며칠 전 SQL 테스트를 치다가 한 문제에 막혔다. Python이라면 데이터 프레임을 정의하여 Pandas 라이브러리의 Pivot 함수를 써서 풀 수 있을 것 같았는데, SQL로 구현하려니 막막했다. 시험이 끝나고 Hackerrank 문제를 풀다가 CASE WHEN을 사용해서 Pivot Table을 구하는 방법을 알게 되었으나... 정작 시간이 지나 다시 풀어보니 테스트 때 막혔던 그 문제는 Pivot Table을 구하지 않아도 풀 수 있었다. 결말은 허무하지만 나중에 다시 써먹을 수도 있으니 기록을 해봤다. (앞부분 Pivot 함수 내용을 스킵하고 싶으시다면 목차의 "2. SQL로 Pivot Table 구하기" 로 이동하시면 됩니다.)
1. Pandas의 Pivot
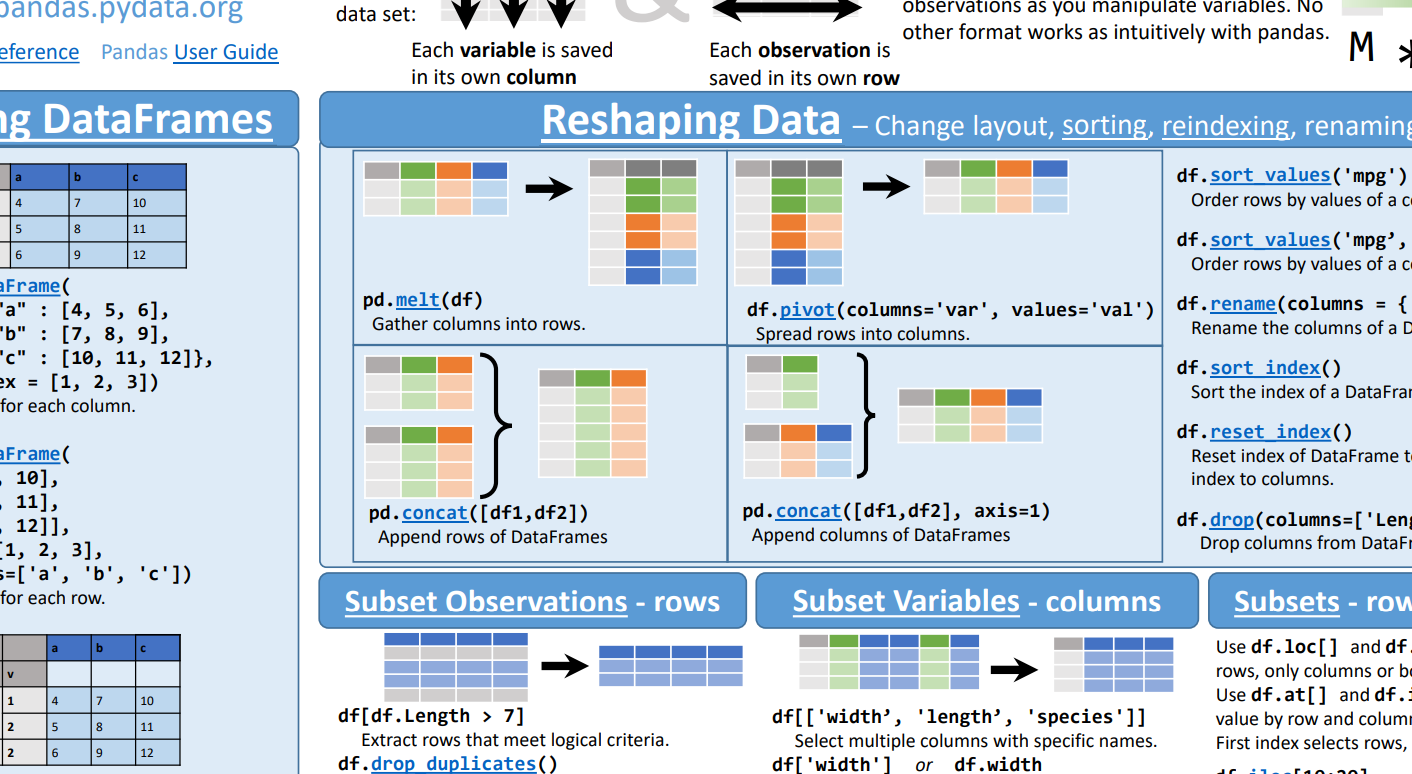
출처 : https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
위 이미지는 Pandas Cheat Sheet의 일부이다. Python으로는 Pandas를 이용하면 간단하게 Pivot Table를 만들 수 있다. 예제로 설명하면 다음과 같다.
