이준석 교수님의 유튜브 강의 Lec 9. Video Classification I , Lec 10. Video Classification II 영상을 참고해서 정리한 내용입니다. 다른 출처표기가 없는 이미지는 유튜브 영상에서 가져온 것임을 밝힙니다.
Challenges with Videos
이미지에서 비디오로 넘어가는 순간 많은 제약이 따르고, 이미지에 비해 (당연히) 발전 속도가 더디다. 왜 그런지 몇 가지 예시로 알아보자.
우선 비디오의 어마어마한 용량. 비디오 데이터셋을 저장하기 위해서는 그에 맞는 저장 공간이 있어야 하는데, 데이터셋의 크기가 커질수록 이를 모두 수용할 수 있는 저장공간이 마땅치 않다. 물론 computational cost도 그에 맞게 매우 크기 때문에 모델 하나 돌리는데 며칠에서 몇 주까지 넘어간다.
또, 데이터셋을 수집하는 데에도 제약이 있다. 우선 라벨링을 하기 힘들다. human labeling일 때 이미지의 경우엔 한 장의 이미지에 대해 label하는데 몇 초밖에 안걸릴 것이다. 하지만 비디오로 넘어가는 순간 비디오의 내용을 보고 “어떤 비디오다” 하는 라벨링을 하기 위해선 영상 길이만큼의 시간이 걸린다. 또, 영상의 경우 저작권 문제가 더욱 심하다.
이와 같은 문제들 때문에 비디오 처리 분야는 아직 갈 길이 멀다. 그럼 지금까지 어떤 접근으로 어떤 문제를 풀고 있는지 알아보도록 하자.
First Ideas: Multiple Frames
비디오 상에서 action recognition을 하기 위한 첫 번째 접근은 바로 frame 별로 cnn을 돌리는 것이다. 그도 그럴 것이 이 논문이 2014년에 나왔으므로 정말 가장 첫 approach인 셈이다.
모든 프레임별로 cnn을 돌려 class label을 예측한다. 이때 score fusion(프레임별로 class score을 계산해 마지막에 모두 더한 후 최종 score 계산)하이나 feature fusion(모든 frame의 feature를 더해 MLP를 지나 최종 class prediction)의 방법 등을 통해 video classification을 수행했다.
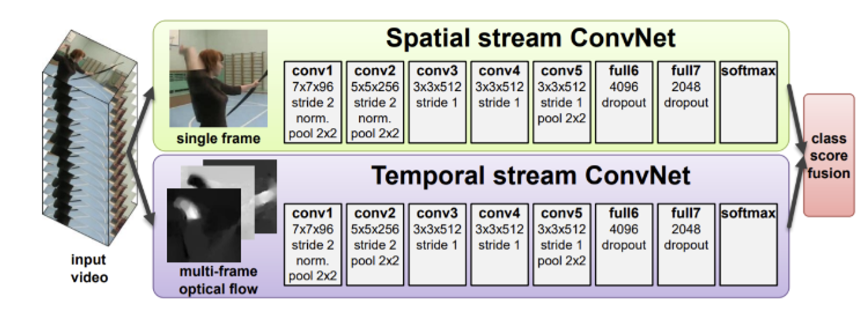
Two-Stream Models
이번에는 two stream으로 spatial 정보와 temporal 정보를 분리하여 따로 훈련하는 것이다.
spatial- single frame의 공간적 feature 이용, appearance 학습temporal- multi frames의 시각적 feature 이용, 이때 optical flow를 feed하여 temporal dynamics를 학습
이때 Optical Flow가 뭘까?
optical flow는 쉽게 말해 프레임을 서로 비교하여 이미지 상의 픽셀이 어디로 움직였는지 벡터로 표현하는 것을 말한다.

왼쪽 이미지를 보면 나란한 두 이미지가 서로 다른 프레임 이미지이며, 물체가 약간 이동했다. 이걸 flow vector를 이용하여 픽셀값들이 어떻게 변했는지 벡터로 표현한 것이 바로 오른쪽 그림이 된다.
Optical Flow를 사용하기 위한 몇 가지 가정이 있다.
