
Intro
- 통계학(Statistics) : 산술적 방법을 기초로, 다량의 데이터를 관찰하고 정리/분석하는 방법을 연구하는 분야.
▶ 근대 과학으로서의 통계학은 19세기 중반 벨기에의 케틀레가 독일의 "국상학"과 영국의 "정치산술"을 자연과학의 "확률 이론"과 결합하여 수립한 학문에서 발전

1) 기술통계학 (Descriptive Statistics)
- 데이터를 수집하고, 수집된 데이터를 쉽게 이해하고 설명할 수 있도록 정리/요약/설명하는 방법론
2) 추론통계학 (Inferential Stattistics)
- 모집단으로 부터 추출한 표본 데이터를 분석하여 모집단의 여러가지 특성을 추측하는 방법론

데이터의 이해
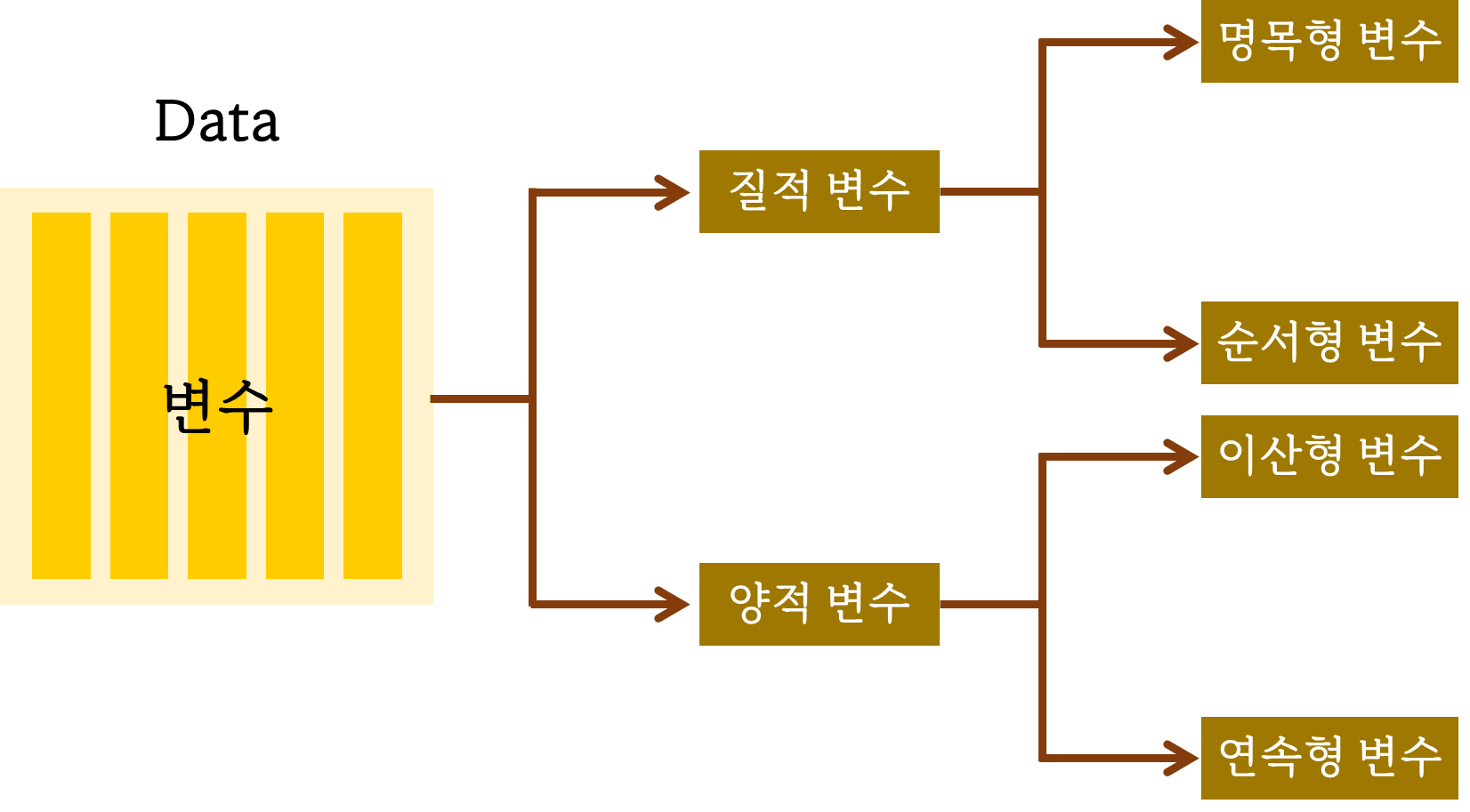
변수와 데이터
- 변수 (Variable)
- 수학에서 변수란, 어떤 정해지지 않은 임의의 값을 표현하기 위한 '기호'. 통상 '변하는 숫자'
- 통계학에서는 조사 목적에 따라 관측된 자료값을 변수 라고 함. 해당 변수에 대하여 관측된 값들이 바로 자료(Data) 가 된다.
