CLIP: Learning Transferable Visual Models From Natural Language Supervision 논문 리뷰
0. Abstraction
최근 딥러닝, 특히 합성곱 신경망(Convolutional Neural Network, CNN)은 컴퓨터 비전 분야에서 놀라운 성과를 이루었습니다. 그러나 이러한 네트워크는 많은 계산 자원과 메모리를 필요로 하기 때문에 모바일 기기나 임베디드 시스템에서 실행하기 어렵습니다.
이 논문에서는 기존 CNN의 두 가지 효율적인 근사 방법을 제안합니다:
-
Binary-Weight-Networks (이진 가중치 네트워크): 필터의 가중치를 이진값(+1 또는 -1)으로 근사화하여 메모리 사용량을 32배 절약합니다.
-
XNOR-Networks (XNOR 네트워크): 가중치뿐만 아니라 합성곱 레이어의 입력까지 이진화하여 주로 이진 연산만으로 합성곱을 근사화합니다. 이는 고정밀 연산의 수를 58배 줄이고 메모리를 32배 절약합니다.
이러한 접근 방식은 GPU 대신 CPU에서도 최신 네트워크를 실시간으로 실행할 수 있는 가능성을 제공합니다. 저자들은 ImageNet 분류 작업에서 이 방법을 평가했고, Binary-Weight-Network 버전의 AlexNet은 전체 정밀도(full-precision) AlexNet과 동일한 분류 정확도를 달성했습니다. 또한 기존의 네트워크 이진화 방법인 BinaryConnect와 BinaryNets보다 ImageNet에서 top-1 정확도가 16% 이상 향상되었습니다.
2. Related Work
Shallow networks (얇은 네트워크)
깊은 신경망을 더 얕은 모델로 추정하여 네트워크 크기를 줄이는 방법입니다. Cybenko의 초기 이론적 연구에 따르면, 충분히 큰 단일 은닉층을 가진 시그모이드 유닛 네트워크는 어떤 결정 경계도 근사화할 수 있다고 합니다. 그러나 실제 컴퓨터 비전이나 음성 인식과 같은 복잡한 분야에서는 얕은 네트워크가 깊은 모델과 경쟁하기 어렵습니다.
Ba와 Caruana의 연구에서는 깊은 네트워크를 모방하도록 얕은 네트워크를 훈련시키는 방법을 제안했지만, 유사한 정확도를 얻으려면 얕은 네트워크의 매개변수 수가 깊은 네트워크의 매개변수 수와 비슷해야 했습니다.
Compressing pre-trained networks (사전 훈련된 네트워크 압축)
이전에 훈련된 네트워크에서 중복적이거나 중요하지 않은 가중치를 제거(pruning)하여 추론 시 네트워크 크기를 줄이는 방법입니다. 초기에는 가중치 감쇠(Weight decay)가 사용되었고, 이후 Optimal Brain Damage와 Optimal Brain Surgeon은 손실 함수의 헤시안(Hessian)을 사용하여 연결 수를 줄이는 방법을 제안했습니다.
최근에는 Han 등이 가지치기를 통해 여러 최첨단 신경망의 매개변수 수를 크게 줄였습니다. Deep compression은 중복 연결을 제거하고 가중치를 양자화한 후 허프만 코딩으로 압축하여 모바일 기기에서 대형 네트워크를 실행하기 위한 저장소와 에너지 소비를 줄였습니다.
Designing compact layers (컴팩트 레이어 설계)
딥 네트워크의 각 레이어에서 컴팩트한 구조를 설계하는 방법입니다. 완전 연결 레이어를 글로벌 평균 풀링으로 대체하는 방법이 Network in Network, GoogLenet, Residual-Net에서 사용되었습니다. Residual-Net의 병목 구조는 매개변수 수를 줄이고 속도를 향상시키기 위해 제안되었습니다.
또한 3×3 합성곱을 더 작은 1×1 합성곱으로 분해하거나 대체하는 방법도 연구되었으며, 이를 통해 매개변수 수를 크게 줄이면서도 높은 정확도를 달성할 수 있었습니다.
Quantizing parameters (매개변수 양자화)
높은 정밀도의 매개변수가 딥 네트워크의 성능에 반드시 필요한 것은 아니라는 발견에 기반합니다. Gong 등은 벡터 양자화 기술을 사용하여 완전 연결 레이어의 가중치를 양자화했으며, 단순히 가중치 값을 0에서 임계값을 설정하는 것만으로도 정확도 손실이 크지 않음을 보여주었습니다.
