2024.12.22
Part 11. 텐서플로
-
Chapter 00. 딥러닝 프레임워크
01. 딥러닝 프레임워크
02. TF_Pytorch 비교
03. 환경세팅 -
Chapter 01. Tensor 다루기
01. Constants
02. Variable
03. tensor연산
Chapter 00. 딥러닝 프레임워크
01. 딥러닝 프레임워크
Deep learning vs Machine learning 차이점 ?
→ 절대적인 계산량에 있다.그렇기에 딥러닝 프레임워크가 필요하다.
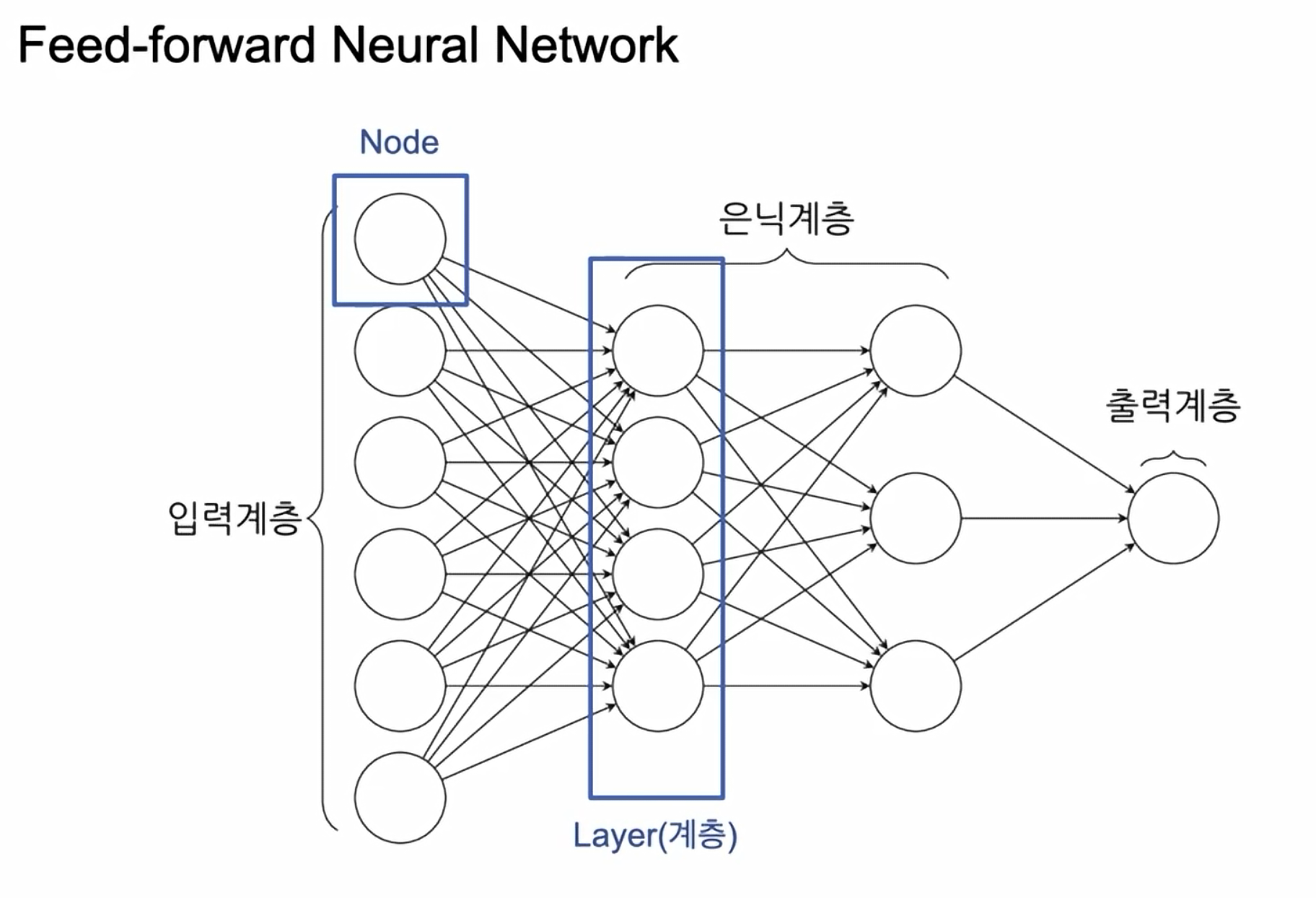
- 딥러닝의 가장 기본적인 형태. Node, layer, 입력계층, 은닉계층, 출력계층 등으로 이루어져있다.
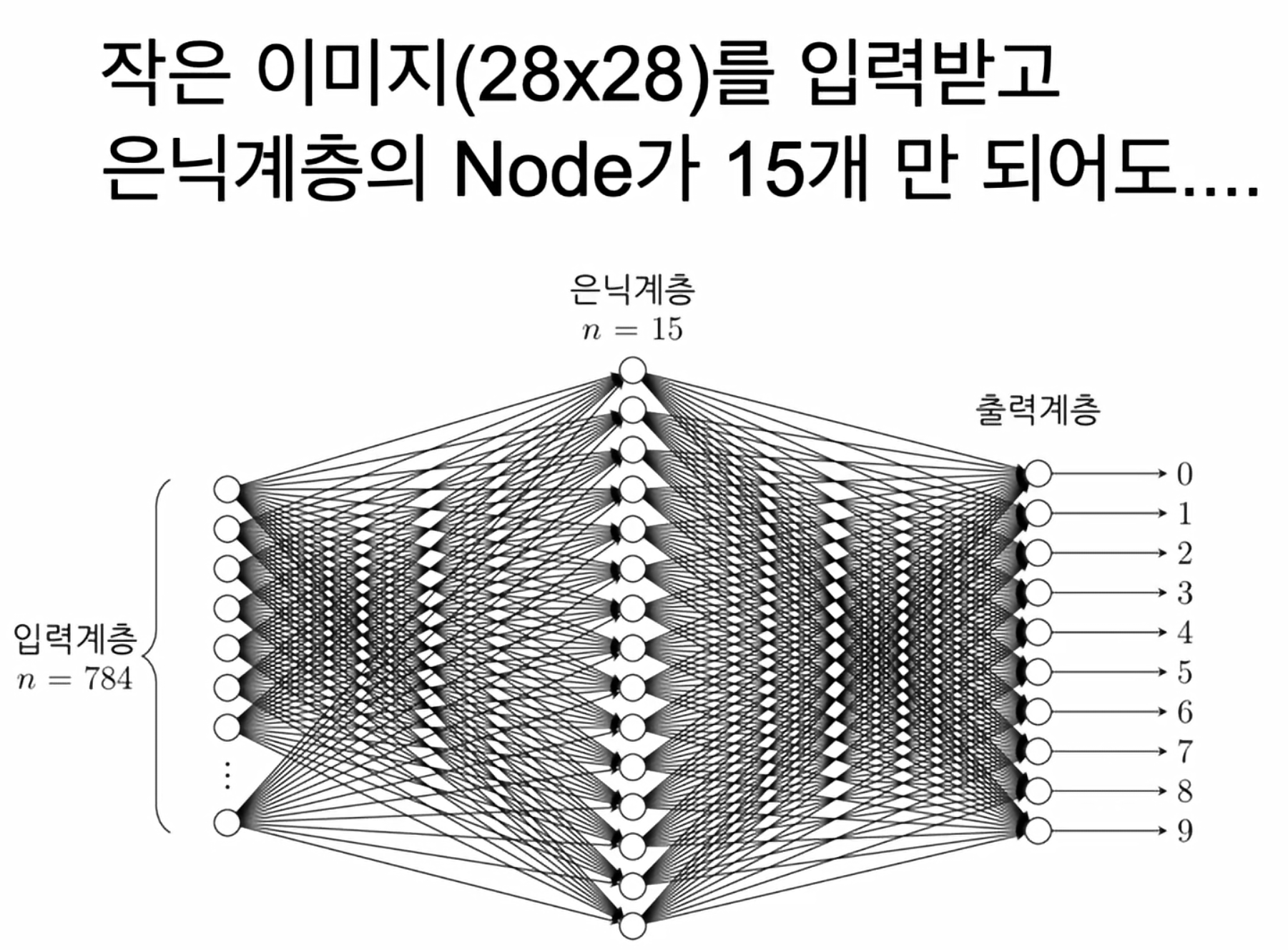
- 작은
28X28이미지로만 보아도, 엄청나게 많은 노드와 계산이 발생한다. - 그렇기에 딥러닝 모델의 성능이 나오지 않을 수 있다.
