SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation 논문 리뷰
paper: https://arxiv.org/abs/2404.05680
github: https://github.com/lhyfst/SphereHead
생성형 인공지능이 발전하면서 가상의 얼굴 이미지는 이제 일상에서 흔히 볼 수 있게 되었습니다. 하지만 '모든 각도'에서 자연스러운 3D 얼굴을 합성하는 것은 여전히 도전적인 과제입니다. 특히 머리 뒷부분까지 자연스럽게 생성하는 기술은 아직 완벽하지 않습니다. 이를 해결하고자 한 연구 하나를 소개하고자 합니다.
0. Abstraction
SphereHead는 모든 각도에서 볼 수 있는 완전한 3D 머리 합성을 위한 새로운 프레임워크입니다. 최근 3D 인식 생성적 적대 신경망(3D-aware Generative Adversarial Networks, 3D-GANs)의 발전으로 정면에 가까운 얼굴 합성은 크게 향상되었지만, 모든 각도에서 볼 수 있는 완전한 3D 머리 합성은 여전히 도전적인 과제로 남아있습니다.
이전의 PanoHead 연구는 정면과 후면 이미지를 모두 포함하는 대규모 데이터셋을 사용하여 전체 머리 합성의 가능성을 보여주었지만, 후면 뷰에서 자주 아티팩트(인공물)가 발생한다는 문제점이 있었습니다. 본 연구팀의 심층 분석에 따르면, 이러한 문제가 발생하는 이유는 크게 두 가지입니다:
-
네트워크 아키텍처 측면에서, 기존 tri-plane/tri-grid 표현 공간의 각 평면은 양쪽에서 오는 특징을 혼동하는 경향이 있어 '미러링' 아티팩트(예: 안경이 뒷면에 나타나는 현상)를 유발합니다.
-
데이터 지도 학습 측면에서, 기존 3D GANs의 판별자 훈련은 주로 렌더링된 이미지 자체의 품질에 초점을 맞추고, 렌더링 관점과의 일관성은 크게 고려하지 않습니다.
SphereHead는 이러한 문제를 해결하기 위해 인간 두상의 기하학적 특성에 맞는 구형 좌표계(spherical coordinate system)에서 새로운 tri-plane 표현 방식을 제안하고, 카메라 매개변수와 이미지 간의 대응 관계를 강조하는 시점-이미지 일관성 손실 함수(view-image consistency loss)를 도입했습니다.
이러한 접근법을 통해 SphereHead는 기존 방법들보다 시각적으로 우수한 결과를 달성하고 아티팩트를 크게 줄였습니다.
1. Introduction

3D 얼굴 합성 기술은 영화 산업, 게임 개발, 가상 현실(VR), 증강 현실(AR) 등 다양한 분야에서 활용되고 있습니다. 최근 몇 년간 인공지능, 특히 생성적 적대 신경망(GAN)을 활용한 얼굴 이미지 합성 기술은 놀라운 발전을 이루었습니다. 그러나 이러한 발전에도 불구하고, 모든 각도에서 자연스러운 3D 머리를 합성하는 것은 여전히 큰 도전 과제입니다.
3D 얼굴 합성의 가장 큰 어려움 중 하나는 머리 뒷부분(두정부, 후두부)을 자연스럽게 생성하는 것입니다. 이는 학습 데이터에서 머리 정면 이미지가 후면 이미지보다 훨씬 많기 때문입니다. 이러한 데이터 불균형으로 인해 기존 모델들은 머리 뒷부분을 생성할 때 자주 오류를 범합니다.
PanoHead는 정면과 후면 이미지를 모두 포함하는 대규모 데이터셋을 활용하여 전체 머리 합성을 시도한 획기적인 연구였습니다. 그러나 이 접근법에도 여전히 두 가지 주요 문제점이 있었습니다:
1. Mirroring artifacts (미러링 아티팩트): 머리 뒷부분이 정면 얼굴의 특징(예: 안경, 표정)을 그대로 반영하는 문제입니다. 예를 들어, 정면에서 안경을 쓴 얼굴이라면 머리 뒷부분에도 안경이 나타나는 비현실적인 결과가 생성됩니다.
