1. Introduction
컴퓨팅 파워의 증가와 모델 능력의 향상으로 문법적으로 거의 완벽한 문장 단위의 자연어 텍스트를 생성해내는 것이 가능해졌다. 그러나 Scientific writing과 같이 다양한 topic들이 연관되어 있고 글의 순서가 중요한 프로세스,현상에 대하여 논리적인 텍스트를 생성해내는 것은 여전히 해결해야 할 문제이다.
특정 도메인에 대한 text writing은 그동안 sturctured inputs(구조화된 데이터)를 사용하는 방식으로 연구가 이루어져왔다. 특히, Information extraction system (IE) 을 통해 automatic하게 structured data를 구축하는 방식으로 연구가 이어져 왔다.
그러나 IE에는 분명한 한계가 존재한다. (challenges for generation such as erroneous annotations, structural variety, and significant abstraction of surface textual features)
2. Problem
- 몇가지 문제점이 존재하는 Information Extraction system(IE)대신 Graph의 자료구조를 사용하고자 한다. 따라서 IE의 output을 Knowledge Graph의 구조로 변형한다. 어떤 방식으로 바꿀 것인가?
- Knowledge graph to text : 방대한 Scientific articles의 abstracts(요약)자료에서 IE를 사용하여 정보를 추출 한 후 Knowledge Graph로 자료 구조를 변형한다. 이렇게 형성된 Knowledge Graph와 article의 title정보를 input으로 받아 article의 abstract를 생성하고자 한다.

3. Method
1.IE output -> connected unlabeled graph
2. provide a large knowledge graphs dataset paired with scientific texts.
3.graph transformer encoder : graph structured inputs -> generate sequences
3.1) The AGENDA Dataset
IE를 통해 추출된 정보를 Knowledge라 칭하자. 논리적이고 통일성있는 글을 생성하기 위해서는 knowledge의 local한 특성뿐만 아니라 global한 특성도 고려해야 한다. Graph의 자료구조는 이 두가지 특성 모두 고려할 수 있다.
본 논문에서는 당시 SOTA를 기록한 정보추출 시스템, SciIE를 통해 Knowledge를 추출하고, 이를 graph의 형식으로 바꾸어 'Abstract GENeration DAtaset(AGENDA)'를 제공한다.
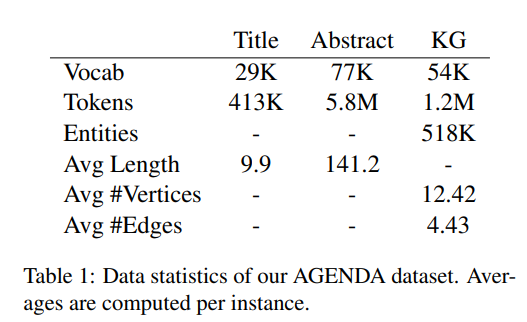
12개의 top AI conferences에 제출된 40k개의 논문의 title과 abstracts를 바탕으로 구성되었다.
SciIE를 통해 과학 용어에 대한 entity , entity types (Task, Method, Metric, Material, or Other Scientific Term)을 추출한다. 뿐만 아니라 co-reference annotations 그리고 7개의 relations (Compare, Used-for, Feature-of, Hyponym-of, Evaluate-for, and Conjunction)을 제공한다.
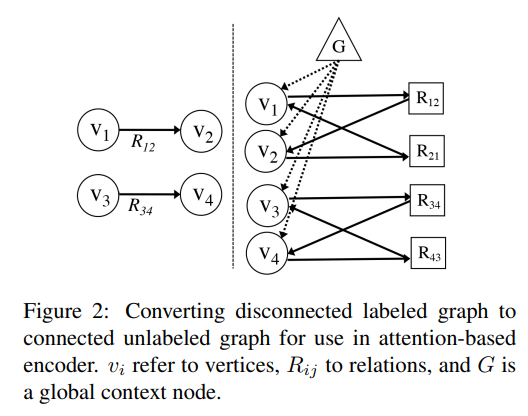
그리고 위의 그림처럼 'unlabeled connected bipartite graph'의 형식으로 바꾸어준다. 방식은 아래와 같다.
1) 각각의 labeled edge를 two vertices로 바꾼다. (forward direction과 reverse)
2) edge vertices를 entity vertices와 연결한다.
3) 모든 entity vertices를 연결하는 global vertex를 추가한다.
global vertex는 추후 디코더를 초기화하는데에 사용된다. (seq2seq에서 final encoder hidden state와 유사한 역할)
final result : , where is a list of entities, relations, global node and is ans adjacency matrix.
