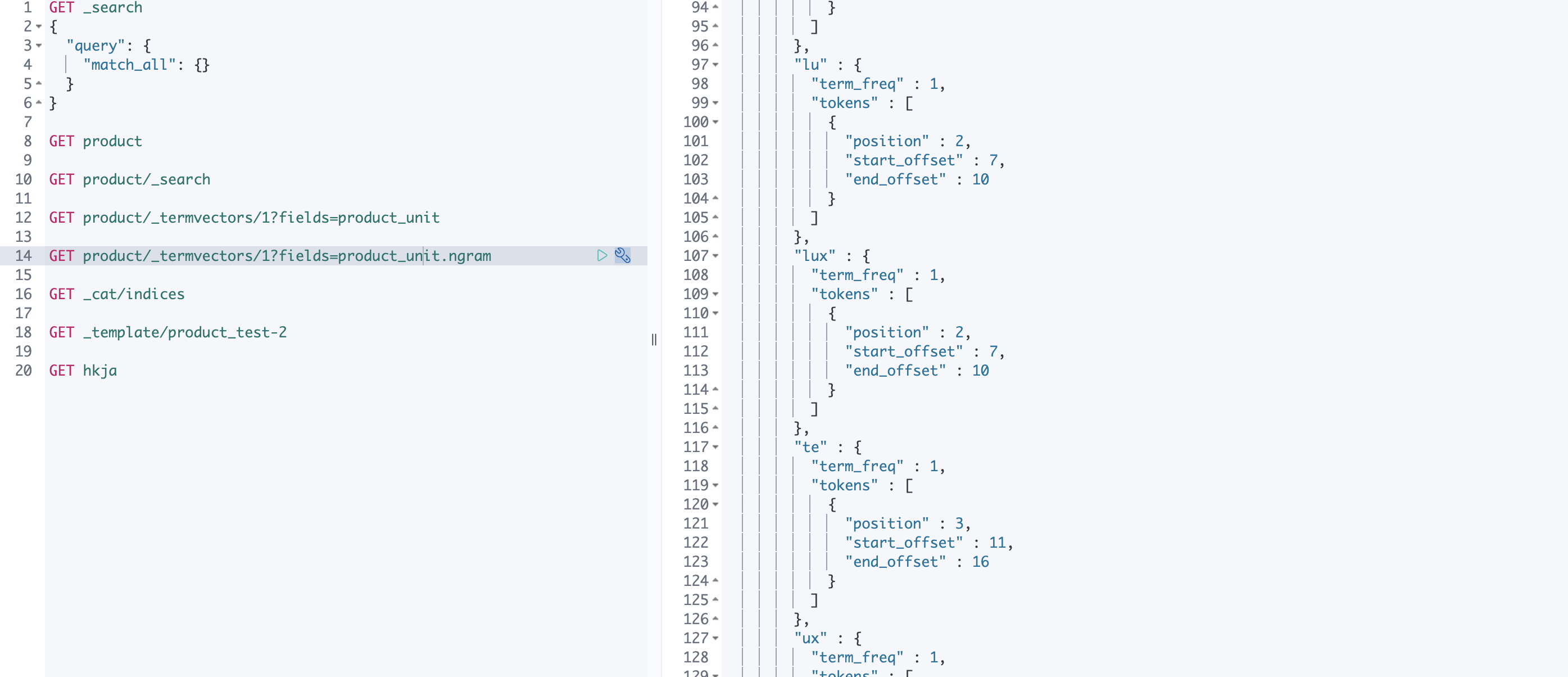
_termvectors를 사용해 product_unit.ngram field가 어떻게 term을 분리해 색인했는지 확인할 수 있습니다. 302_WH_LUX_WHITE text를 아래와 같이 ngram term으로 구분하여 저장하는 것을 볼 수 있습니다.
이렇게 Logstash를 활용해 Mysql의 Data를 Elasticsearch로 전송하면서 색인과 검색에 활용할 Analyzer를 적용하는 Mapping을 완료했습니다. 다음에는 NestJS에서 Elasticsearch를 활용해 Full-Text Search 기능을 구현하는 법에 대해 알아보겠습니다.
참고자료
Logstash를 사용해 Elasticsearch와 RBDMS 동기화 유지하는 방법
Elasticsearch 가이드북
ElasticSearch 에서 wildcard 쿼리 대신 ngram을 활용하는 방법
Elasticsearch 공식문서 - search_analyzer
