OpenVLA: An Open-Source Vision-Language-Action Model 논문 리뷰
paper: https://arxiv.org/pdf/2406.09246
github: https://github.com/openvla/openvla
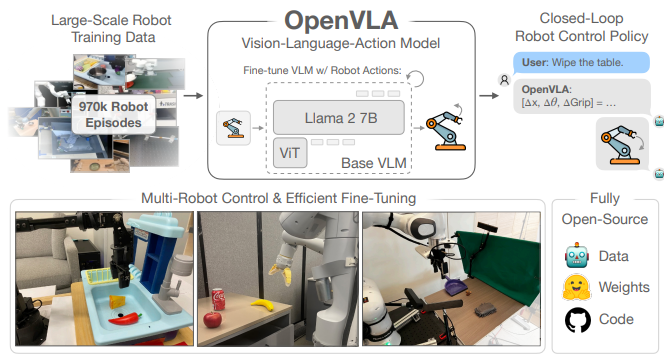
최근 로봇공학 분야에서는 다양한 비전, 언어, 그리고 액션을 통합한 AI 모델의 발전이 두드러지고 있습니다. 특히 로봇이 시각 정보와 자연어 명령을 이해하고 적절한 물리적 행동을 취할 수 있게 하는 비전-언어-액션(Vision-Language-Action, VLA) 모델은 로봇의 자율성과 유연성을 크게 향상시키는 핵심 기술로 주목받고 있습니다.
오늘 소개할 논문 "OpenVLA: An Open-Source Vision-Language-Action Model"은 Stanford, UC Berkeley, Toyota Research Institute 등 여러 연구 기관이 공동으로 개발한 오픈소스 VLA 모델을 제시합니다. 이 모델은 인터넷 규모의 데이터로 사전 훈련된 비전-언어 모델을 기반으로, 970,000개의 실제 로봇 데모 데이터셋을 활용해 로봇 제어 능력을 학습합니다.
OpenVLA는 7B(70억) 파라미터 규모의 모델로, 기존의 55B 파라미터를 가진 폐쇄형 모델인 RT-2-X보다 파라미터 수는 7배 적지만, 29개 작업에서 평균 16.5%의 절대적 성공률 향상을 달성했습니다. 또한 새로운 로봇 환경에 효율적으로 적응할 수 있는 파인튜닝 방법과 소비자용 GPU에서도 운용 가능한 최적화 기법을 제공합니다.
1. Introduction
로봇 조작(manipulation) 분야에서 기존 학습 정책들의 가장 큰 약점은 학습 데이터를 벗어난 상황에서의 일반화 능력 부족입니다. 예를 들어, 현재의 로봇 정책들은 물체 위치나 조명 변화와 같은 초기 조건 변화에는 어느 정도 대응할 수 있지만, 주변 방해 물체(distractors)나 이전에 보지 못한 새로운 물체에 대해서는 취약하며, 학습하지 않은 새로운 지시문에 대응하기도 어렵습니다.
반면, 컴퓨터 비전과 자연어 처리 분야에서는 CLIP, SigLIP, Llama 2와 같은 파운데이션 모델들이 인터넷 규모의 데이터로 사전 학습되어 뛰어난 일반화 능력을 보여주고 있습니다. 이러한 파운데이션 모델들의 강점을 로봇 제어에 접목시키려는 시도가, 바로 비전-언어-액션(Vision-Language-Action, VLA) 모델의 핵심 아이디어입니다.
최근 RT-2와 같은 VLA 모델들은 비주얼 언어 모델(Vision-Language Model, VLM)을 로봇 제어 액션 생성에 맞게 파인튜닝하여, 새로운 물체와 작업에 대한 일반화 능력을 보여주며 로봇 정책의 새로운 기준을 제시했습니다. 그러나 이러한 모델들이 널리 사용되기 어려운 이유는 두 가지입니다:
-
기존 모델들은 폐쇄적(closed)이며, 모델 아키텍처, 학습 절차, 데이터 구성에 대한 투명성이 부족합니다.
-
기존 연구들은 VLA 모델을 새로운 로봇, 환경, 작업에 배포하고 적응시키는 모범 사례를 제공하지 않습니다. 특히 일반 소비자용 하드웨어(예: 소비자급 GPU)에서의 활용 방법을 다루지 않습니다.