- 질적 자료
- 명목형 변수 :관측된 데이터가 성별, 주소지, 업종 등과 같이 몇 개의 범주로 구분하여 표현할 수 있는 데이터를 의미.
- 데이터 입력시 1은 남자, 2는 여자로 표현간으하나 여기서 숫자의 의미는 없음
- 순서형 변수 : 교육수준, 건강상태
- 양적 자료
- 이산형 변수 : 관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있음 (시험성적 등)
- 연속형 변수 : 숫자를 표현할 때는 이산형 데이터와 연속형 데이터로 구분할 수 있음 (사람의 키, 몸무게 등)
- EDA (Exploratory Data Analysis)
-
데이터를 분석하는 과정 중 가장 많이 사용하는 분석방법을 Exploratory Data Analysis 라고 한다.
-
EDA는 데이터를 탐색하는 분석 방법으로, 도표, 그래프, 요약, 통계 등을 사용하여 데이터를 체계적으로 분석하는 하나의 방법 -
사용 목적
- 데이터 분석 프로젝트 초기에 가설을 수립하기 위해 사용
- 데이터 분석 프로젝트 초기에, 적절한 모델 및 기법의 선정
- 변수 간 트렌드, 패턴, 관계 등을 찾고 통계적 추론을 기반으로 가정을 평가
- 분석 데이터가 적절한지, 평가, 추가수집, 이상치 발견 등에 활용
데이터 시각화
-
데이터 시각화 (Data Visualization)
- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정.
- 목적은 도표 (graph)라는 수단을 통해 정보를 명확하고 효과적으로 전달하는 것.


그림 출처 : InfoGram Website
- 각종 그래프 참조사진
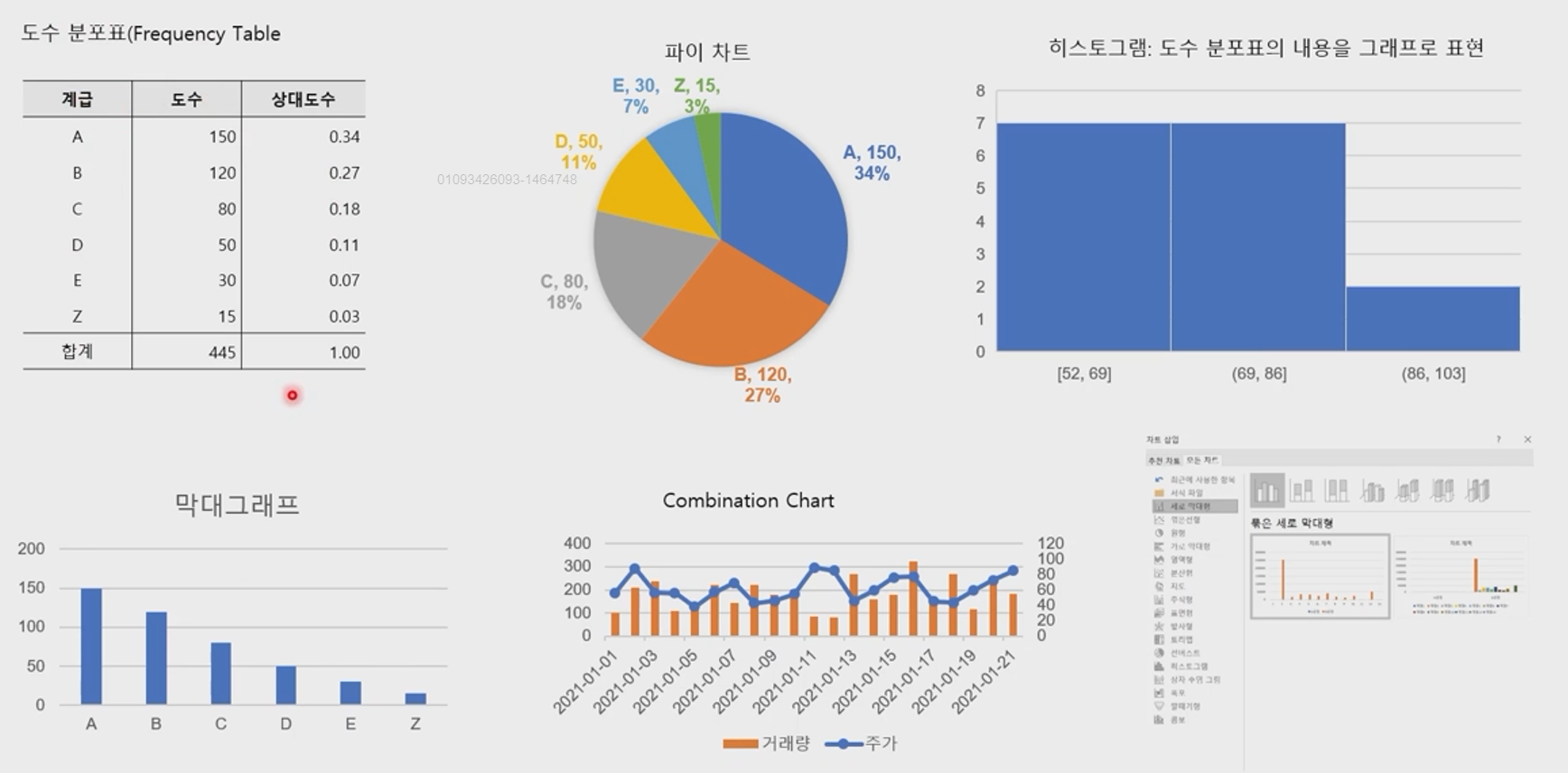
그림 출처 : Zero-base
데이터의 기초 통계량
기초통계량
- 통계량(statistic)은 표본으로 산출한 값으로, 기술통계량이라고도 표현.
- 통계량을 통해 데이터(표본)가 갖는 특성 이해
중심 경향치