딥러닝이 풀어야하는 과제들은 수학적으로 표현하기 힘든 것들이 많다. 이미지, 소리, 영상 등등..

어마어마한 연산량이 발생하게 된다.
그렇기에 딥러닝과 기존 머신러닝의 큰 차이는 결국 연산량에 있다.
근데 똑똑하신 분들이 이 많은 연산량을 해결하기 위해,
분산처리,병렬처리,동시처리를 만들어 냈다.
결국 딥러닝 프레임워크는 GPU 등을 이용해서 위 작업들을 하기 쉽게 만들어주는 도구이다!!

- 결국 4가지만 할 줄 알면
딥러닝 프레임워크를 익혔다고 볼 수 있음
1. Tensor 생성하고 다루기
2. 연산 정의 ( 모델을 어떻게 연결할 것인가 ? )
3. 최적화 (미분)
4. 데이터 다루기
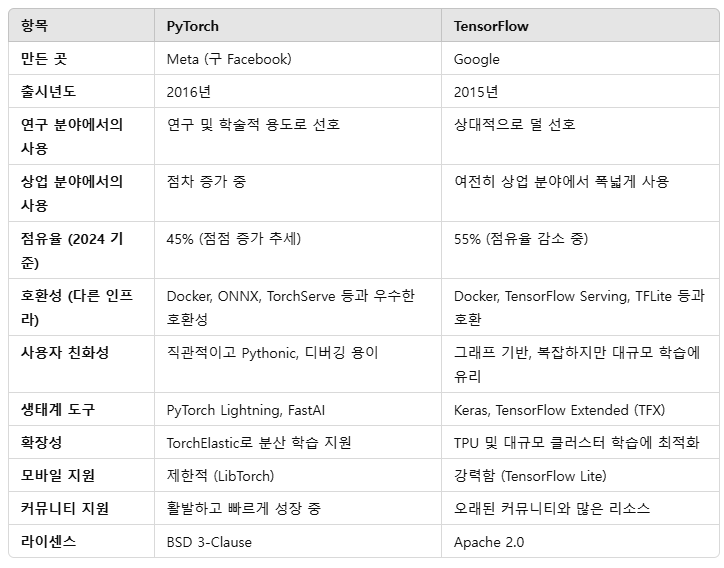
02. TensorFlow vs PyTorch 비교
- 실제 연구 필드에서는
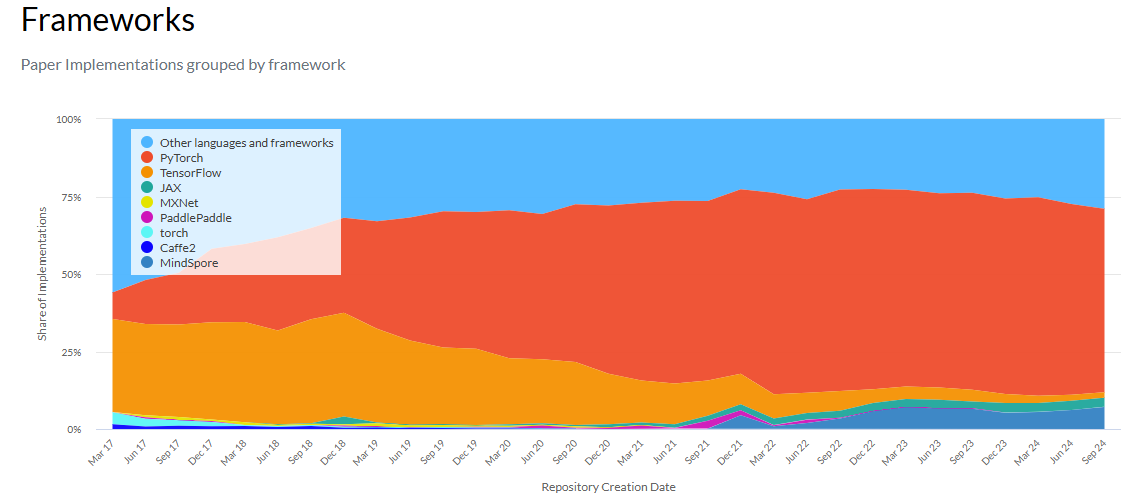
PyTorch를 많이 쓰고있다. TensorFlow대비해서PyTorch가 거의 9:1 비율로PyTorch를 많이 사용하고 있다.
- 해당 사이트에서 트렌드를 보면 아래의 그래프와 같다. paperswithcode
PyTorch가 연구,논문분야에서는 압도적으로 많이 사용된다.- 단, 앱, 웹 등 실용/산업분야에서는 아직
TensorFlow가 많이, 범용적으로 적용되는것을 확인할 수 있다.
- 다만,
PyTorch는 페이스북,TensorFlow는 구글에서 만들어짐. 구글에서는 대부분 tf를 많이 사용함.- 또한 위에서 기재했듯이, 상업/기업/상품화에 있어서는
TensorFlow가 훨씬 안정적이고, 다양한 옵션이 제공됨.
03. 환경세팅
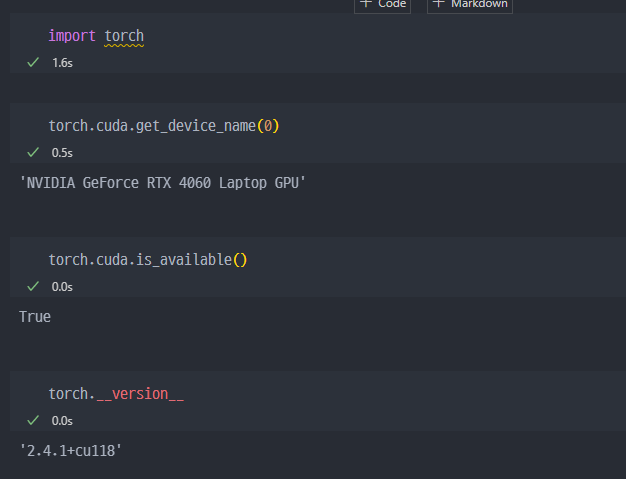
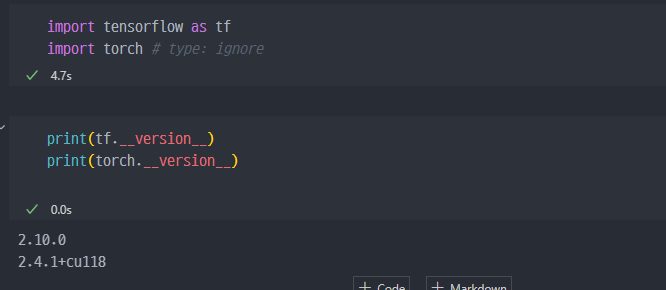
Colab으로 사용하면 컴퓨터에 설치 없이 바로 사용가능하다.- 또는
TensorFlow및PyTorch를install해준다.

