Post-Training Quantization for Vision Transformer 논문 리뷰


0. Abstraction
Transformer 모델은 컴퓨터 비전에서 뛰어난 성능을 보이지만, 복잡한 아키텍처로 인해 모바일 장치 구현이 어렵습니다. 본 논문은 Vision Transformer의 메모리와 계산 비용을 줄이기 위한 효과적인 post-training quantization 알고리즘을 제안합니다. Attention 메커니즘을 보존하기 위해 ranking loss를 도입하고, 양자화 후에도 self-attention 결과의 상대적 순서를 유지합니다. 또한 각 레이어의 양자화 손실과 특징 다양성 간의 관계를 분석하고, attention map과 출력 특징의 nuclear norm을 활용한 mixed-precision quantization 방식을 제안합니다. 실험 결과, 제안된 방법은 기존 최신 알고리즘보다 우수한 성능을 보였으며, DeiT-B 모델로 ImageNet에서 81.29%의 top-1 정확도를 달성했습니다.
1. Introduction
Transformer 기반 모델들은 이미지 분류, 객체 탐지 등 다양한 컴퓨터 비전 작업에서 뛰어난 성능을 보이지만, 수억 개의 매개변수와 높은 계산 비용으로 인해 자원이 제한된 장치에서 실행하기 어렵습니다. 양자화는 모델 아키텍처를 변경하지 않고 가중치에 더 낮은 비트 폭을 사용하여 신경망을 압축하는 효과적인 기술입니다. NLP 분야에서는 BERT와 같은 모델에 양자화 방법이 적용되었지만, 컴퓨터 비전용으로 설계되지 않았고 추가 훈련이 필요합니다. Post-training quantization은 미세 조정 없이 신경망을 직접 양자화할 수 있지만, 기존 방법들은 Vision Transformer의 고유한 구조를 고려하지 않습니다. 본 논문에서는 Vision Transformer의 특성을 고려한 효과적인 Post-training quantization(PTQ) 알고리즘을 제안합니다.
2 Related Works
2.1 Vision Transformer
컴퓨터 비전 분야에 Transformer를 적용한 다양한 연구들이 진행되었습니다. Chen 등은 픽셀을 자동 회귀적으로 예측하는 시퀀스 Transformer를 훈련시켜 CNN과 비슷한 성능을 달성했습니다. Dosovitskiy 등이 제안한 ViT는 이미지 패치를 시퀀스로 간주하여 Transformer를 직접 적용하는 모델로, 여러 이미지 인식 벤치마크에서 뛰어난 성능을 보였습니다. Touvron 등은 ImageNet에서만 훈련하면서 Transformer에 특화된 교사-학생 전략을 도입한 DeiT를 개발했습니다. 이외에도 객체 탐지, 의미 분할, 이미지 처리, 비디오 이해 등 다양한 컴퓨터 비전 문제에 Transformer 기반 모델이 적용되고 있습니다.
2.2 Compression of Transformer in NLP
BERT와 같은 Transformer 모델의 메모리와 계산 복잡성을 줄이기 위한 다양한 접근법이 제안되었습니다. Wu 등은 지역 컨텍스트와 장거리 관계 모델링을 분리하여 엣지 장치에서 Transformer를 실행하기 위한 Short Range Attention을 제안했습니다. 8비트 양자화는 Transformer 모델에 성공적으로 적용되었지만, 초저비트(1-2비트) 양자화는 모델 용량 감소로 인해 더 어렵습니다. 이를 해결하기 위해 mixed-precision quantization과 product quantization 같은 복잡한 방법들이 사용되었습니다. Zhang 등의 TernaryBERT와 Bai 등의 이진화 연구는 더 낮은 비트로 BERT를 압축했지만, 컴퓨터 비전용으로 설계되지 않았으며 추가 훈련이 필요합니다.
2.3 Post-Training Quantization
미세 조정 없이 신경망을 양자화하는 post-training quantization 방법들이 다수 개발되었습니다. Yoni 등은 양자화된 텐서와 원래 텐서 사이의 L2 거리를 최적화하는 OMSE 방법을 제안했습니다. Ron 등은 클리핑 범위와 채널당 비트 할당을 분석적으로 계산하는 ACIQ 방법을 제시했습니다. Zhao 등은 이상치 채널 문제를 해결하기 위한 이상치 채널 분할(OCS) 방법을 제안했습니다. Wang 등은 더 낮은 비트 양자화를 위한 Bit-Split and Stitching 프레임워크를, Nagel 등은 가중치 반올림 메커니즘인 AdaRound를 제안했습니다. 이러한 방법들은 CNN을 위해 설계되었으며 Vision Transformer의 고유한 구조를 고려하지 않습니다.