이러한 한계를 극복하기 위해 저자들은 OpenVLA를 소개합니다. OpenVLA는 7B 파라미터 규모의 오픈소스 VLA로, 다양한 로봇 조작 정책을 위한 새로운 최첨단 성능을 제시합니다. 이 모델은 사전 훈련된 비주얼 언어 모델 백본을 기반으로, Open-X Embodiment 데이터셋의 970,000개 로봇 궤적 데이터로 미세 조정됩니다. 이 데이터셋은 다양한 로봇 형태, 작업, 장면을 포함하고 있습니다.
풍부한 데이터와 새로운 모델 구성요소의 결합으로, OpenVLA는 이전 최고 수준의 VLA인 55B 파라미터의 RT-2-X 모델보다 WidowX와 Google Robot 환경에서의 29개 평가 작업에서 16.5% 더 높은 성공률을 달성했습니다. 또한 저자들은 VLA 모델의 효율적인 파인튜닝 전략을 연구했으며, 파인튜닝된 OpenVLA 정책이 사전 훈련된 Octo와 같은 정책보다 우수한 성능을 보이고, Diffusion Policy와 같은 처음부터 학습한 모방 학습 방법보다 20.4% 더 나은 성능을 보임을 입증했습니다.
이 연구의 주요 기여점은 다음과 같습니다:
-
7B 파라미터 규모의 오픈소스 VLA 모델을 제공하여 로봇 조작 정책의 새로운 최고 수준을 설정
-
VLA 모델의 효율적인 파인튜닝 방법 연구 및 제시
-
저순위 적응(LoRA)과 모델 양자화를 통한 소비자용 GPU에서의 효율적인 훈련 및 추론 방법 제공
2. Related Work
Visually-Conditioned Language Models (비주얼 언어 모델)
비주얼 언어 모델(VLM)은 인터넷 규모의 데이터로 학습되어 입력 이미지와 언어 프롬프트에서 자연어를 생성하는 모델입니다. 이 모델들은 시각적 질문 응답부터 객체 지역화까지 다양한 응용 분야에 적용되고 있습니다.
최근 VLM의 주요 발전은 사전 훈련된 비전 인코더와 사전 훈련된 언어 모델의 특성을 연결하는 모델 아키텍처에 있습니다. 초기 연구에서는 비전과 언어 특성 간의 교차 주의(cross-attending) 메커니즘에 다양한 아키텍처를 탐구했지만, 최근 오픈소스 VLM은 "패치-토큰(patch-as-token)" 접근 방식으로 수렴하고 있습니다. 이 방식에서는 사전 훈련된 비주얼 트랜스포머의 패치 특성을 토큰으로 처리하고, 이를 언어 모델의 입력 공간으로 투영합니다.
OpenVLA는 Karamcheti 등의 VLM을 사전 훈련된 백본으로 사용합니다. 이 모델은 다중 해상도 시각적 특성에서 훈련되어, DINOv2의 저수준 공간 정보와 SigLIP의 고수준 의미론을 결합하여 시각적 일반화를 돕습니다.
Generalist Robot Policies (일반적인 로봇 정책)
최근 로봇공학 분야에서는 다양한 로봇 데이터셋에서 다중 작업 "일반적" 로봇 정책을 훈련하는 추세가 있습니다. 특히 Octo는 여러 로봇을 즉시 제어할 수 있고 새로운 로봇 설정에 유연하게 파인튜닝할 수 있는 일반적인 정책을 훈련합니다.
이러한 접근 방식과 OpenVLA의 주요 차이점은 모델 아키텍처에 있습니다. Octo와 같은 이전 연구는 일반적으로 사전 훈련된 언어 임베딩이나 비주얼 인코더와 같은 구성 요소들을 조합하고, 정책 훈련 과정에서 이들을 "연결(stitch)"하는 것을 학습합니다. 반면 OpenVLA는 더 엔드투엔드(end-to-end) 접근 방식을 채택하여, VLM을 로봇 액션을 언어 모델 어휘의 토큰으로 취급하여 직접 파인튜닝합니다.
Vision-Language-Action Models (비전-언어-액션 모델)
여러 연구에서 로봇공학을 위한 VLM의 활용을 탐구해 왔습니다. 시각적 상태 표현, 객체 감지, 고수준 계획, 그리고 피드백 신호 제공을 위해 VLM을 사용했습니다. 일부 연구는 VLM을 엔드투엔드 시각-운동 조작 정책에 직접 통합했지만, 정책 아키텍처에 상당한 구조가 필요하거나 보정된 카메라가 필요하여 적용 범위가 제한적이었습니다.