- 표본(데이터)을 이해하기 위해서는 표본의 중심에 대해서 관심을 갖기 때문에 표본의 중심을 설명하는 값을 대표값이라 함. 이를
중심 경향치
-
대표적인
중심 경향치는 평균값이며, 중앙값, 최빈값, 절사 평균 등이 존재 -
평균은 모집단으로부터 관측된 n개의 x가 주어 졌을때, 아래와 같이 정의됨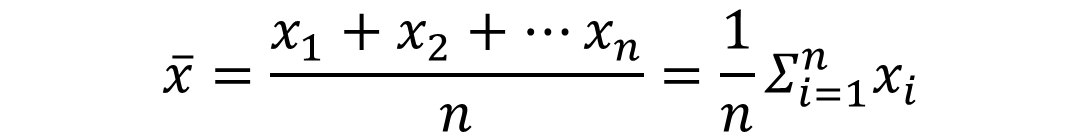
- 평균은 표본으로 추출된 표본평균(sample mean)이라고하며, 모집단의 평균을 모평균이라하여 𝜇 라고 표기함
중앙값(median)
-
평균과 같이 자주 사용하는 값
-
표본으로부터 관측치를 크기순으로 나열했을 때, 가운데 위치하는 값을 의미
-
관측치가 홀수일 경우 중앙에 위치하는 값이고, 짝수일 경우 가운데 두 개의 값을 산술평균한 값
-
이상치가 포함된 데이터에 대해서 사용
ex1) 80, 82, 84, 85, 90, 95, 100 → 85
ex2) 80, 82, 85, 90, 95, 95, 100 → 87.5
최빈값 (mode)
-
관측치 중에서 가장 많이 관측되는 값
-
옷사이즈와 같이 명목형 데이터의 경우 사용

산포도
- 데이터가 어떻게 흩어져 있는지를 확인하기 위해서는
중심경향치와 함께 산포에 대한 측도를 같이 고려 - 데이터의 산포도를 나타내는 측도로는 범위, 사분위수, 분산, 표준편차, 변동 계수 등이 있음
범위(Range)
- 데이터의 최대값과 최소값의 차이를 의미
사분위수(Quartile)
- 전체 데이터를 오름차순으로 정렬하여 4등분 하였을 때,
- 첫 번째 : 제 1사분위수(Q1)
- 두 번째 : 제 2사분위수(Q2)
- 세 번째 : 제 3사분위수(Q3)
- 네 번째 : 제 4사분위수(Q4)
백분위수(percentile)
-
전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값을 말하며, 제 p백분위수는 p%에 위치한 자료 값을 말함.
-
데이터를 오름차순으로 배열하고 자료가 n개 있을 때, 제 (100*p) 백분위수는 아래와 같다.