3 Methodology
3.1 Preliminaries
표준 Transformer는 1-D 토큰 임베딩 시퀀스를 입력으로 받기 때문에, Vision Transformer는 일반적으로 이미지 를 일련의 평평한 2D 패치 ∈ 로 재구성합니다. 여기서 H와 W는 원본 이미지의 높이와 너비이고, (P, P)는 각 이미지 패치의 해상도입니다. 따라서 는 Transformer의 유효 시퀀스 길이입니다.
일반적으로 Vision Transformer는 모든 레이어에서 일정한 너비를 사용하므로, 훈련 가능한 선형 투영이 각 벡터화된 패치를 모델 차원 d로 매핑합니다. 따라서 첫 번째 Transformer 레이어에 대한 입력은 다음과 같습니다.
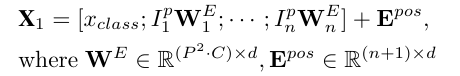
표준 Transformer 레이어는 두 가지 주요 모듈을 포함합니다: Multi-Head Self Attention(MSA)과 Multi-Layer Perceptron(MLP) 모듈입니다. l번째 Transformer 레이어에 대해, 그 입력이 라고 가정하면, queries와 keys의 점곱으로 계산된 어텐션 점수는 다음과 같이 표현할 수 있습니다:
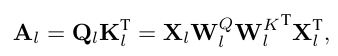
그런 다음 정규화된 점수에 softmax 함수를 적용하여 출력을 얻고, multi-head self attention 모듈의 출력은 다음과 같습니다:
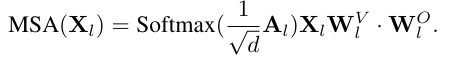
MLP 모듈은 및 로 매개변수화된 두 개의 선형 레이어를 포함합니다. 여기서 는 MLP의 중간 레이어의 뉴런 수입니다. MLP의 입력을 라고 하면, 출력은 다음과 같이 계산됩니다:
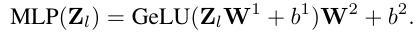
이를 종합하여, l번째 Transformer 레이어에 대한 순방향 전파는 다음과 같이 표현할 수 있습니다:
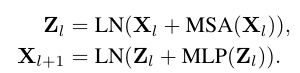
여기서 LN은 레이어 정규화(Layer Normalization)를 나타냅니다.
Vision Transformer의 가장 큰 계산 비용은 MSA와 MLP 모듈의 대규모 행렬 곱셈에 있습니다. CNN을 위한 주류 양자화 방법을 따라, 우리는 행렬 곱셈에 관련된 모든 가중치와 입력을 양자화합니다. 가중치 양자화의 경우, 모든 Transformer 레이어의 가중치 와 선형 임베딩 를 양자화합니다. 이 가중치 외에도, 모든 선형 레이어와 행렬 곱셈 연산의 입력도 양자화합니다. 기존 방법을 따라, softmax 연산과 레이어 정규화는 양자화하지 않습니다. 이는 이러한 연산에 포함된 매개변수가 무시할 수 있을 정도로 적고, 양자화할 경우 정확도가 크게 저하될 수 있기 때문입니다.
3.2 Optimization for Post-Training Quantization (학습 후 양자화를 위한 최적화)
학습 후 양자화의 경우, 부동 소수점 숫자를 유한한 값 집합으로 제한해야 합니다. 양자화 간격의 선택은 양자화에 매우 중요하며, 널리 사용되는 옵션 중 하나는 데이터 범위를 균등하게 분할하는 uniform quantization function(균일 양자화 함수)를 사용하는 것입니다:
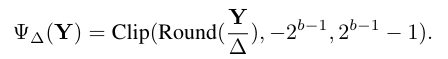
여기서 는 양자화 간격, b는 양자화 비트 폭, Y는 가중치나 입력을 나타내는 텐서입니다. Clip은 양자화된 도메인의 범위를 초과하는 텐서의 요소를 제한하는 것을 의미합니다.
