Distilling the Knowledge in a Neural Network 논문 리뷰
Introduction
논문 개요
신경망 모델의 규모가 기하급수적으로 증가하면서 발생하는 계산 비용과 배포 문제를 해결하기 위해, 2015년 Geoffrey Hinton 연구팀은 혁신적인 모델 경량화 기법인 Knowledge Distillation(지식 증류)을 제안했습니다.
이 기법은 화학적 증류 과정에서 영감을 얻어, 대형 모델(Teacher Network)이 함축한 지식의 본질을 소형 모델(Student Network)에 전달하는 메커니즘을 수학적으로 정립하였습니다.
논문의 핵심 아이디어
이 논문의 핵심 아이디어는 간단합니다. 크고 복잡한 신경망 모델(Teacher 모델)의 지식을 작고 가벼운 신경망 모델(Student 모델)로 효과적으로 전달하는 방법을 제안했습니다. 이를 통해 작은 모델이 큰 모델의 성능에 근접하면서도 계산 비용과 메모리 사용량을 크게 줄일 수 있다는 것이 핵심입니다.
연구 배경 및 필요성
인공지능 모델, 특히 딥러닝 모델은 점점 더 크고 복잡해지고 있습니다. 이러한 대형 모델들은 뛰어난 성능을 보이지만, 실제 환경에 배포하기에는 많은 계산 자원과 메모리를 필요로 합니다. 특히 모바일 기기나 임베디드 시스템과 같은 제한된 환경에서는 이러한 대형 모델을 사용하기 어렵습니다.
또한, 여러 모델을 앙상블(ensemble)하여 사용하면 성능이 향상되지만, 이 역시 계산 비용이 크게 증가한다는 문제가 있습니다. 이러한 배경에서 모델의 성능은 유지하면서 크기와 계산 비용을 줄이는 방법에 대한 연구가 필요했습니다.
2. Distillation
Distillation은 잘 학습된 large model 이 주는 결과를 바탕으로 small model 역시 좋은 성능을 내도록 하는 과정이라 설명할 수 있을 것입니다.
2.1 Knowledge Distillation이란?
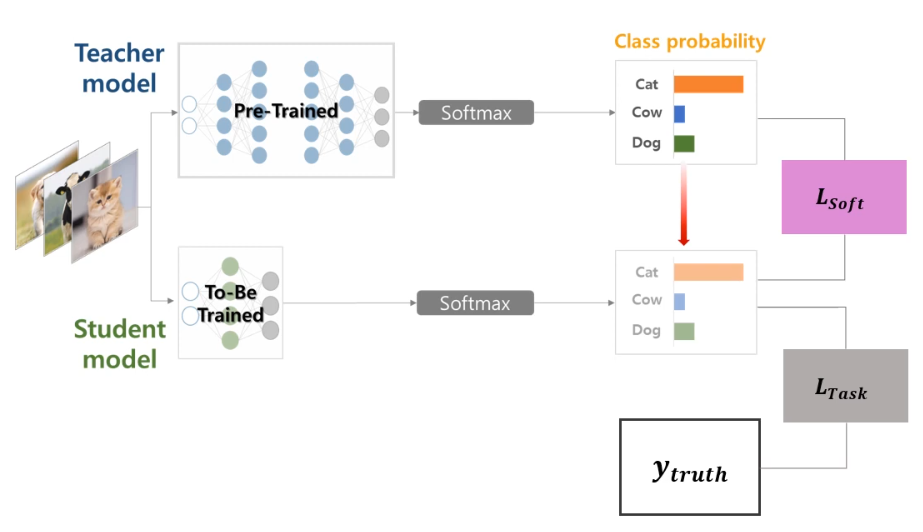
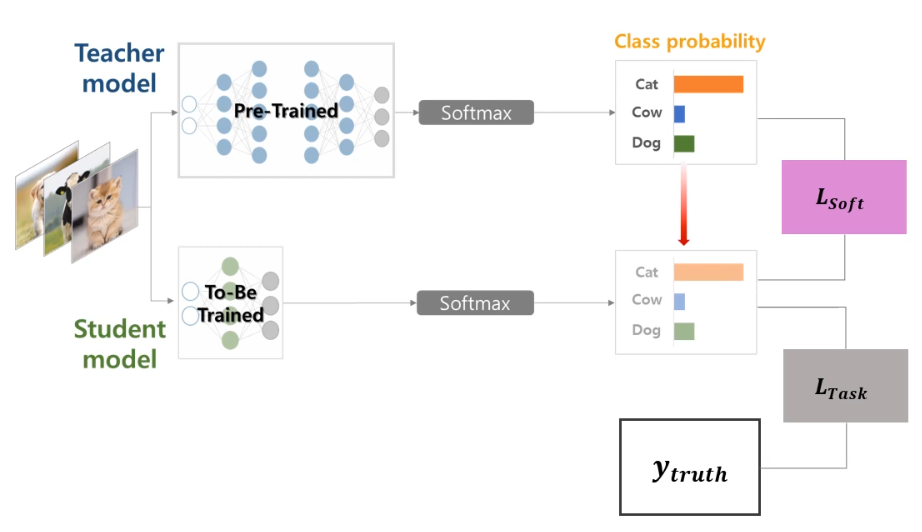
Knowledge Distillation(지식 증류)은 큰 모델이나 모델 앙상블(Teacher 모델)에서 학습한 지식을 작은 모델(Student 모델)로 전달하는 기계학습 기법입니다.
