Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation 논문 리뷰
paper: https://arxiv.org/pdf/2501.12202
github: https://github.com/Tencent/Hunyuan3D-2
1. Introduction
3D 콘텐츠는 게임, 영화, 가상현실(VR), 증강현실(AR)을 비롯한 다양한 분야에서 필수적인 요소가 되었습니다. 하지만 전통적인 3D 모델링 방식은 전문적인 기술과 많은 시간이 필요한 복잡한 과정입니다. 특히 고품질의 텍스처를 입힌 3D 에셋을 만드는 작업은 매우 작업 난이도가 높습니다.
최근 인공지능, 특히 확산 모델(Diffusion Models)의 발전으로 2D 이미지 생성 분야에서 놀라운 성과가 있었습니다. 이러한 기술을 3D 영역으로 확장하려는 시도가 계속되어 왔지만, 고품질 3D 모델과 텍스처를 동시에 생성하는 것은 여전히 어려운 과제였습니다.
Hunyuan3D 2.0은 이러한 문제를 해결하기 위해 개발된 대규모 3D 합성 시스템입니다. 이 시스템은 두 가지 핵심 구성 요소로 이루어져 있습니다:
- Hunyuan3D-DiT: 3D 형상(모양) 생성에 특화된 모델
- Hunyuan3D-Paint: 생성된 형상에 고해상도 텍스처를 입히는 모델
이 논문에서는 Hunyuan3D 2.0이 어떻게 기존의 3D 생성 모델들을 뛰어넘어 더 정교하고 사실적인 3D 에셋을 생성할 수 있는지 설명합니다. 또한 형상 생성과 텍스처 합성을 분리함으로써 복잡한 문제를 효과적으로 해결하는 방법을 소개합니다.
2 Hunyuan3D 2.0 Architecture
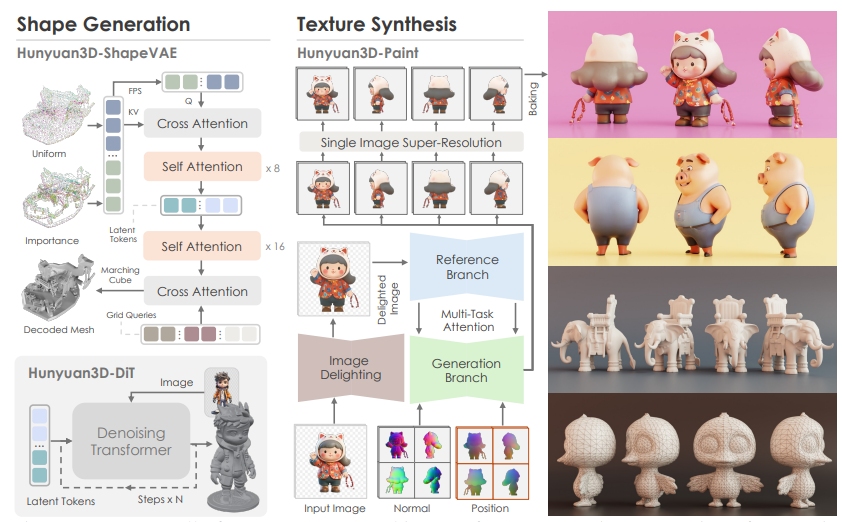
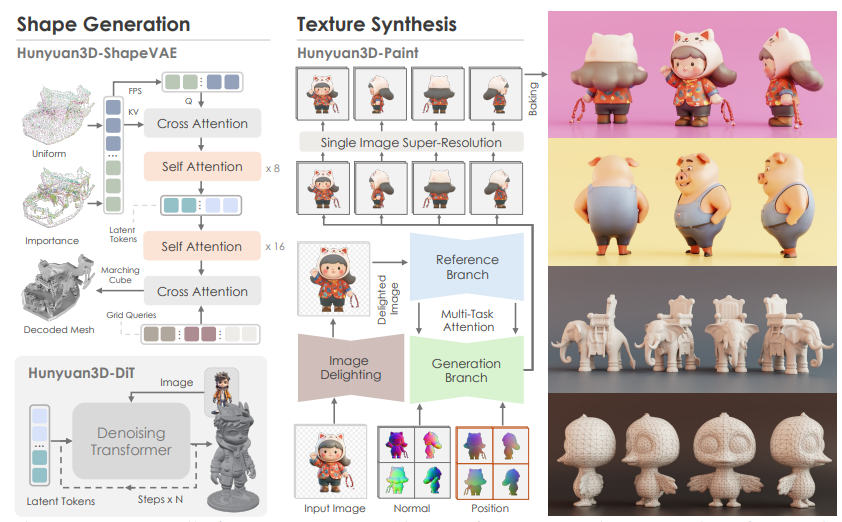
Hunyuan3D 2.0은 두 단계로 구성된 파이프라인을 채택하고 있습니다: 먼저 기본 3D 메시를 생성한 후, 이 메시에 텍스처 맵을 합성합니다. 이러한 접근 방식은 형상과 텍스처 생성의 복잡성을 분리하여 각각의 문제를 효과적으로 해결할 수 있게 합니다.