2. Multiple-face artifacts (다중 얼굴 아티팩트): 머리 뒷부분에 얼굴과 유사한 형태가 부자연스럽게 생성되는 문제로, 때로는 정면 얼굴과 다른 정체성, 표정, 액세서리를 가진 얼굴이 생성됩니다.
SphereHead 연구는 이러한 문제점들을 해결하기 위해 두 가지 주요 기여를 합니다:
1. Spherical tri-plane representation (구형 tri-plane 표현): 인간 머리의 기하학적 특성에 맞는 구형 좌표계 기반의 새로운 표현 방식을 제안합니다. 이 접근법은 머리의 각 위치에 있는 특징을 명시적으로 분리하여 미러링 아티팩트를 완전히 해결합니다.
2. View-image consistency loss (시점-이미지 일관성 손실 함수): 판별자가 이미지의 품질뿐만 아니라 카메라 매개변수와의 일관성도 고려하도록 하는 손실 함수를 도입했습니다. 이를 통해 다중 얼굴 아티팩트 문제를 효과적으로 해결합니다.
2. Related Work
3D-aware Image Synthesis (3D 인식 이미지 합성)
3D 인식 이미지 합성은 2D 이미지를 생성하면서도 3D 기하학적 정보를 내포하는 기술입니다. 초기 접근법들은 메시(mesh) 또는 복셀(voxel) 기반 표현을 사용했으나, 이러한 방법들은 계산 비용이 높고 해상도에 제한이 있었습니다.
최근에는 신경 복사 필드(Neural Radiance Fields, NeRF)와 같은 암시적 표현(implicit representation)이 주목받고 있습니다. NeRF는 복잡한 장면을 높은 충실도로 표현할 수 있지만, 훈련에 많은 시간이 소요됩니다. 이를 개선하기 위해 tri-plane 표현과 같은 하이브리드 접근법이 개발되었습니다.
3D Face Synthesis (3D 얼굴 합성)
초기 3D 얼굴 합성 연구는 주로 3D 모핑 모델(3DMM)과 같은 매개변수 모델을 사용했습니다. 이후 StyleGAN과 같은 GAN 기반 접근법이 등장하며 고품질 얼굴 이미지 생성이 가능해졌습니다.
EG3D, GRAM 등의 연구는 tri-plane 표현을 도입하여 3D 일관성이 있는 얼굴 합성을 가능하게 했습니다. 그러나 이러한 접근법들은 주로 정면 또는 거의 정면에 가까운 시점의 얼굴 합성에 중점을 두었습니다.
Full-head Synthesis (전체 머리 합성)
전체 머리(모든 각도에서 볼 수 있는 머리) 합성 연구는 상대적으로 최근에 시작되었습니다. PanoHead는 처음으로 다양한 시점의 머리 이미지를 포함하는 대규모 데이터셋을 구축하고, tri-grid 표현을 도입하여 전체 머리 합성을 시도했습니다.
그러나 PanoHead는 앞서 언급한 미러링 아티팩트와 다중 얼굴 아티팩트 문제를 완벽히 해결하지 못했습니다. SphereHead는 이러한 문제를 해결하기 위해 구형 좌표계 기반의 새로운 표현 방식과 시점-이미지 일관성 손실 함수를 제안했습니다.
Tri-plane Representation (삼중 평면 표현)
삼중 평면 표현은 3D 공간의 특징을 세 개의 직교 평면(xy, yz, xz)에 저장하는 방식입니다. 이 방법은 복셀 그리드보다 메모리 효율적이면서도 NeRF보다 빠른 렌더링이 가능합니다.
EG3D, GRAM, GET3D 등의 연구는 tri-plane 표현을 3D GAN에 성공적으로 적용했습니다. PanoHead는 여기서 더 나아가 tri-grid 표현을 도입했지만, 여전히 데카르트 좌표계(Cartesian coordinate system)를 사용했기 때문에 미러링 아티팩트 문제가 완전히 해결되지 않았습니다.