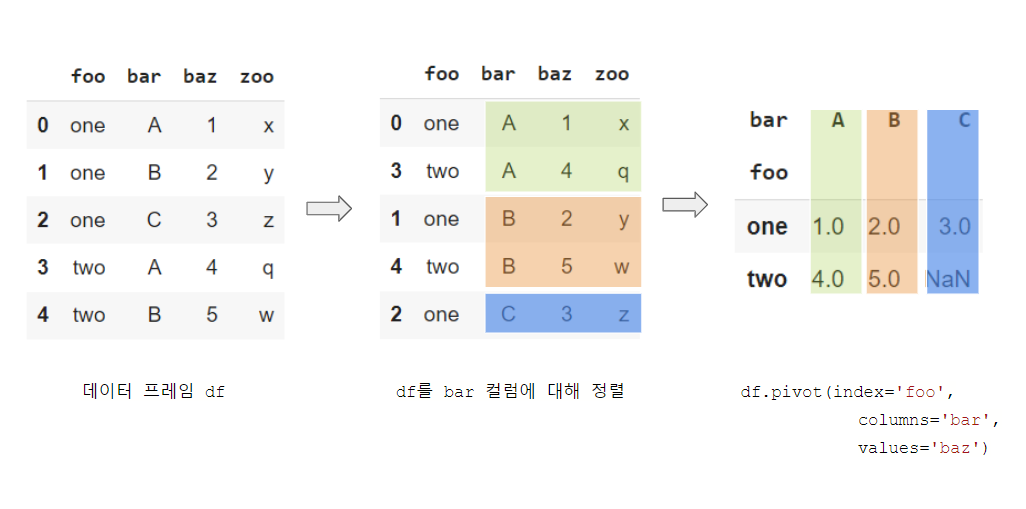
이해를 돕고자 가운데처럼 bar 칼럼을 기준으로 정렬했는데, 실제로는 데이터 프레임을 정렬할 필요 없이 바로 df.pivot(index='foo', columns='bar', values='baz')로 오른쪽과 같은 Pivot Table을 구할 수 있다. 여기서 index와 column을 지정하여 Pivot Table을 구했듯이 SQL에서도 비슷한 방식으로 구현할 수 있다.
2. SQL로 Pivot Table 구하기
Hackerrank의 Occupation 예제를 풀어보겠다.
<문제 설명>

Input인 Occupations 테이블은 Name과 Occupation, 총 2개의 필드로 이루어져있다. 여기서 Occupation 필드를 Pivot하여 위와 같은 Output을 도출하는 문제다. 출력 조건은 다음과 같다.
- Output 칼럼의 헤더는 순서대로 Doctor, Professor, Singer, Actor 이다.
- 각 칼럼마다 알파벳 순으로 이름을 출력하고 더이상 이름이 없는 경우라면 Null을 출력한다.
Step 1)
Pandas Pivot함수에서 파라메터로 index를 지정했듯이, 여기서도 index로 지정할 새로운 칼럼이 필요하다. 우선, CASE WHEN을 이용해서 다음과 같은 테이블을 구할 수 있다.
