[Coursera] C3W1 Neural Language Processing in TensorFlow - Sentiment in text
DeepLearning.AI TensorFlow Developer
목록 보기
9/12

실습환경 참조
tensorflow==2.7.0
tensorflow-datasets==4.0.1
scikit-learn==1.0.1
pandas==1.1.5
matplotlib==3.2.2
seaborn==0.11.2GOAL
- TensorFlow 의 Tokenizer 및 pad_sequences API 에 대해 학습
- neural network training 을 위해 텍스트를 인코딩하여 준비하는 방법에 대해 학습
Sentiment in text
L2 Word based encodings
-
단어에서 각 문자는 아스키코드로 인코딩될 수 있지만, 아래 두 글자는 동일한 아스키코드를 가진 문자들이 모여 서로 다른 의미를 나타낸다.

-
각 단어에 가중치를 부여하여 문장을 구성하면 동일한 단어는 동일한 가중치를 가지며 아래와 같이 표현된다.

L3 Using APIs
C3_W1_Lab_1_tokenize_basic.ipynb 코드보기
- NLP 과제는 corpus ( 입력 텍스트 뭉치 )로부터 단어사전을 추출해 데이터를 준비하는 것 부터 시작된다.
- 이를
token이라고 부르고 Tensorflow 와 keras 는 API 를 통해 이 과정을 지원한다.
각 단어를 토큰화하는 과정을 살펴보자. fit_on_texts() 와 word_index
-
자주 등장하는 단어가 더 낮은 index 를 가진다.
-
Tokenizer( num_words = 100 )
- Tokenizer 는 상위 num_words 개의 단어를 볼륨별로 가져와 인코딩한다.
- 적은 개수의 단어는 영향이 최소화되고 정확도가 떨어질 수 있지만 , training time 에 큰 영향을 줄 수 있어 주의해야 함
- 기본적으로 구두점을 제거해주고 모든 단어를 소문자로 변환한다. ( 설정 가능 )
-
tokenizer.word_index
- (keyword, valuetoken) tuple 을 반환한다.


-
num_words: 빈도 순위로 단어의 최대개수 - 1 까지 고려된다.- dictionary 생성에는 영향을 주지 않는다.
tokenizer.texts_to_sequences(sentences)시에 가장 자주 등장하는num_words개의 단어가 반환됨- num_words = 2

