[논문 리뷰] Sequence to Sequence Knowledge graph Completion and Question Answering (ACL, 2022)
논문 리뷰
1. Introduction
저자들은 Knowledge graph completion을 하는 method들이 아래와 같은 필요 조건들을 만족해야 좋은 모델이라고 말하고 있다.
- scalablility : have model size and inference time independent of the number of entities
- quality : reach good empirical performance
- versatility : be applicable for multiple tasks such as KGC and QA
- simplicity : consist of a single module with a standard architecture and training pipeline

저자들이 본 논문에서 제시하는 KGT5모델은 이 4가지 조건을 모두 충족한다고 한다.
2. Problem
- Pretrained for link prediction
- Finetune it for Qustion Answering
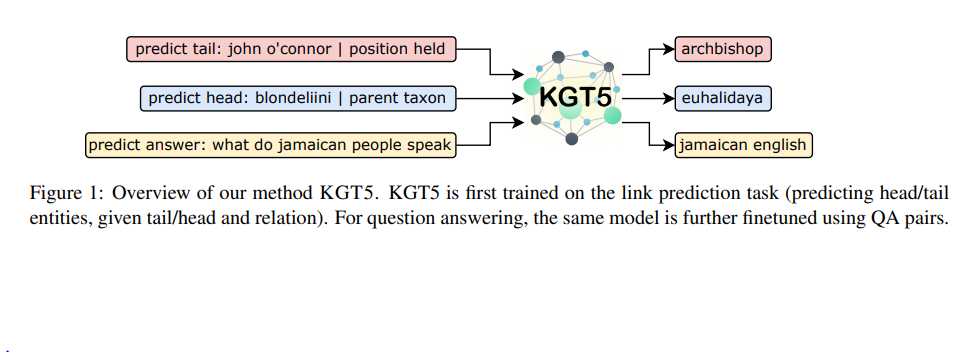
3. Method
- sequece to sequence model
- encoder-decoder transformer model (T5)
- Pretrained for link prediction
- finetune it for question answering
- while finetuning for QA, regularize with the link prediction objective.
✔ T5(Unified Text to text model) Architecture
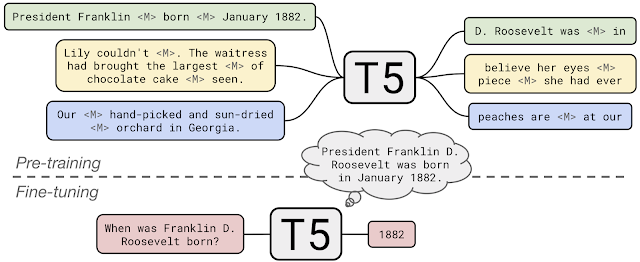
모든 언어 문제를 text-to-text task로 변환
basic encoder-decoder transformer architecure
simplicity : text-to-text 방식을 사용하면 여러가지 task에 대해서 동일한 모델 구조와 동일한 loss function을 사용할 수 있다.