SELECT CASE WHEN Occupation = 'Doctor' THEN Name END Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END Professor,
CASE WHEN Occupation = 'Singer' THEN Name END Singer,
CASE WHEN Occupation = 'Actor' THEN Name END Actor
FROM Occupations
ORDER BY Name;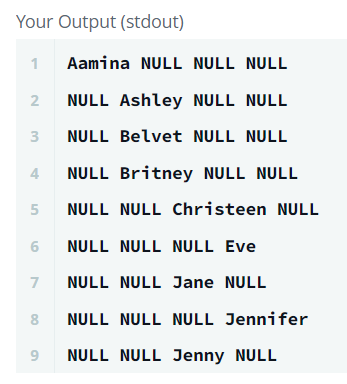
Output 칼럼의 헤더는 순서대로 Doctor, Professor, Singer, Actor 이다.
입력 테이블의 레코드 값마다 해당하는 직군에는 Name을, 그 외의 직군에는 Null값을 출력했다. 그리고 마지막에 Name을 기준으로 정렬했다.
Step 2) index 칼럼 생성하기
SET을 이용해서 NewIndex 칼럼을 생성한다.
SET @c1=0, @c2=0, @c3=0, @c4=0;
SELECT CASE WHEN Occupation = 'Doctor' THEN Name END Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END Professor,
CASE WHEN Occupation = 'Singer' THEN Name END Singer,
CASE WHEN Occupation = 'Actor' THEN Name END Actor,
CASE
WHEN Occupation = 'Doctor' THEN (@c1:=@c1+1)
WHEN Occupation = 'Professor' THEN (@c2:=@c2+1)
WHEN Occupation = 'Singer' THEN (@c3:=@c3+1)
WHEN Occupation = 'Actor' THEN (@c4:=@c4+1)
END NewIndex -- index 칼럼 생성
FROM Occupations
ORDER BY Name;c1, c2, c3, c4는 각각 Doctor, Professor, Singer, Actor 칼럼의 인덱스를 나타낸다. 레코드마다 CASE WHEN 구문으로 직군을 확인하고, 해당하는 직군의 인덱스는 1씩 더해주어 NewIndex를 값으로 기록한다. 위 코드의 결과는 다음과 같다.

이렇게 Pivot Table을 만들기 위한 Index를 만들었다. (여기서 NewIndex)
Step3) GROUP BY로 Pivot Table 만들기
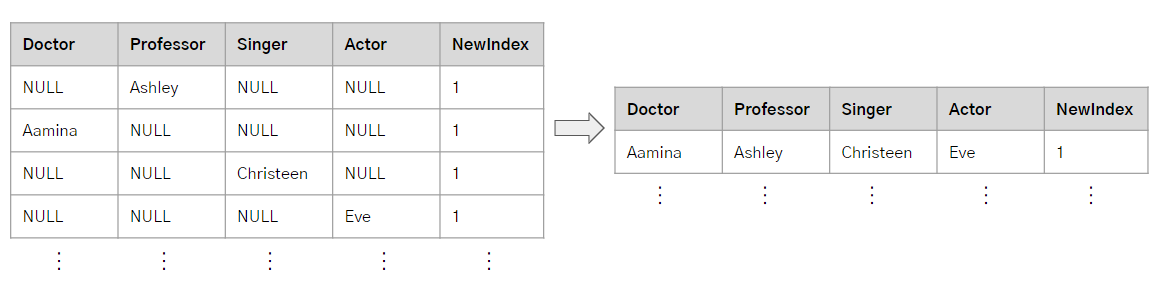
이전 Step의 결과는 왼쪽 테이블과 같다. 여기서 GROUP BY를 사용해 Pivot Table을 만든다.
필드에 Null값이 포함되어 있는 경우 ASC로 정렬했을 때 NULL은 가장 마지막 순서로 배치된다. 따라서 NewIndex로 그룹핑하여 필드별로 MIN값을 구하면 원하는 결과를 출력할 수 있다.