다른 연구들은 +1/0/-1 가중치를 가진 희소 네트워크 훈련, 8비트 정수의 고정 소수점 구현, 삼진 가중치와 3비트 활성화를 가진 고정 소수점 네트워크 등 다양한 양자화 방법을 제안했습니다.
Network binarization (네트워크 이진화)
본 논문과 가장 관련성이 높은 연구 분야입니다. 네트워크 이진화는 신경망의 가중치와 활성화를 이진값으로 제한하는 방법입니다.
Expectation BackPropagation(EBP)은 이진 가중치와 이진 활성화를 가진 네트워크로도 높은 성능을 달성할 수 있음을 보여주었습니다. BinaryConnect는 EBP의 확률적 아이디어를 확장하여, 전방 및 후방 전파 중에 이진 가중치를 사용하고 매개변수 업데이트 단계에서는 실수값 가중치를 유지하는 방법을 제안했습니다.
BinaryNet은 BinaryConnect를 더 확장하여 가중치와 활성화 모두를 이진화했습니다. 본 논문의 접근 방식은 이들과 유사하지만 이진화 방법과 네트워크 구조에서 차이가 있으며, ImageNet에서의 실험 결과 BinaryNet보다 훨씬 우수한 성능을 보였습니다.
3. Binary Convolutional Neural Network
CNN을 ⟨I, W, *⟩로 표현할 수 있으며, 여기서 I는 입력 텐서의 집합, W는 가중치 필터의 집합, *는 합성곱 연산을 나타냅니다. 두 가지 이진 CNN 변형을 제안합니다: Binary-Weight-Networks와 XNOR-Networks.
3.1 Binary-Weight-Networks
Binary-Weight-Networks에서는 실수값 가중치 필터 W를 이진 필터 와 스케일링 팩터 α ∈ R+를 사용하여 W ≈ αB로 근사화합니다. 이를 통해 합성곱 연산은 다음과 같이 근사화될 수 있습니다:
여기서 ⊕는 곱셈이 없는 합성곱 연산을 나타냅니다. 가중치가 이진값이므로, 합성곱은 덧셈과 뺄셈만으로 구현할 수 있으며, 메모리 사용량을 32배 절약할 수 있습니다.
Estimating binary weights (이진 가중치 추정)
최적의 이진 가중치와 스케일링 팩터를 찾기 위해, 실수값 가중치 W와 이진 가중치 αB 사이의 L2 거리를 최소화하는 최적화 문제를 해결합니다:
이 문제의 최적 해는 다음과 같습니다:
최적 이진 가중치: (가중치의 부호를 취함)
최적 스케일링 팩터: (절대 가중치 값의 평균)
따라서, 이진 가중치 필터의 최적 추정은 가중치 값의 부호를 취하고, 최적 스케일링 팩터는 절대 가중치 값의 평균을 사용하는 것으로 간단히 구할 수 있습니다.
Training Binary-Weights-Networks
CNN 훈련의 각 반복은 전방 패스, 후방 패스, 매개변수 업데이트의 세 단계로 이루어집니다. Binary-Weight-Networks를 훈련시키기 위해, 전방 패스와 후방 전파 동안에만 가중치를 이진화하고, 매개변수 업데이트는 실수값 가중치를 사용합니다.
이는 매개변수 변화가 매우 작기 때문에, 매개변수 업데이트 후 바로 이진화하면 이러한 작은 변화가 무시되어 훈련 목표가 개선되지 않기 때문입니다. 이 훈련 방식은 BinaryConnect와 유사합니다.
3.2 XNOR-Networks
XNOR-Networks는 한 단계 더 나아가 가중치뿐만 아니라 합성곱 레이어의 입력도 이진화합니다. 이를 통해 합성곱 연산을 XNOR 비트 연산과 비트 카운팅으로 대체하여 계산 효율성을 크게 향상시킬 수 있습니다.