이 과정은 마치 교사가 학생에게 지식을 전달하는 것과 유사하여 Teacher-Student 패러다임으로 불리기도 합니다.
지식 증류의 목적은 작고 가벼운 모델이 큰 모델의 성능에 최대한 가깝게 도달하도록 하는 것입니다. 이를 통해 실제 배포 환경에서 계산 비용과 메모리 사용량을 줄이면서도 좋은 성능을 유지할 수 있습니다.
Teacher 모델과 Student 모델
-
Teacher 모델(Cumbersome Model): 크고 복잡한 신경망 모델 또는 여러 모델의 앙상블로, 높은 성능을 보이지만 계산 비용이 많이 듭니다.
-
Student 모델: 작고 가벼운 신경망 모델로, Teacher 모델의 지식을 전달받아 성능을 향상시키는 것이 목표입니다.
Teacher 모델은 많은 파라미터와 복잡한 구조로 인해 데이터를 잘 학습하고 일반화 능력이 뛰어나지만, 실제 환경에 배포하기에는 무겁습니다. 반면 Student 모델은 가볍고 빠르지만 단독으로는 Teacher 모델만큼의 성능을 내기 어렵습니다. Knowledge Distillation은 이 두 모델 간의 장점을 결합하는 방법입니다.
기존 학습 방식과의 차이점
기존의 신경망 학습 방식은 주로 원-핫 인코딩(one-hot encoding)된 레이블, 즉 Hard Target을 사용합니다. 이는 정답 클래스에는 1, 나머지 클래스에는 0의 값을 할당하는 방식입니다.
반면 Knowledge Distillation에서는 Teacher 모델의 출력 확률 분포인 Soft Target을 활용합니다.
이 Soft Target은 각 클래스에 대한 확률값을 포함하고 있어, 클래스 간의 유사성과 관계에 대한 풍부한 정보를 담고 있습니다. 예를 들어, '사슴' 이미지를 분류할 때 '말'과의 유사성 정보도 함께 학습할 수 있습니다.
2.2 Knowledge Distillation의 작동 원리
Soft Target의 개념
Soft Target은 Teacher 모델이 출력하는 확률 분포로, 각 클래스에 대한 세밀한 확률값을 포함합니다. 이는 단순히 정답/오답의 이진 정보가 아닌, 클래스 간의 유사성과 관계에 대한 풍부한 정보를 담고 있습니다.
예를 들어, 이미지 분류 문제에서 '사슴' 이미지를 분류할 때:
Hard Target: [0, 0, 1, 0, 0, ...] (사슴 클래스만 1, 나머지는 0)
Soft Target: [0.01, 0.39, 0.6, 0, 0, ...] (사슴 60%, 말 39%, 배 1% 등의 확률 분포)
Soft Target은 '사슴'이 '말'과 시각적으로 유사하다는 정보를 담고 있어, Student 모델이 이러한 클래스 간 관계를 학습할 수 있게 합니다.
Temperature 매개변수
Soft Target을 생성할 때 중요한 요소는 T:Temperature(온도) 매개변수입니다. 이는 Softmax 함수에 적용되는 스케일링 파라미터로, 출력 확률 분포의 '부드러움(softness)'을 조절합니다.
- 기존의 Softmax 함수는 다음과 같습니다:
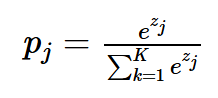
- Temperature(T)를 적용한 Softmax 함수는 다음과 같이 변형됩니다:
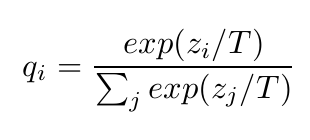
각 클래스별 확률값은 , logit은 로 표현됩니다.