이미지 출처 : https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
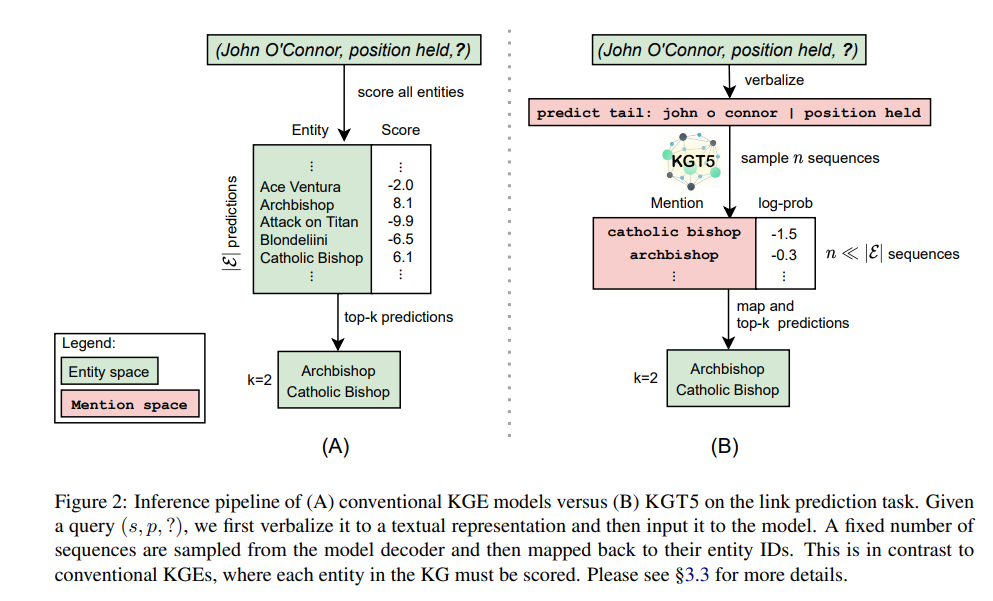
✔ KGT5 model Architecture
3-1. Textual Representation & Verbalization
1) Text mapping
For link prediction,
link prediction을 하기 위해서는 entity와 relation을 (통일된) text representation 형식으로 mapping 해주어야 한다. Wikidata-based KG의 경우에는 entity와 relation에 대해서 canonical mentions 을 textual representation으로 사용한다. canonical mention으로는 해당 entity(relation)의 wikidata page titles을 사용한다고 한다.
disambiguation scheme 존재 : 때때로 여러 개의 entity들이 동일한 canonical name을 갖는 경우가 존재한다. entity에 대한 description이 존재하는 경우에는 canonical name에 한 줄의 description을 덧붙여 representation으로 사용하고, 존재하지 않는 경우에는 unique id를 덧붙여 canonical name을 one-to-one mapping해준다고 한다.
For Qustion Answering,
disambiguation을 사용하지 않음. one-to-one mapping이 불필요.
2) Verbalization
(s,p,?) 을 text mapping과정을 거쳐 textual mention을 얻은 후, verbilize과정을 거친다.
(barak obama, born in, ?)
input : 'predict tail : barak obama | born in'
output : 'united states' (output은 entity 'United States'의 unique mention 이다.)
3-2. Training KGT5 for Link Prediction
In training, for each triple (s,p,o) verbalize the queries (s,p,?) , (?,p,o).
corresponding output sequences are the text mentions of o and repectively.
KGT5 trained with 'teacher forcing' and 'cross entropy loss'
There is no negative sampling.
✨Teacher forcing (교사강요)
RNN계열의 모델에서는 각 디코딩 step에서 다음에 올 토큰 예측을 위해 현재 시점의 INPUT과 이전 시점의 예측값을 사용한다. 그러나 이는 TEST시에 해당하는 과정이다. training 시 교사강요를 사용하면 이전 시점의 예측값을 INPUT으로 받는 것이 아니라, 이전 시점의 '실제값'을 INPUT으로 받아 다음 토큰의 예측을 진행한다. 그리고 모델이 예측한 값과 실제 레이블과의 오차를 계산하기 위해 크로스 엔트로피 손실 함수를 사용한다.
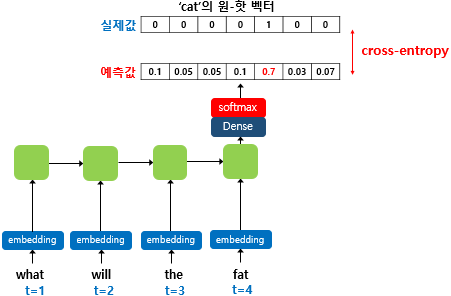
이미지 출처 : https://wikidocs.net/46496

3-3. Link Prediction Inference
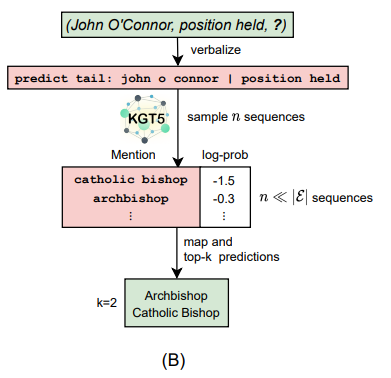
SAMPLING METHOD
다음에 올 단어 토큰 하나를 Autoregressive하게 예측하는 과정을 동일한 Input sequence에 대하여 여러번 수행하여 N개의 예측값을 얻는다. 이러한 방식을 통해 모든 entity에 대한 score를 구하는 수고를 피했다고 한다. (sampling size = 500 사용)
추가로 여러개의 예측 후보를 얻을 수 있는 또다른 방법인 BEAMSEARCH METHOD와 비교하는 실험을 진행하였다.