- np가 정수면, np번째와 np+1번째 자료의 평균
- np가 정수가 아니라면, np보다 큰 최소의 정수를 m이라고 할 때, m번째 자료
분산(Variance)
-
데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도
-
데이터의 각각의 값들의 편차 제곱함으로 계산하며 수식은 아래와 같다.
- 표본분산
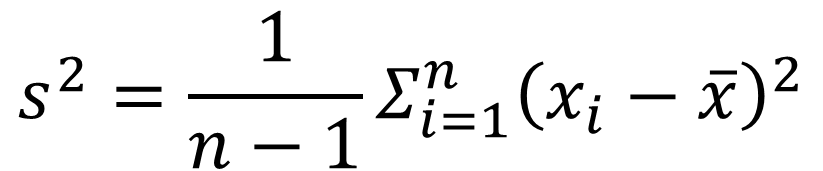
표준편차(Standard deviation)
-
분산의 제곱근으로 정의
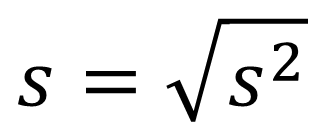
모분산
-
크가기 N인 모집단의 평균을 𝜇라고 할 때, 모평균과 모분산은 다음과 같다.
- 모분산
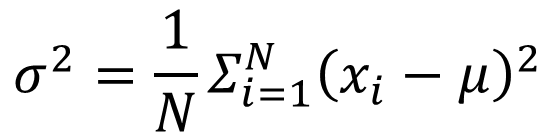
- 모표준편차
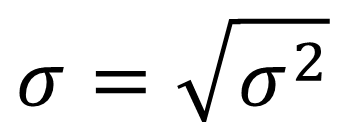
변동계수 (Coefficient of Variation:CV)
- 평균에서 다른 두 개 이상의 그룹의 표준편차를 비교할 때 사용
- 변동계수는 표준편차를 평균으로 나누어서 산출하여 단위, 조건에 상관없이 서로 다른 그룹의 산포를 비교하며 살제분석에서 자주 사용
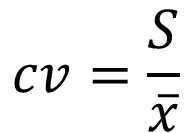
- 분포에 따른 데이터그래프 예시
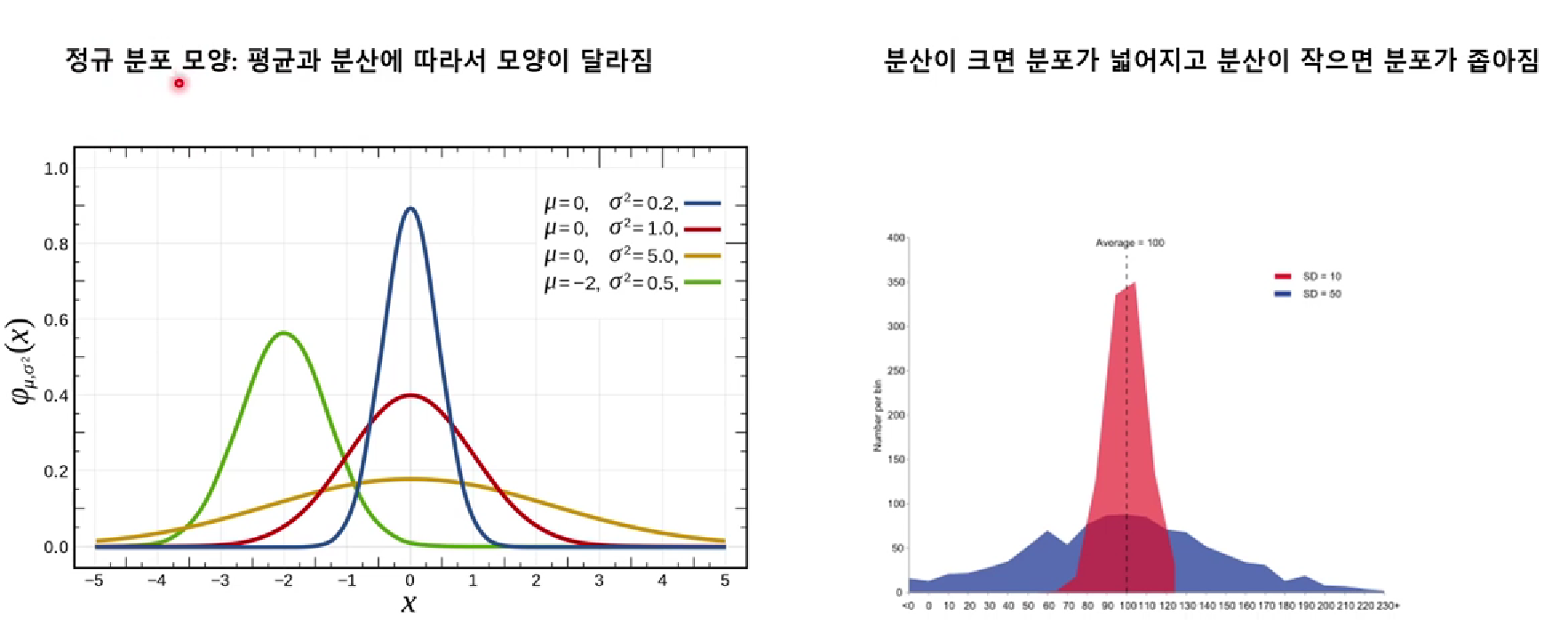
그림 출처 : Zero-base
분포에서 중요 그래프
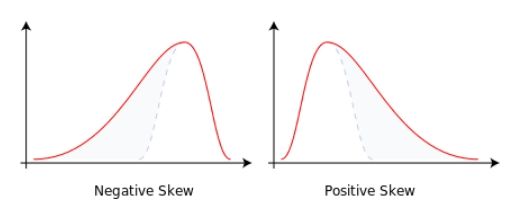