- 아래처럼
Import에 문제가 없는지, 사용하는 디바이스가 무엇인지 등 확인할 수 있다.TensorFlow와TensorFlow-GPU셋팅 이후에PyTorch를 다운로드하는데, 별달리 추가설치 없이 라이브러리, 패키지만 콘다에서 인스톨해주면 나머지는TensorFlow환경과 연동되는지 바로 사용이 된다.
TensorFlow다운로드 학습자료 참고

Chapter 01. Tensor 다루기
01. Constants
Tensor란?
- Tensor
- Deep learning FrameWork는 기본적으로
Tensor를 다루는 도구이다. Tensor를 다룰때 가장 중요한 것!! → SHAPE!!!- 제일 에러가 많이 나는 이유이며, 제일 헷갈리는 것. 개발할 때 우리가 이론을 알아야 하는 이유, 함수들의 설정값을 확인해야 하는 이유들이 해당된다.
- Deep learning FrameWork는 기본적으로
- Tensor 생성
- 우리가 생성하는 것은
tf.Tensor데이터!! - 항상 체크해야 하는 것!!
- SHAPE
- dtype (데이터 타입이 같아야 연산이 가능하다)
- 우리가 생성하는 것은
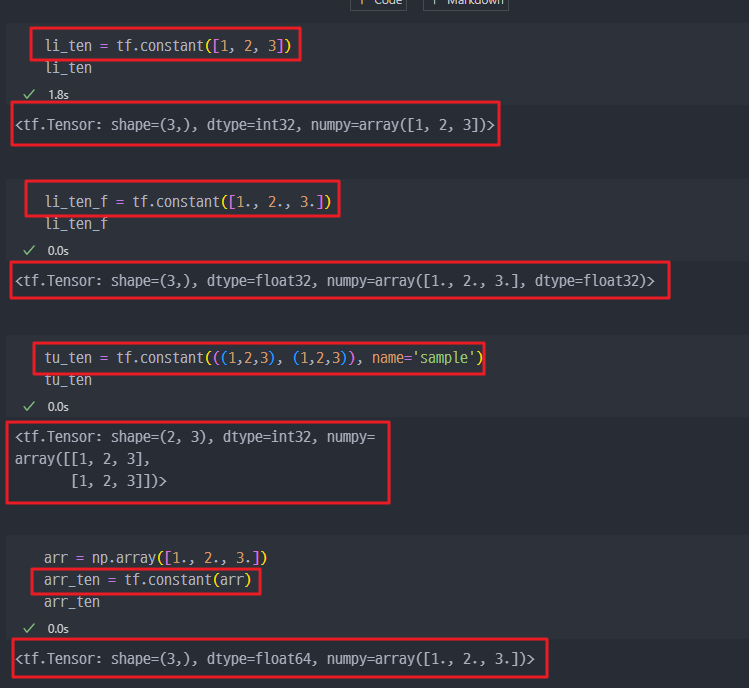
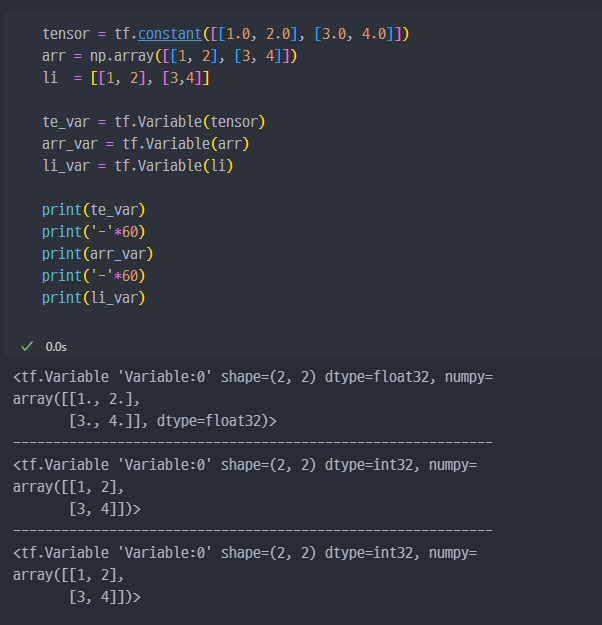
- Constant(상수)
tf.constant()list→ Tensortuple→ TensorArray→ Tensor
숫자(상수)를 어떻게 생성하냐?? → 리스트, 튜플, Array로 생성하고
Tensor로 만들면 된다!!
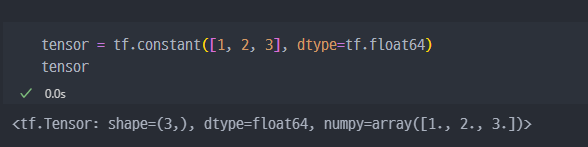
기존에 있는 데이터를Tensor로 변경
numpy.array에서 변경하면float64타입으로 된다.
- 모바일 등에서는 16bit 타입을 많이 쓴다. 성능의 하락보다 속도의 상승을 더 좋아하기 때문이다.