최근 연구들은 OpenVLA와 유사하게 사전 훈련된 VLM을 로봇 액션 예측에 직접 파인튜닝하는 방법을 탐구했습니다. 이러한 모델들은 로봇 제어 액션을 VLM 백본에 직접 융합하기 때문에 비전-언어-액션(VLA) 모델이라고 불립니다. 이 접근법은 세 가지 주요 이점이 있습니다:
-
대규모 인터넷 비전-언어 데이터셋에서 사전 훈련된 비전 및 언어 구성 요소의 정렬을 수행합니다.
-
로봇 제어를 위해 특별히 제작되지 않은 일반적인 아키텍처를 사용하여 최신 VLM 훈련의 확장 가능한 인프라를 활용하고 코드 수정을 최소화하면서 수십억 파라미터 정책 훈련으로 확장할 수 있습니다.
-
VLM의 급속한 개선에서 로봇공학이 직접적으로 혜택을 받을 수 있는 경로를 제공합니다.
기존 VLA 연구는 단일 로봇이나 시뮬레이션 환경에서의 훈련과 평가에 중점을 두어 일반성이 부족하거나, 새로운 로봇 환경에 효율적인 파인튜닝을 지원하지 않는 폐쇄형 모델이었습니다.
특히 RT-2-X는 55B 파라미터 VLA 정책을 Open X-Embodiment 데이터셋에서 훈련하여 최첨단 일반적 조작 정책 성능을 보여주었습니다. 그러나 OpenVLA는 RT-2-X와 여러 중요한 측면에서 차이가 있습니다:
-
강력한 오픈 VLM 백본과 더 풍부한 로봇 사전 훈련 데이터셋을 결합하여, OpenVLA는 파라미터 수가 10배 적으면서도 실험에서 RT-2-X보다 더 나은 성능을 보입니다.
-
OpenVLA는 새로운 대상 환경에 대한 모델 파인튜닝을 철저히 조사하는 반면, RT-2-X는 파인튜닝 설정을 연구하지 않았습니다.
-
OpenVLA는 VLA를 위한 현대적 파라미터 효율적 파인튜닝 및 양자화 접근법의 효과를 처음으로 입증했습니다.
-
OpenVLA는 VLA 훈련, 데이터 믹스, 목표, 추론에 대한 향후 연구를 지원하는 최초의 오픈소스 일반적 VLA입니다.
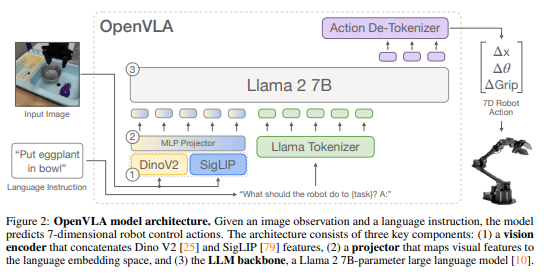
3. The OpenVLA Model
OpenVLA 모델은 Open X-Embodiment 데이터셋에서 970,000개의 로봇 데모로 훈련된 7B 파라미터 비전-언어-액션 모델(VLA)입니다. VLA 모델 개발에 있어 최적의 모델 백본, 데이터셋, 하이퍼파라미터 선택에 대한 다양한 미해결 질문이 있습니다. 이 섹션에서는 OpenVLA 개발 접근 방식과 핵심 교훈을 상세히 설명합니다.
3.1 Preliminaries: Vision-Language Models
최근 VLM의 아키텍처는 다음 세 가지 주요 부분으로 구성됩니다(그림 2 참조):
-
비주얼 인코더(Visual Encoder): 이미지 입력을 "이미지 패치 임베딩"으로 매핑합니다.
-
프로젝터(Projector): 비주얼 인코더의 출력 임베딩을 가져와 언어 모델의 입력 공간으로 매핑합니다.
-
대규모 언어 모델(LLM) 백본: 실제 텍스트 생성을 담당합니다.
VLM 훈련 중에는 다양한 인터넷 소스에서 수집된 페어링 또는 인터리브된 비전 및 언어 데이터에 대해 다음 텍스트 토큰 예측 목표로 모델이 엔드투엔드로 훈련됩니다.