SphereHead는 인간 머리의 구형에 가까운 기하학적 특성을 고려하여, 구형 좌표계 기반의 tri-plane 표현을 제안했습니다
3. SphereHead
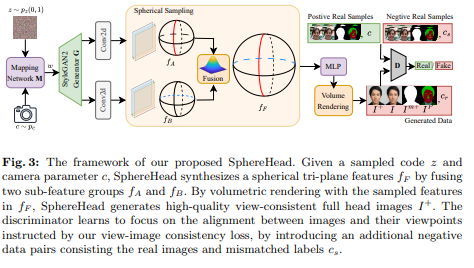
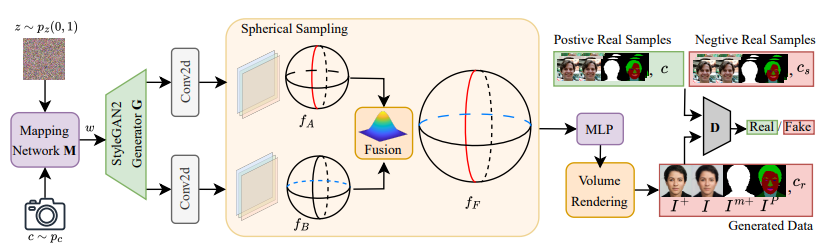
이제 본 논문의 핵심인 SphereHead 프레임워크에 대해 자세히 살펴보겠습니다. SphereHead는 기존 3D 머리 합성 모델의 문제점을 해결하기 위해 개발된 새로운 접근법입니다.
SphereHead의 전체 프레임워크는 다음과 같은 구성 요소를 포함합니다:
-
잠재 코드(latent code) z와 카메라 매개변수 c를 입력으로 받습니다.
-
구형 tri-plane 특징을 생성하는 생성기(generator)
-
볼륨 렌더링(volumetric rendering)을 통해 2D 이미지를 생성합니다.
-
생성된 이미지와 카메라 매개변수의 일관성을 판단하는 판별자(discriminator)
생성기는 랜덤 잠재 코드 z에서 구형 tri-plane 특징 fF를 생성합니다. 이 특징은 두 개의 하위 특징 그룹 와 를 융합하여 생성됩니다. 볼륨 렌더링을 통해 고품질의 시점-일관성 있는 전체 머리 이미지 가 생성됩니다.
판별자는 시점-이미지 일관성 손실 함수를 통해 이미지와 시점 간의 일치에 초점을 맞추도록 학습됩니다. 이를 위해 실제 이미지와 잘못 매칭된 카메라 매개변수 cs로 구성된 추가적인 부정 데이터 쌍을 도입했습니다.
3.1 Dual Spherical Tri-plane Representation
3D 전체 머리 합성의 주요 도전 과제는 다양하고 복잡한 헤어스타일을 가진 후두부(머리 뒷부분)를 생성하는 것입니다. 이 문제는 두 가지 주요 원인에서 비롯됩니다:
-
불균형한 훈련 데이터로 인한 편향된 지도 학습
-
기존 tri-plane 표현의 한계
기존 tri-plane 표현은 데카르트 좌표계(x, y, z)에서 정의되어 특징 평면(xy, yz, xz)의 각 위치가 3D 공간의 서로 다른 위치에 매핑될 수 있습니다. 이로 인해 머리의 정면과 후면 특징이 서로 얽히게 되고, 미러링 아티팩트가 발생합니다. PanoHead의 tri-grid 표현도 유사한 구조를 가지며 동일한 데카르트 좌표계를 사용하기 때문에 미러링 아티팩트 문제가 완전히 해결되지 않았습니다.
SphereHead는 이 문제를 해결하기 위해 구형 tri-plane 표현을 제안합니다. 이 접근법은 머리의 각 위치 특징을 명시적으로 분리합니다.
구형 좌표계에서 3D 공간의 점은 (r, θ, ϕ)로 표현됩니다:
-
r: 원점으로부터의 거리(반경)
-
θ: 방위각(azimuthal angle), xy 평면에서 x축으로부터의 각도
-
ϕ: 극각(polar angle), z축으로부터의 각도
SphereHead의 구형 tri-plane은 다음 세 가지 특징 평면으로 구성됩니다:
-
반원 평면(semicircle plane): (r, ϕ) 좌표 공간
-
원형 평면(circular plane): (r, θ) 좌표 공간
-
구형 평면(spherical plane): (θ, ϕ) 좌표 공간
3D 위치의 특징을 쿼리할 때, 해당 위치를 구형 좌표로 변환하고 세 특징 평면에 투영합니다. 각 평면에서 이중 선형 보간(bilinear interpolation)을 통해 특징 벡터를 검색하고, 이를 합산하여 최종 특징을 얻습니다. 경량 디코더 네트워크는 이 3D 특징을 색상과 밀도로 해석하며, 이를 볼륨 렌더링을 통해 RGB 이미지로 변환합니다.
