📃 Paper : https://arxiv.org/pdf/2111.14447.pdf
💻 Code : https://github.com/YoadTew/zero-shot-image-to-text
한 줄 요약 : visual-semantic model을 large language model과 함께 사용하여 image input에 대한 descriptive text를 생성하는 모델에 대한 연구다.
Introduction
최근, computer vision 분야에서는 zero-shot capability에 대한 연구가 활발하게 진행되고 있다. 이와 관련된 연구로 openAI에서 발표한 모델 CLIP이 있다. 방대한 웹 (이미지,텍스트)쌍의 데이터로 사전학습된 모델로 수십가지의 다운스트림 태스크 수행이 가능하다. 그리고 또 다른 연구로 DALL-E (Ramesh et al.)가 있다. 주어진 test description에 맞는 적절한 이미지를 생성하는 모델이다.
✨ 본 논문에서는, CLIP모델과 GPT-2를 함께 사용하여 DALL-E모델과 정확히 반대의 역할을 하는, 주어진 Image에 대하여 text description을 생성하는 모델을 제안한다.

Problem
- How to provide zero-shot image captioning that brings together real-world variability and real-world Knowledge?
- How can we describe in words the difference between two images?
- How can we combine concepts from multiple images?
What is CLIP?
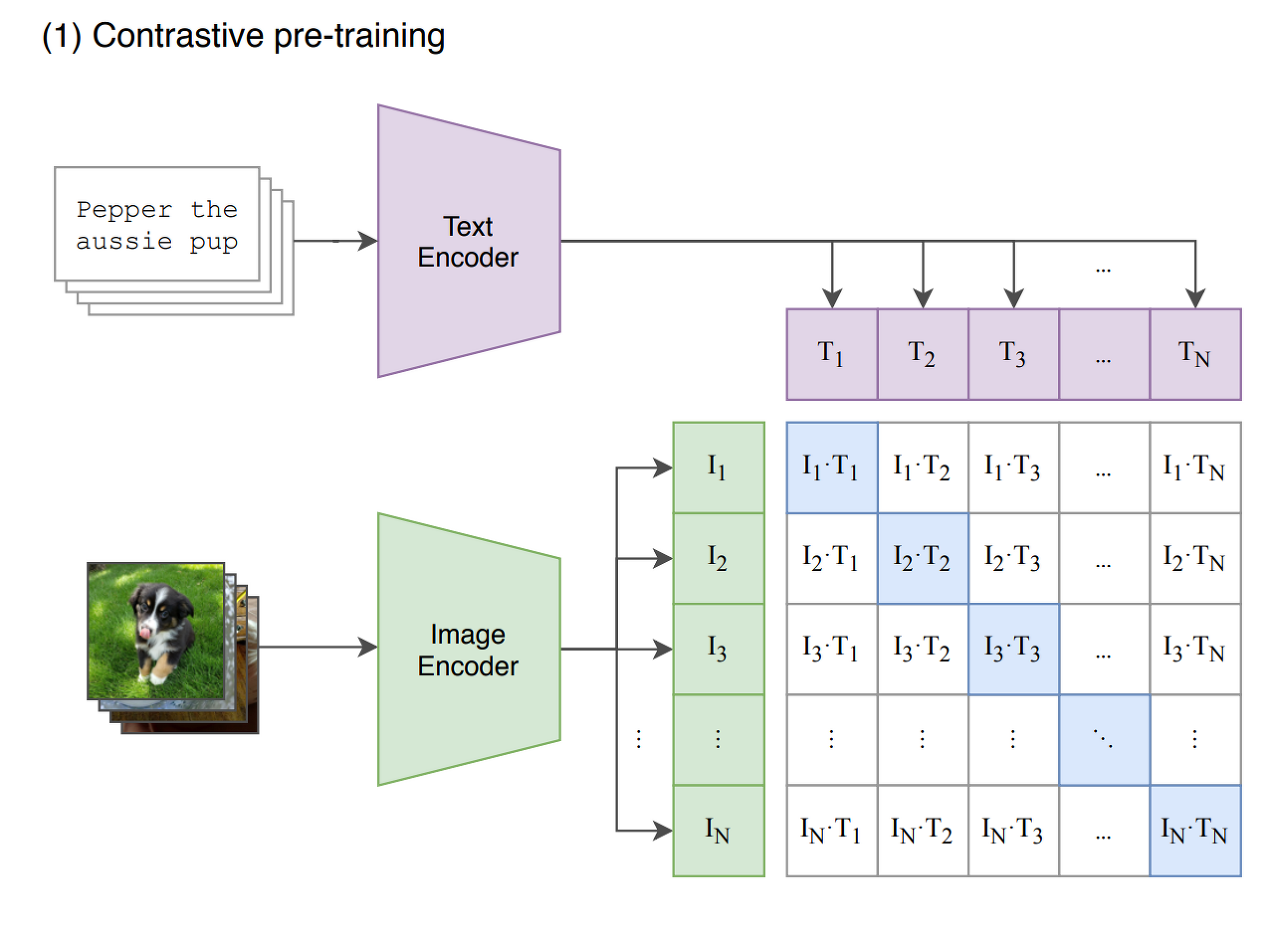