FPS가 충분히 크다고 할 때, 즉 1초에 들어있는 프레임이 충분히 많을 때 다음 세 가정이 만족된다고 가정한다.
Brightness constancy: 한 프레임에서 특정 픽셀의 값은 다음 프레임에서도 거의 유사하다.Temporal persistence: 객체가 다음 프레임으로 넘어갈 때 그렇게 멀리 까지 멀어지지 않는다. (그만큼 빨리 움직이는 객체가 드물다)Spatial conherence: 가까이 있는 픽셀들은 같은 객체에 속하며, 비슷하게 이동한다.
그럼 그 optical flow를 어떻게 모델에 입력하는지 알아보자.
우선 Spatial 은 하나의 프레임을 ConvNet에 넣어주면 된다. 즉, 2D 이미지 하나를 conv에 넣는 것이다. 하지만 문제는 Temporal 이다. 왜냐, Temporal 은 여전히 multi frames이기 때문에 3D이다. 따라서 바로 ConvNet에 넣어줄 수가 없다.
여기 논문에서 사용한 아이디어는 간단하다.
예를 들어 L개의 frames가 있을 때 총 채널의 수는 2L이다. 각 프레임마다 두 개의 채널(가로 움직임, 세로 움직임)이 있으므로! 다시 말하자면 이는 결국 h w 2L인 하나의 이미지라고 생각할 수 있다. 대신 채널의 수가 2L인 이미지인 셈이다.
이렇게 생각하면 결국 2D 이미지로 볼 수 있으며 Spatial과 동일하게 ConvNet에 넣어줄 수 있게 된다.
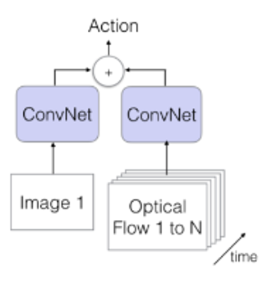
따라서 모델 자체는 2D를 input으로 받는 셈이 된다.
Spatio 로는 모든 프레임 중 랜덤으로 고른 한 장의 이미지를, Temporal 로는 모든 프레임의 optical flow를 층층이 쌓은 한 장의 이미지와 같은 데이터를 입력으로 준다.
Problem
당연히 문제가 있는데, 가장 큰 문제는 “하나의 프레임”만 본다는 것이다. 영상 중 어느 프레임을 보는지에 따라 영상의 label이 달라질 수 있다. 또, optical flow를 모두 미리 계산해서 사용하는데 그에 따라 storage가 많이 필요하다.
동영상을 저장하는데 모든 프레임 채널 3개를 저장했다면 optical flow를 저장하는 순간 여기에 추가로 모든 프레임 채널 2개를 저장하는 셈이 된다. 따라서 상당히 비효율적이다.
이번에는 3D Convolution 매커니즘과 함께 video classification 모델들에 대해 알아보자.
3D Convolution
이제 영상을 처리하기 위해선 기존에 배웠던 2D Convolution에서 3D로 확장해야 한다. 간단한 예시부터 보자.
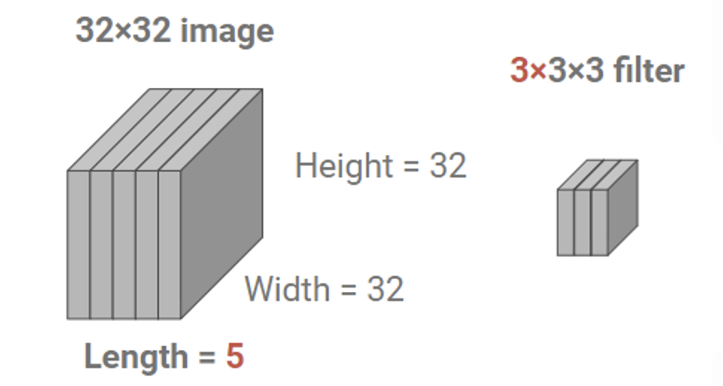
channel = 1인 5장의 이미지가 있다고 하자. 이때 시간축을 length라 표현하고 표기할 때 제일 앞에 쓰기로 하면 이 이미지는 5 32 32로 표현할 수 있다. 이때 필터는 3 3 3, 즉 3개의 이미지씩 묶어서 본다고 하면 연산이 어떻게 되는지 보자.