더 나아가, SphereHead는 이중 구형 tri-plane 표현(dual spherical tri-plane representation)을 사용합니다. 두 개의 구형 tri-plane(구형 A와 구형 B)이 서로 다른 반경을 가지고 있어, 머리의 내부와 외부 특징을 더 잘 모델링할 수 있습니다. 이 두 특징 그룹은 나중에 융합되어 최종 특징 표현을 형성합니다.
구형 tri-plane 표현의 수학적 공식
3D 점 p = (x, y, z)를 구형 좌표 (r, θ, ϕ)로 변환하는 공식:
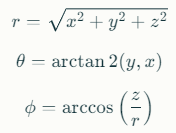
이 구형 좌표를 사용하여 각 특징 평면에 투영하고, 특징 벡터 f를 검색합니다:
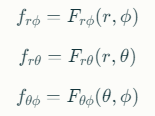
최종 특징 벡터는 세 특징 벡터의 합으로 계산됩니다:
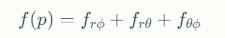
이 접근법의 핵심 이점은 구형 좌표계의 기하학적 특성이 머리의 각 위치 특징을 명시적으로 분리하여 미러링 아티팩트를 완전히 해결한다는 것입니다.
3.2 View-image Consistency Loss (ViCo Loss)
SphereHead의 두 번째 주요 기여는 시점-이미지 일관성 손실 함수(View-image Consistency Loss, 이하 ViCo Loss)입니다. 이 손실 함수는 두 번째 문제인 다중 얼굴 아티팩트를 해결하기 위해 설계되었습니다.
기존 3D GAN의 판별자 훈련에서는 주로 렌더링된 이미지의 품질에만 초점을 맞추고, 이미지와 카메라 매개변수 간의 일관성은 크게 고려하지 않았습니다. 이로 인해 판별자는 이미지의 시각적 품질만으로 생성된 데이터 쌍을 평가하는 경향이 있었고, 이미지와 시점 간의 일관성은 약화되었습니다.
이 문제는 머리 이미지와 같이 특정 방향의 지도 학습 강도가 크게 불균형한 경우 특히 심각합니다. 그 결과, 생성기는 정면 얼굴과 같이 많이 지도된 콘텐츠를 잘못된 방향에 생성하는 경향이 있어 다중 얼굴 아티팩트가 발생합니다.
ViCo Loss는 이 문제를 해결하기 위해 판별자가 이미지와 카메라 매개변수 간의 일치에 집중하도록 합니다. 판별자 훈련 과정에서 세 가지 유형의 데이터 쌍이
사용됩니다:
1. Positive Real Samples (양성 실제 샘플): 실제 이미지와 해당 카메라 매개변수 쌍 (I_real, c_real)
2. Negative Real Samples (부정 실제 샘플): 실제 이미지와 무작위로 섞인 실제 카메라 매개변수 쌍 (I_real, c_shuffled)
3. Generated Data (생성된 데이터): 생성된 이미지와 해당 카메라 매개변수 쌍 (I_gen, c_gen)
ViCo Loss의 수학적 공식은 다음과 같습니다:
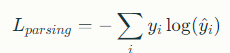
여기서 D는 판별자 함수이고, c_s는 I_real과 무관한 섞인 카메라 매개변수입니다.
이 손실 함수는 판별자가 이미지의 품질뿐만 아니라 이미지와 카메라 매개변수 간의 일관성도 고려하도록 합니다. 이를 통해 판별자는 시각적으로 고품질이더라도 시점과 일치하지 않는 이미지를 거부하도록 학습됩니다.
3.3 Parsing Branch for Semantic Embedding
SphereHead는 생성된 머리 이미지의 의미론적 컨트롤을 향상시키기 위해 파싱 분기(Parsing Branch)를 도입합니다. 이 파싱 분기는 생성된 이미지의 주요 의미론적 요소(피부, 눈, 입, 코, 머리카락 등)를 분할하는 역할을 합니다.
파싱 분기는 메인 생성기에 병렬로 구현되며, 생성된 특징 맵을 입력으로 받아 의미론적 분할 맵을 출력합니다. 이 분할 맵은 머리의 다양한 부분을 명시적으로 식별하고 분리합니다.
파싱 분기의 주요 이점은 다음과 같습니다:
-
향상된 의미론적 제어: 생성된 머리의 특정 부분(예: 머리카락 스타일, 피부 톤)을 더 정확하게 제어할 수 있습니다.
-
일관된 구조 생성: 머리의 다양한 부분 간의 구조적 일관성을 유지하는 데 도움이 됩니다.