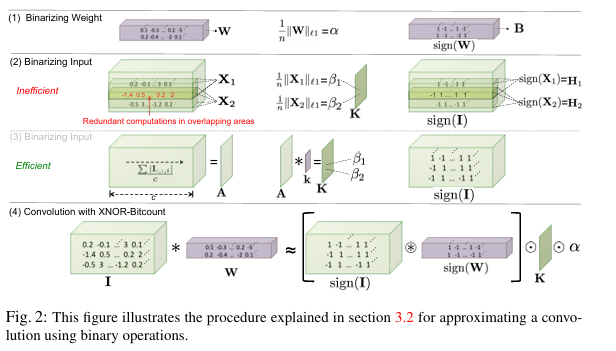
Binary Dot Product (이진 내적)
두 실수 벡터 사이의 내적을 로 근사화하고자 합니다. 여기서 은 이진 벡터이고 는 스케일링 팩터입니다.
최적화 문제를 풀면, 최적 이진 벡터는 로 주어지며, 여기서 ⊙는 요소별 곱을 나타냅니다. 최적 스케일링 팩터는 γ = βα로, β는 입력의 절대값 평균, α는 가중치의 절대값 평균입니다.
Binary Convolution (이진 합성곱)
합성곱은 시프트 연산과 내적의 반복으로 구성됩니다. 이진 내적을 사용하면, 이진 가중치와 이진 입력 사이의 합성곱을 다음과 같이 근사화할 수 있습니다:
여기서 ⊛는 XNOR 및 비트 카운팅 연산을 사용한 합성곱을 나타내며, K는 입력의 모든 하위 텐서에 대한 스케일링 팩터를 포함하는 행렬입니다. 이를 통해 합성곱 연산을 주로 이진 연산으로 수행하여 계산 효율성을 크게 향상시킬 수 있습니다.
Training XNOR-Networks
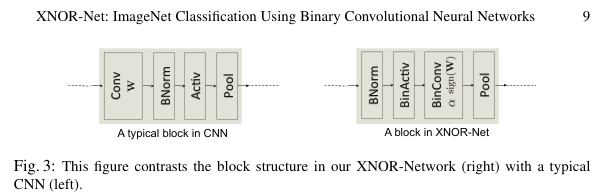
CNN의 일반적인 블록 구조는 합성곱(Convolution), 배치 정규화(Batch Normalization), 활성화(Activation), 풀링(Pooling) 순으로 구성됩니다. 그러나 이진 입력에 풀링을 적용하면 상당한 정보 손실이 발생합니다.
저자들은 이를 해결하기 위해 블록 구조를 변경하여, 먼저 배치 정규화를 적용한 후 이진 활성화, 그 다음 이진 합성곱, 마지막으로 풀링을 적용하는 순서를 제안합니다. 이렇게 하면 이진화로 인한 정보 손실을 최소화할 수 있습니다.
훈련 알고리즘은 Binary-Weight-Networks와 유사하게, 전방 패스와 후방 전파에서는 이진 가중치와 이진 입력을 사용하고, 매개변수 업데이트에서는 실수값 가중치를 사용합니다.
BinaryGradient (이진 그래디언트)
각 레이어에서 후방 패스의 계산 병목 현상은 가중치 필터(w)와 입력에 대한 그래디언트() 사이의 합성곱을 계산하는 것입니다. 전방 패스에서의 이진화와 유사하게, 후방 패스에서 을 이진화할 수 있습니다. 이는 이진 연산을 사용하는 매우 효율적인 훈련 절차로 이어집니다.
방정식 6을 사용하여 에 대한 스케일링 팩터를 계산하면 SGD에 대한 최대 변화 방향이 감소됩니다. 모든 차원에서 최대 변화를 보존하기 위해, 스케일링 팩터로 를 사용합니다.
k-bitQuantization (k-비트 양자화)
지금까지 sign(x) 함수를 사용하여 가중치와 입력의 1비트 양자화를 보여주었습니다. 양자화 수준을 k-비트로 쉽게 확장할 수 있습니다. 부호 함수 대신 를 사용하면 됩니다. 여기서 은 반올림 연산을 나타내며, 입니다.