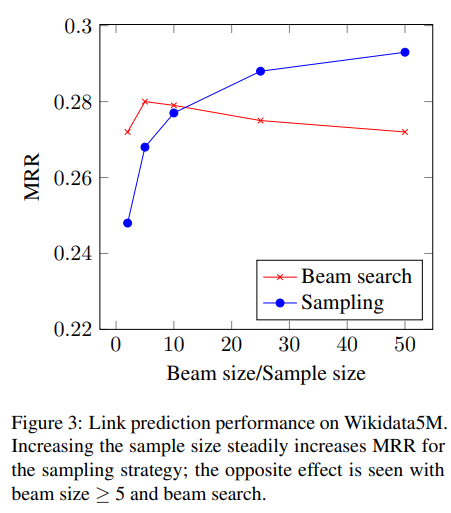
beamsearch의 경우 beam size가 5 이상이 되면 모델의 성능이 떨어진다.
3-4. KGQA Training and Inference
Question Answering task수행을 위해, 우선 모델을 앞서 설명한 link prediction task에 대하여 pretraining 한다. 그 후 모델을 QA task에 fine-tuning한다.
새로운 task를 위해 모델의 input은 주어진 question 앞에 'predict answer: '을 붙여 함께 모델에 주어진다. output은 answer entity의 mention string이다.
QA finetuning시 overffiting을 막기 위하여 QA의 배치에 link prediction sequence를 추가하는 방식으로 추가적인 정규화 과정을 진행했다고 한다.
(모델이 사전 학습한 KG에서 샘플링된 link prediction sequence를 QA sequence의 수와 동일하게 배치에 추가한다고 함.)
Inference단계에서는 beamsearch를 사용한다고 한다. (beam size=4)
4. Experiments
Datasets
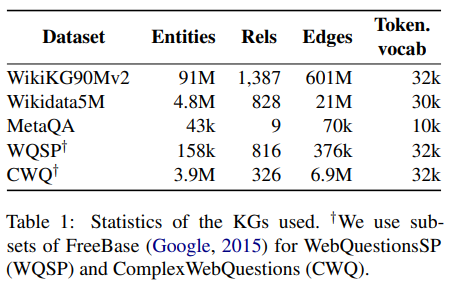
Experiments setup
for KGT5, There is no dataset specific hyperparameter tuning.
use same architecture, batch size, dropout and learning rate schedule throughout all experiments.
- neighbourhood based reranking for KGQA (topic entity annotation이 dataset에 있는 경우에만 진행)
: question
: topic entity from question
: predicted answer entity
: probablity of predicted entity
: hyperparameter
: n-hop neighbourhood of the topic entity (n=1,2 or 3)
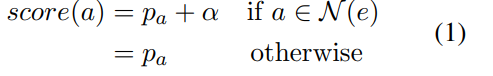
Link prediction
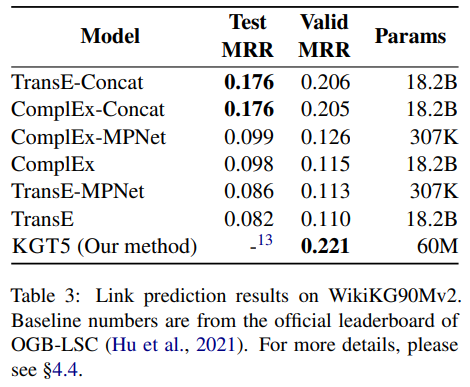
-MPNET,-Concat : entity representation으로 text embedding을 사용.