-
의미론적 임베딩 학습: 생성 프로세스에 의미론적 정보를 명시적으로 통합하여 더 자연스러운 결과를 생성합니다.
파싱 분기는 cross-entropy loss (교차 엔트로피 손실 함수)를 사용하여 훈련됩니다:

여기서 는 실제 의미론적 레이블이고, 는 파싱 분기에 의해 예측된 레이블입니다.
파싱 분기의 출력은 또한 다중 스케일 특징 융합(multi-scale feature fusion)을 통해 메인 생성 경로에 피드백됩니다. 이를 통해 의미론적 정보가 생성 프로세스 전체에 통합되어 더 자연스럽고 일관된 머리 합성이 가능해집니다.
4. Dataset
SphereHead 연구에서는 전체 머리 합성을 위한 새로운 대규모 데이터셋을 구축했습니다. 이 데이터셋의 구성과 처리 과정에 대해 살펴보겠습니다.
데이터 수집 및 구성
SphereHead 데이터셋은 다양한 시점에서 촬영된 약 60,000장의 머리 이미지를 포함하고 있습니다. 특히 중요한 점은 이 데이터셋이 머리 후면 뷰 이미지도 포함하고 있다는 것입니다.
데이터셋의 주요 구성 요소는 다음과 같습니다:
-
다양한 연령, 성별, 인종의 인물 이미지
-
다양한 헤어스타일과 액세서리(안경, 귀걸이 등)
-
다양한 카메라 각도에서 촬영된 이미지(정면, 측면, 후면)
-
각 이미지에 대한 카메라 매개변수 및 포즈 정보
데이터 처리 파이프라인
-
원시 이미지 데이터는 다음과 같은 처리 과정을 거쳤습니다:
-
얼굴 감지 및 정렬: 먼저 각 이미지에서 얼굴을 감지하고 정렬합니다.
-
배경 제거: 머리 영역을 정확히 분리하기 위해 배경을 제거합니다.
-
카메라 매개변수 추정: 각 이미지의 카메라 위치, 방향, 초점 거리 등을 추정합니다.
-
의미론적 분할: 머리의 다양한 부분(피부, 눈, 입, 코, 머리카락 등)을 분할합니다.
품질 필터링: 낮은 해상도, 흐릿함, 과도한 편집 등으로 인한 저품질 이미지를 필터링합니다.
데이터 증강(Data Augmentation)
데이터셋의 다양성을 높이기 위해 다음과 같은 증강 기법을 적용했습니다:
-
색상 변환: 색상, 명도, 대비를 조정하여 다양한 조명 조건을 시뮬레이션합니다.
-
기하학적 변환: 작은 회전, 크기 조정, 이동을 적용하여 포즈 다양성을 증가시킵니다.
-
합성 데이터 생성: 부족한 후면 뷰 데이터를 보완하기 위해 3D 모델을 사용하여 합성 이미지를 생성합니다.
5. Experiments
SphereHead의 성능을 평가하기 위해 다양한 실험이 수행되었습니다. 이 섹션에서는 훈련 세부 사항, 정성적 및 정량적 비교, 사용자 연구, 단일 시점 GAN 역변환 등의 실험 결과를 살펴보겠습니다.
5.1 Training Details and Baselines

Training Details
SphereHead 모델의 훈련 과정은 다음과 같습니다:
-
최적화 알고리즘: Adam 최적화기를 사용했으며, 학습률은 0.002로 설정했습니다.
-
배치 크기: 32로 설정했습니다.
-
훈련 기간: 약 25,000 iterations(반복) 동안 훈련했습니다.
-
하드웨어: 8개의 NVIDIA A100 GPU를 사용했습니다.
-
손실 함수: 합성을 위한 적대적 손실(adversarial loss), 시점-이미지 일관성 손실(ViCo loss), 그리고 파싱 손실(parsing loss)의 조합을 사용했습니다.
훈련 과정에서 점진적 성장(progressive growing) 전략을 적용했습니다. 먼저 저해상도(64×64)에서 시작하여 점진적으로 해상도를 높여(128×128, 256×256) 최종적으로 512×512 해상도에 도달했습니다.
Baselines (비교 기준선)
SphereHead의 성능을 평가하기 위해 다음과 같은 최신 방법들과 비교했습니다:
-
EG3D: 최초의 tri-plane 표현 기반 3D GAN 중 하나로, 고품질 얼굴 합성에 효과적입니다.