Similarity-Aware Quantization for Linear Operation(선형 연산을 위한 유사성 인식 양자화)
l번째 Transformer 레이어의 MSA 모듈과 MLP 모듈의 선형 연산에 대해, 원래 출력은 로 계산됩니다. 가중치와 입력에 대한 균일 양자화와 해당 역양자화 연산은 다음과 같이 설명할 수 있습니다:
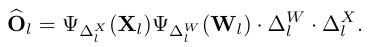
여기서 은 양자화된 레이어의 출력을 나타냅니다. 양자화 간격은 실제로 양자화 과정에서 클리핑 임계값을 제어하며, 이는 원래 출력 특징 맵과 양자화된 특징 맵 간의 유사성에 큰 영향을 미칩니다. 따라서, 가중치 와 입력 모두에 대한 양자화 간격을 최적화하여 과 사이의 유사성을 향상시키는 데 초점을 맞춥니다. 여기서 입력 은 N개의 샘플이 있는 주어진 보정 데이터셋 D에서 생성됩니다. 구체적으로, 보정 데이터셋은 일반적인 학습 데이터셋보다 훨씬 적습니다. l번째 Transformer 레이어에서, 유사성 인식 양자화는 다음과 같이 공식화될 수 있습니다:
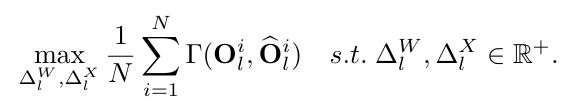
여기서 는 원래 출력 특징 맵과 양자화된 출력 특징 맵 사이의 유사성입니다. 이 논문에서는 유사성 측정을 위해 Pearson correlation coefficient(피어슨 상관 계수)를 채택합니다:
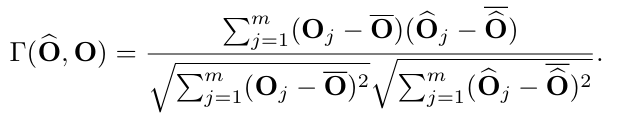
Ranking-Aware Quantization for Self-Attention(Self-Attention을 위한 순위 인식 양자화)
Self-Attention 레이어는 특징들의 전역 관련성을 계산할 수 있기 때문에 Transformer의 핵심 구성 요소입니다. 이는 Transformer가 CNN과 차별화되는 특성입니다. Self-Attention 계산에 있어서, 연구자들은 양자화 후에 어텐션 맵의 상대적 순서가 변경되는 것을 경험적으로 발견했습니다. 이는 성능 저하를 크게 초래할 수 있습니다. 따라서, 이 문제를 해결하기 위해 양자화 과정 중에 순위 손실(ranking loss)을 도입했습니다:
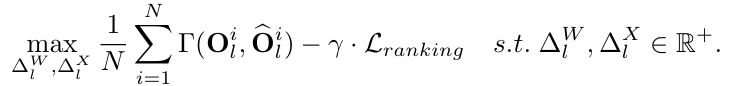
여기서 은 쌍별 순위 기반 손실 함수를 나타내며, γ는 트레이드오프 하이퍼파라미터입니다. 순위 손실은 다음과 같이 공식화할 수 있습니다:

여기서 는 매개변수 θ를 가진 힌지 함수(hinge function)이고, (h, w)는 행렬 A의 크기입니다. 주어진 예제 쌍에 대해, 예제들이 올바른 순서로 배열되고 마진으로 구분될 때만 손실이 0이 됩니다.
위의 최적화 문제를 해결하기 위해, Transformer 레이어의 균일 양자화를 위한 간단하지만 효율적인 대체 검색 방법을 제시합니다. 먼저, 입력의 양자화 간격 를 고정하고, 가중치의 양자화 간격 를 조정을 위해 최적화합니다. 둘째, 를 고정하고, 입력의 양자화 간격을 미세 조정하기 위해 를 최적화합니다. 목표 함수가 수렴하거나 최대 반복 횟수를 초과할 때까지 와 를 번갈아 최적화합니다. 또한, 빠른 수렴을 위해, 와 는 각각 가중치 또는 입력의 최대값을 기준으로 초기화됩니다. 와 의 검색 공간에 대해, 우리는 구간을 C개의 후보 옵션으로 선형적으로 나누고 그들에 대해 간단한 검색 전략을 수행합니다.
Bias Correction (편향 보정)
양자화로 인해 발생하는 출력의 편향된 오류를 더욱 줄이기 위해, 각 검색 반복 후에 편향 보정 방법을 도입합니다. 가중치와 입력의 양자화 오류가 다음과 같이 정의된다고 가정합니다:
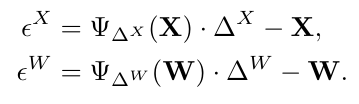
출력 오류의 기대값이 0이 아니라면, 출력의 평균이 변할 것입니다. 이러한 분포의 변화는 다음 레이어에서 해로운 동작을 초래할 수 있습니다. 우리는 다음을 관찰함으로써 이 변화를 수정할 수 있습니다:
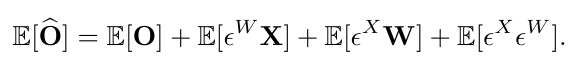
따라서, 편향된 출력에서 예상 오류를 빼는 것은 각 출력 단위의 평균이 보존되도록 합니다. 구현을 위해, 예상 오류는 보정 데이터를 사용하여 계산할 수 있으며, 예상 오류 벡터가 레이어의 출력과 동일한 형태를 가지므로 레이어의 편향 매개변수에서 뺄 수 있습니다.