OpenVLA는 Prismatic-7B VLM을 기반으로 합니다. Prismatic은 위에서 설명한 표준 아키텍처를 따르며, 600M 파라미터 비주얼 인코더, 작은 2계층 MLP 프로젝터, 7B 파라미터 Llama 2 언어 모델 백본으로 구성됩니다. 주목할 만한 점은 Prismatic이 사전 훈련된 SigLIP와 DinoV2 모델로 구성된 2부분 비주얼 인코더를 사용한다는 것입니다. 입력 이미지 패치는 두 인코더를 통해 별도로 전달되고 결과 특성 벡터는 채널별로 연결됩니다. CLIP이나 SigLIP 전용 인코더와 같은 더 일반적으로 사용되는 비전 인코더와 달리, DinoV2 특성의 추가는 향상된 공간 추론에 도움이 되는 것으로 나타났으며, 이는 로봇 제어에 특히 유용할 수 있습니다.
SigLIP, DinoV2 및 Llama 2는 각각 인터넷에서 찾은 수조 개의 이미지-텍스트, 이미지 전용, 텍스트 전용 데이터로 구성된 학습 데이터에 대한 세부 정보를 공개하지 않습니다. Prismatic VLM은 LLaVA 1.5 데이터 믹스를 사용하여 이러한 구성 요소 위에서 파인튜닝되며, 이는 오픈소스 데이터셋에서 약 1백만 개의 이미지-텍스트 및 텍스트 전용 데이터 샘플을 포함합니다.
3.2 OpenVLA Training Procedure
OpenVLA를 훈련하기 위해, 저자들은 사전 훈련된 Prismatic-7B VLM 백본을 로봇 액션 예측에 맞게 파인튜닝합니다(그림 2 참조). 액션 예측 문제는 "비전-언어" 작업으로 공식화되며, 입력 관측 이미지와 자연어 작업 지시문이 예측된 로봇 액션 문자열에 매핑됩니다.
VLM의 언어 모델 백본이 로봇 액션을 예측할 수 있도록, 연속적인 로봇 액션을 언어 모델의 토크나이저가 사용하는 이산 토큰으로 매핑하여 LLM의 출력 공간에서 액션을 표현합니다. Brohan 등의 방법을 따라, 로봇 액션의 각 차원을 별도로 256개의 빈으로 이산화합니다. 각 액션 차원에 대해, 빈 너비는 훈련 데이터의 액션에서 1번째와 99번째 분위수 사이의 구간을 균등하게 나누도록 설정합니다. 최소-최대 경계를 사용한 Brohan 등과 달리 분위수를 사용함으로써 이산화 구간을 크게 확장하고 액션 이산화의 효과적인 세분성을 감소시킬 수 있는 데이터의 이상치 액션을 무시할 수 있습니다.
이 이산화를 사용하여, N차원 로봇 액션에 대해 N개의 이산 정수(0...255 범위)를 얻습니다. 안타깝게도 OpenVLA의 언어 백본인 Llama 토크나이저는 파인튜닝 중에 새로 도입된 토큰을 위해 단 100개의 "특수 토큰"만 예약하고 있어, 액션 이산화의 256개 토큰에는 충분하지 않습니다. 대신, 저자들은 다시 단순성을 선택하고 Brohan 등의 접근 방식을 따라 Llama 토크나이저 어휘의 가장 적게 사용되는 256개 토큰(마지막 256개 토큰에 해당)을 액션 토큰으로 덮어씁니다.
액션이 토큰 시퀀스로 처리되면, OpenVLA는 예측된 액션 토큰에 대해서만 교차 엔트로피 손실을 평가하는 표준 다음 토큰 예측 목표로 훈련됩니다. 저자들은 3.4절에서 이 훈련 절차를 구현하기 위한 주요 설계 결정에 대해 논의합니다.
3.3 Training Data
OpenVLA 훈련 데이터셋을 구성하는 목표는 다양한 로봇 형태, 장면, 작업을 포착하는 것입니다. 이를 통해 최종 모델이 여러 로봇을 즉시 제어하고 새로운 로봇 설정에 효율적으로 파인튜닝할 수 있게 됩니다. 저자들은 훈련 데이터셋을 큐레이션하기 위한 기반으로 Open X-Embodiment 데이터셋1을 활용합니다. 현재 전체 OpenX 데이터셋은 70개 이상의 개별 로봇 데이터셋과 2백만 개 이상의 로봇 궤적으로 구성되어 있으며, 대규모 커뮤니티 노력을 통해 일관되고 사용하기 쉬운 데이터 형식으로 통합되었습니다.