CLIP은 web-scale(4억개)의 (이미지, 텍스트)쌍으로 구성된 dataset, WebImageText(WIT)를 사전 학습한다.
N개의 (이미지, 텍스트) 쌍의 배치가 주어졌을 때, CLIP은 NXN개의 가능한 (이미지, 텍스트) 쌍을 예측하도록 학습된다. 이를 위해, CLIP은 N개의 실제 쌍의 이미지 임베딩과 텍스트 임베딩의 코사인 유사도(위 그림에서 파란색으로 색칠된 부분)을 최대화하고 N^2-N개의 잘못된 쌍의 코사인 유사도는 최소화하도록 이미지 인코더와 텍스트 인코더를 같이 학습함으로써 multi-modal 임베딩 공간을 학습한다.
Image encoder로는 ResNet, VIT(Vision transformer) Text encoder로는 Transformer를 사용한다.
Method
본 논문에서 새롭게 도입한 방식을 요약해보면 아래와 같다.
- CLIP loss 과 추가적인 loss term 사용
- semantic relations capturing through Visual-Semantic Arithmetic in CLIP'S embedding space.
- combining multi-modal encoders
이 방식들이 무엇인지 하나씩 살펴보도록 하자.
Model Method Overview
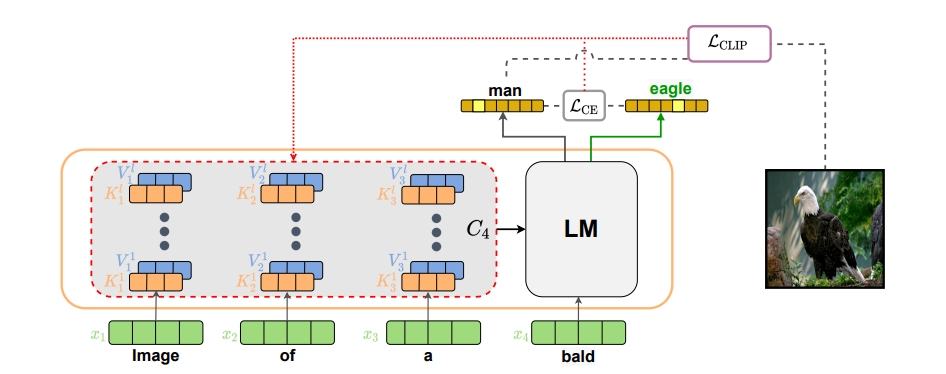
1. LM모델을 통해 "Image of a"와 같은 초기 prompt의 다음에 올 단어를 추론하게 된다.
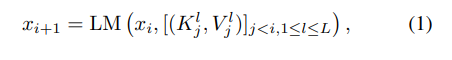
는 생성된 문장의 i번째 단어이고, 은 j번째 토큰의 트랜스포머에서의 key, value값이다. 은 트랜스포머 레이어 인덱스를 의미한다. auto-regressive한 방식으로 다음에 올 단어를 추론한다. GPT-2모델을 이용하기 때문에 전체 레이어의 수는 L=24개 이다.