4. Experiments
4.1 Efficiency Analysis
메모리 효율성
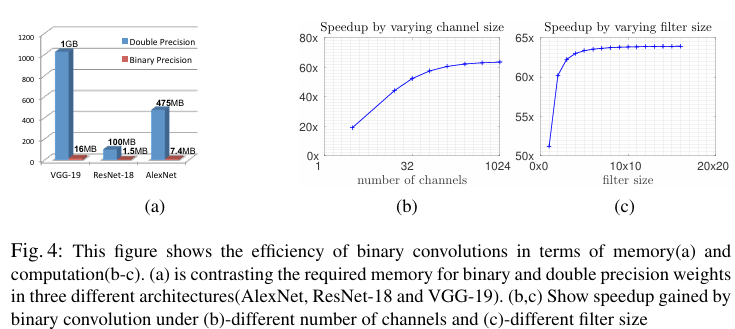
이진 가중치를 사용하면 32비트 실수 대신 1비트로 가중치를 저장할 수 있어 메모리 요구량을 32배 줄일 수 있습니다. 그림 4-a는 AlexNet, VGG-19, ResNet-18에서 이진 가중치와 실수 가중치에 필요한 메모리를 비교한 결과를 보여줍니다. 이진 가중치 네트워크는 크기가 매우 작아 휴대용 기기에 쉽게 탑재될 수 있습니다.
계산 효율성
표준 합성곱에서 총 연산 수는 로, c는 채널 수, 는 필터 크기, 는 입력 크기입니다. 저자들의 이진 합성곱 근사에서는 이진 연산과 비이진 연산만 필요합니다.
최신 CPU에서는 한 클록에 64개의 이진 연산을 수행할 수 있으므로, 이론적인 속도 향상은 로 계산됩니다. 일반적인 CNN 구조에서는 약 62.27배의 속도 향상이 가능하며, 실제 CPU 구현에서는 58배의 속도 향상을 달성했습니다.
채널 크기가 작은 첫 번째 레이어(c=3)와 필터 크기가 작은 마지막 레이어(1×1)는 이진화 시 효율성이 낮아 이진화하지 않는 것이 좋습니다.
4.2 Image Classification
저자들은 제안된 방법을 ImageNet 데이터셋에서 평가했습니다. ImageNet은 1000개 카테고리의 약 120만 개 훈련 이미지와 5만 개 검증 이미지를 포함하는 대규모 데이터셋입니다.

AlexNet
AlexNet 아키텍처에 대한 실험 결과, Binary-Weight-Network(BWN)는 56.8% top-1, 79.4% top-5 정확도를 달성했으며, 이는 전체 정밀도 AlexNet(56.6% top-1, 80.2% top-5)과 거의 동일한 수준입니다. XNOR-Network는 44.2% top-1, 69.2% top-5 정확도를 달성했습니다.
반면, 경쟁 방법인 BinaryConnect(BC)는 35.4% top-1, 61.0% top-5 정확도를, BinaryNet(BNN)은 27.9% top-1, 50.42% top-5 정확도를 달성하여, 저자들의 방법이 큰 차이(약 17%)로 우수함을 보여주었습니다.
ResNet-18
ResNet-18 아키텍처에 대한 실험에서는 BWN이 60.8% top-1, 83.0% top-5 정확도를 달성했으며, XNOR-Net은 51.2% top-1, 73.2% top-5 정확도를 달성했습니다. 전체 정밀도 ResNet-18의 정확도는 69.3% top-1, 89.2% top-5로, BWN이 상당히 근접한 성능을 보여주었습니다.
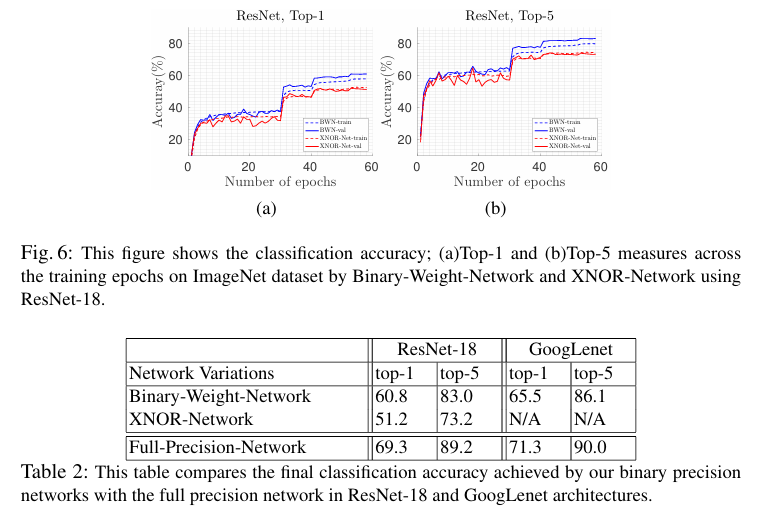
GoogLenet 변형
GoogLenet 변형 아키텍처에서는 BWN이 65.5% top-1, 86.1% top-5 정확도를 달성했으며, 전체 정밀도 네트워크의 정확도는 71.3% top-1, 90.0% top-5였습니다.