왜도 (skew)
- 자료의 분포가 얼마나 비대칭적인지 표현하는 지표
- 왜도가 0이면 좌우가 대칭, 0에서 클수록 우측꼬리가 길고, 0에서 작을수록 좌측 꼬리가 길다.
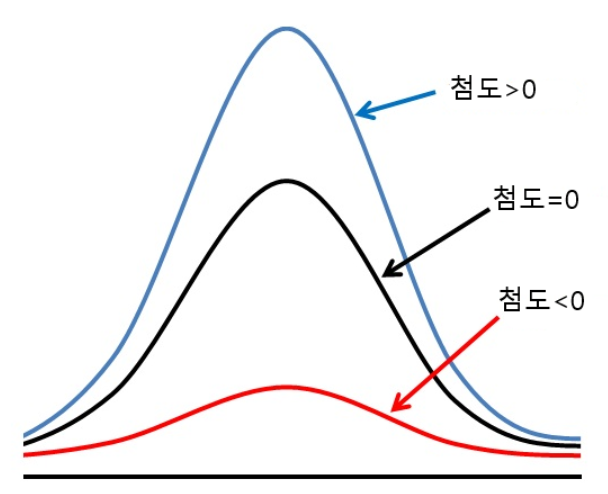
첨도 (kutosis)
- 확률분포의 꼬리가 두꺼운 정도를 나타내는 척도
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가까움
- 3보다 작을 경우에는 (K<3) 산포는 정규분포보다 꼬리가 얇은 분포
- 첨도값이 3보다 큰 양수이면 (K>3) 정규분포보다 꼬리가 두꺼운 분포로 판단.
확률 이론
확률 (Probability)
-
모든 경우의 수에 대한 특정 사건이 발생하는 비율
-
확률의 고전적 정의
- 어떤 사건의 발생확률은 그것이 일어날 수 있는 경우의 수 vs 가능한 모든 경우의 수 비.
- 단, 이는 어떠한 사건도 다른 사건들보다 더 많이 일어날 수 있다고 기대할 근거가 없을 때, 그러니깐 모든 사건이 동일하게 일어날 수 있다고 할 때에 성립한다.
-
표본 공간( Sample Space )
- 표본공간이란 어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합
-
통계적 확률 정의
- 어떤 시행을 N번 반복 시, 사건 A에 해당하는 결과가 r번 일어난 경우 r/N이고, 사건 A가 일어날 상대도수라고 함.
- N이 무한히 커지면 상대도수는 일정한 수로 수렴하는데, 이 극한값 lim_(𝑛→∞)(𝑟/𝑁)을 사건 A의 통계적 확률 또는 경험적 확률 이라고 함.