은 반복적으로 사용되기 때문에, 'context cache'에 저장되어 있어야 한다.
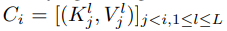
2. CLIP-Guided Language modeling
1) language model은 주어진 image에 맞는 방향으로 단어를 생성해야 한다.
2) 그리고 language attributes를 유지해야 한다.
첫번째 목표는 CLIP loss를 통해 토큰들과 이미지 간의 관련성을 계산하여 모델을 적절하게 조정하므로써 달성 가능하다.
두번째 목표를 위해서 추가적인 loss term을 사용한다. 이는 다음에 올 토큰의 분포가 원래의 language모델의 분포와 유사하도록 유지하는 역할을 한다.
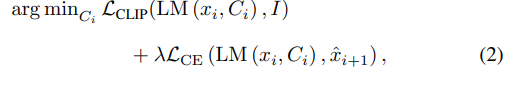
는 원래의 변동되지 않은 context cache를 이용한 토큰 분포다. 하이퍼파라미터 는 두 loss term간 균형을 맞추는 역할을 한다.
위의 optimization과정을 통해 context cache 를 매 타임 포인트마다 조정한다. Optimization은 auto-regression 과정 동안 이루어지며, 각 토근마다 반복된다.
그렇다면 CLIP Loss를 어떻게 계산하는지 살펴보자.
- 상위 512 token 후보들에 대한 potentials 을 계산하고 나머지 토큰들에는 zero potential로 설정한다. k번째 토큰 후보에 상응하는 sentence, 는 이미지 와 매칭된다.
은 text embedding(과 image embedding()간의 코사인 유사도다.은 target distribution의 sharpness를 조정하는 하이퍼파라미터다.2.CLIP loss는 clip potential distribution과 모델을 통해 얻은 토큰의 target distribution 사이의 cross-entropy loss를 계산한다.
clip loss는 이미지와 생성된 문장 사이의 매칭 스코어가 높아지게 한다.
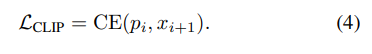
3. Inference
zero-shot method를 사용하기 때문에 추론 과정에서 추가적인 훈련은 이루어지지 않는다.
5단계의 gradient descent를 통해 를 update한다.

각 단계에서는 새롭게 생성된 토큰들이 추가되어 optimization이 재수행된다. (보통 다른 모델에서 수행되는 weight optimizing 과정이 없다.)
4. Visual-Semantic Arithmetic
NLP분야에서는 Word Embedding arithmetic이 사용되곤 한다. word2vec에서의 예를 살펴보면,
queen = 'king'-'man'+ 'woman'
위와 같이 되도록 단어를 벡터로 임베딩한다. 본 논문에서는 이러한 arithmetic을 image space에 적용하고자 하였다.
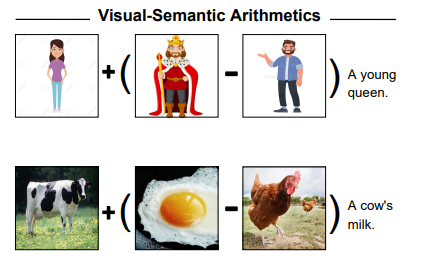
-
CLIP의 임베딩 공간에서 arithmetic을 수행하기 위해 우선 이미지/text를 clip의 인코더를 사용하여 인코딩한다 ().
-
요구되는 산술연산을 수행한다. 예)
-
2번 과정의 결과물을 3번 식의 대신 사용한다.
두 이미지의 차이가 무엇인지, 두 이미지의 의미를 비교할 수 있는 능력을 모델이 갖추게 되었다고 할 수 있다.