전체 파이프라인
Hunyuan3D 2.0의 전체 파이프라인은 다음과 같이 구성됩니다:
-
입력 조건 처리: 텍스트 설명이나 참조 이미지를 입력받아 처리
-
형상 생성 (Hunyuan3D-DiT): 잠재 확산 모델을 통해 3D 메시 생성
-
텍스처 합성 (Hunyuan3D-Paint): 생성된 메시에 고해상도 텍스처 매핑
-
최종 렌더링: 텍스처가 적용된 3D 에셋의 최종 렌더링
이 파이프라인의 가장 큰 장점은 형상 생성과 텍스처 합성을 분리함으로써 각 단계를 독립적으로 최적화할 수 있다는 점입니다. 또한 사용자가 직접 제작한 메시에도 AI 기반 텍스처를 적용할 수 있어 실용성이 높습니다
3. 형상 생성 모델: Hunyuan3D-DiT (Shape Generation Model)
Hunyuan3D-DiT는 텍스트나 이미지를 입력으로 받아 3D 형상을 생성하는 모델입니다. 이 모델은 확산 변환기(Diffusion Transformer)를 기반으로 하며, 정확하고 세밀한 3D 메시를 생성하는 것을 목표로 합니다.
3.1 Hunyuan3D-ShapeVAE
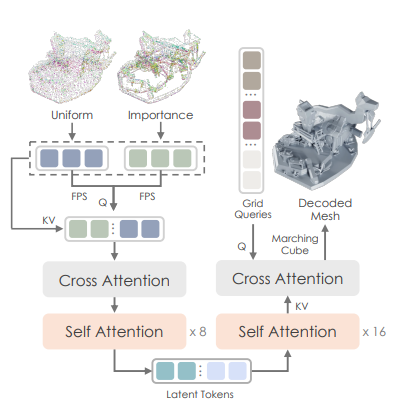
Hunyuan3D-DiT의 핵심 구성 요소 중 하나는 Hunyuan3D-ShapeVAE입니다. 이것은 변분 오토인코더(Variational Autoencoder, VAE)로, 3D 형상 데이터를 연속적인 잠재 토큰으로 압축하는 역할을 합니다.
VAE의 기본 원리는 다음과 같은 수식으로 표현됩니다:
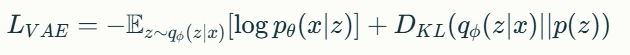
여기서:
는 인코더 네트워크로, 입력 x를 잠재 변수 z로 매핑
는 디코더 네트워크로, 잠재 변수 z를 원래 입력 공간 x로 복원
은 쿨백-라이블러 발산(Kullback-Leibler divergence)으로, 인코더의 출력 분포와 사전 분포(보통 정규 분포) 간의 차이를 측정
Hunyuan3D-ShapeVAE는 단순히 균일하게 샘플링된 포인트뿐만 아니라, 중요도 샘플링 전략을 사용하여 메시 구조의 고주파 세부 정보(모서리, 가장자리 등)를 효과적으로 포착합니다. 이를 통해 생성된 3D 모델의 세부 디테일이 더욱 정확하게 표현됩니다.
이중-단일 스트림 트랜스포머 아키텍처
Hunyuan3D-DiT는 이중-단일 스트림 트랜스포머 아키텍처를 채택하고 있습니다. 이 아키텍처에서는 형상 토큰과 조건 토큰(입력 이미지에서 파생)이 별도로 처리되지만, 어텐션 메커니즘을 통해 상호작용합니다.
트랜스포머의 셀프 어텐션(Self-Attention) 메커니즘은 다음과 같은 수식으로 표현됩니다:

이중-단일 스트림 아키텍처에서는 형상 토큰과 조건 토큰이 별도의 경로로 처리되지만, 크로스 어텐션(Cross-Attention)을 통해 서로 정보를 교환합니다.
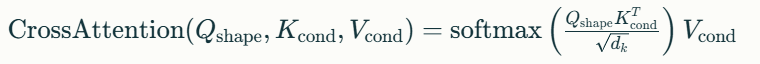
이러한 구조를 통해 모델은 입력 조건(텍스트나 이미지)의 정보를 효과적으로 반영한 3D 형상을 생성할 수 있습니다.
흐름 기반 확산 모델 (Flow-based Diffusion Model)
Hunyuan3D-DiT는 기존의 확산 모델에서 발전된 형태인 흐름 기반 확산 모델을 사용합니다. 이 모델은 데이터 분포와 노이즈 분포 사이의 변환을 연속적인 벡터 필드로 정의합니다.