<최종 풀이>
SET @c1=0, @c2=0, @c3=0, @c4=0;
SELECT MIN(Doctor), MIN(Professor), MIN(Singer), MIN(Actor)
FROM (
SELECT CASE WHEN Occupation = 'Doctor' THEN Name END Doctor,
CASE WHEN Occupation = 'Professor' THEN Name END Professor,
CASE WHEN Occupation = 'Singer' THEN Name END Singer,
CASE WHEN Occupation = 'Actor' THEN Name END Actor,
CASE
WHEN Occupation = 'Doctor' THEN (@c1:=@c1+1)
WHEN Occupation = 'Professor' THEN (@c2:=@c2+1)
WHEN Occupation = 'Singer' THEN (@c3:=@c3+1)
WHEN Occupation = 'Actor' THEN (@c4:=@c4+1)
END NewIndex
FROM Occupations
ORDER BY Name
) Temp
GROUP BY NewIndex;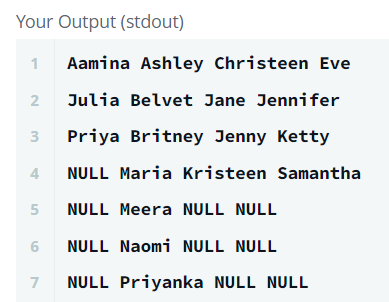
3. 그때 못 푼 그 문제
SQL 테스트에서 막혔던 문제는 대략 이런 내용이었다.
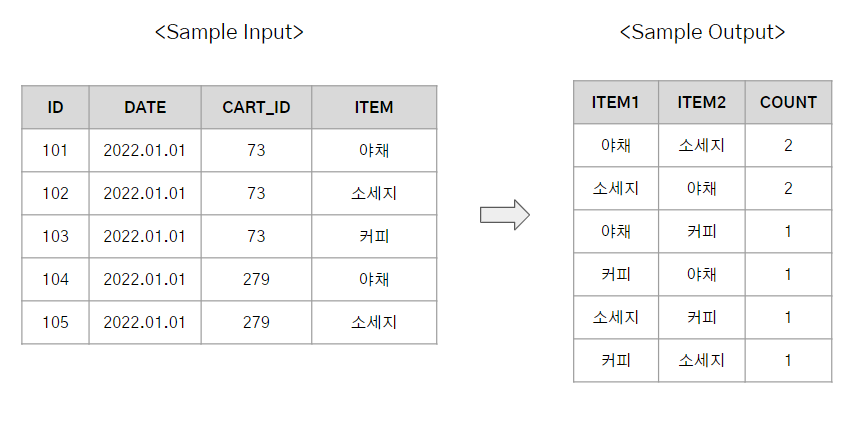
구매한 날짜(DATE), 장바구니 아이디(CART_ID)와 함께 구매한 품목(ITEM)이 왼쪽 테이블처럼 기록된다. 주로 어떤 품목들이 같이 구매되는지 연관성 분석을 하기 위해 오른쪽과 같은 결과를 출력하면 되는 문제였다. 처음 이 문제를 봤을 때는 Pivot Table로 풀어야한다고 생각했는데 다시 보니 Self Join을 이용해서 해결하는게 더 간단해보인다.
SELECT SUBSTRING_INDEX(GROUPED_ITEM, ',', 1) ITEM1,
SUBSTRING_INDEX(GROUPED_ITEM, ',', -1) ITEM2,
CNT
FROM (
SELECT CONCAT(A.ITEM, ',', B.ITEM) AS GROUPED_ITEM, COUNT(*) CNT
FROM CART_PRODUCTS A
INNER JOIN CART_PRODUCTS B ON A.CART_ID = B.CART_ID --Self Join
WHERE A.ITEM != B.ITEM -- 서로 다른 품목만 묶음
GROUP BY GROUPED_ITEM
) TEMP
ORDER BY CNT DESC;이렇게 조합을 구하는 문제나, 사용자별 첫 번째 채널과 마지막 채널을 확인하는 문제를 풀 때 Self Join과 Where 구문이 유용한 것 같다.
출처
- Pandas Cheat Sheet : https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
- Hackerrank 예제 : https://www.hackerrank.com/challenges/occupations/problem?isFullScreen=true