-
PanoHead: 전체 머리 합성을 위해 tri-grid 표현을 사용한 접근법입니다.
-
SphereHead-w/o-SP: 구형 tri-plane 표현 없이 SphereHead 아키텍처를 사용한 변형입니다.
-
SphereHead-w/o-ViCo: 시점-이미지 일관성 손실 없이 SphereHead 아키텍처를 사용한 변형입니다.
이러한 비교를 통해 SphereHead의 각 구성 요소(구형 tri-plane 표현, ViCo 손실)의 효과를 평가할 수 있습니다.
5.2 Qualitative Comparisons
정성적 비교에서는 SphereHead가 기존 방법들에 비해 현저하게 개선된 결과를 보여주었습니다.
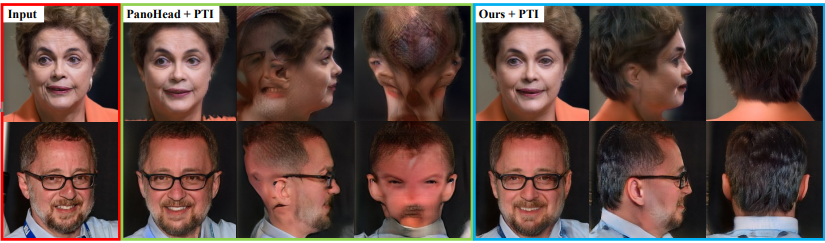
기존 방법들과의 비교
기존 모델들과 SphereHead를 비교했을 때 관찰된 주요 차이점은 다음과 같습니다:
-
EG3D: 정면 및 측면 뷰에서는 좋은 결과를 보였지만, 후면 뷰에서는 심각한 왜곡과 아티팩트가 발생했습니다. 이는 EG3D가 주로 정면 얼굴 이미지로 훈련되었기 때문입니다.
-
PanoHead: 다양한 시점에서 머리를 생성할 수 있었지만, 후면 뷰에서 미러링 아티팩트와 다중 얼굴 아티팩트가 자주 발생했습니다. 예를 들어, 정면에서 안경을 쓴 얼굴이 머리 뒷부분에도 안경이 나타나거나, 다른 정체성의 얼굴 형태가 생성되었습니다.
-
SphereHead: 모든 시점에서 자연스러운 머리를 생성했으며, 미러링 아티팩트와 다중 얼굴 아티팩트가 크게 감소했습니다. 특히 후면 뷰에서 자연스러운 머리카락과 두상 형태를 보여주었습니다.
SphereHead 변형들과의 비교
SphereHead의 다양한 변형을 비교하여 각 구성 요소의 효과를 평가했습니다:
-
SphereHead-w/o-SP: 구형 tri-plane 표현 없이는 미러링 아티팩트가 여전히 발생했습니다. 이는 구형 tri-plane 표현이 머리의 정면과 후면 특징을 효과적으로 분리하는 데 중요하다는 것을 보여줍니다.
-
SphereHead-w/o-ViCo: 시점-이미지 일관성 손실 없이는 다중 얼굴 아티팩트가 여전히 발생했습니다. 이는 ViCo 손실이 카메라 매개변수와 이미지 간의 일관성을 강화하는 데 중요하다는 것을 보여줍니다.
-
SphereHead-full: 모든 구성 요소를 포함한 완전한 SphereHead 모델은 가장 적은 아티팩트와 가장 자연스러운 결과를 보여주었습니다.
5.4 Quantitative Results
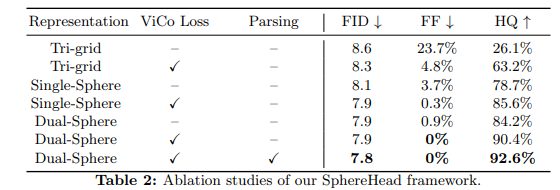
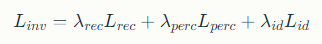
FID 결과는 SphereHead가 모든 시점에서 가장 높은 이미지 품질을 달성했음을 보여줍니다. 특히 후면 뷰에서의 개선이 두드러졌습니다.
또한, SphereHead가 기존 방법들에 비해 아티팩트를 크게 줄였음을 보여줍니다. 특히, 구형 tri-plane 표현이 미러링 아티팩트를 줄이는 데 효과적이며, ViCo 손실이 다중 얼굴 아티팩트를 줄이는 데 효과적임을 확인할 수 있습니다.
