📃 Paper : https://arxiv.org/pdf/2107.14795.pdf
Introduction
지금까지 대부분의 머신러닝 연구들은 각각의 Data type과 task에 특화된 모델들을 개발하는데에 집중해왔다. Multiple Modalities를 다루는 경우에도 각 modal에 특화된 모델을 사용한 후 integrate하는 방식이 적용되어 왔다. 이러한 방식의 경우 input, output data type이 더 다양해지는 경우 모델이 매우 복잡해지며 input과 output의 데이터 구조가 모델의 처리 과정에 큰 제약을 준다.
따라서 본 논문에서는 task specific하지 않은 임의의 task에 적용 가능한
✨ 네트워크의 구조를 변화시킬 필요 없이 다양한 데이터 타입을 다룰 수 있는 모델 아키텍쳐를 제안한다.
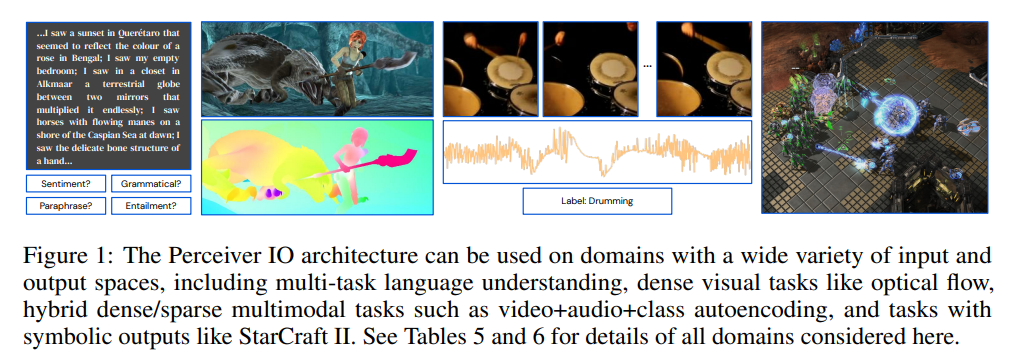
Perceiver 에서 Perceiver IO로
Perceiver IO는 기존의 Perceiver (Jaegle et al.,2021)를 발전시킨 모델이다.
Perceiver는 네트워크의 구조를 변화시키지 않고 다양한 모달리티의 input 데이터를 다룰 수 있다는 contribution이 있지만, classification 같은 단순한 output space만 다룰 수 있었다.
Problem
- 네트워크의 구조를 변화시킬 필요 없이 input 뿐만 아니라 다양한 output data를 다룰 수 없을까? (domain-agnostic, output generality)
- input, output이 다양해지고 size가 커짐에 따라 모델의 complexity가 증가하는 문제를 해결할 수 없을까 ?
Method
Perceiver IO Structure overview
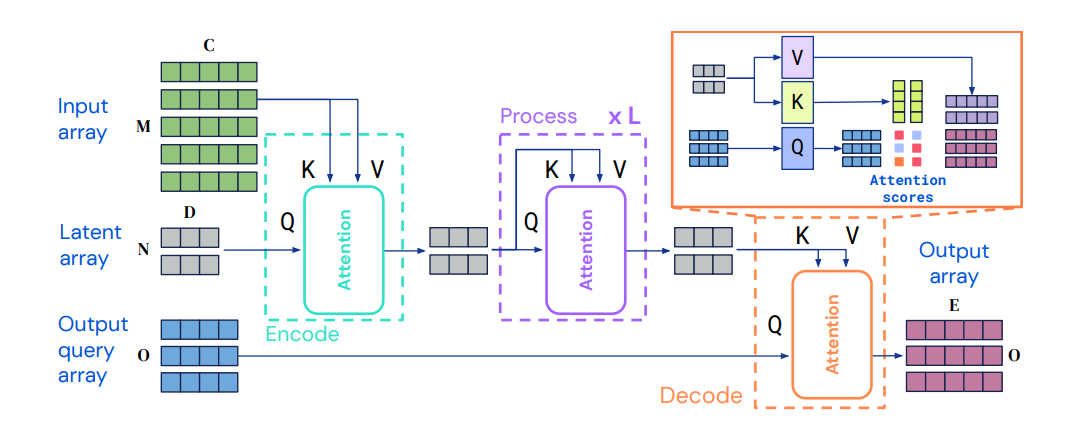
Perceiver IO는 Perceiver(Jaegle et al.,2021)를 기반으로 만들어진 모델이다. 기존의 모델에서 Decoding Structure를 발전시켜 많은 도메인에 적용시킬 수 있는(domain-agnostic) 모델을 만들었다. 기존의 perceiver는 input을 encoding하는 과정에서 transformer의 attention module을 적용하여 input generality를 획득하는 형태의 구조다.