사실 필터가 움직이는 것은 2D와 동일하나 시간축으로도 움직인다는 점만 다르다. 원본 데이터의 length = 5인데 필터의 length = 3이므로 시간축으로 3개의 이미지씩 한 번에 본다는 의미.
따라서 final output size를 계산하면 3 30 30 * 1(=filter) 이 된다.
그럼 이미지가 채널이 1이 아니라면 어떻게 될까?
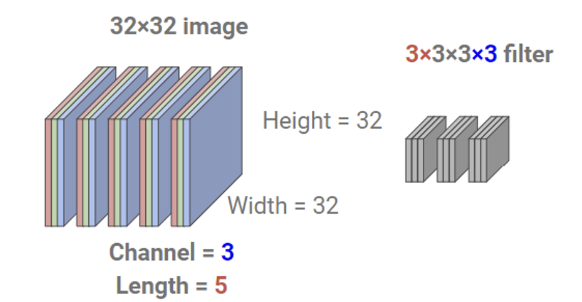
2D에서 이미지의 채널에 따라 필터의 채널이 그대로 결정된다고 했다. 둘의 채널 크기가 다르면 conv 연산 자체가 안될테니. 이것도 위의 방식으로 계산을 하면 된다.
3D Convolutional Models
1. C3D
이름 그대로 Convolutional 3D인 모델이며 CNN을 사용하여 비디오 데이터를 처리하는 모델이다. 이 모델 이전에도 비슷한 논문이 나왔었지만 이땐 AlexNet이 나오기도 이전 모델이기 때문에 파장 없이 넘어간 케이스.
그럼 이 모델의 아키텍처 먼저 보자.

구조는 사실 AlexNet 과 거의 유사하다. 3D로 temporal 축만 하나 더 추가되었을 뿐, conv+pool 구조는 거의 비슷하다. 여기선 3 * 3 * 3 filter를 사용했는데, 즉 프레임 3개씩 묶어서 conv를 한다는 의미다.

그럼 이런 아키텍쳐가 완성된다.
사실 그냥 우리가 익숙한 2D Conv에서 시간축이 하나 더 생겨서 연산이 복잡해졌을 뿐, 더이상의 변화는 없다.
물론 이렇게 영상을 처리했을 때는 단점이 있다.
우선 잘 생각해보면 대부분의 영상은 15~30FPS 정도, 즉 한 프레임당 1/30초 정도 걸린다. 근데 여기서 Conv를 이용하면 2개 내지 3개의 프레임을 고려하여 Conv를 하겠다는 말인데 해봤자 1/10초를 묶어서 보겠다는 말이다.
어떤 영상이든지 1/10초만에 엄청난 변화가 있는 영상이 흔하진 않을 것이다. 거의 유사한 프레임들만 보기 때문에 시간적으로 큰 차이가 없을 것이다. 따라서 long range temporal하게 모델링을 하는데 실패한 셈이다.
2. R3D
이번엔 Facebook이 낸 또 다른 논문인 R3D이다. 이름에서 R은 ResNet 을 뜻한다. ResNet의 가장 큰 차이점이 skip connect 이 있었는데 여기 모델에서도 그대로 사용하고 있다.

ResNet 2D에서 3D로 넘어가면서 변경된 부분들을 빨간색으로 표시한 것이다. 보면 아무래도 동영상을 다루기 때문에 연산량이 많이 레이어를 깊게 쌓는게 불가능하였기에 34층으로 줄였다. 그리고 당연히 필터에도 temporal 축을 추가했다. 그 외에는 명칭이 변하는 등의 minor한 변화들이 있었고, 나머지는 기존 아키텍쳐와 동일하다.
하지만 사실 이 R3D는 논문에서 떨어졌다. 대신 후속 논문이 등재되면서 같이 소개됐던 모델!
3. R(2+1)D
이게 바로 그 후속 논문이다. 아이디어는 간단하다. 우리 이전에 Conv의 연산량이 너무 많아서 이를 조정하는 방법으로 Conv layer 앞뒤로 1*1 filter을 이용해서 채널수를 조정하는 이야기를 했었다. 여기서도 비슷한 맥락이다.