tf.matmul=행렬 곱셈(matrix multiplication)- 단, 같은 shape, 같은 dtype 에서만 적용가능하다.
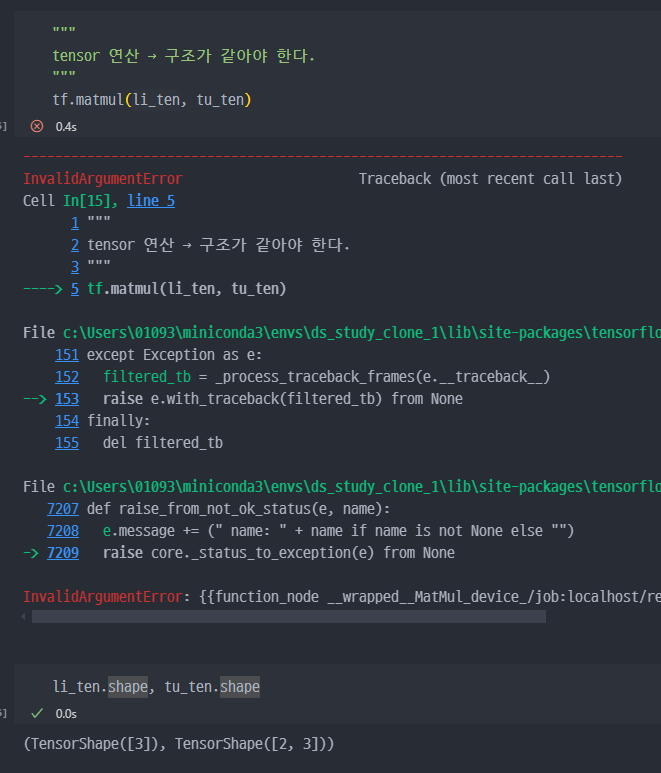
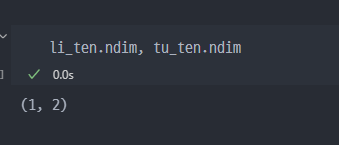
랭크수 확인 명령어
데이터타입 컨트롤
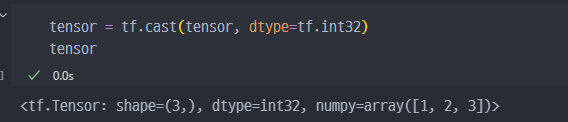
tf.cast→ 데이터 타입 컨트롤 방법- 미리 지정 : dtype=tf.float64 .. 등
tf.cast로 기존의tensor dtype변경
간단퀴즈
- 간단퀴즈 : 오류없이 아래의 코드 실행
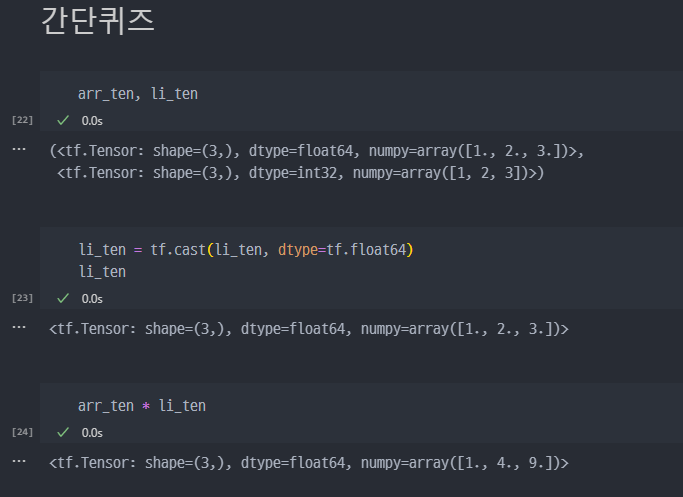
특정 값의 Tensor 생성
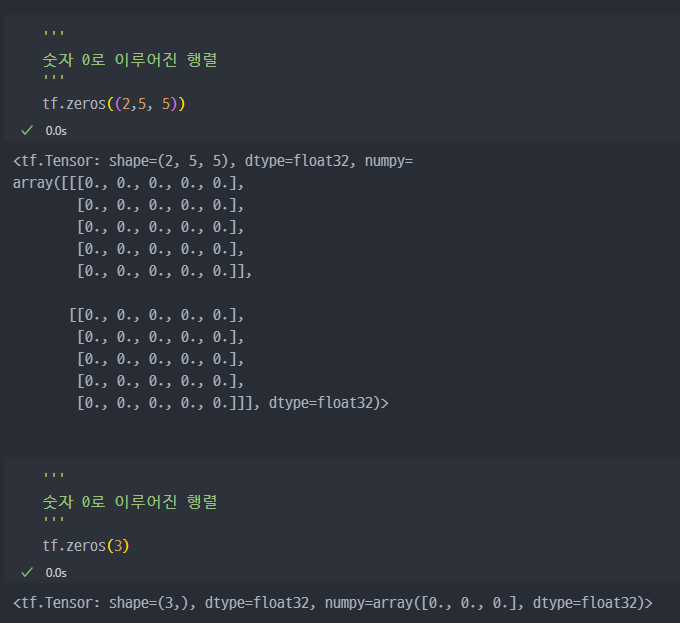
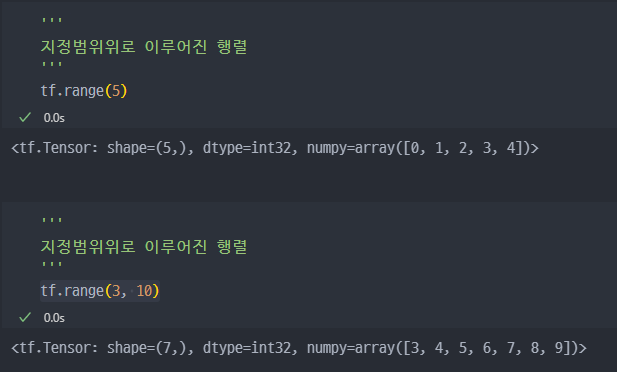
tf.onestf.zerostf.range:tf.range(start, limit, delta, dtype=None)*delta - 증가값
tf.ones( )
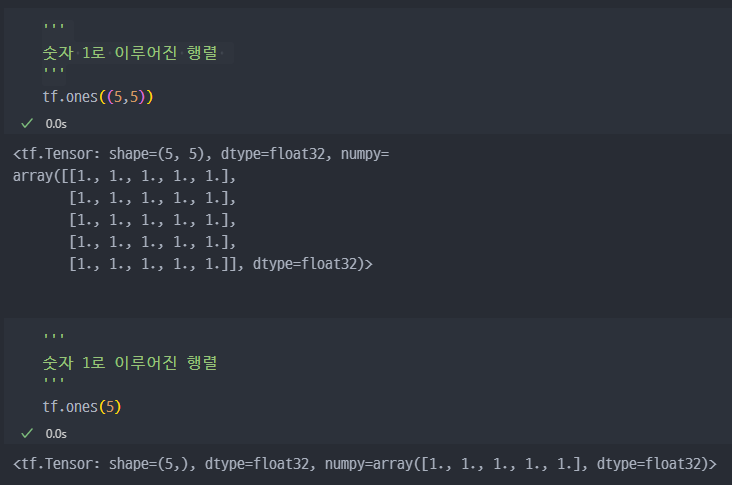
tf.zeros( )
tf.range( )
간단퀴즈
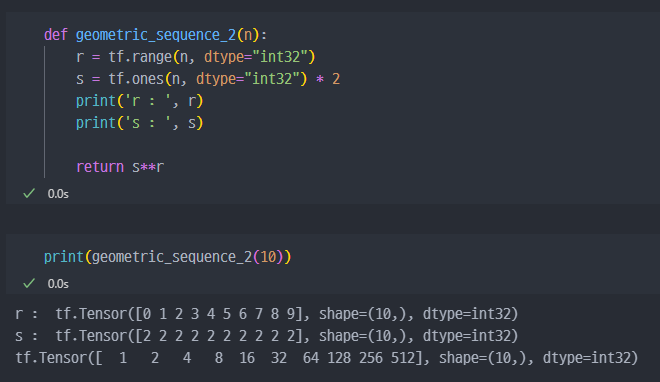
n을 입력하면 첫 항이 1이고 공비가 2인 등비수열을 생성하는 함수를 만드시오. ( 이 때 결과값은 tf.Tensor 데이터이고, 데이터 타입은 tf.int32 )
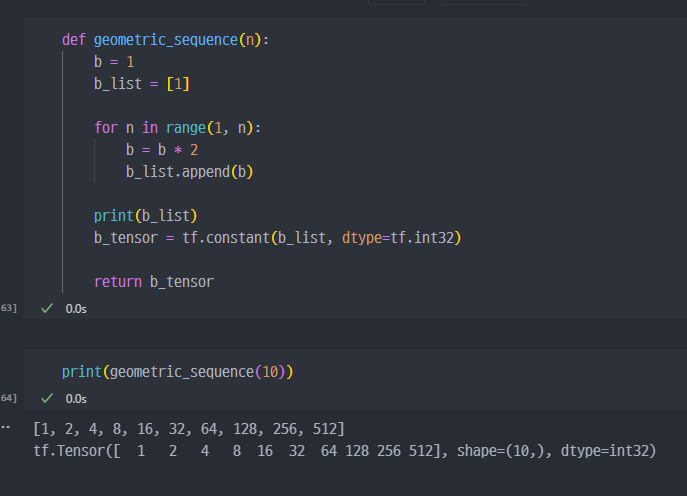
- 강의풀이
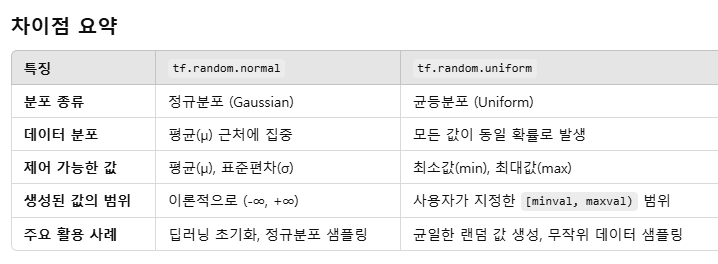
Random Value(난수)
tf.random이 구현되어 있음.- 데이터타입은 상수 형태로 반환됨.