✨ 이와 유사하게 Perceiver IO는 attention module을 input뿐만 아니라 output predict에도 사용하여 input과 같은 수준의 output generality를 획득한다.
✨ 주목할 것은 Q, K, V 벡터가 하나의 Input에서 얻어진 값이 아니라는 점이다. Latent space (잠재 공간)을 두어 연산량을 줄인다. 기존의 트랜스포머 모델이 갖고있던 input, output이 커짐에 따라 연산량이 매우 방대해진다는 문제점을 개선한 부분이다. (computational complexity를 개선)
이제 Perceiver IO의 구조를 Encoding, Processing, Decoding 부분으로 나누어 자세히 살펴보도록 하겠다.
공통적으로는 같은 구조의 Transformer-style attention module을 사용한다. 그러나 Key/values 그리고 Query를 생성하기 위해 사용되는 input이 각각 다르다. query-key-value attention 이후에는 multi-layer perceptron(MLP)가 뒤따른다.
1) Encoding
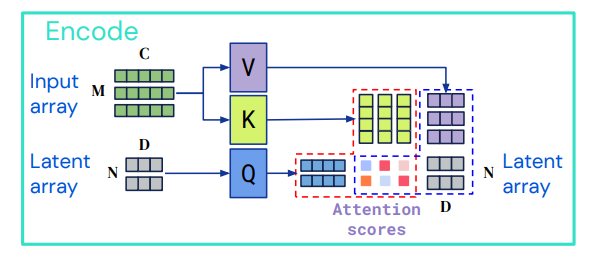
Cross-attention module을 사용하여 input array 를 latent space 로 맵핑한다. 처음의 input보다 더 작은 차원으로 인코딩 되며 N, D는 하이퍼파라미터다.
key/values의 input array:
Query의 input array:
2) Processing
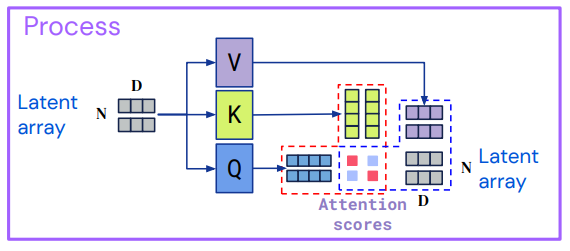
L개의 Self-attention layer 과정을 거친다. encoding과정의 결과물인 latent z는 여러번의 attention 연산을 거쳐 정제된 latent representation을 갖게 된다.
3) Decoding
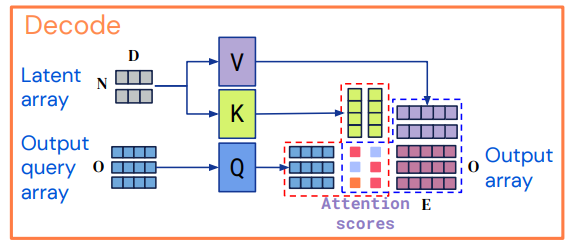
Cross-attention module 과정을 거치며 latent representation 를 output array 로 맵핑한다.
Output query array
1) 각 output에 대한 적절한 정보를 포함하고 있다.
2) output array와 동일한 index demension을 가져야 한다.
3) query array는 직접 디자인 되거나, 학습된 임베딩이 될 수도 있고 혹은 간단한 함수의 형태가 될 수 있다.
4) vector들을 결합(concatenating 또는 adding)하여 원하는 output과 관련된 정보를 포함하도록 구성한다.
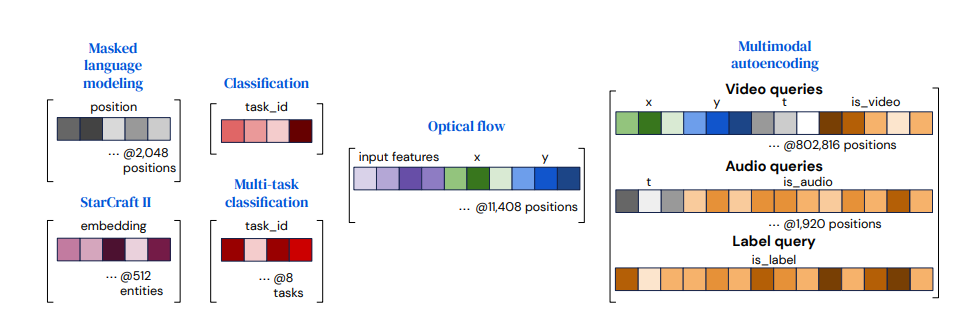
Query structure for the tasks
1) tasks with simple outputs (ex.classification) : 쿼리는 모든 example마다 재사용될 수 있으며 처음부터 학습될 수 있다.