확률의 성질
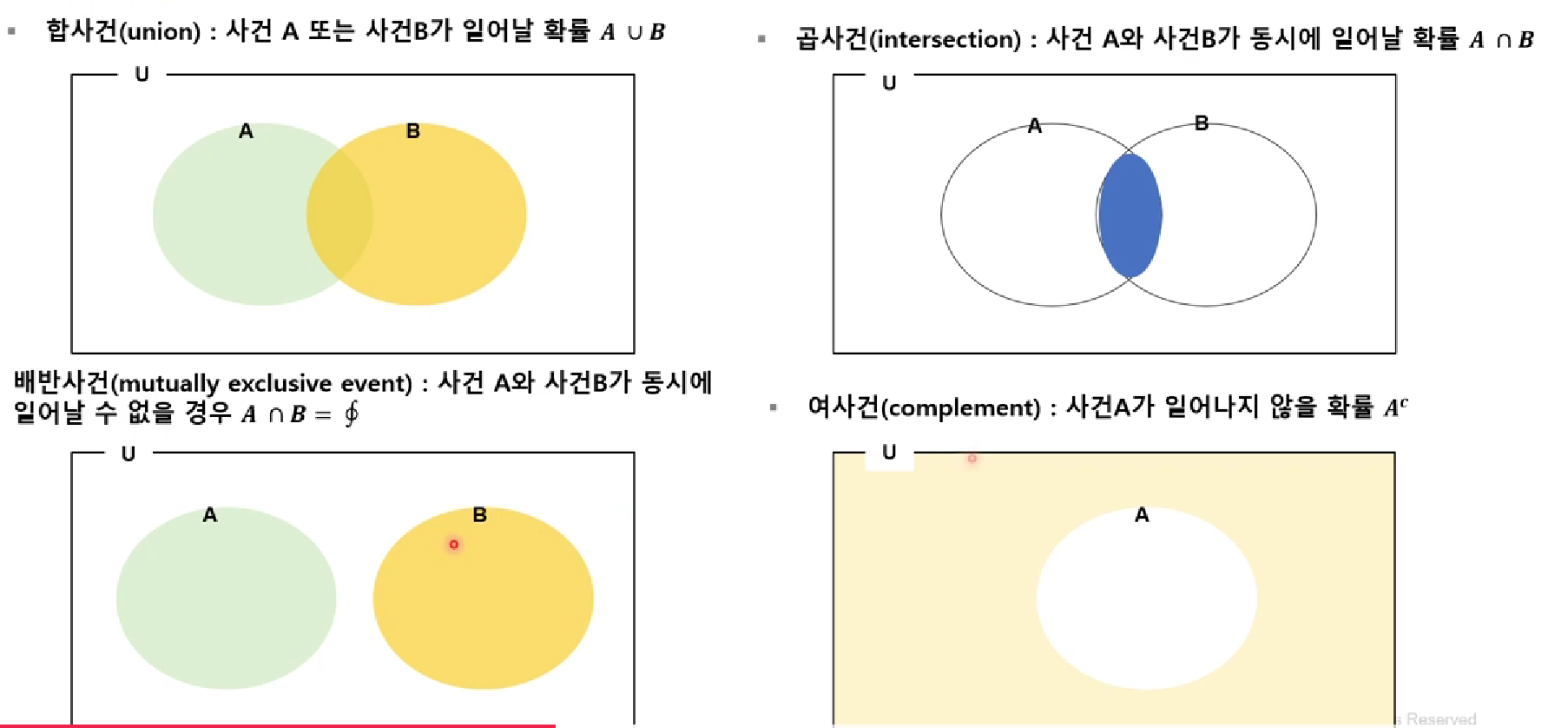
그림 출처 : Zero-base
- 확률의 덧셈법칙 : P(A U B) = P(A) + P(B) - P(A ∩ B)
- A와 B가 배반 사건이면, P(A ∩ B) = P(𝜙) = 0
- A의 여사건이 𝐴c이면, P(A) + P(Ac) = 1
예제) 1부터 13까지 13장의 카드에서 한장을 뽑는 실험
- A : 짝수를 뽑을 확률
- B : 5이하의 카드를 뽑을 확률
-
S = (1~13) → 1/13
- 사건 A = (2,4,6,8,10,12) = P(A) = 6/13
- 사건 B = (1,2,3,4,5) = P(B) = 5/13
- P(A ∩ B) = (2,4) = 2/13
-
P(A U B) = P(A) + P(B) - P(A ∩ B)
-
6/13 + 5/13 - 2/13 = 9/13
조합과 순열
-
! (Factorial) : n개를 일렬로 늘여놓은 경우의 수를
n!으로 표현 -
순열(Permutation) : 순서를 고려하여 n개 중 r개를 뽑아서 배열하는 경우의 수
nPr = n! / (n-r)!