Temperature 값의 영향:
-
T = 1: 일반적인 소프트맥스 함수와 동일
-
T > 1: 출력 확률 분포가 더 부드러워지며, 낮은 확률값들도 상대적으로 높아짐
-
T < 1: 출력 확률 분포가 더 뾰족해지며, 가장 높은 확률값이 더욱 강조됨
높은 Temperature를 사용하면 클래스 간의 유사성 정보가 더 잘 보존되어 Student 모델이 이를 학습할 수 있습니다. 논문에서는 학습 과정에서 높은 Temperature를 사용하고, 추론 과정에서는 T=1로 설정하는 방식을 제안했습니다.
Matching logits is a special case of distillation
Temperature을 어떻게 설정하는 것이 좋을까에 대한 고민을 특별한 케이스를 가지고 설명합니다.
작은 모델의 logit 의 변화에 따른 cross enropy의 변화 즉 gradient는 아래와 같이 표현되며, 이 때 큰 모델의 logit은 로, 큰 모델에서 생성된 target 확률을 로 표현합니다.
Cross entropy 식을 distilled model에서 나오는 logit () 으로 미분하면 식은 다음과 같다.
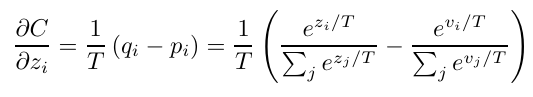
이때 temperature T가 logit 값보다 더 크다면, 지수가 0에 가까워지고 exp 함수의 특성상 1에 가까워진다. 따라서 다음과 같은 근사가 가능해진다고 합니다.
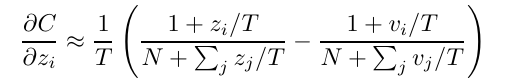
이 때 지식 증류가 잘 일어났다면 logit 와 logit 의 평균이 0이 될 것이기 때문에 최종적으로 아래와 같은 식을 얻을 수 있습니다.
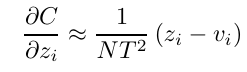
2.3 Distillation Loss
Knowledge Distillation에서는 두 가지 손실 함수(Loss Function)를 조합하여 사용합니다:
Distillation Loss: Teacher 모델의 Soft Target과 Student 모델의 출력 간의 차이를 측정합니다. 주로 KL Divergence(Kullback-Leibler Divergence)를 사용합니다
여기서 는 Teacher 모델의 logit, 는 Student 모델의 logit입니다.

Student Loss: 원래의 Hard Target과 Student 모델의 출력 간의 차이를 측정합니다. 주로 Cross Entropy를 사용합니다.
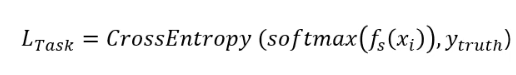
최종 손실 함수는 이 두 손실의 가중 합으로 정의됩니다:

여기서 α는 두 손실 간의 균형을 조절하는 하이퍼파라미터입니다. 이를 통해 Student 모델은 원래의 학습 목표(Hard Target)와 Teacher 모델의 지식(Soft Target)을 동시에 학습할 수 있습니다.
2.4 Knowledge Distillation의 장점
모델 경량화와 효율성
Knowledge Distillation의 가장 큰 장점은 모델 경량화와 효율성 향상입니다. 큰 모델이나 앙상블 모델의 성능을 작은 모델로 압축함으로써, 다음과 같은 이점을 얻을 수 있습니다:
-
계산 비용 감소: 작은 모델은 추론 시 필요한 연산량이 적어 더 빠르게 동작합니다.
-
메모리 사용량 감소: 파라미터 수가 적어 메모리 요구량이 줄어듭니다.
-
배포 용이성: 모바일 기기나 임베디드 시스템과 같은 제한된 환경에서도 사용할 수 있습니다.
IBM의 자료에 따르면, Knowledge Distillation을 통해 모델 크기를 "천 배 작고 빠르게" 만들면서도 앙상블 모델의 성능을 유지할 수 있다고 합니다.
일반화 성능 향상
Knowledge Distillation은 단순히 모델 크기를 줄이는 것을 넘어, Student 모델의 일반화 성능을 향상시키는 효과도 있습니다:
-
Regularization 효과: Soft Target은 Hard Target보다 더 많은 정보를 담고 있어, 모델이 과적합(overfitting)되는 것을 방지합니다.
-
클래스 간 관계 학습: 클래스 간의 유사성 정보를 학습함으로써, 보다 풍부한 특징 표현(feature representation)을 얻을 수 있습니다.
-
데이터 효율성: 논문의 실험 결과에 따르면, Soft Target을 사용할 경우 전체 데이터의 3%만으로도 전체 데이터를 Hard Target으로 학습한 경우와 비슷한 성능을 얻을 수 있었습니다.