2) outputs with a spatial or sequence structure : position encoding을 포함한다. (e.g. learned positional encoding or a Fourier feature)
3) outputs with a multi-task or multimodal structure : 각각의 task, 모달리티에 학습시킨 단일한 쿼리들을 사용한다.
4) other structure : output은 쿼리 위치의 input content를 반영해야 한다.
각 단계에서 수행되는 어텐션 모듈의 구체적인 연산과정은 아래와 같다.
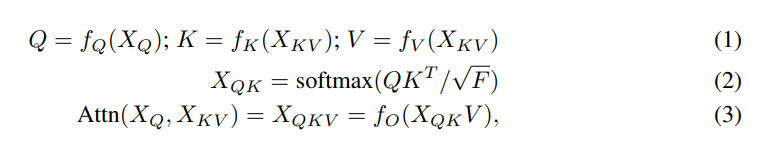
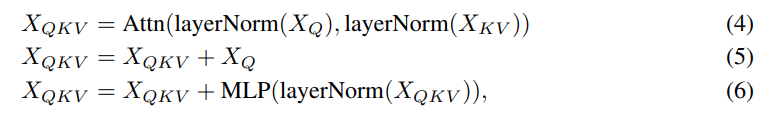
Encoding 과정을 예로 들어 설명하면, attention array 는 이고 는 다. 이후 는 MLP의 input으로 사용되어 최종적으로 를 생성한다. MLP는 두 층의 GELU로 구성되어 있다. 한편, Decoding의 경우 때때로 query가 input space의 feature를 담고 있기 때문에 이 경우, (5)과정이 없는 경우가 더 좋다고 한다.
Time complexity
각각 M, N, O를 input, latent, output array의 index dimension이라고 하자. 그리고 모든 레이어어가 F의 feature size를 갖고 L개의 Latent attention block이 있다고 하자. 그러면 모델의 complexity는 다음과 같다.
Input, output array size linear time complexity를 갖는다. 따라서 input/output size와 모델의 latent depth를 분리하여 구성할 수 있다.
기존 perceiver: quadratic -> perceiver IO: linear
experiments
1) Language
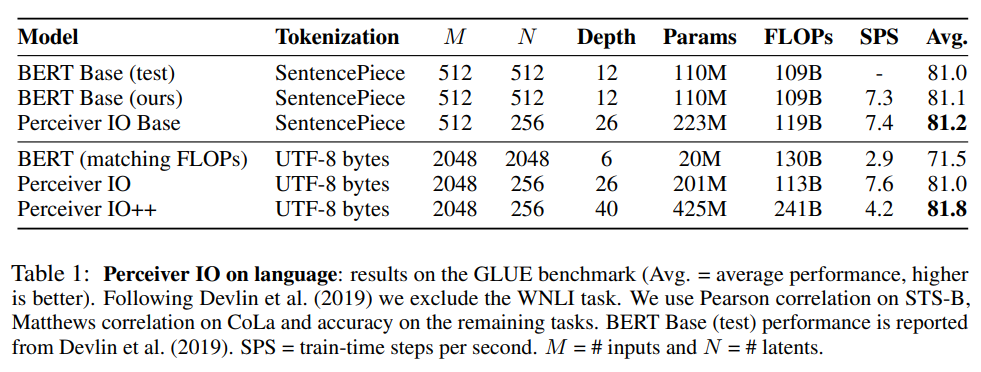
perceiver IO를 Standard Transformers for language 모델들과 비교하였다.
-
해당 실험은 Perceiver IO가 tokenization 과정을 거치지 않아도 masked language modeling에 대해서 토큰화를 거친 트랜스포머보다 더 우수한 성능을 보일 수 있다는 것을 보여준다.
-
모델이 얼마나 빠르게 동작하는지에 대한 metric인 FLOPs(Floating Point Operations)를 사용하여 모델을 비교 하였다. (훈련 시간과 직접적인 관련)
-
Perceiver IO에 SentencePiece 대신 UTF-8 bytes Tokenization을 적용하였다. raw byte input을 바로 사용하는 방식으로 regular transformer보다 더 긴 길이의 text를 다룰 수 있다.