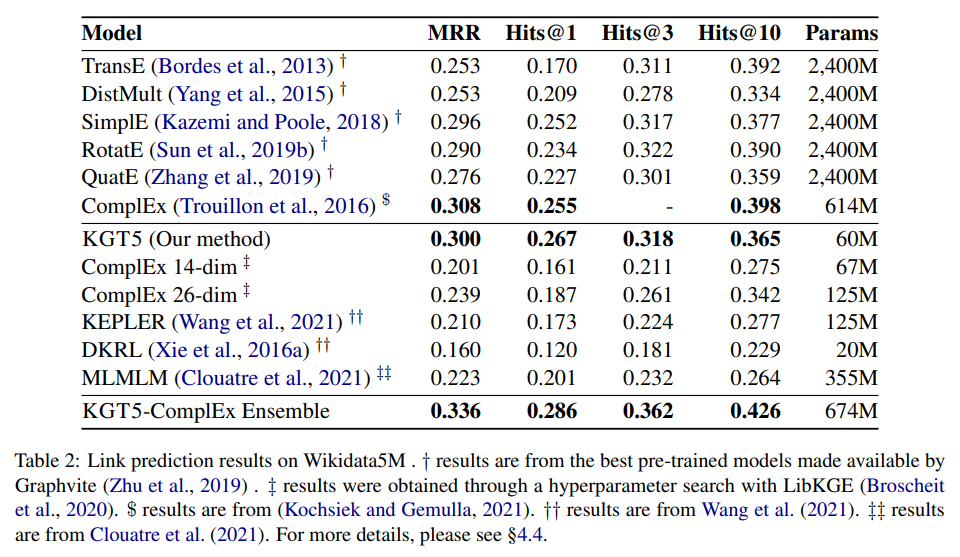
- KGT5-ComplEX Ensemble :
본 모델의 추론 단계에서 사용하는 sampling방식의 한계를 보완하고자 사용한 모델이다. sampling방식의 특성상 낮은 빈도를 갖는 sequence들은 sampling되기 어렵고 또한 올바르게 순위를 매기는 것도 어렵다.
쿼리의 정답이 trainKG에 존재하지 않으면 KGT5를 사용하고 그렇지 않으면 ComplEX를 사용하는 방식이다. (ComplEX: Wikidata5M 에서의 SOTA 모델.)
QA over Incomplete KGs
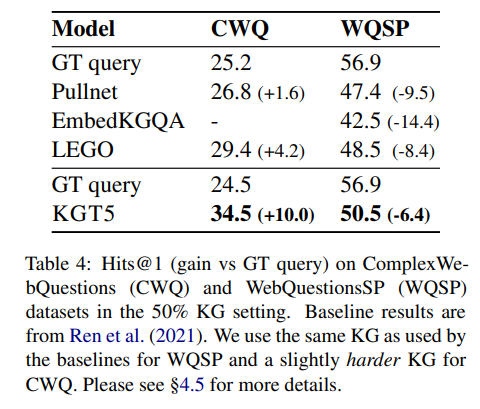
Knowledge Graph에 불완전성을 주기 위하여 랜덤하게 50%의 edge를 drop했다고 한다. 다른 비교 모델들의 경우 동일한 split상황에서 비교를 진행하기 어렵기 때문에 선행 연구(Ren et al.2021)에서 비교한 baseline결과와 동일한 split방식을 본 모델에도 적용하여 실험한 결과를 제시하였다.
GT query : ground truth SPARQL queries for test question.
KGT5모델은 복잡성과 SIZE측면에서 가장 까다로운 dataset인 CWQ에서 가장 큰 Performance gain을 보이고 있다.