3.2) Graph Writer Model Overview
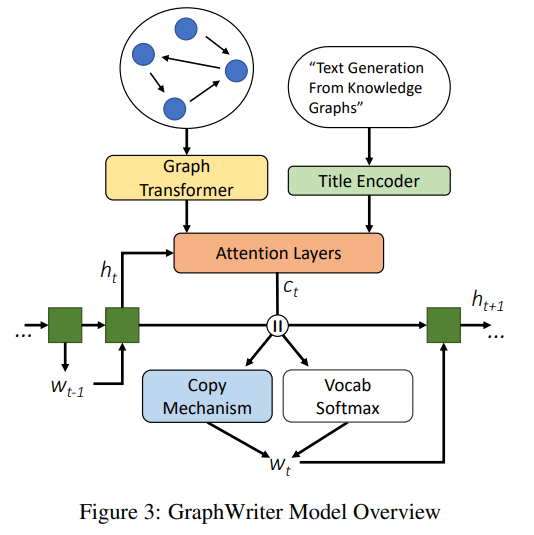
전체적인 모델의 구조는 Encoder-Decoder 구조를 따른다. Knowledge graph와 title을 input으로 받고 각각 다른 encoder를 거친다.
3.3) Encoder: Graph Transformer
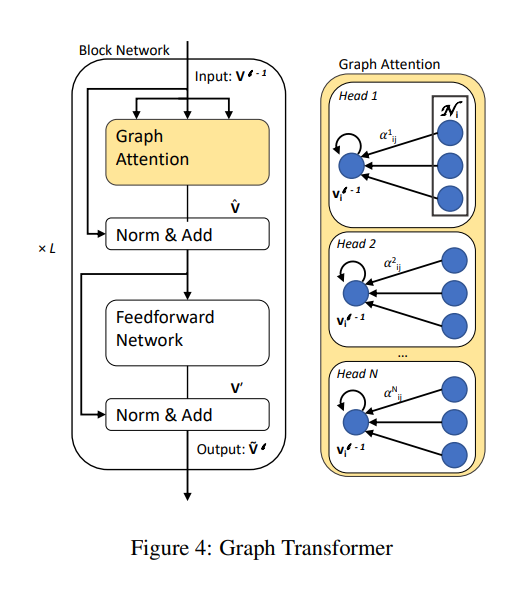
모델 구조는 Graph Attention Network(GAT), Velickovic et al.과 유사하다. 그러나 GAT에서는 인접한 노드로부터 온 정보를 통해서만 Vertex의 representation이 update된다는 단점이 존재했다. 본 논문에서는 transformer architecture를 사용하여 보다 global한 문맥 정보를 학습하도록 하였다.
1) 의 Embedding matrix
2) 는 연결된 이웃 vertex들과 N-headed self attention
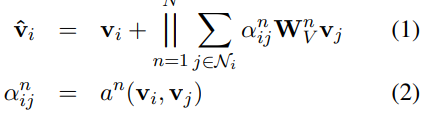
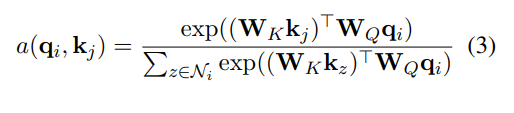
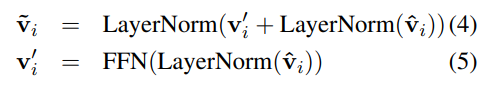
이러한 attention block 개를 거친다. layer의 output은 layer의 input으로 사용된다. Graph transformer 의 최종적인 결과물인 vertex encodings 은 entities, relations, global node의 representation이다. 본 논문에서는 인코딩의 결과물을 'graph contextualized vertex encodings'라 칭한다.
3.4) Embedding Vertices, Title Encoding
vertex embedding : , (: dense embedding, : entity phrase length)
앞서 살펴본 graph transformer의 input인 vertex embedding은 bidirectional RNN 의 last hidden state를 사용한다. RNN의 output embedding은 d차원의 각 vertex의 representation, 이다.
Title encoding :
3.5) Decoder
encoder와 마찬가지로 decoder역시 attention-based의 구조와 RNN 기반의 구조를 갖는다. 디코더의 각 time step에서는 decoder hidden state 를 각각 graph와 title sequence에 대한 context vectors 와 를 계산하는데에 사용된다.