Experiments
Image Captioning study
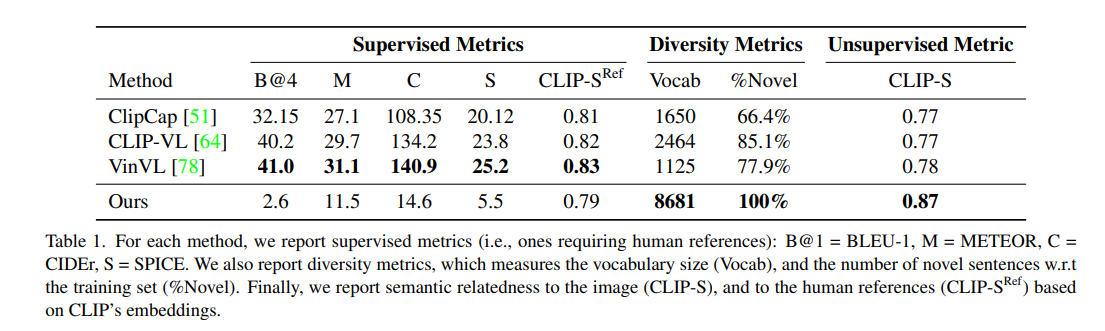
이미지 캡션 생성에 대한 모델의 zero-shot method의 성능을 테스트하기 위한 실험이다. COCO dataset의 test set을 사용하여 모델 test를 진행하였다.
-
supervised metric(i.e.,metrics requiring human references)에 대해서는 본 모델의 성능이 supervised captioning method를 사용한 baseline model들보다 현저하게 떨어지는 것을 확인할 수 있다.
-
diversity metric에 대해서는 본 모델이 가장 많은 단어를 생성해낸 것을 확인할 수 있다. 또한 모든 경우에서 훈련 데이터셋에서는 한번도 등장하지 않았던 문장을 생성해냈음을 알 수 있다. (100% on %Novel)
-
Unsupervised Metric, CLIP-S는 이미지와 캡션 사이의 관련성을 평가한 지표다. 이경우 본 논문의 모델이 가장 높은 성능을 보이고 있음을 확인할 수 있다.

OCR

이미지 안에 있는 텍스트를 구별해내는 능력에 대한 실험 결과다. 이경우 원래 method에서 사용하던 prompt"Image of a"를 "Image of text that says."로 바꿨다.
External Knowledge

생성된 캡션들은 다양한 주제에 대한 풍부한 현실 세계의 지식들로 구성될 수 있음을 보여준다.
Visual-Semantic Arithmetic Study
Subtraction : 벡터 간의 뺄셈은 직관적으로 벡터 사이의 방향을 표현한다.
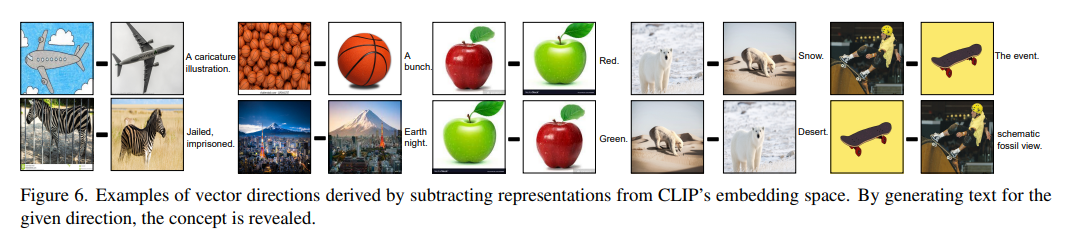
뺄셈 연산의 결과물에 대하여 text를 생성한 예시들이다. 비행기를 그린 그림에서 실제 비행기 이미지를 뺀 경우 "A caricature illustration"이라는 text가 생성된다. 반대로 "A caricature illustration"이라는 text에서 실제 비행기 이미지 사진을 더하는 연산을 수행하면 왼쪽의 비행기를 그린 그림 이미지가 매칭된다고 한다.
Summation : 덧셈 연산을 통해 생성된 text는 두개의 이미지가 갖고 있는 의미를 적절하게 합하여 표현한다.