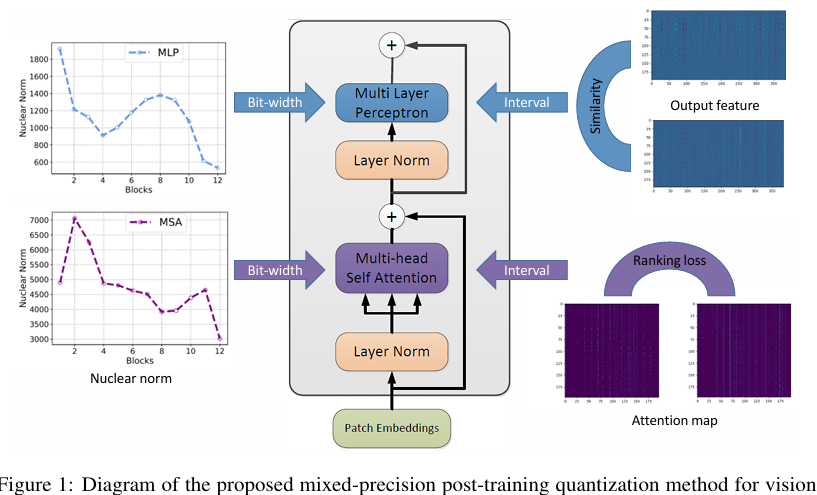
3.3 Mixed-Precision Quantization for Vision Transformer(Vision Transformer를 위한 혼합 정밀도 양자화)
서로 다른 Transformer 레이어는 서로 다른 구조에 주목하며, 당연히 그들은 서로 다른 민감도를 보입니다. 따라서, 모든 레이어에 동일한 비트 폭을 할당하는 것은 최적이 아닙니다. 결과적으로, 우리는 성능을 유지하기 위해 더 민감한 레이어에 더 많은 비트를 할당하는 혼합 정밀도 양자화를 탐색합니다. Transformer 레이어의 고유한 구조를 고려하여, 우리는 MSA 또는 MLP 모듈의 모든 연산에 동일한 비트 폭을 할당합니다. 이는 가중치와 입력이 동일한 비트 폭으로 할당되므로 하드웨어 구현에도 친화적일 것입니다.
특이값 분해(Singular Value Decomposition, SVD)는 선형 대수학에서 중요한 행렬 분해 접근법입니다. 이는 유전자 발현 데이터의 직사각형 행렬을 취하며, 그 공식은 다음과 같이 작성될 수 있습니다:
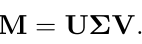
여기서 ∑의 대각선 항목 는 M의 특이값으로 알려져 있습니다. 그리고 nuclear norm(핵 노름)은 특이값의 합으로, 행렬의 데이터 관련성을 나타냅니다. 이 논문에서는 MSA 모듈의 어텐션 맵과 MLP 모듈의 출력 특징의 핵 노름으로 Transformer 레이어의 민감도를 추정할 것을 제안합니다. 핵 노름은 더 민감한 레이어에는 더 높은 비트 폭을 사용하고 그렇지 않은 레이어에는 그 반대로 사용하면서 혼합 정밀도 설정의 검색 공간을 줄이는 데 사용될 수 있습니다. 기존 방법에서 영감을 받아, 우리는 비트 폭을 결정하기 위해 파레토 프론티어(Pareto frontier) 접근법을 활용합니다. 주요 아이디어는 다음 메트릭에 따라 그들이 초래하는 총 2차 섭동에 기반하여 각 후보 비트 폭 구성을 정렬하는 것입니다:
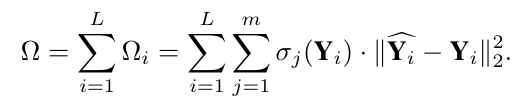
주어진 목표 모델 크기에 대해, 우리는 그들의 Ω 값에 기반하여 후보 비트 폭 구성을 정렬하고 최소 Ω를 가진 비트 폭 구성을 선택합니다. 각 Transformer 레이어의 어텐션 맵과 출력 특징의 nuclear norm(핵 노름)이 그림 1에 나와 있습니다. 볼 수 있듯이, 이들은 서로 다른 Transformer 레이어마다 다양합니다.