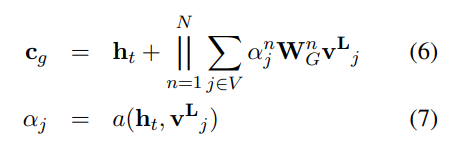
그래프 디코더의 초기값으로는 앞서 언급한 global vertex encoding output이 사용된다. t time step에서의 decoder hidden state와 graph contextualized encodings에 대하여 멀티헤드 어텐션을 진행한다. 또한 이와 유사하게 decoder hidden state와 title encoding의 멀티헤드어텐션을 거쳐 계산된다.
그리고 이 두 context vector를 concate하여 최종적인 context vector를 구한다.
그리고 , 둘 다 RNN의 next timestep의 input으로 사용된다. 다음으로 각 타임 스텝마다 예측될 단어 토큰에 대한 확률을 구하는 방식은 이 논문의 방식과 유사하게 따랐다고 한다. Get to the point: Summarization with Pointer generator network, See et al.(2017)
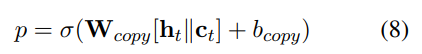
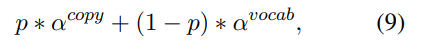
,
은 를 vocabulary size에 맞게 scaling한 후 softmax를 취하여 계산된다.
(??? knowledge graph의 copying entity 혹은 디코더의 vocab으로 부터 output을 선택하게 된다. 그리고 이 두 분포를 조정?
vocab의 확률 분포에 attention 확률 분포를 더하여 attention을 많이 준 단어를 강조하는? )

4. Experiments
GraphWriter를 통해 생성한 abstract에 대하여 human evaluation과 automatic evaluation 모두 진행하였다.
human evaluation의 경우 참가자들에게 2-3개의 abstacts를 주고
- grammar
- fluency: is the abstract written in well-formed English?
- coherence : does the abstract have an introduction, state the problem, describe a solution, and discuss evaluations or results?
- informativeness: does the abstract relate to the provided title and make use of appropriate scientific terms?
위 4가지를 평가기준으로 하여 worse와 best를 선택하도록 하였다.
automatic metric의 경우 BLEU와 METEOR를 사용하였다.
Comparisons 비교 모델에는 3가지가 있다.
- GAT : 본 모델의 Graph transformer encoder를 Graph Attention Network로 바꾸었다.
- EntityWriter : graph의 relation을 포함하는 것이 유용한지 실험하기 위해 Graph writer 모델에서 entities와 title정보만 사용한 모델을 비교군에 추가하였다.
- Rewriter : Wang et al.(2018) 논문의 모델로, 문서의 title 정보만 사용하여 반복적으로 title의 초안을 재작성하는 모델이다.
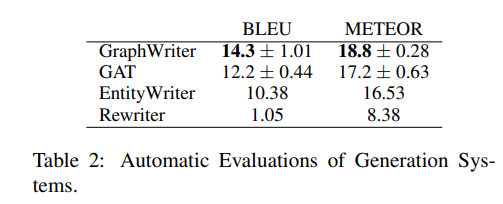
automatic metric으로 평가한 결과, Graph writer가 제일 우수한 성능을 보이고 있다. GAT보다 좋다는 것은 global contextualization이 더 좋은 텍스트를 생성해낸다는 것이고 EntityWriter보다 더 좋다는 것은 relation 정보를 사용하는 것이 더 좋은 텍스트를 생성한다는 것을 의미한다.

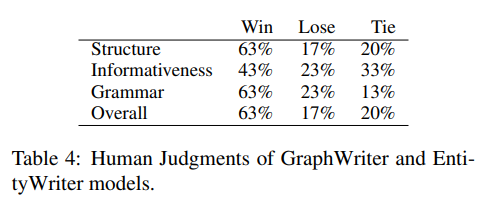

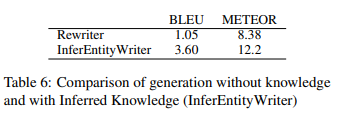
title 정보만 사용한 Rewriter모델과 보다 공정한 비교를 하기 위해 본 모델에 title에서 추론한 entities정보만 사용한 모델(InferEntityWriter)과 비교실험을 하였다. InferEntityWriter모델이 더 좋은 결과를 보이고 있다는 것은, 중간 예측 단계가 abstract generation에 도움이 된다는 것을 의미한다고 한다.
5. Limitation
-
Knowledge graph에 존재하는 40%의 엔티티들은 생성된 텍스트에 등장하지 않았다고 한다. 즉, 아직도 kg의 정보를 전부 활용하지는 못하고 있다는 의미다.
-
논문에서는 위의 문제에 대하여 inference 단계에서의 개선이 필요하다고 말하고 있다.
-
추가로, 모델이 생성한 전체 문장 중 18%는 문장 혹은 절(phrase)을 반복하고 있다고 한다.