-
조합(Combination) : 순서를 고려하지 않고 n개 중 r개를 뽑아서 배열하는 경우의 수
nCr = nPr / r! = n! / ( r! x (n-r)! )
조건부 확률
- Conditional Probability : 어떤 사건 A가 발생한 상황에서 또 하나의 사건 B가 발생할 확률

-
확률의 곱셈법칙
- P(A ∩ B) = P(A) x P(B|A) = P(B) x P(A|B)
- 사건 A와 B가 독립인 경우, P(A ∩ B) = P(A) x P(B)
베이즈 정리(Bays Theorem)
조건부 확률(Conditional Probability)
사건 B가 발생했을 때 사건 A가 발생할 확률은, 사건 B의 영향을 받아 변하게 될 수도 있습니다.
조건부 확률은 어떤 사건 B가 일어났을 때(여기서 P(B)>0으로 가정합니다), 사건 A가 일어날 확률을 의미합니다. 수식으로는 다음과 같이 정의 됩니다.

비슷한 원리로 만약 P(A)>0이라면 사건 A가 발생했을 때 사건 B가 발생할 확률은 다음과 같이 나타낼 수 있습니다.
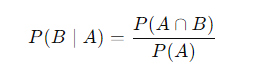
위의 두 식에 간단한 곱셈을 적용하여 우리는 아래의 식을 유추해 낼 수 있습니다. 단순해 보이고 별 의미 없어 보일 수 있지만 앞으로 매우 중요하게 쓰일 식이기 때문에 잘 알아두시면 좋습니다.
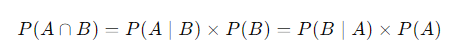
독립사건(Independence)
고등학교 수학시간에 두 사건이 서로 독립이라면 다음 식이 성립해야 한다고 배웠습니다.
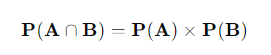
이를 사건이 n개가 있는 경우로 확장시키면 다음과 같이 나타낼 수 있습니다. 어떠한 1≤i1<⋯<ik≤n에 대해서도 다음 식을 만족시킨다면 사건 A1,⋯,An 를 독립인 사건이라고 합니다.
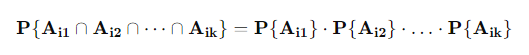
정의가 어렵게 느껴질 수 있어서 보충설명을 드리겠습니다. i1,⋯,ik 라는 숫자는 1에서 n까지의 숫자중 임의의 k개( n개 이하)를 뽑은 인덱스 입니다. 즉 n개의 사건 중 아무거나 k개뽑아서 교집합 한 확률이 각각 확률의 곱과 같다면 독립이라고 할 수 있습니다.
베이즈 정리(Bayes’ Law)
베이즈 정리를 정확히 배우기 전에 먼저 분할(Partition) 이라는 개념을 공부해야 합니다. K개의 집합 B1,⋯,BK가 어떤 집합 S의 분할이 되려면 두 조건을 만족해야 합니다.
첫번째로 B1,⋯,BK는 각각 서로소여야 합니다. 집합이 서로소 라는 것은 무작위로 두개를 뽑았을 때 겹치는 부분이 없어야 한다는 뜻입니다.
두번째로 K개의 B1,⋯,BK를 합집합 하였을때 그 집합은 정확히 S가 되어야 합니다. 이 두 조건을 만족해야 B1,⋯,BK를 S의 분할이라고 할 수 있습니다.
아래 그림에 좋은 예시를 첨부하여 놓았습니다. 집합 A1,A2,A3,A4는 각각 서로 겹치는 부분이 없고 합집합을 했을 때 A가 되므로 이들은 A의 분할이라고 할 수 있습니다.
자 이제 K개의 집합 B1,⋯,BK가 어떤 사건 S의 분할이라고 합시다. 그러면 모든 S의 부분집합 A에 대해서 다음과 같은 식이 성립하게 됩니다.
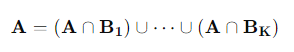
괄호안의 사건들이 각각 서로소이기 때문에 사건 A가 일어날 확률은 아래의 식과 같이 계산 할 수 있습니다.
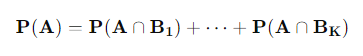
따라서 어떤 A 라는 사건이 일어났을때 Bj라는 사건이 일어날 조건부 확률은 다음과 같이 계산 할 수 있습니다.
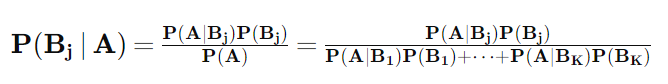
위의 식을 일반적으로 베이즈 정리라고 합니다. 단순한 수식장난으로 보일 수 있지만 통계학에서는 매우 중요한 의미를 가지고 있는 식이며 베이지안 통계학(Bayesian Statistics)라는 응용 통계학의 분야도 따로 있습니다. 또 머신러닝등 다양한 다른분야에서도 활발하게 활용되고 있습니다.