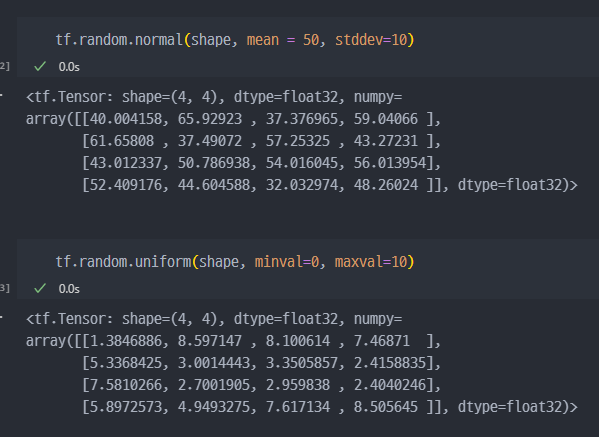
tf.random.normal: 정규분포 중에서 랜덤하게 상수 반환- Gaussian Normal Distribution
tf.random.uniform: 균등분포 중에서 랜덤하게 상수 반환- Uniform Distribution
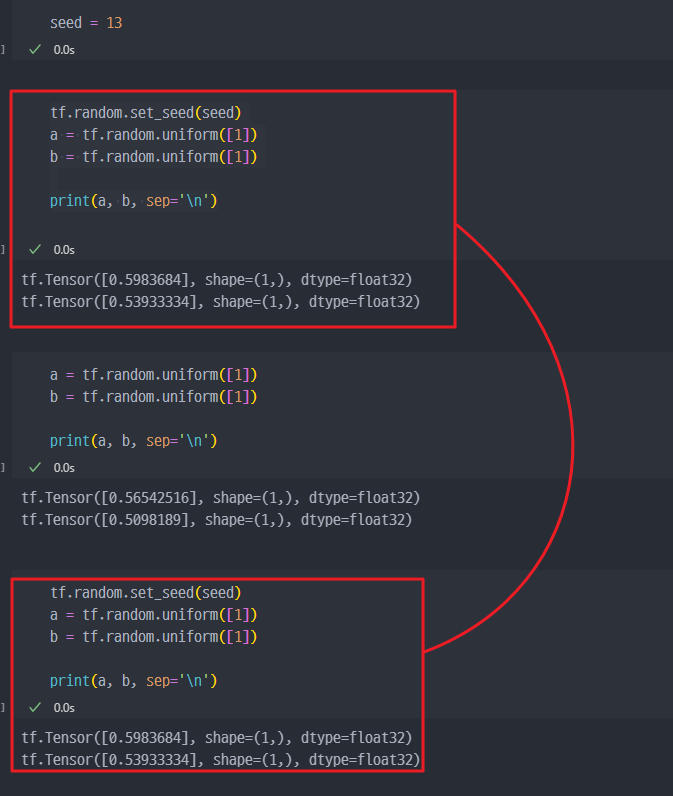
- Random seed 관리하기 !!
- Random Value로 보통 가중치를 초기화
- 이외에도 학습과정에서 Random Value가 많이 사용됨
- 이를 관리하지 않으면, 자신이 했던 작업이 동일하게 복구 또는 재현이 안됨!!!
tf.randim.set_seed({seed_number})- 항상 Random Seed를 고정해두고 개발해야 한다.
02. Variable
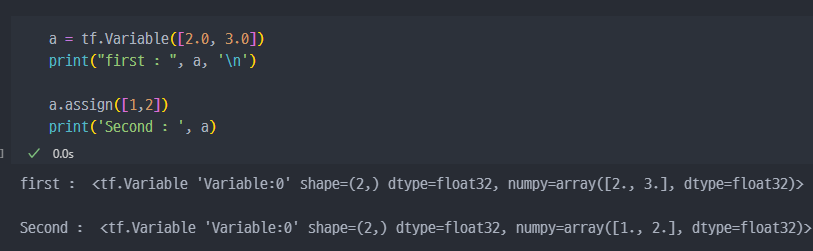
- 미지수, 가중치를 정의할 때 사용
- 직접 사용할 일이 많지는 않음
- 변수 정의는 변수 생성 + 초기화
- 미리 정해놓은 공간이라는 개념으로 생각하는게 좋음. 변수명은 공간이 이름이며, 변수에 어느값을 할당하냐는 그때 그때 정하는 것.
- 변수는 기존
tensor의 메모리를 재사용하여tensor를 재할당 할 수 있다.
03. Tensor 연산
연산
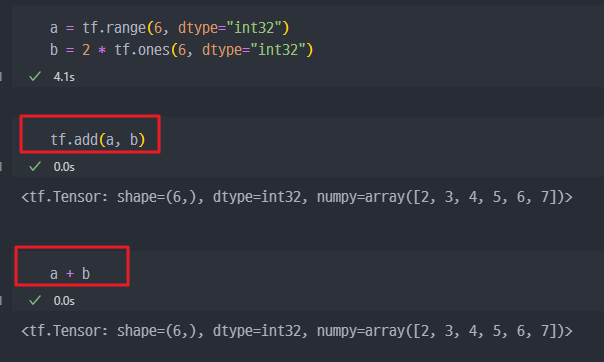
기본연산 : 아래의 기본연산은 특수 메서드를 이용하여 연산자 오버로딩이 되어 있으므로 그냥 연산자 기호를 사용하는게 가능하다.
tf.add: 덧셈tf.subtract: 뺄셈tf.multiply: 곱셈tf.divide: 나눗셈tf.pow: n-제곱tf.negative: 음수부호
여러가지 연산
tf.abs: 절대값tf.sign: 부호tf.round: 반올림tf.ceil: 올림tf.floor: 내림tf.square: 제곱tf.sqrt: 제곱근tf.maximum: 최댓값 ( 두 tensor의 각 원소에서 최댓값만 반환)tf.minimum: 최솟값 ( 두 tensor의 각 원소에서 최솟값만 반환)tf.cumsum: 누적합tf.cumprod: 누적곱
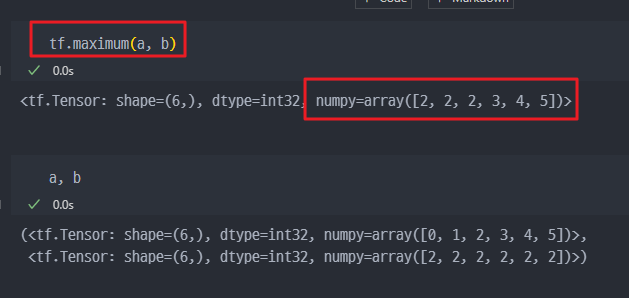
maximum: 같은 자리의 값중에서 큰 값들만 추출해서 다시 tensor를 생성한다.
Axis 이해하기
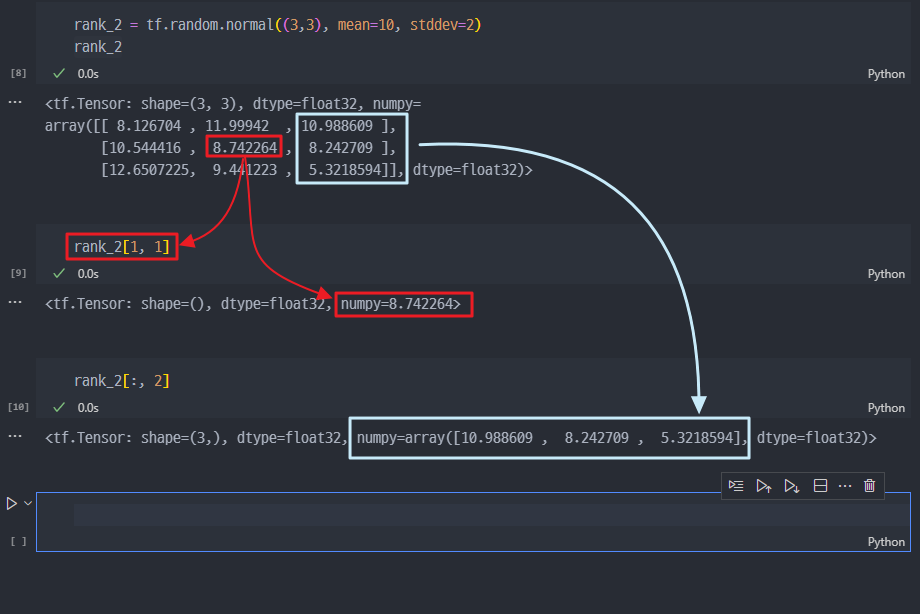
행렬,
Numpy의 array, 또는pandas의 DataFrame과 유사하다
- 3차원부터는 조금 헷갈릴 수 있다.