4. Experimental Results(실험 결과)
4.1 Implementation Details(구현 세부 사항)
- 이미지 분류에는 CIFAR-10, CIFAR-100, ImageNet 데이터셋을, 객체 탐지에는 COCO2017 데이터셋을 사용함.
- 보정 데이터셋으로 CIFAR에서는 100개, ImageNet과 COCO에서는 1000개의 이미지를 무작위로 선택함.
- 기준 모델로는 ViT-B, ViT-L, DeiT-S, DeiT-B(이미지 분류용)와 DETR(객체 탐지용)을 사용함.
4.2 Results and Analysis
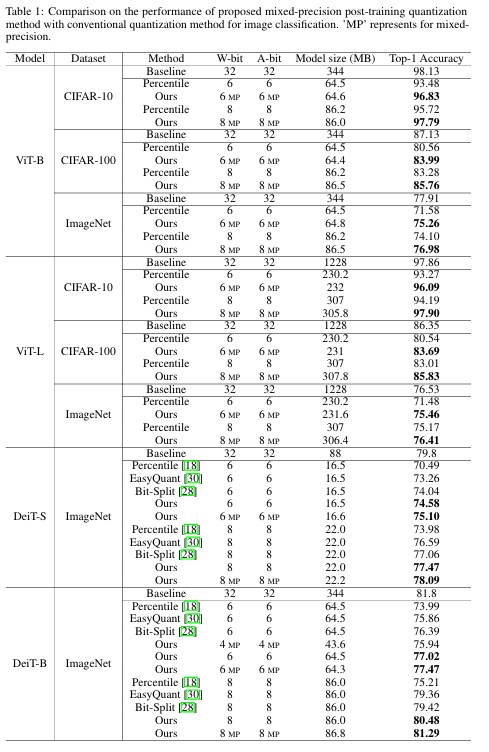
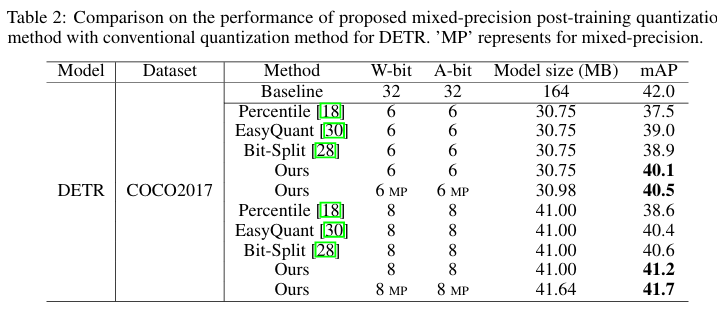
- 제안된 방법은 모든 모델과 데이터셋에서 기존 방법들보다 우수한 성능을 보임.
- 8비트 양자화 모델은 대부분 전체 정밀도 모델과 비슷한 성능을 달성함.
- Mixed-precision 양자화는 성능을 더욱 향상시키며, 객체 탐지 작업에서도 우수한 일반화 능력을 보여줌.
4.3 Ablation Study

- 유사성 인식 양자화, 순위 인식 양자화, 편향 보정, 혼합 정밀도 각 구성 요소의 효과를 개별적으로 분석함.
- 각 구성 요소가 양자화된 모델의 성능 향상에 기여하며 모두 사용했을 때 최상의 결과를 얻음.
- 특히 Nuclear Norm(핵 노름) 기반 혼합 정밀도는 서로 다른 레이어의 다양한 민감도를 고려하여 성능을 크게 향상시킴.
5. Conclusion
본 논문에서는 Vision Transformer를 위한 효과적인 post-training quantization 알고리즘을 제안했습니다. 이 방법은 선형 레이어에 대한 유사성 인식 양자화와 Self-Attention에 대한 순위 인식 양자화를 포함하며, 편향 보정과 nuclear norm 기반 mixed-precision 양자화를 통해 성능을 향상시켰습니다. 실험 결과, 제안된 방법은 다양한 모델과 데이터셋에서 기존 방법들보다 우수한 성능을 보였으며, ImageNet에서 DeiT-B 모델로 81.29%의 top-1 정확도와 COCO에서 DETR 모델로 우수한 성능을 달성했습니다. 이 연구는 Vision Transformer 모델의 압축과 가속화에 중요한 기여를 하며, 향후 더 다양한 아키텍처와 더 낮은 비트 양자화 연구가 기대됩니다.