위 식에서 핵심은 사건 A가 일어났을 때의 확률( P(Bj|A) ) 을 계산함에 있어서 이를 거꾸로 뒤집어 B 가 일어났을때의 확률들( P(A|Bi) 들 )로 표현 할 수 있다는 것 입니다. 즉 A 가 조건으로 주어졌을 때 B 의 확률에 대해서 궁금했던 것을 반대로 B 가 조건으로 주어졌을 때 A 의 확률에 대해서 이야기 하는 것으로 바꾸어 쓸 수 있다는 것 입니다. 예제를 통해 적용되는 방식을 살펴보도록 하겠습니다.
어떤 주식이 그날 상승할 확률을 θ 라고 합시다. 우리는 일별 주가 데이터 분석을 통해 θ 값이 0.4일 확률이 50%이고 0.6일 확률이 50%임을 발견하였습니다. 이를 식으로 표현하면 다음과 같습니다.
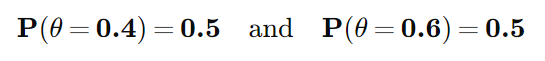
자 이제 또다른 데이터 관측을 통해 θ 값이 결정된 이후 주가가 3일연속 상승할 확률이 θ3 으로 주어짐을 알아냈습니다(여기서 서로 다른 날의 주가의 상승과 하락은 독립적이라고 가정하겠습니다). 그렇다면 주가가 3일연속 상승하였을 때, θ 값이 0.6인 확률은 얼마나 될까요?
문제를 쉽게 풀기 위해 주가가 3일연속 오른 사건을 A라고 하도록 하겠습니다. 그러면 우리가 구해야 되는 확률은 P(θ=0.6|A) 가 되고 이를 베이즈 정리를 통해 나타내면 그 값을 다음과 같이 계산 할 수 있습니다.
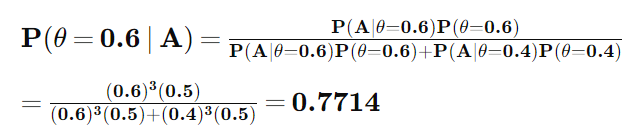
현재 가지고 있는 정보를 기초로하여 정한 초기확률 또는 확률 시행 전에 이미 가지고 있는 지식을 통해 부여한 확률을 사전확률(prior probability) 이라고 합니다. 위의 문제에서는 θ값이 0.4일 확률이 50%이고 0.6일 확률이 50% 라는 사실이 사전확률에 해당됩니다.
사건 발생 후에 어떤 원인으로부터 일어난 것이라고 생각되어지는 확률 또는 추가된 정보로부터 사전정보를 새롭게 수정한 확률을 사후확률(posterior probability) 라고 합니다. 사후확률은 위의 문제에서와 같이 조건부 확률을 통해 표현 할 수 있습니다. 베이즈 정리를 통해 구한 0.7714 라는 수치가 이 문제에서 사후확률에 해당합니다.
이처럼 베이즈 정리는 새로운 정보에 대해 어떻게 대응하여 결과를 도출 해낼지를 알려주는 강력한 도구가 되기 때문에 매우 중요합니다. 일반적으로 우리는 새로운 정보를 너무 무시하거나 과대평가하는 경향성을 가지고 있습니다. 그렇기 때문에 추가적인 정보를 받아들이고 올바른 방향으로 믿음을 수정하는 일은 생각보다 우리에게 매우 힘든 일입니다. 베이즈 정리는 이런 방향성에 대한 수학적인 가이드라인을 제공해 준다는 측면에서 그 중요성을 발견 할 수 있습니다.
출처 : https://junpyopark.github.io/bayes/
연습문제
- 자동차 보험의 고객의 분포 A등급 30%, B등급 50%, C등급 20%이고,
- 각 고객 등급별로 1년내 사고의 확률은 A등급 0.1, B등급 0.2, C등급 0.3이라면,
- 1) 임의의 한 고객을 선택하였을 때, 그 고객이 1년 이내의 사고를 낼 확률
- 2) 어떤 고객이 1년내 사고를 낸 고객이라면, 그 고객이 A등급일 확률
풀이) A등급 고객을 A1, B등급을 A2, C등급을 A3이라 하고, 1년이내 사고 낼 사건을 B라고 하면
- P(B) = P(B|A1) X P(A1) + P(B|A2) X P(A2) + P(B|A3) X P(A3) = 0.3X0.1 + 0.5X0.2 + 0.2X0.3 = 0.19
- P(Ai|B) = P(B|Ai) X P(Ai) / P(B) = 0.3X0.1 / 0.19 = 0.15789...