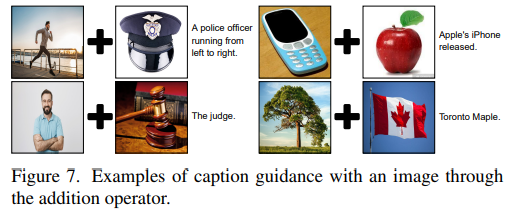
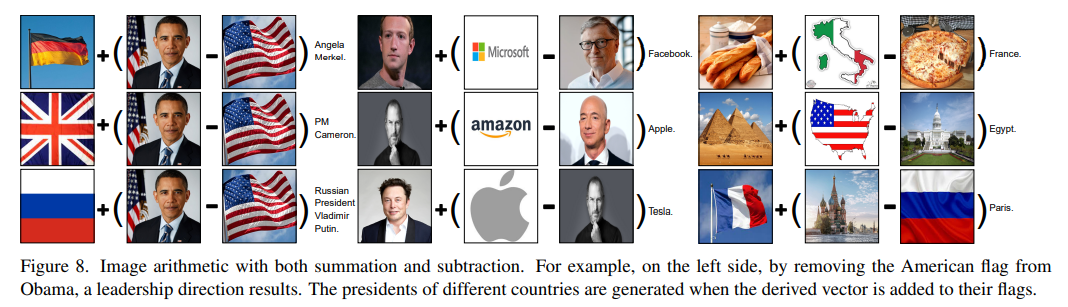
좀 더 풍부한 임베딩 공간을 사용하기위해 다음과 같은 전략을 사용하였다고 한다.
우선 뺄셈 을 진행하여 direction을 결정한 후 다양한 종류의 덧셈 연산을 수행하여 다양한 임베딩을 생성한다고 한다. 예를 들어 '오바마'이미지에서 '미국 국기'이미지를 빼는 연산을 통해 '리더십'의 개념을 생성한다. 그리고 이를 '독일 국기'이미지와 합하면 'Angela Merkel'을, '영국 국기'와 더하면 전)영국 총리 'Cameron'의 text를 생성한다고 한다.
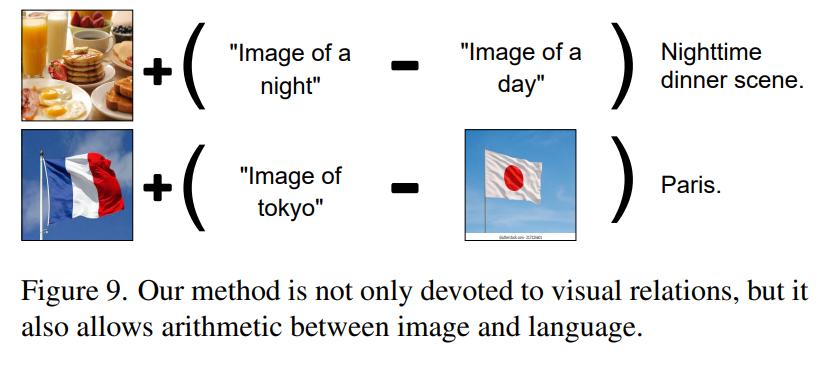
이 밖에도 이미지 혹은 텍스트 간의 연산 뿐만아니라, 이미지와 텍스트 사이의 연산도 수행 가능하다고 한다. (Mutimodal Arithmetic)
Limitation & Contribution
-
Contribution :
처음으로 visual-semantic을 생성하는 모델을 제안하였다.
Visual-semantic arithmetic을 제안하였다. -
Limitation:
model의 ability는 pre-trained models에 의존한다.
gpt-2보다 우수한 성능을 자랑하는 gpt-3 혹은 다른 새로운 언어모델을 적용한 연구가 필요하다.
사용된 LM과 image-language matching model은 필연적으로 biaes를 초래한다. Western knowledge에 집중되어 있기 때문에 다른 문화권의 이미지에 대해서는 제대로 text generation을 수행하지 못하였다고 한다. (예를들어, the president of china - '시진핑'의 relation을 형성하는데 실패했다고 한다...)