이 데이터로 훈련하는 것을 실용적으로 만들기 위해, 저자들은 원시 데이터셋에 여러 단계의 데이터 큐레이션을 적용합니다. 이 큐레이션의 목표는 (1) 모든 훈련 데이터셋에서 일관된 입력 및 출력 공간을 보장하고, (2) 최종 훈련 믹스에서 형태, 작업, 장면의 균형 잡힌 믹스를 보장하는 것입니다. (1)을 해결하기 위해,를 따라 최소 하나의 3인칭 카메라가 있고 단일 팔 엔드 이펙터 제어를 사용하는 조작 데이터셋만 포함하도록 훈련 데이터셋을 제한합니다. (2)를 위해, 첫 번째 필터링 라운드를 통과한 모든 데이터셋에 대해 Octo의 데이터 믹스 가중치를 활용합니다. Octo는 다양성이 적은 데이터셋의 가중치를 낮추거나 제거하고 더 큰 작업 및 장면 다양성을 가진 데이터셋의 가중치를 높입니다.
저자들은 또한 DROID 데이터셋을 포함하여 Octo 출시 이후 Open X 데이터셋에 추가된 몇 가지 추가 데이터셋을 10%의 보수적인 믹스 가중치로 훈련 믹스에 통합하는 실험을 했습니다. 실제로, DROID에 대한 액션 토큰 정확도는 훈련 전반에 걸쳐 낮게 유지되어 향후 그 다양성을 맞추기 위해 더 큰 믹스 가중치나 모델이 필요할 수 있음을 시사했습니다. 최종 모델의 품질을 위태롭게 하지 않기 위해, 저자들은 훈련의 마지막 3분의 1을 위해 데이터 믹스에서 DROID를 제거했습니다.
3.4 OpenVLA Design Decisions
OpenVLA 모델을 개발할 때, 저자들은 최종 모델 훈련 실행을 시작하기 전에 소규모 실험에서 다양한 설계 결정을 탐색했습니다. 구체적으로, 반복 속도를 높이고 계산 비용을 줄이기 위해 전체 OpenX 믹스에서 훈련하는 대신 BridgeData V2에서 OpenVLA 모델을 훈련하고 평가했습니다. 다음은 이러한 탐색에서 얻은 주요 교훈입니다:
VLM 백본: 초기에 여러 VLM 백본으로 실험했습니다. Prismatic 외에도 IDEFICS-1과 LLaVA를 로봇 액션 예측을 위해 파인튜닝하는 것을 테스트했습니다. LLaVA와 IDEFICS-1은 장면에 하나의 객체만 있는 작업에서는 비슷한 성능을 보였지만, LLaVA는 여러 객체가 있는 장면에서 언어 지시에 따라 올바른 객체를 조작해야 하는 작업에서 더 강력한 언어 접지를 보여주었습니다. 구체적으로, LLaVA는 BridgeData V2 싱크 환경에서 다섯 가지 언어 접지 작업에서 평균적으로 IDEFICS-1보다 35% 더 높은 절대 성공률을 달성했습니다. 파인튜닝된 Prismatic VLM 정책은 추가적인 개선을 달성하여, 단순한 단일 객체 작업과 다중 객체 언어 접지 작업 모두에서 약 10%의 절대 성공률로 LLaVA 정책을 능가했습니다. 저자들은 이 성능 차이를 융합된 SigLIP-DinoV2 백본(3.1절 참조)에 의해 제공되는 향상된 공간 추론 능력 때문이라고 생각합니다. 성능 향상 외에도 Prismatic은 모듈식이고 사용하기 쉬운 코드베이스를 제공하므로 최종적으로 OpenVLA 모델의 백본으로 선택했습니다.