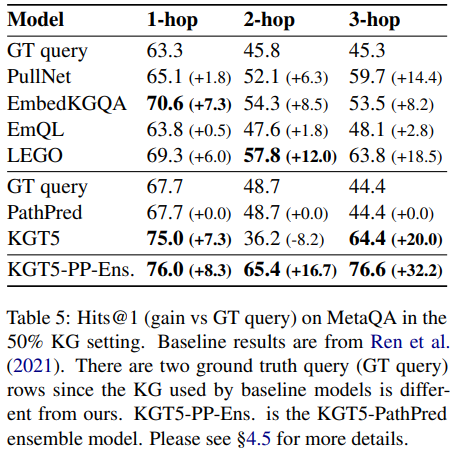
MetaQA dataset에는 1-hop에서 3-hop까지의 path를 거쳐서 추론을 해야하는 질문들이 존재한다.
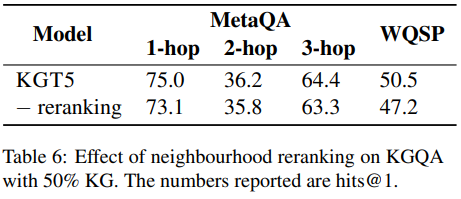
1-hop과 3-hop의 hits@1 결과는 KGT5가 다른 비교 모델들보다 좋은 성능을 보이고 있지만 2-hop에서는 더 나쁜 결과를 보이고 있다. 이 부분에 대해서 조사해본 결과, KGT5는 정답 엔티티와 head 엔티티의 타입이 같은 경우(ex. actor -> movie -> actor questions.)에 취약함을 보이고 있음을 알 수 있었는데, 1-hop과 2-hop에는 이런 데이터가 존재하지 않고 2-hop에만 존재한다고 한다.
이 문제에 대한 대안으로 KGT5 모델과 PathPred baseline을 앙상블한 모델을 추가로 제시하고 있다. (KGT5-PP-Ens.) 앙상블 모델은 질문 q가 주어졌을 때 우선 PathPred모델을 통해 정답을 구하고, 정답을 구하지 못하면 KGT5모델을 사용하는 방식으로 작동한다.
Ablation study on Reranking
KG vs LM pretraining
-
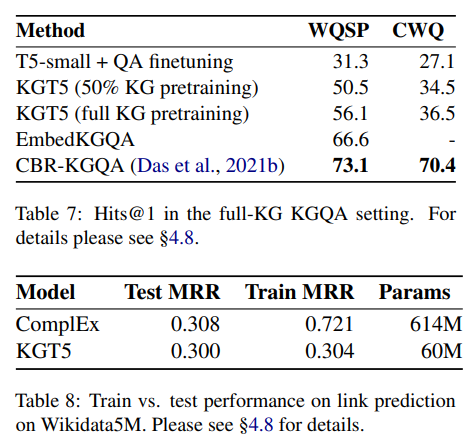
Tab7.에서 T5-small은 KGT5와 같은 구조를 가졌지만 KG 의 link prediction뿐만 아니라 여러 task에 대해서 pretraining된 모델이다. 이를 QA task에 대하여 KGT5와 성능 비교를 했을 때 KGT5의 성능이 훨씬 좋은 것을 알 수 있다.
-
KG의 50%만 Pretraining 했을떄와 전체 그래프를 pretraining 했을 때의 성능 차이는 그리 크지 않다. 그리고 EmbededKGQA(ComplEX based model), CBR-KGQA(semantic parsing method)의 다른 모델보다 성능이 떨어진다. 이는 KGT5가 보지 않은 요소에 대한 generalizing 능력은 갖추었지만, memorizing 능력은 떨어진다는 것을 알 수 있다.
이는 Tab8.의 결과에서도 확인할 수 있는데 TrainMRR이 ComplEX보다 확연히 떨어진 이유를 저자들은 KGT5모델이 파라미터 수가 적기 때문에 Pretraining시 본 요소들에 대하여 기억을 잘 하지 못하기 때문일 것이라고 설명하고 있다.
5. Contribution
- 모델 사이즈를 줄이면서도 큰 KG dataset을 다룰 수 있다.
(기존의 방법들과 비교했을때 최대 98%수준까지 모델 사이즈를 줄였다고 한다.) - 추가적인 모델 없이 동일한 모델로 link prediction과 down stream task(QA)를 할 수 있다.
6. Limitations
- Not good at memorizing facts.
- Textual mention 사용의 제한.