5.5 Single-view GAN Inversion
SphereHead의 응용 가능성을 보여주기 위해 단일 시점 GAN 역변환(Single-view GAN Inversion) 실험이 수행되었습니다.
GAN 역변환이란?
GAN 역변환은 실제 이미지를 GAN의 잠재 공간(latent space)에 매핑하는 과정입니다. 이를 통해 GAN은 실제 이미지와 유사한 이미지를 생성할 수 있으며, 더 나아가 실제 이미지의 다양한 변형(예: 다른 시점, 조명, 표정)을 생성할 수 있습니다.
실험 설정
단일 시점 GAN 역변환 실험은 다음과 같이 설계되었습니다:
-
입력: 단일 시점(주로 정면)의 실제 머리 이미지
-
목표: 동일한 정체성을 유지하면서 다양한 시점에서의 머리 이미지 생성
역변환 방법
SphereHead의 역변환 프로세스는 다음과 같은 단계로 이루어집니다:
최적화 기반 역변환: 주어진 입력 이미지와 최대한 유사한 이미지를 생성하는 잠재 코드 z를 찾기 위해 최적화 기반 접근법을 사용합니다. 이는 다음과 같은 손실 함수를 최소화하여 수행됩니다:
는 픽셀 단위 재구성 손실(pixel-wise reconstruction loss)
는 지각적 손실(perceptual loss)
는 ID 손실(identity loss)입니다.
다중 시점 렌더링: 최적화된 잠재 코드 z를 사용하여 다양한 카메라 매개변수 c에 대한 이미지를 렌더링합니다.
6. Discussion
강점
-
감소된 아티팩트: 구형 tri-plane 표현과 ViCo 손실을 통해 미러링 아티팩트와 다중 얼굴 아티팩트를 크게 줄였습니다.
-
향상된 다중 시점 일관성: 모든 시점에서 일관된 정체성과 구조를 유지하는 능력이 향상되었습니다.
-
고품질 머리 합성: 특히 머리 후면에서 자연스러운 머리카락과 두상 형태를 생성하는 능력이 향상되었습니다.
-
효율적인 표현: 구형 tri-plane 표현은 계산 효율성과 메모리 효율성을 유지하면서도 고품질 결과를 달성합니다.
-
일반화 능력: 다양한 헤어스타일, 액세서리, 인구통계학적 특성에 잘 일반화됩니다.
한계점
-
복잡한 액세서리 처리: 매우 복잡한 액세서리(예: 정교한 귀걸이, 헤드폰)의 정확한 표현에 어려움이 있을 수 있습니다.
-
특이한 헤어스타일: 데이터셋에 충분히 표현되지 않은 매우 특이한 헤어스타일(예: 특정 형태의 모호크, 복잡한 브레이드)의 생성에 한계가 있을 수 있습니다.
-
계산 요구사항: 이중 구형 tri-plane 표현은 표준 tri-plane 표현보다 약간 더 많은 계산 리소스를 필요로 합니다.
-
극단적인 포즈: 매우 극단적인 포즈(예: 크게 기울어진 머리)에서는 여전히 약간의 왜곡이 발생할 수 있습니다.
-
후면 뷰 데이터 의존성: 고품질 후면 뷰 생성은 여전히 충분한 후면 뷰 훈련 데이터에 의존합니다.
7. Conclusion
SphereHead는 안정적인 3D 전체 머리 합성을 위한 혁신적인 프레임워크로, 두 가지 핵심 기술적 기여를 통해 기존 모델의 문제점을 해결했습니다. 첫째, 구형 tri-plane 표현은 인간 머리의 구형 특성에 맞게 설계되어 머리의 정면과 후면 특징을 효과적으로 분리함으로써 미러링 아티팩트를 제거했습니다. 둘째, 시점-이미지 일관성 손실 함수는 이미지와 카메라 매개변수 간의 일치를 강화하여 다중 얼굴 아티팩트 문제를 해결했습니다. 연구팀은 다양한 시점의 머리 이미지 60,000장을 포함하는 데이터셋을 구축하고 공개했으며, 광범위한 실험과 사용자 연구를 통해 SphereHead의 우수한 성능을 입증했습니다. 이 기술은 3D 아바타 생성, 가상 현실, 영화, 게임 제작 등 다양한 분야에 활용될 수 있으며, 더 자연스럽고 일관된 3D 콘텐츠 생성을 위한 새로운 가능성을 열었습니다.