Image Resolution (이미지 해상도): 입력 이미지의 해상도는 VLA 훈련의 계산 요구 사항에 상당한 영향을 미칩니다. 고해상도 이미지는 더 많은 이미지 패치 토큰을 생성하여 훈련 계산을 2차적으로 증가시키는 더 긴 컨텍스트 길이를 초래합니다. 224×224px와 384×384px 입력을 가진 VLA를 비교했지만, 평가에서 성능 차이를 발견하지 못했고, 후자는 훈련에 3배 더 오래 걸립니다. 따라서 최종 OpenVLA 모델에는 224×224px 해상도를 선택했습니다. 많은 VLM 벤치마크에서는 해상도 증가가 성능을 향상시키지만, VLA에서는 아직 이러한 추세를 관찰하지 못했습니다.
Fine-Tuning Vision Encoder (비전 인코더 파인튜닝): VLM에 관한 이전 연구에서는 VLM 훈련 중에 비전 인코더를 동결하는 것이 일반적으로 더 높은 성능으로 이어진다는 것을 발견했습니다. 직관적으로, 동결된 비전 인코더는 인터넷 규모 사전 훈련에서 학습한 강력한 특성을 더 잘 보존할 수 있습니다. 그러나 저자들은 VLA 훈련 중에 비전 인코더를 파인튜닝하는 것이 좋은 VLA 성능에 중요하다는 것을 발견했습니다. 저자들은 사전 훈련된 비전 백본이 정밀한 로봇 제어를 가능하게 하기 위해 장면의 중요한 부분에 대한 충분한 세밀한 공간 세부 정보를 포착하지 못할 수 있다고 가정합니다.
Training Epochs (훈련 에포크): 일반적인 LLM 또는 VLM 훈련 실행은 훈련 데이터셋을 최대 한두 번 정도만 반복합니다. 반면, 저자들은 VLA 훈련을 위해 훈련 데이터셋을 훨씬 더 많이 반복하는 것이 중요하다는 것을 발견했으며, 훈련 액션 토큰 정확도가 95%를 초과할 때까지 실제 로봇 성능이 지속적으로 증가했습니다. 최종 훈련 실행은 훈련 데이터셋을 27번 반복합니다.
Learning Rate (학습률): VLA 훈련을 위해 여러 수량 크기에 걸쳐 학습률을 탐색했으며, 2e-5의 고정 학습률(VLM 사전 훈련 중에 사용된 것과 동일한 학습률)을 사용하여 최상의 결과를 달성했습니다. 학습률 워밍업이 이점을 제공하지 않는다는 것을 발견했습니다.
3.5 Infrastructure for Training and Inference
최종 OpenVLA 모델은 14일 동안 64개의 A100 GPU 클러스터에서 훈련되었으며, 총 21,500 A100-시간으로 배치 크기는 2048입니다. 추론 중에 OpenVLA는 bfloat16 정밀도(양자화 없이)로 로드될 때 15 GB의 GPU 메모리를 필요로 하며, 하나의 NVIDIA RTX 4090 GPU에서 약 6 Hz로 실행됩니다(컴파일, 추측적 디코딩 또는 기타 추론 속도 향상 트릭 없이). 5.4절에서 보여지듯이, 실제 로봇 작업에서 성능을 손상시키지 않고 양자화를 통해 추론 중 OpenVLA의 메모리 풋프린트를 더 줄일 수 있습니다. 저자들은 그림 6에서 다양한 소비자 및 서버급 GPU에서의 추론 속도를 보고합니다.
편의를 위해, 저자들은 로봇에 실시간 원격 스트리밍 액션 예측을 가능하게 하는 원격 VLA 추론 서버를 구현했습니다. 이를 통해 로봇을 제어하기 위해 강력한 로컬 컴퓨팅 장치에 액세스할 필요성이 없어졌습니다. 이 원격 추론 솔루션은 오픈소스 코드 릴리스(4절)의 일부로 제공됩니다.
4. The OpenVLA Codebase
모델과 함께 저자들은 VLA 모델 훈련을 위한 모듈식 PyTorch 코드베이스인 OpenVLA 코드베이스를 공개합니다(https://openvla.github.io 참조). 이 코드베이스는 개별 GPU에서 VLA 파인튜닝부터 다중 노드 GPU 클러스터에서 수십억 파라미터 VLA 훈련까지 확장되며, 자동 혼합 정밀도(AMP, PyTorch), FlashAttention, 완전 분할 데이터 병렬성(FSDP, Zhao 등)과 같은 대규모 트랜스포머 모델 훈련을 위한 최신 기술을 지원합니다.
OpenVLA 코드베이스는 Open X 데이터셋에서 훈련하기 위한 완전한 지원을 제공하고, HuggingFace의 AutoModel 클래스와 통합되며, LoRA 파인튜닝과 양자화 모델 추론을 지원합니다.