앙상블 효과 모방
여러 모델을 앙상블하면 일반적으로 단일 모델보다 더 좋은 성능을 얻을 수 있지만, 계산 비용이 크게 증가한다는 단점이 있습니다. Knowledge Distillation은 앙상블 모델의 지식을 단일 모델로 전달함으로써, 앙상블의 이점을 유지하면서도 계산 비용을 줄일 수 있습니다.
논문에서는 Dropout을 사용한 큰 모델을 여러 모델의 앙상블과 유사하다고 보고, 이러한 모델의 지식을 작은 모델로 전달하는 방법을 제안했습니다.
단계를 정리하자면
1) Teacher Network : training set(x, hard label)을 사용해 large model 학습
2) large model 학습 뒤, large model의 output(soft label)을 target으로 하는 transfer set(x, soft label)을 생성. 이 때 soft label의 T는 1이 아닌 높은 값 사용.
3) Student Network
transfer set을 사용해 small model 학습. T는 soft label을 생성할 때와 같은 값 사용. -> soft predictions
transfer set을 사용해 small model 학습. T는 1로 고정. -> hard predictions
4) loss 생성
distillation loss : soft label과 soft predictions의 차이를 Kullback-Leiber Divergence를 통해 구함.
student loss : hard predictions과 hard label을 Cross-entropy를 통해 구함.
3. Preliminary experiments on MNIST & Results
MNIST 데이터셋 실험
논문에서는 먼저 MNIST 손글씨 숫자 데이터셋을 사용하여 Knowledge Distillation의 효과를 검증했습니다. 이 실험에서는 다음과 같은 결과를 얻었습니다:
일반적인 학습: 모든 클래스(0-9)에 대해 학습한 모델은 높은 정확도를 보였습니다.
클래스 제외 실험: 특정 클래스(숫자 3)를 제외하고 학습한 후, Soft Target을 사용하여 Knowledge Distillation을 적용했을 때, 제외된 클래스에 대해서도 98.6%의 높은 정확도를 달성했습니다.
이는 Soft Target이 클래스 간의 유사성 정보를 담고 있어, 직접적으로 학습하지 않은 클래스에 대해서도 간접적인 학습 효과가 있음을 보여줍니다. 예를 들어, 숫자 5가 숫자 3과 시각적으로 유사하다면, 5에 대한 학습을 통해 3에 대한 정보도 일부 학습할 수 있습니다.
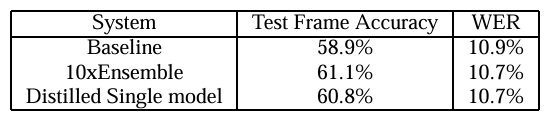
JFT 데이터셋 실험
논문에서는 더 큰 규모의 JFT 데이터셋과 실제 상용 시스템에 대한 실험도 진행했습니다:
Hard Target 학습: 전체 데이터로 학습했을 때 테스트 정확도는 58.9%, 3%의 데이터로 학습했을 때는 44.5%였습니다(Early stopping을 사용했음에도 과적합 발생).
- Hard Target: 일반적으로 원-핫 인코딩(one-hot encoding)된 레이블로, 정답 클래스에는 1, 나머지 클래스에는 0의 값을 할당합니다.
- 예시: 3개의 클래스가 있는 분류 문제에서 Hard Target은 [0, 0, 1]과 같이 나타낼 수 있습니다.
Soft Target 학습: 3%의 데이터만으로 학습했을 때 테스트 정확도는 57%에 달했습니다(Early stopping 사용 안 함).
- Soft Target: 교사 모델의 출력 확률 분포로, 각 클래스에 대한 확률값을 포함합니다.
- 예시: 3개의 클래스가 있는 분류 문제에서 Soft Target은 [0.2, 0.3, 0.5]과 같이 나타낼 수 있습니다.
Early Stopping은 기계 학습에서 과적합(overfitting)을 방지하기 위해 사용되는 정규화 기법입니다. 이는 모델의 성능이 검증 데이터셋에서 더 이상 개선되지 않을 때 학습을 중단하는 방식으로 작동합니다. Early Stopping은 다양한 기계 학습 알고리즘에서 사용되며, 특히 반복적인 최적화 방법(예: 경사 하강법)에서 유용합니다.
이 결과는 Soft Target을 사용한 Knowledge Distillation이 데이터 효율성 측면에서도 큰 이점이 있음을 보여줍니다. 전체 데이터의 일부만으로도 전체 데이터를 사용한 일반적인 학습과 비슷한 성능을 얻을 수 있었습니다.