- num_words = 100

- num_words = 2
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat'
]
# Tokenizer 는 상위 num_words 개의 단어를 볼륨별로 가져와 인코딩한다.
tokenizer = Tokenizer( num_words = 100 )
tokenizer.fit_on_texts( sentences )
word_index = tokenizer.word_index
print(word_index)L4 Text to sequence
- 각 문장의 길이가 동일한 것이 학습하는 데에 편리하다.
- train data 에서 보이지 않았던 단어들은 생략된다.
Train data 로 Tokenzier 구성
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer( num_words = 100 )
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print(word_index)
print(sequences)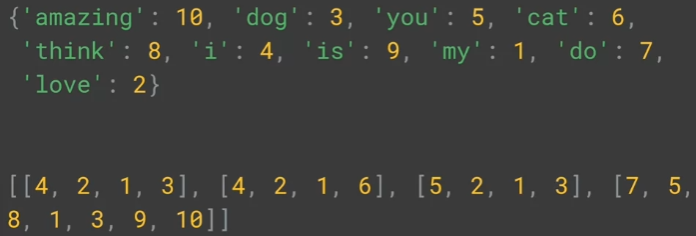
Test data : train data 에서 보이지 않았던 단어들이 생략됨
test_data = [
'I really love my dog',
'my dog loves my manatee'
]
test_seq = tokenizer.texts_to_sequences(test_data)
print(test_seq)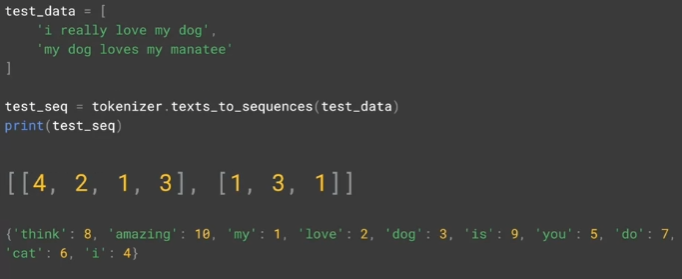
L5 Looking more at the Tokenizer
- 많은 훈련 데이터 준비하기
- train 단계에서 보이지 않았던 단어가 나오면
default값을 주는 방법
corpus Vocabulary 에 없는 단어가 등장하면 default value 부여 : oov_token - out of Vocabulary
# oov_token 으로는 아무 단어나 설정해도 되지만 ,
# sentence 에서 등장하지 않는 word 로 설정하기 위해 "<OOV>" 로 설정
tokenizer = Tokenizer( num_words = 100 ,
oov_token="<OOV>") 
L6 Padding
- sentence 의 길이가 일정하지 않을 경우 , padding 을 이용하여 앞 부분에
0를 추가해준다.# padding='post'를 이용하면 0 value 가 뒷 부분에 추가됨 padded = pad_sequence(sequences, padding='post')
- sentence 가 max sentence length 보다 길 경우 , default 로 앞 부분의 단어가 생략된다.
padded = pad_sequences( sequences , padding = 'post', maxlen = 5 )
- 옵션으로 앞 / 뒤 중 어느 부분의 단어가 생략될지 설정할 수 있다.
padded = pad_sequences( sequences , padding = 'post', truncating = 'post', maxlen = 5 )
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
sentences = [
'I love my dog',
'I love my cat',
'You love my dog',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer( num_words = 100 , oov_token="<OOV>" )
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences)
print(word_index)
print(sequences)
print(padded)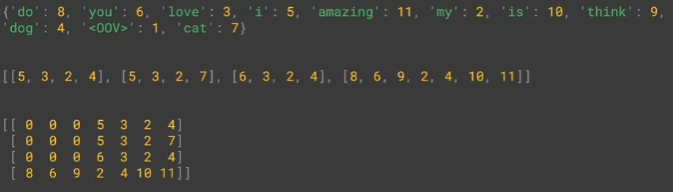
L8 Notebook for lesson2
L9 Sarcasm,really?
- 풍자하는 뉴스인지에 대한 데이터
is_sarcastic: 풍자글 이면 1 아니면 0headline: 뉴스기사 headline 정보artikle_link: 기사 원문에 접근할 수 있는 링크 , 부가적인 내용 수집에 도움이 됨
- json import 가 쉽도록 가공해보자.
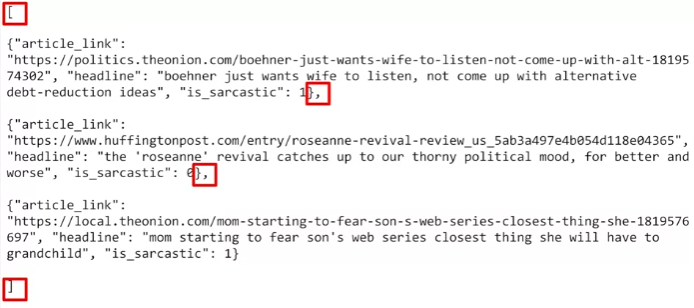
kaggle 에서 받은 데이터를 import 해보자.
import json
with open("sarcasm.json", 'r') as f :
datastore = json.load(f)
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link'])L10 Working with the Tokenizer
fit_on_texts: word index 생성 및 tokenizer 초기화word_index: word index 속성을 가져옴