5. Experiments
실험 평가의 목표는 OpenVLA가 즉시 사용 가능한 다중 로봇 제어 정책으로서 강력하게 기능할 수 있는지, 그리고 새로운 로봇 작업에 파인튜닝하기 위한 좋은 초기화가 될 수 있는지 테스트하는 것입니다. 구체적으로, 다음 질문에 답하고자 합니다:
-
여러 로봇과 다양한 유형의 일반화를 평가할 때 OpenVLA는 이전의 일반적 로봇 정책과 어떻게 비교됩니까?
-
OpenVLA를 새로운 로봇 설정과 작업에 효과적으로 파인튜닝할 수 있으며, 최신 데이터 효율적 모방 학습 접근법과 비교하면 어떻습니까?
-
파라미터 효율적 파인튜닝과 양자화를 사용하여 OpenVLA 모델의 훈련 및 추론에 대한 계산 요구 사항을 줄이고 더 접근 가능하게 만들 수 있습니까? 성능-계산 트레이드오프는 무엇입니까?
5.1 Direct Evaluations on Multiple Robot Platforms (다중 로봇 플랫폼에서의 직접 평가)
로봇 설정 및 작업:
-
BridgeData V2 평가를 위한 WidowX 로봇과 Google 로봇(모바일 조작 로봇)에서 평가
-
다양한 일반화 능력 테스트: 시각적, 동작, 물리적, 의미론적 일반화 및 언어 조건부 능력
-
BridgeData V2에서 170회 롤아웃(17개 작업, 각 10회), Google 로봇에서 60회 롤아웃(12개 작업, 각 5회)
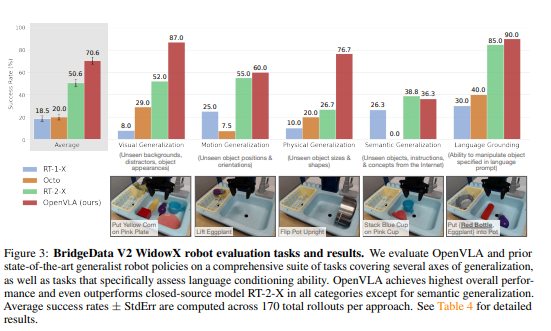
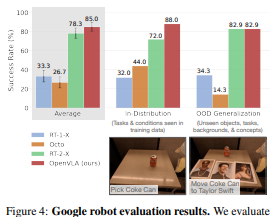
비교 결과:
-
RT-1-X(35M 파라미터)와 Octo(93M 파라미터)는 방해 물체가 있는 상황 등에서 어려움 겪음
-
OpenVLA(7B)는 55B 파라미터의 RT-2-X보다 10배 작은 모델 크기에도 불구하고 BridgeData V2에서 우수한 성능, Google 로봇에서는 비슷한 성능 달성
-
RT-2-X는 의미론적 일반화 작업에서 더 높은 성능을 보였으나, OpenVLA는 다른 모든 작업 카테고리에서 비슷하거나 더 나은 성능 보임
-
OpenVLA의 성능 우위 요인: 더 큰 훈련 데이터셋(970K vs. 350K), 데이터 전처리 개선, 융합 비전 인코더 사용
5.2 Data-Efficient Adaptation to New Robot Setups (새로운 로봇 설정에 대한 데이터 효율적 적응)
로봇 설정 및 파인튜닝 방법:
-
10-150개 데모를 사용한 작은 데이터셋으로 모델 파인튜닝
-
Franka-Tabletop(5Hz 제어)과 Franka-DROID(15Hz 제어) 로봇 환경에서 테스트
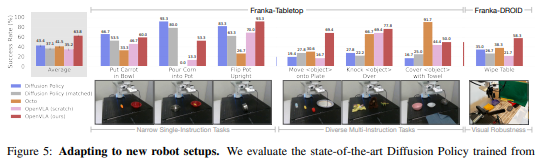
비교 결과:
-
Diffusion Policy는 좁은 단일 지시 작업("당근을 그릇에 넣기" 등)에서 강점 보임
-
OpenVLA와 Octo는 언어 접지가 중요한 다중 물체/지시 작업에서 우수한 성능
-
OpenVLA가 모든 작업 유형에서 최소 50% 성공률을 달성하여 가장 높은 평균 성능 기록
-
OpenVLA(scratch)의 낮은 성능은 OpenX 사전 훈련의 중요성을 입증