음향 모델 실험
논문에서는 실제 상용 음성 인식 시스템의 음향 모델에 Knowledge Distillation을 적용한 실험도 진행했습니다. 이 실험에서는 앙상블 모델의 지식을 단일 모델로 전달함으로써, 음향 모델의 성능을 크게 향상시킬 수 있었습니다.
이러한 실험 결과들은 Knowledge Distillation이 다양한 도메인과 데이터셋에서 효과적으로 작동함을 보여줍니다.
4. Specialist 모델 활용
Specialist 모델의 학습 및 활용 과정은 다음과 같습니다:
-
클래스 그룹화: 혼동되기 쉬운 클래스들을 그룹화합니다. 논문에서는 Generalist 모델의 혼동 행렬(confusion matrix)을 분석하여 유사한 클래스들을 식별했습니다.
-
Specialist 모델 학습: 각 클래스 그룹에 대해 특화된 Specialist 모델을 학습합니다. 이때 해당 그룹의 클래스들과 함께 무작위로 선택된 다른 클래스들도 포함하여 학습합니다.
-
Knowledge Distillation 적용: Specialist 모델 학습 시에도 Knowledge Distillation을 적용하여 Generalist 모델의 지식을 전달받습니다.
-
앙상블 예측: 추론 시에는 Generalist 모델이 먼저 예측을 수행하고, 특정 클래스 그룹에 속할 가능성이 높은 경우 해당 Specialist 모델의 예측을 함께 고려합니다.
이러한 접근 방식은 모든 클래스를 한 모델에서 처리하는 것보다 효율적이며, 특히 클래스 수가 많은 대규모 분류 문제에서 유용합니다.
Specialist 모델의 장점
Specialist 모델 접근 방식의 주요 장점은 다음과 같습니다:
-
분류 정확도 향상: 유사한 클래스들을 구분하는 데 특화된 모델을 사용함으로써, 혼동되기 쉬운 클래스들 간의 분류 정확도를 향상시킬 수 있습니다.
-
계산 효율성: 모든 입력에 대해 모든 Specialist 모델을 실행할 필요가 없으므로, 전체적인 계산 비용을 줄일 수 있습니다.
-
모듈화 및 확장성: 새로운 클래스가 추가될 때 전체 시스템을 재학습할 필요 없이, 해당 클래스에 대한 Specialist 모델만 추가할 수 있습니다.
논문의 실험 결과에 따르면, Specialist 모델을 활용한 앙상블 접근 방식은 단일 Generalist 모델보다 더 높은 성능을 보였으며, 특히 혼동되기 쉬운 클래스들에 대한 분류 정확도가 크게 향상되었습니다.
더 나아가
KD에 대해 더 찾아보다가 BERT에 Knowledge Distillation의 응용 예시가 있어 간단하게 적어보자 합니다.
BERT → DistilBERT (언어 모델 경량화)
배경 및 필요성
BERT(Bidirectional Encoder Representations from Transformers)는 이전에 리뷰한 것 처럼 NLP 분야에서 획기적인 성능을 보인 Transformer 기반의 사전 훈련된(pre-trained) 언어 모델입니다. 하지만 BERT는 매우 많은 파라미터(약 110M~340M)를 가지고 있어, 실제 배포 환경에서 높은 계산 비용과 긴 추론 시간을 요구합니다.
DistilBERT의 등장
DistilBERT는Knowledge Distillation 기반의 경량화된 BERT 모델로, 원본 BERT-base 모델의 약 40%에 해당하는 파라미터만 사용하면서도 원본 성능의 약 97%를 유지합니다.

DistilBERT의 학습 방법
교사(Teacher): 원본 BERT-base (110M 파라미터)
학생(Student) 모델: 크기가 작은 Transformer 구조
손실 함수: 세 가지 손실을 결합하여 사용
-
Distillation Loss: Teacher와 Student의 출력 확률(logits) 간 KL Divergence(Kullback-Leibler Divergence, 쿨백-라이블러 발산)를 최소화
-
Masked Language Modeling Loss: 언어 모델링 손실
-
Cosine Embedding Loss: Teacher와 Student의 은닉 상태(hidden states)가 유사하도록 유도
결과
DistilBERT는 원본 BERT-base 모델 대비 다음과 같은 성능 향상을 이루었습니다:
파라미터 수: 약 40% 감소
추론 속도: 약 60% 향상
정확도: GLUE 벤치마크 기준으로 원본 BERT-base 대비 약 97% 수준 유지

이러한 결과를 통해 Knowledge Distillation이 BERT분야(NLP분야)에서도 뛰어난 경량화 성능을 제공한다는 것을 잘 보여줍니다.