from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sequences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape)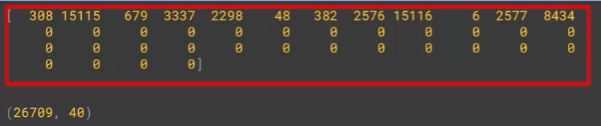
L11 Notebook for lesson 3
C3_W1_Lab_3_sarcasm.ipynb 코드 바로가기
( 참고 )자주 등장하는 전치사 같은 것들을 word index 생성 전에 제거하여 성능을 높일 수 있다.
Quiz
- If you have a number of sequences of different length, and call pad_sequences on them, what’s the default result?
They’ll get padded to the length of the longest sequence by adding zeros to the beginning of shorter ones
Week 1: Explore the BBC News archive
BBC News Classification Dataset
which contains 2225 examples of news articles with their respective categories (labels).
library import
import csv
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencesdataset 불러오기
with open("./data/bbc-text.csv",'r') as csvfile:
print(f"First line (header) looks like this:\n\n{csvfile.readline()}")
print(f"Each dat point looks like this:\n\n{csvfile.readline()}")
Removing stopwords : remove_stopwords
- 전치사 같은 의미없는 단어 제거하기
- "I ate it before" 와 같이 문장 첫 / 끝 단어로 사용되는 경우를 위해 공백 추가
- 공백 사이에 있는 것을 한 단어로 취급하고 replace 처리
- 첫 / 끝 공백 제외 후의 문장에서 여러 개의 space 를 하나로 치환
for word in stopwords: sentence = " " + sentence sentence = sentence.replace(" " + word + " " , " " ) sentence = sentence[1:].replace(" "," ") sentence = sentence.replace(" "," ")
```python
def remove_stopwords(sentence):
"""
Removes a list of stopwords
Args:
sentence (string): sentence to remove the stopwords from
Returns:
sentence (string): lowercase sentence without the stopwords
"""
# List of stopwords
stopwords = ["a", "about", "above", "after", "again", "against", "all", "am", "an", "and", "any", "are", "as", "at", "be", "because", "been", "before", "being", "below", "between", "both", "but", "by", "could", "did", "do", "does", "doing", "down", "during", "each", "few", "for", "from", "further", "had", "has", "have", "having", "he", "he'd", "he'll", "he's", "her", "here", "here's", "hers", "herself", "him", "himself", "his", "how", "how's", "i", "i'd", "i'll", "i'm", "i've", "if", "in", "into", "is", "it", "it's", "its", "itself", "let's", "me", "more", "most", "my", "myself", "nor", "of", "on", "once", "only", "or", "other", "ought", "our", "ours", "ourselves", "out", "over", "own", "same", "she", "she'd", "she'll", "she's", "should", "so", "some", "such", "than", "that", "that's", "the", "their", "theirs", "them", "themselves", "then", "there", "there's", "these", "they", "they'd", "they'll", "they're", "they've", "this", "those", "through", "to", "too", "under", "until", "up", "very", "was", "we", "we'd", "we'll", "we're", "we've", "were", "what", "what's", "when", "when's", "where", "where's", "which", "while", "who", "who's", "whom", "why", "why's", "with", "would", "you", "you'd", "you'll", "you're", "you've", "your", "yours", "yourself", "yourselves" ]
# Sentence converted to lowercase-only
sentence = sentence.lower()
### START CODE HERE
for word in stopwords:
sentence = " " + sentence
sentence = sentence.replace(" " + word + " " , " " )
sentence = sentence[1:].replace(" "," ")
sentence = sentence.replace(" "," ")
### END CODE HERE
return sentenceReading the raw data : parse_data_from_file
( 조건 )
- 첫 행은 header 이므로 처리하지 않는다.
- numpy array 아니고 list 여도 괜찮음
csv.reader를 사용할 때 적절한 arguments 전달이 필요하다. csv.reader 는 반복자를 포함한다. label 은 row[0] 로 접근할 수 있고, text 는 row[1] 로 접근할 수 있다.- 각 sentence 에 대해
remove_stopwords처리
def parse_data_from_file(filename):
"""
Extracts sentences and labels from a CSV file
Args:
filename (string): path to the CSV file
Returns:
sentences, labels (list of string, list of string): tuple containing lists of sentences and labels
"""
sentences = []
labels = []
with open(filename , 'r') as csvfile:
### START CODE HERE
reader = csv.reader( csvfile , delimiter=",")
next( reader,None )
datalist = list(reader)
sentences = [ remove_stopwords( row[1] ) for row in datalist ]
labels = [ row[0] ) for row in datalist ]
### END CODE HERE
return sentences , labelsUsing the Tokenizer : fit_tokenizer
Tokenizerinitialize : oov_token ="< OOV >"
def fit_tokenizer(sentences):
"""
Instantiates the Tokenizer class
Args:
sentences (list): lower-cased sentences without stopwords
Returns:
tokenizer (object): an instance of the Tokenizer class containing the word-index dictionary
"""
### START CODE HERE
# Instantiate the Tokenizer class by passing in the oov_token argument
tokenizer = Tokenizer(oov_token="<OOV>")
tokenizer.fit_on_texts(sentences)
# Fit on the sentences
### END CODE HERE
return tokenizerpadded sequence 생성하기 : get_padded_sequences
def get_padded_sequences(tokenizer, sentences):
"""
Generates an array of token sequences and pads them to the same length
Args:
tokenizer (object): Tokenizer instance containing the word-index dictionary
sentences (list of string): list of sentences to tokenize and pad
Returns:
padded_sequences (array of int): tokenized sentences padded to the same length
"""
### START CODE HERE
# Convert sentences to sequences
sequences = tokenizer.texts_to_sequences(sentences)
# Pad the sequences using the post padding strategy
padded_sequences = pad_sequences(sequences, padding='post')
### END CODE HERE
return padded_sequenceslabel tokenizing 하기
# GRADED FUNCTION: tokenize_labels
def tokenize_labels(labels):
"""
Tokenizes the labels
Args:
labels (list of string): labels to tokenize
Returns:
label_sequences, label_word_index (list of string, dictionary): tokenized labels and the word-index
"""
### START CODE HERE
# Instantiate the Tokenizer class
# No need to pass additional arguments since you will be tokenizing the labels
label_tokenizer = Tokenizer()
# Fit the tokenizer to the labels
label_tokenizer.fit_on_texts(labels)
# Save the word index
label_word_index = label_tokenizer.word_index
# Save the sequences
label_sequences = label_tokenizer.texts_to_sequences(labels)
### END CODE HERE
return label_sequences, label_word_index