5.3 Parameter-Efficient Fine-Tuning (파라미터 효율적 파인튜닝)
파인튜닝 접근법 비교:
-
전체 파인튜닝: 모든 가중치 업데이트
-
마지막 계층만: 트랜스포머 백본의 마지막 계층과 토큰 임베딩 매트릭스만 파인튜닝
-
동결된 비전: 비전 인코더를 동결하고 다른 모든 가중치 파인튜닝
-
샌드위치 파인튜닝: 비전 인코더, 토큰 임베딩 매트릭스, 마지막 계층만 파인튜닝
-
LoRA(Low-Rank Adaptation): 저순위 행렬 분해를 통한 효율적 파인튜닝
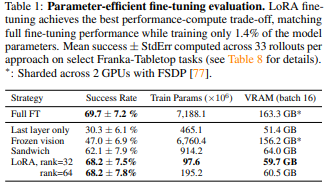
결과:
-
마지막 계층만 파인튜닝하거나 비전 인코더를 동결하면 성능 저하
-
LoRA가 성능과 메모리 소비 사이 최상의 트레이드오프 달성
-
LoRA는 전체 파인튜닝과 비슷한 성능(68.2% vs. 69.7%)을 보이면서 파라미터의 1.4%만 파인튜닝
-
LoRA 사용 시 단일 A100 GPU에서 10-15시간 내에 새 작업 적응 가능(전체 파인튜닝 대비 8배 계산 감소)
5.4 Memory-Efficient Inference via Quantization (양자화를 통한 메모리 효율적 추론)
양자화 방법:
-
bfloat16(기본), 8비트, 4비트 정밀도로 OpenVLA 모델 서빙 비교
-
8개 대표적 BridgeData V2 작업에서 평가
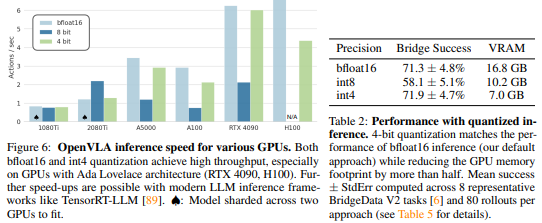
결과:
-
8비트 양자화: 추론 속도 저하(A5000 GPU에서 1.2Hz)로 인해 성능 감소(58.1%)
-
4비트 양자화: GPU 메모리 사용량을 절반 이상 줄이면서도 bfloat16과 유사한 성능 유지(71.9% vs. 71.3%)
-
4비트 양자화 모델은 A5000에서 3Hz로 실행 가능해 훈련 데이터 시스템 역학과 더 유사
6. Discussion and Limitations
OpenVLA 모델의 현재 한계점과 향후 연구 방향:
1. 다중 이미지 관측 지원 부족:
-
현재는 단일 이미지 관측만 지원
-
실제 로봇 환경은 다양한 센서 입력이 있는 이질적 시스템
-
다중 이미지 및 고유 입력과 관측 이력 지원으로 확장 필요
2. 추론 처리량 한계:
-
ALOHA와 같은 고주파수(50Hz) 제어 환경에서 활용하기 위한 처리량 개선 필요
-
액션 청킹이나 추측적 디코딩과 같은 최적화 기술이 해결책이 될 수 있음
3. 성능 향상 여지:
-
기존 일반적 정책보다 우수한 성능을 보이지만 아직 90% 이상의 높은 신뢰성은 부족
-
더 세밀한 조작 작업에서 성능 향상 필요
4. 추가 연구 질문:
-
계산 제한으로 인해 VLA 설계 관련 많은 질문이 충분히 탐구되지 않음
-
기본 VLM 크기의 영향, 인터넷 규모 데이터와의 공동 훈련 효과, 최적 시각적 특성 등
-
OpenVLA의 공개로 커뮤니티가 이러한 질문들을 공동으로 탐구할 수 있게 됨
7. 마지막으로
OpenVLA는 로봇 조작을 위한 강력한 오픈소스 비전-언어-액션 모델을 제공하며, 파라미터 효율적 파인튜닝과 양자화를 통한 계산 효율성으로 다양한 환경에서의 접근성과 활용성을 크게 높였습니다.