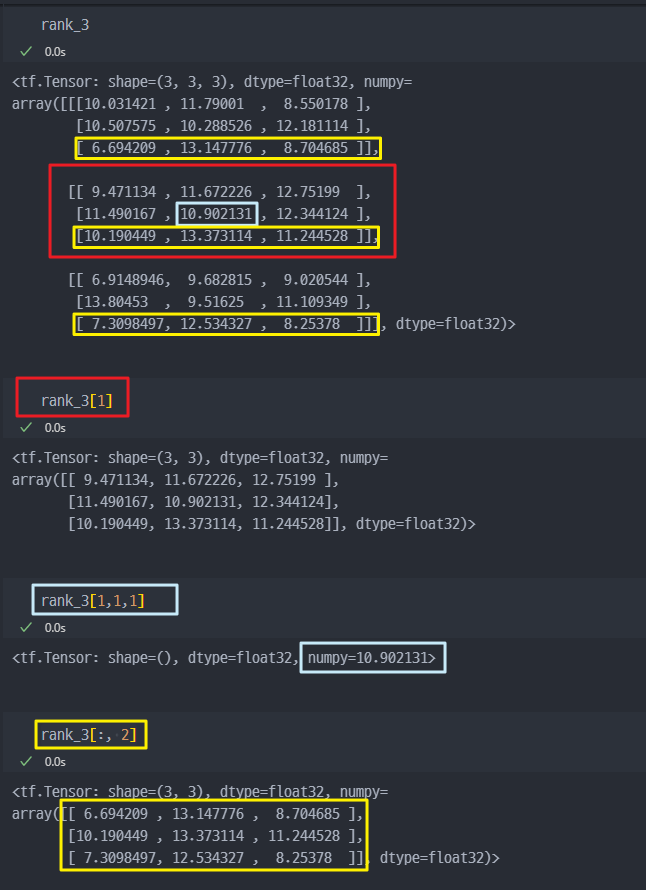
- 4차원.
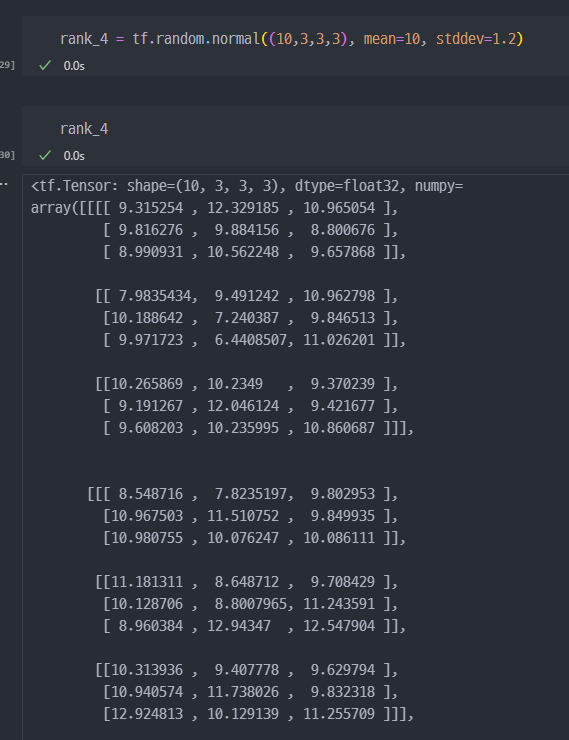
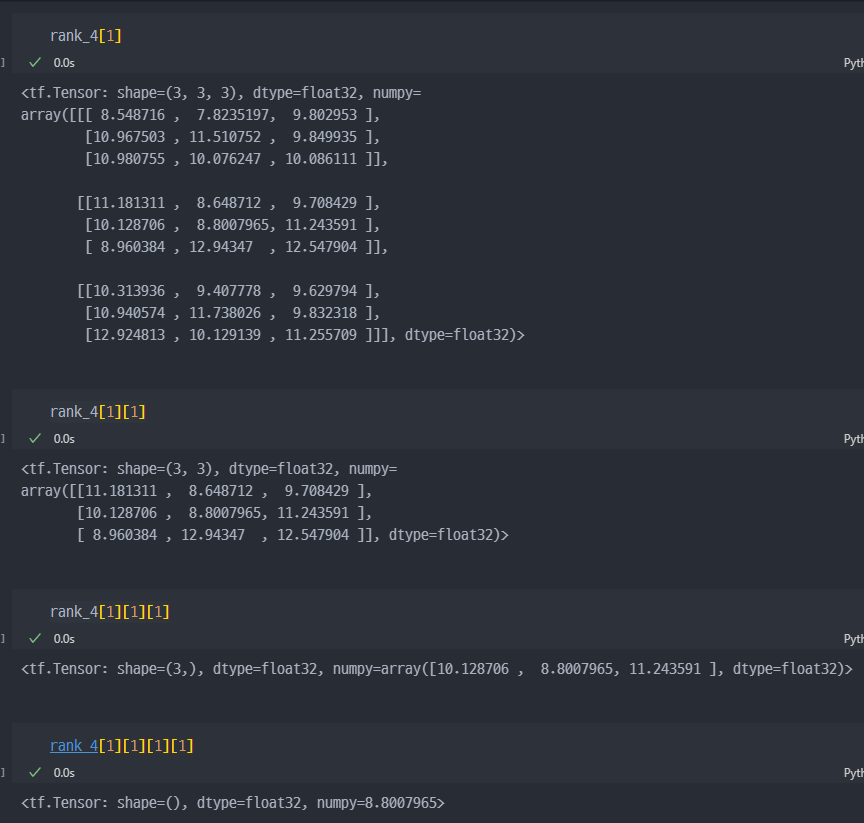
차원 축소 연산
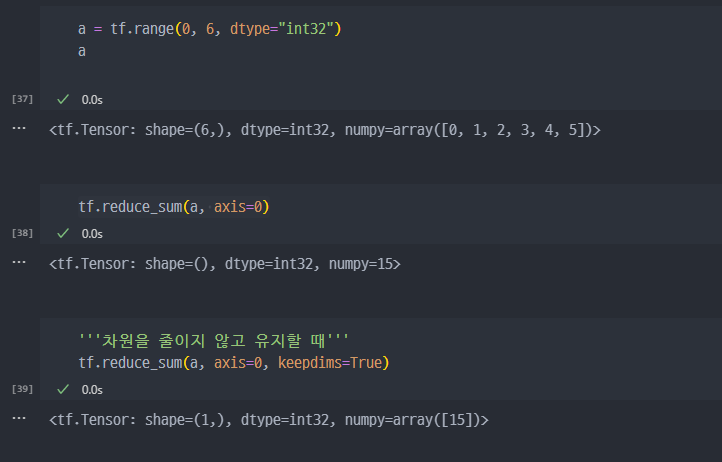
tf.reduce_mean: 설정한 축(axis)의 평균을 구한다.tf.reduce_max: 설정한 축(axis)의 최댓값을 구한다.tf.reduce_min: 설정한 축(axis)의 최솟값을 구한다.tf.reduce_prod: 설정한 축(axis)의 요소를 모두 곱한 값을 구한다.tf.reduce_sum: 설정한 축(axis)의 요소를 모두 더한 값을 구한다.