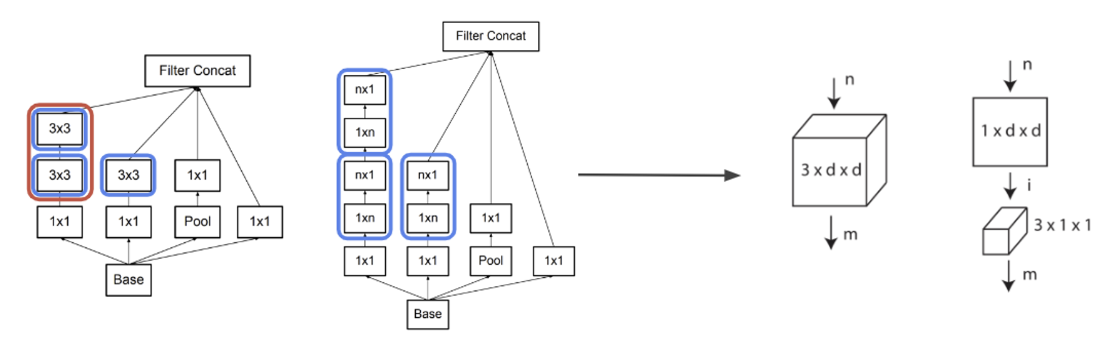
여기서는 Trmporal 과 Spatio 를 따로 고려하겠다는 취지로 입력이 들어오면 바로 3 d d filter로 연산하는게 아니라 필터를 두 개로 나눴다.
- 1 d d Filter 시간 축은 건들이지 않고
Spatio정보만 학습하는 필터이다. 그래서 하나의 프레임에 대해 2D Conv를 실행한다.
- 3 1 1 Filter 이번에는 공간 축을 건들이지 않고
Temporal정보만 학습하는 필터이다. 가로 세로로는 움직이지 않고 오직 시간축에 따라서만 움직이는 conv 필터인 셈이다.
이렇게 하면 하나의 필터에서 시공간적인 정보를 한꺼번에 학습하는게 아니라 시간적, 공간적 정보를 따로 학습하게 되므로 사실상 이전에 봤던 Two Stream 과 유사한 맥락이라 볼 수 있다.
4. T3D
이번에는 DenseNet을 이용하여 만든 모델이다. DenseNet은 쉽게 설명하면 ResNet과 같은 skip connection을 모든 레이어와 연결하는 모델이다. 따라서 그래디언트 flow를 강화하면서 더 효율적으로 정보전달이 가능하게 만든 아키텍쳐라 볼 수 있다. T3D에서는 이러한 DenseNet을 이용해 모델링되었다.
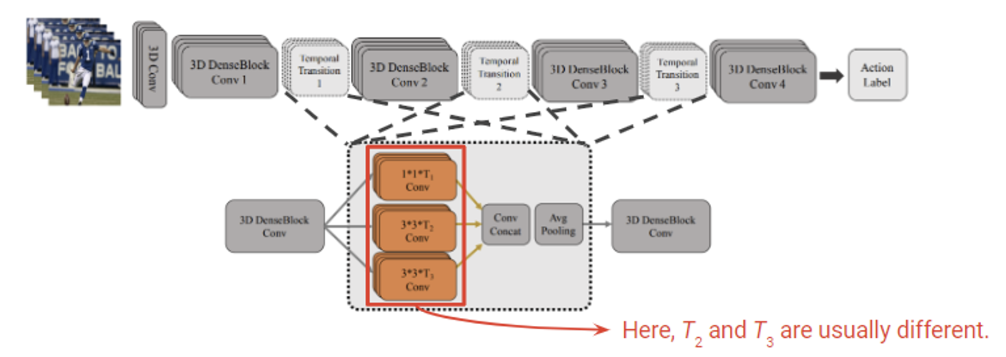
여기서 주된 아이디어는 사실 Inception module 과 비슷하다. 여러 필터를 두고(여기서는 시간축 크기가 다르다) conv를 지나 결과를 concat해주는 방식이다.