이러한 결과는 Binary-Weight-Networks가 전체 정밀도 네트워크에 매우 근접한 성능을 달성할 수 있음을 보여줍니다. XNOR-Networks는 가중치와 입력 모두를 이진화함에도 불구하고 상당히 높은 정확도를 유지했으며, 두 방법 모두 기존의 네트워크 이진화 방법들보다 훨씬 우수한 성능을 보였습니다.
4.3 Ablation Studies
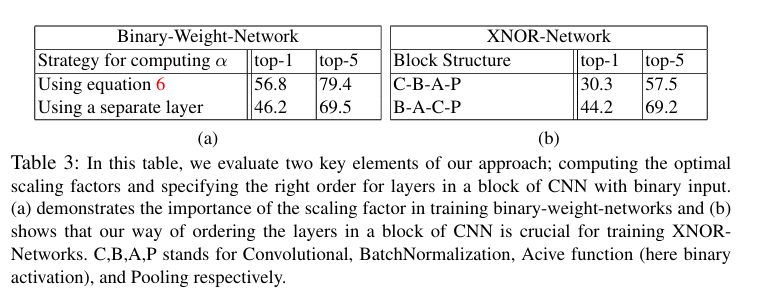
스케일링 팩터 계산 방법의 영향
스케일링 팩터 α를 방정식 6을 사용하여 계산하는 방법과, α를 네트워크 매개변수로 간주하여 별도의 레이어로 학습하는 방법을 비교했습니다.
결과적으로, 방정식 6을 사용한 방법이 top-1 정확도 56.8%, top-5 정확도 79.4%를 달성한 반면, 별도 레이어를 사용한 방법은 top-1 정확도 46.2%, top-5 정확도 69.5%로 성능이 저하되었습니다. 이는 최적의 스케일링 팩터를 계산하는 방법이 이진 네트워크의 성능에 중요함을 보여줍니다.
CNN 블록 구조의 영향
저자들은 표준 블록 구조인 C-B-A-P(Convolution, Batch Normalization, Activation, Pooling)와 제안된 블록 구조인 B-A-C-P의 성능을 비교했습니다.
결과적으로, 제안된 B-A-C-P 구조가 top-1 정확도 44.2%, top-5 정확도 69.2%를 달성한 반면, 표준 C-B-A-P 구조는 top-1 정확도 30.3%, top-5 정확도 57.5%에 그쳤습니다. 이는 이진 입력을 사용할 때 레이어 순서가 성능에 중요한 영향을 미침을 보여줍니다.
이러한 연구 결과는 저자들이 제안한 스케일링 팩터 계산 방법과 블록 구조가 이진 네트워크의 성능 향상에 중요한 역할을 함을 입증합니다.
5. Conclusion
Binary-Weight-Networks: 가중치를 이진화하여 네트워크 크기를 32배 줄입니다. 이는 제한된 메모리를 가진 기기에서도 깊은 신경망을 사용할 수 있게 합니다. 놀랍게도, 이진 가중치 버전의 AlexNet은 전체 정밀도 AlexNet과 동일한 정확도를 달성했습니다.
XNOR-Networks: 가중치와 입력 모두 이진화하여 주로 비트 연산만으로 계산을 수행합니다. 이는 58배의 속도 향상을 제공하며, GPU 없이도 CPU에서 실시간 추론을 가능하게 합니다.
이 연구는 ImageNet과 같은 대규모 데이터셋에서 이진 신경망의 성능을 평가한 최초의 시도입니다. 실험 결과, 제안된 방법은 기존의 네트워크 이진화 방법들보다 훨씬 높은 정확도를 달성했습니다.
이러한 발전은 모바일 기기, 임베디드 시스템, 웨어러블 디바이스 등 제한된 자원을 가진 환경에서도 최첨단 딥러닝 모델을 효율적으로 실행할 수 있는 가능성을 열어줍니다. 향후 연구 방향으로는 다양한 네트워크 아키텍처에 이 방법을 적용하거나, 이진화 기법을 더욱 개선하여 정확도와 효율성의 균형을 더욱 향상시키는 것이 있을 수 있습니다.