흐름 매칭 목표는 다음과 같은 수식으로 표현됩니다:
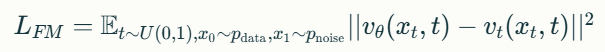
여기서:
는 학습하려는 벡터 필드
는 목표 벡터 필드로, 가우시안 분포에서 데이터 분포로의 이동을 정의
는 시간 t에서의 중간 상태로, (실제 데이터)와 (노이즈) 사이의 보간된 상태
이 접근법은 전통적인 확산 모델보다 더 빠른 샘플링과 더 높은 품질의 생성 결과를 얻을 수 있게 합니다.
4.텍스처 합성 모델: Hunyuan3D-Paint (Texture Synthesis Model)
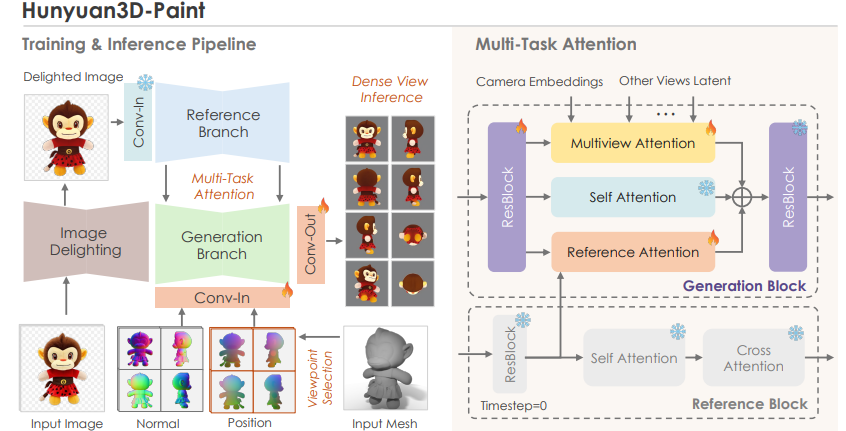
Hunyuan3D-Paint는 생성된 3D 메시에 고해상도 텍스처를 합성하는 모델입니다. 이 모델은 기하학적 정보와 확산 모델의 장점을 결합하여 사실적이고 세밀한 텍스처를 생성합니다.
다중 뷰 확산 기술 (Multi-view Diffusion Technique)
Hunyuan3D-Paint는 다중 뷰 확산 기술을 사용하여 3D 모델의 다양한 각도에서 일관된 텍스처를 생성합니다. 이 기술은 여러 각도에서 본 2D 이미지들이 3D 공간에서 일관성을 유지하도록 보장합니다.
다중 뷰 확산의 손실 함수는 다음과 같이 정의될 수 있습니다:
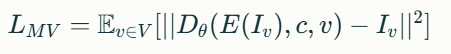
여기서:
는 다양한 뷰포인트의 집합
는 뷰포인트 v에서의 이미지
는 인코더 함수로, 이미지를 잠재 표현으로 변환
는 디코더 함수로, 잠재 표현, 조건 c, 뷰포인트 v를 입력으로 받아 이미지를 재구성
텍스처 일관성 유지
3D 모델의 텍스처는 모델의 모든 부분에서 일관성을 유지해야 합니다. Hunyuan3D-Paint는 UV 매핑과 확산 모델을 결합하여 이러한 일관성을 보장합니다.
UV 매핑은 3D 모델의 표면을 2D 평면에 펼쳐놓는 방식으로, 다음과 같은 수식으로 표현할 수 있습니다:
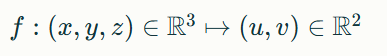
Hunyuan3D-Paint는 이 매핑을 활용하여 2D 텍스처 공간에서 확산 모델을 적용하고, 그 결과를 다시 3D 모델에 매핑합니다. 이 과정에서 텍스처의 일관성과 연속성을 유지하기 위한 추가적인 제약 조건이 적용됩니다.
Implementation Details
Hunyuan3D 2.0의 구현에 관한 세부 사항을 살펴보겠습니다.
모델 크기와 계산 요구사항
Hunyuan3D 2.0은 다음과 같은 모델 규모를 가지고 있습니다:
- Hunyuan3D-DiT: 약 2.6B 파라미터를 가진 대규모 모델
- Hunyuan3D-Paint: 약 1.3B 파라미터의 텍스처 합성 모델
경량화 버전(Hunyuan3D-2mini): 5GB VRAM만 필요한 가벼운 버전
표준 버전: 형상 생성에 6GB VRAM, 전체 과정(형상 + 텍스처)에 12GB VRAM 필요
이러한 다양한 크기의 모델 제공으로 사용자의 하드웨어 환경에 맞게 선택할 수 있는 유연성을 제공합니다.