기초사용법
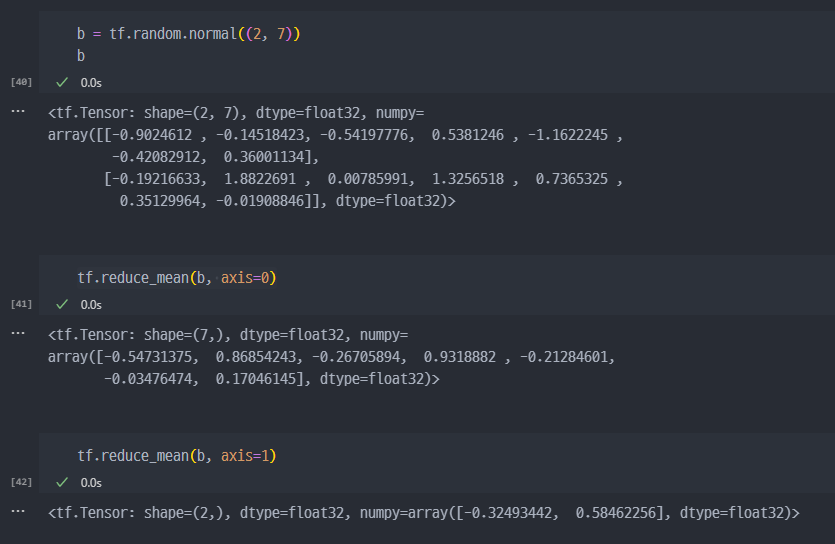
axis옵션에서, 0은 각 행 (row) 끼리 계산하는 것. 즉 (2X7) 행렬에서 axis=0 으로 차원축소하게되면, 한줄 즉 (7,) 로 변경된다.
axis=1 옵션으로 진행하면, 각 컬럼(열)끼리 계산하는 것이며, (2,)으로 변경된다.
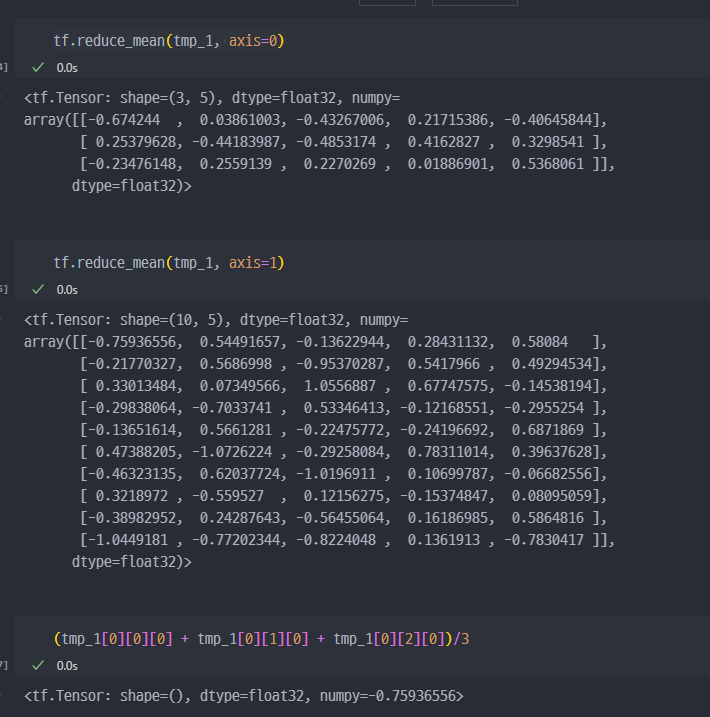
다양한 차원에서 연습필요
행렬과 관련된 연산
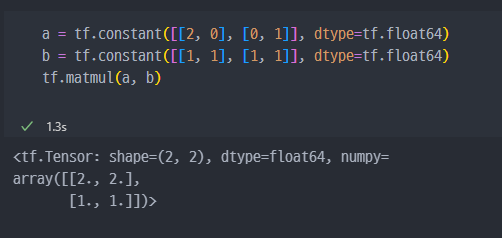
tf.matmul: 내적tf.linalg.inv: 역행렬
Numpy와 동일하다.
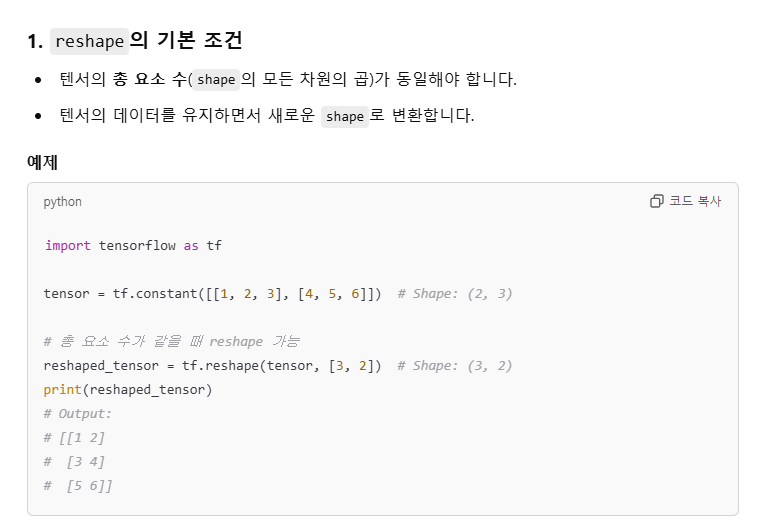
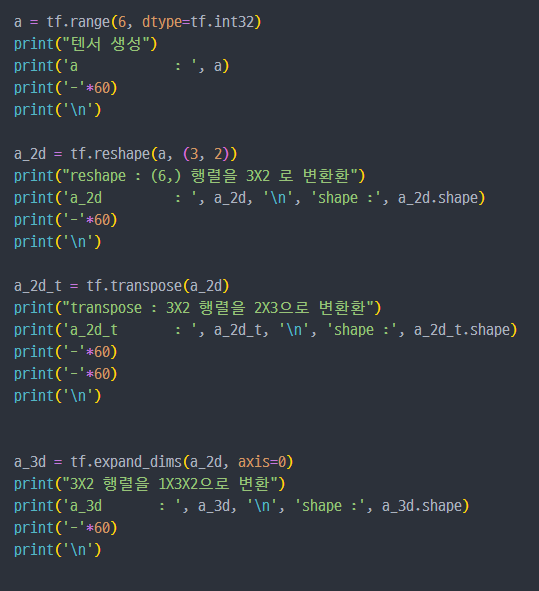
크기 및 차원을 바꾸기
축을 잘 이해하고 사용해야 한다!!