이 모델에서 주목할만한 점은 Spatio정보를 학습하는데 2D pre-trained 가중치를 사용했다는 점이다.
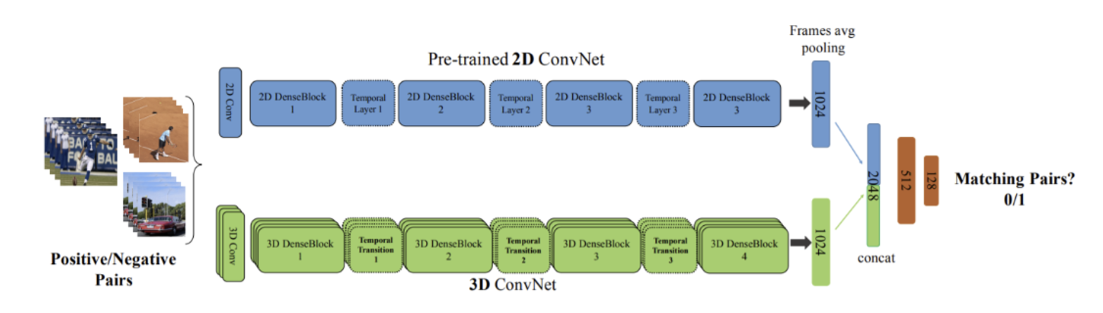
사실 비디오 데이터는 이미지에 비해 상당히 부족하다. 하지만 잘 생각해보면 temporal은 그렇다 치고 spatio는 2D로 학습한 가중치를 끌어다 써도 사실 큰 문제가 없을 것이다. 따라서 여기선 knowledge transfer 방법을 사용한다. 말이 거창하지만 결국 2D 이미지에 대해 미리 학습해놓은 모델을 끌어다가 다른 task에 적용한다는 말이다.
5. I3D
여기까지 오니 이름이 다 거기서 거기구만.. 유명한 모델 따라서 줄줄이 이름을 짓는건가?
I3D는 Two-Stream Inflated 3D ConvNet이라는 풀네임을 가진 아키텍쳐로 사실 Two stream 모델을 제안했던 옥스포트에서 3D Conv 아이디어를 덧붙인 모델이다.
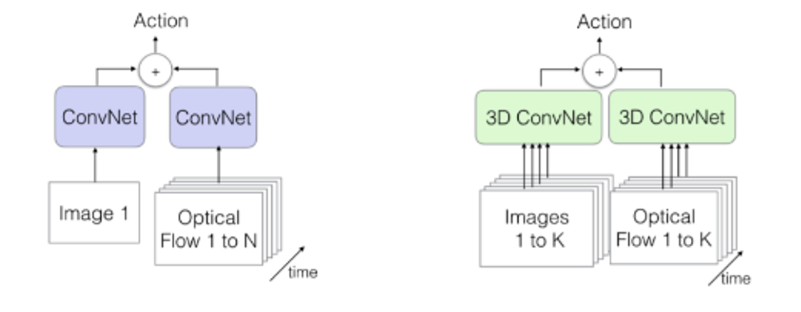
왼쪽이 Two Stream 모델이었다. 이미지와 optical flow를 한 장의 이미지로 취급하여 2D ConvNet에 입력으로 주는 방식이었다. I3D는 그와 다르게 spatio 와 temporal 모두 3D ConvNet 을 사용한다.
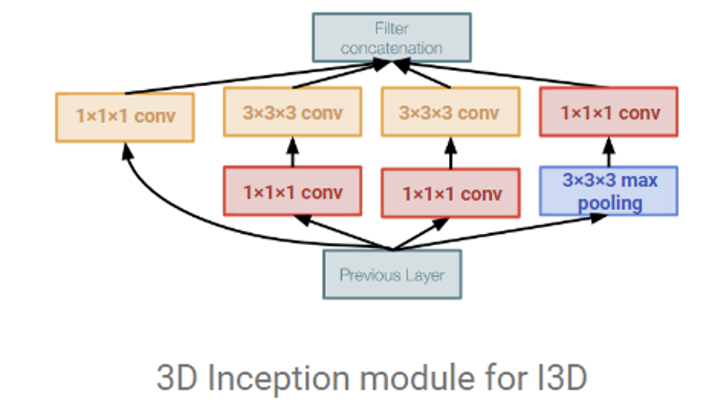
여기서는 GoogleNet을 사용한다. Inception module을 그대로 사용하는데 가운데 33이 왜 두 개가 있는지는 의문이다. 논문에서 실제로 그렇게 발표하고 코드도 33이라는데 도대체 왜 똑같은거 두 개를 놔둔건진…
여튼 기존의 GoogleNet을 3D로 확장했을 뿐 그 이상의 차이점은 없다. 자세한 설명은 넘어가도록 하겠다.