범용 텍스트/이미지-텍스처 변환 기능
Hunyuan3D-Paint는 생성된 메시뿐만 아니라 사용자가 제공한 어떤 기하학적 모델에도 텍스트나 이미지 기반 텍스처 적용 가능
ControlNet와 IP-Adapter 같은 고급 텍스트-이미지 변환 모델을 활용
사용자 제공 텍스트/이미지 프롬프트를 기반으로 기하학적 형태에 맞는 입력 이미지 생성
형태와 일치하거나 불일치하는 이미지에 관계없이 임의의 텍스처 적용 가능
"re-skinning"이라 불리는 기능으로 동일한 3D 모델에 다양한 텍스처를 적용하는 응용 가능

5. Evaluations
1. 3D 형상 생성
평가 방법:
-
형상 복원(Shape Reconstruction)과 형상 생성(Shape Generation) 능력 비교
-
베이스라인: 3DShape2VecSet, Michelangelo, Direct3D, Craftsman 1.5, Trellis 등
-
지표: IoU(교집합/합집합), ULIP, Uni3D 기반 유사성 점수
결과:
-
Hunyuan3D-ShapeVAE는 중요도 샘플링 전략을 통해 모든 베이스라인 모델을 성능 면에서 능가
-
Hunyuan3D-DiT는 이미지 프롬프트에 가장 충실한 결과 생성 (인간 얼굴, 표면 세부사항, 로고 텍스트 등)
-
생성된 메시는 구멍이 없어 후속 텍스처 작업에 견고한 기반 제공
2. 텍스처 맵 합성
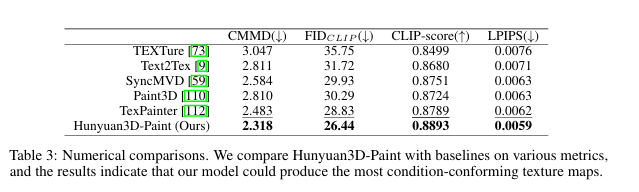
평가 방법:
-
텍스트 기반 텍스처 맵 합성 실험 진행
-
베이스라인: TEXTure, Text2Tex, SyncMVD, Paint3D, TexPainter
-
지표: FIDCLIP, CMMD, CLIP-score, LPIPS
결과:
-
Hunyuan3D-Paint는 최고의 생성 품질과 의미적 정확성 달성
-
생성된 텍스처 맵은 이음새 없고(seamless) 조명 불변적(lighting-invariant)
-
같은 메시에 다양한 프롬프트로 각기 다른 고품질 텍스처 적용 가능 (re-skinning 응용)
3. 텍스처 적용된 3D 에셋 생성
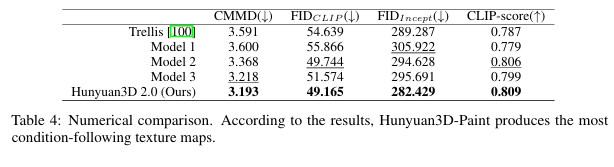
평가 방법:
-
종단간(end-to-end) 생성 능력 평가
-
베이스라인: Trellis(오픈소스), Model 1/2/3(비공개)
-
지표: FIDCLIP, CLIP-score, CMMD, LPIPS
결과:
-
Hunyuan3D 2.0은 모든 측정 지표에서 베이스라인 모델들을 능가
-
이미지 프롬프트의 텍스트 요소도 정확하게 형상 표면의 돌기와 텍스처로 구현
-
복잡한 동작이나 장면도 고해상도, 고품질로 생성 가능
종합적으로, Hunyuan3D 2.0은 3D 형상 생성, 텍스처 맵 합성, 그리고 이 둘을 결합한 완전한 3D 에셋 생성 모든 영역에서 최첨단 성능을 보여주었습니다. 특히 텍스처의 세부 표현과 프롬프트 조건에 대한 충실도가 우수한 것으로 입증되었습니다.
6. Conclusion
Hunyuan3D 2.0은 고해상도 텍스처 3D 에셋 생성을 위한 혁신적인 시스템으로, 확산 모델의 강점을 3D 영역으로 효과적으로 확장했습니다. 이 시스템은 형상 생성과 텍스처 합성을 분리함으로써 각 문제를 더 효율적으로 해결하고, 높은 품질의 3D 에셋을 생성할 수 있게 해줍니다.
글을 마무리 하며,
Hunyuan3D 2.0의 형상 생성과 텍스처 합성을 분리한 파이프라인 구조가 효율적이면서도 인상적이었습니다.
또한 DiffFlow(흐름 기반 확산 모델)와 중요도 샘플링 전략을 통한 모델성능 향상 과정이 놀라웠습니다. 더군다나 오픈소스로 공개되어 많은 사람들에게 공개한 점이 대단했고, 이를 활용한 다양한 연구를 진행보면 좋을 것 같습니다.