-
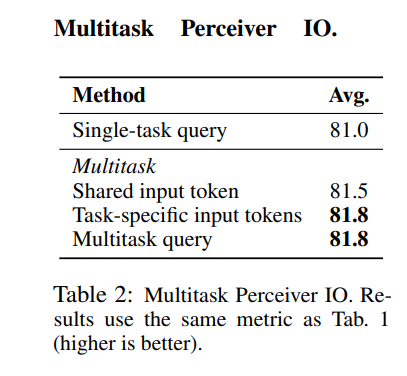
GLUE의 8가지 Task에 대하여 multi task와 single task를 수행했을 때의 성능 비교 실험을 하였다.
-
multitask queries를 사용하고, UTF-8 Byte를 사용한 모델이 single-task query보다 더 좋은 성능을 보이고 있다.
-
task들이 단일한 토큰을 공유하고 있는 경우(shared input token)보다 task-specific 토큰을 사용하는 경우의 성능이 좋았고, task-specific token을 사용한 것과 Multitask query를 사용한 것의 성능은 동일하다. Multitask query의 경우 [CLS]토큰을 사용하지 않기 때문에 더 generic한 방법이라고 볼 수 있다.
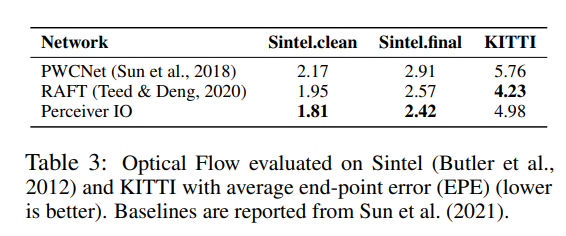
2) Optical Flow
Optical Flow는 영상 내 물체의 연속적인 움직임 패턴을 기록한 것이다. 같은 장면에 대한 두 개의 이미지가 주어졌을 때 첫 이미지에서 각 픽셀의 이동을 추정한다.
-
Perceiver IO에서는 두개의 Frame을 channel dimension을 따라 연결 한 후 각 픽셀 주변의 3*3 patch를 추출하는 방식을 취한다. 여기에 positional encoding을 추가한 후, Perceiver IO를 적용한다.
-
Optical Flow분야에서 주로 사용되는 PWCNet, RAFT 모델과 Sintel, KITTI에 대하여 비교를 진행하였다.
3) Mutimodal Autoencoding
Kinetics-700-2020 dataset에 대하여 audio-video-label multimodal autoencoding 작업에 Perceiver IO를 적용하는 실험을 진행하였다.
기존의 모델들은 각 모달리티를 결합하는 방식이 명확하지 않았다. (각 데이터마다 차원이 다르기 때문)
- Pervceiver IO 는 각 모달리티 별 Input에 각각의 모달리티에 특화된 방식의 임베딩을 적용하여 패딩을 수행한다.
- 이후 2D array로 직렬화를 한다.
- modality embedding과 positional encoding을 포함한 query를 사용하여 output을 생성한다.
- classification label을 masking하여 kinetics dataset을 classifier로 사용하여 평가를 진행하였다.
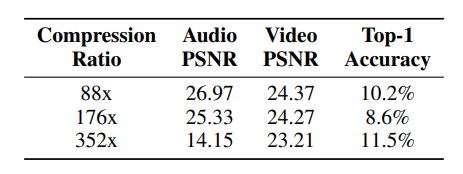
- 비디오, 오디오 PSNR과 classification accuracy 사이에 trade-off가 존재한다.
(PSNR(Peak signal to noise ratio)이 높을 수록 대체로 이미지/오디오의 품질이 좋다고 생각할 수 있다.) - classification에 가중을 두었을 때, video PSNR 20.7으로 유지하면서 top-1 accuracy 45%를 기록했다고 한다.

- reconstructions 실험 결과다. 왼쪽이 input, 오른쪽이 재구성된 결과물이다.
4) Imagenet, Starcraft II, And Audioset
-
Imagenet에서는 Perceiver IO가 2D Convolution을 사용하지 않고도 84.5%의 top-1 accuracy를 기록했다고 한다.
-
이하 생략...
Contribution
- input, output 사용의 generality를 획득하면서 model complexity는 linear하게 줄였다.
- Multimodal과 Mutitask를 다룰 수 있는 단순하고 통일된 setting을 제공하였다.