6. SlowFast
간단히 설명하면 Optical Flow를 안쓰기 위해 어떻게든 Conv 로 문제를 풀려는 노력이라 할 수 있다. 전반적인 아이디어는 사실 Two Stream을 그대로 따라간다. 여기서 conv를 이용해서 two stream으로 어떻게 풀어나가는지 보면 재미있다.
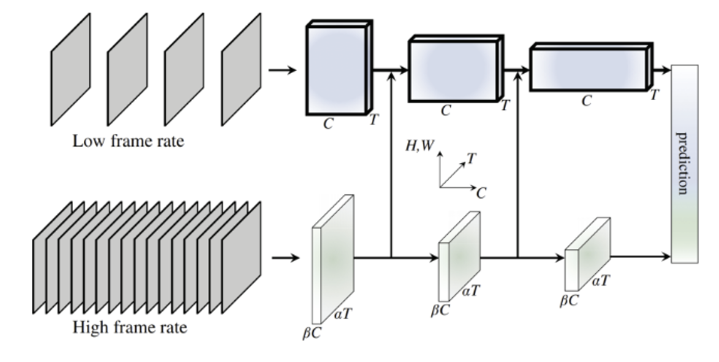
Two Stream처럼 여기서도 spatio 와 temporal 정보를 나눠서 학습을 진행했다.
- Slow path(위): 영상에서 stride 값을 크게 줘서 멀리 떨어진 프레임들을 추출한다. 그럼 뽑힌 프레임들은 장면이 크게 차이가 날 것이다. 이를 이용해서 시간축이 아닌 공간상의 이미지를 학습한다는 의미로, Two Stream에서
Spatio정보를 학습하는 것과 거의 동일하다.
- Fast path(아래): 이번에는 stride = 2로 준다. 즉 두 프레임 중 하나를 뽑는다는 의미로 상당히 가까운 프레임들을 많이 추출한다. 이를 이용하면 움직임을 탐지할 수 있으며 Two Stream에서
Temporal정보를 학습하는 것과 동일하다.
결국 Conv를 이용하지만 stride에 차이를 둬서 공간 또는 시간에 집중하는 두 개의 stream으로 나누겠다는 의미다!
근데 생각해보면 그럼 fast path에서 뽑는 프레임 수가 훨씬 더 많으니 연산량을 비교하면 엄청나게 차이가 날 것이며, 그럼 모델은 더욱이 이쪽에만 신경써서 학습할 것이다. 그걸 방지하기 위해 slow path 와 fast path 의 채널 수 를 다르게 하여 전체 연산량이 어느정도 비슷해지도록 조정을 했다.
Lateral Connection
여기에 하나의 아이디어가 더 추가된다. 아니, spatio정보와 temporal 정보를 잘 뽑았는데 이걸 꼭 classification 전단계에서만 fusion을 해야 해? 중간에 학습하는 도중에 서로의 feature를 입력으로 넣어주면 더 잘 학습할 수 있지 않을까? 하는 기대에서 나온 아이디어이다.

구현은 간단하다. spatio와 temporal feature 크기(차원)을 동일하게 잘 맞춰준 뒤에 중간에 서로를 연결하는 통로를 파주면 된다. 그럼 공간적 정보를 학습하는 데에 시간 정보를 활용할 수 있고 반대도 성립한다.
여기까지! video classification 모델들에 대해 핵심 내용만 간단히 정리해보았다. 끝~ 🌟