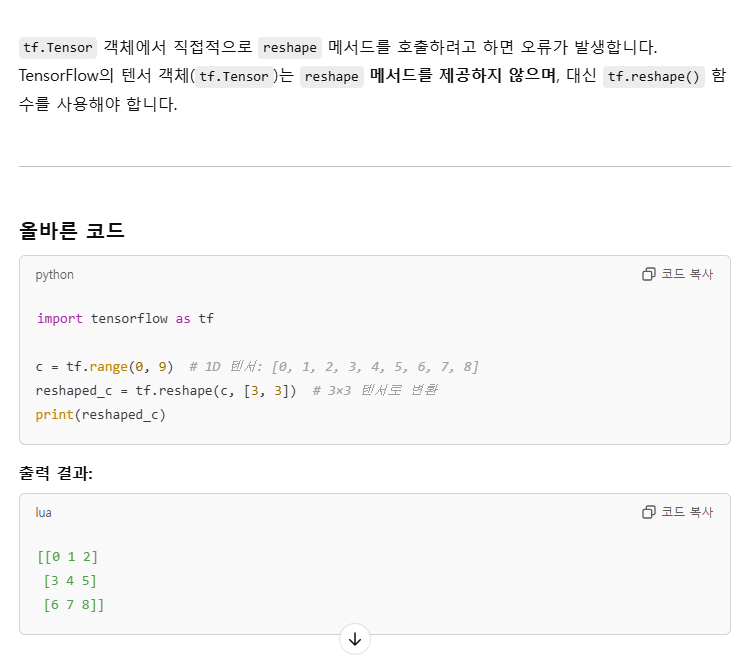
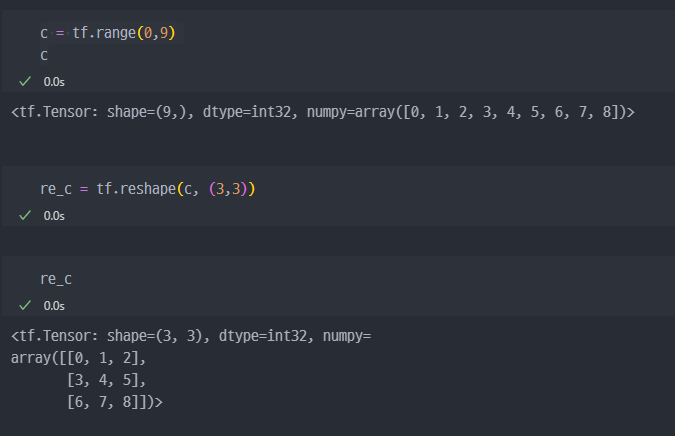
tf.reshape: 벡터 행렬의 크기 변환tf.transpose: 전치 연산tf.expand_dims: 지정한 축으로 차원을 추가tf.squeeze: 벡터로 차원을 축소

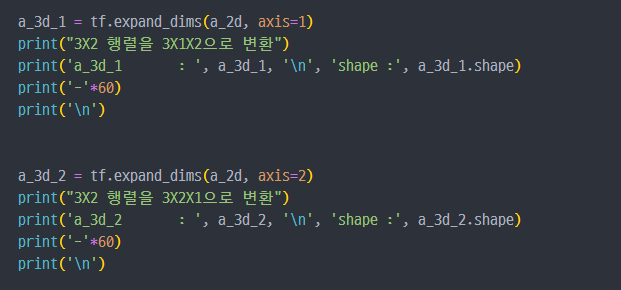
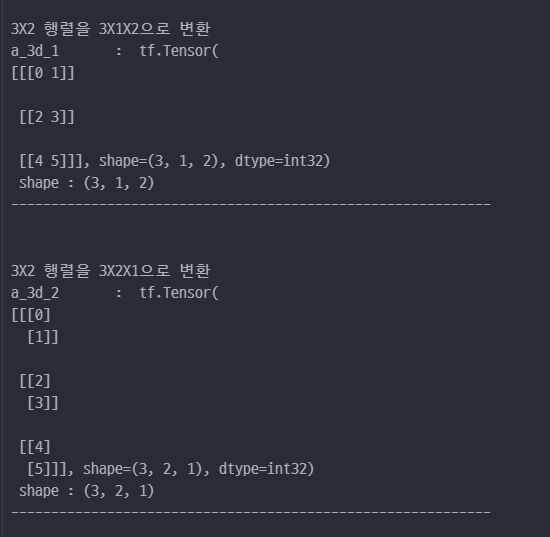
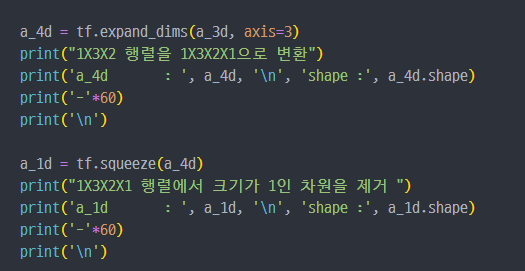
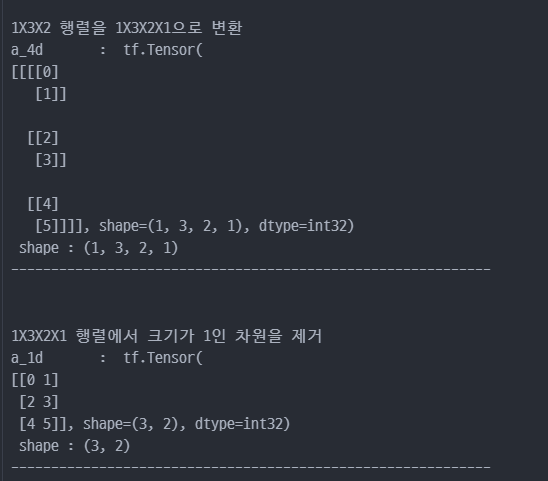
tensor를 나누거나 두 개 이상의 tesnor 합치기
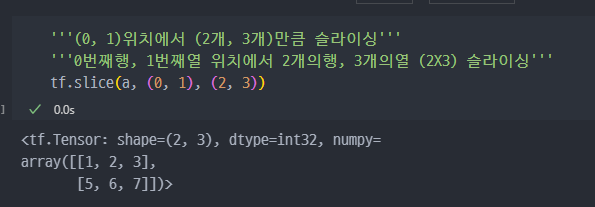
tf.slice: 특정 부분 추출tf.split: 분할tf.concat: 합치기tf.tile: 복제 - 붙이기tf.stack: 합성tf.unstack: 분리
slice
split
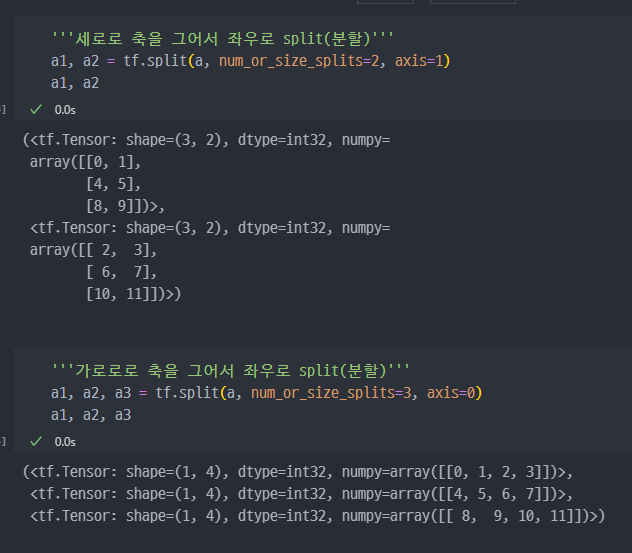
concat
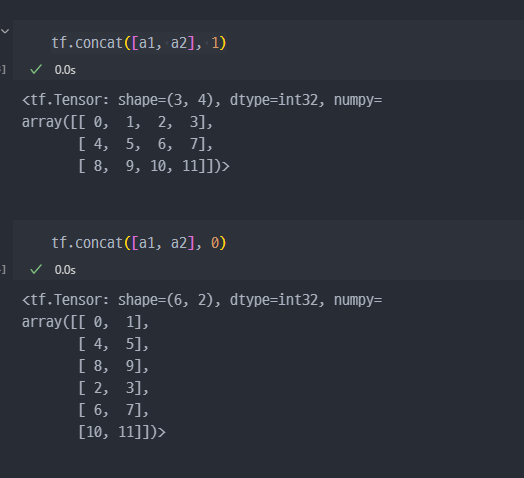
tile
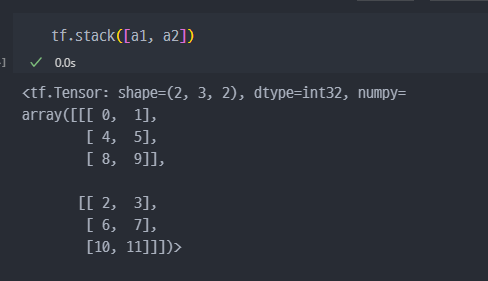
stack :
(3X2)행렬 2개를 stack 해서(2X3X2)행렬로 변경