알고리즘 코딩테스트를 대비하여 라이브러리를 만들듯, SQL에서 자주 헷갈리는 Window 함수를 예시와 함께 정리해보았다.
Window 함수는 주로 다음과 같은 예시에서 활용되는 것 같다.
- 2015년, 일별 자전거 누적 이용량 구하기.
- 한달간 자전거 이용량의 이동평균 구하기.
- 2015년 10월 25일, 각 자전거가 가장 마지막에 반납된 정거장을 구하기.
- 각 대여소에서 대여 시간이 가장 긴 3개의 행 구하기.
- 어떤 자전거의 다음 대여 시간 찾기.
1. Syntax
Window 함수는 윈도우라고 부르는 행의 그룹에 대한 집계 분석(예를 들어 SUM, COUNT) 값을 반환한다. 윈도우? 집계 분석? 도대체 무슨말인가 이게..
우선 어떻게 생겼는지 구조부터 확인해보자. 다음은 예시로 활용할 테이블(table_a) 이다.
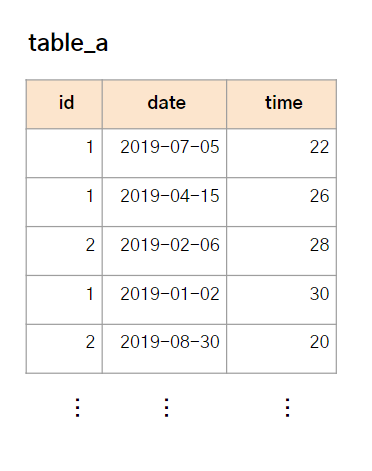
syntax 예시
SELECT
*,
Avg(TIME) over(
PARTITION BY id
ORDER BY DATE
ROWS BETWEEN 1 preceding AND CURRENT ROW
) avg_time
FROM
table_a모든 Window 함수에는 OVER가 있다. 그리고 OVER에는 3가지의 파트가 있다. 각 파트는 Optional 하다.
PARTITION BY
- row를 그룹화하는 기준. 예시에선 id를 기준으로 파티션이 분리되었다.
ORDER BY
- 각 파티션 안에서 정렬하는 기준이다. 예시에선 각 id마다 date 순으로 정렬된다.
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
- window frame 구문이다.
- 연산을 수행하는 범위를 지정한다. 예시에선 time의 평균을 구하는데, 직전 1개의 행과 현재 행에 대해 연산을 수행한다.
window frame 구문을 아래와 같은 예시처럼 설정할 수 있다.
rows between 100 preceding and 1 preceding: (현재 행을 기준으로) 이전 100번째 행부터 이전 1번째 행까지rows between unbounded preceding and current row: (현재 행을 기준으로) 이전 모든 행과 현재 행까지range between unbounded preceding and current row: (현재 값을 기준으로) 이전 모든 값과 현재 값까지
예시의 결과는 다음과 같다.
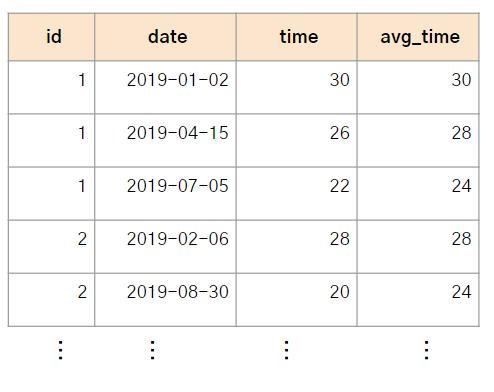
2. Window function의 종류
BigQuery 공식 문서에 따르면 Window function의 종류는 아주 많다. 크게 세 가지로 분류할 수 있는데,
1) Analytic aggregate function (집계 분석)
- 특정 범위의 윈도우에 대해 AVG(), MIN(), SUM(), COUNT() 등의 연산이 수행되어 하나의 값이 출력되는 함수다.
2) Analytic navigation function (탐색)
- 행의 위치를 이용해 값을 찾을 수 있다. 예를 들어 특정 윈도우에 대해 첫번째 행과 마지막 행을 구하고 싶을 때, FIRST_VALUE(), LAST_VALUE() 함수를 이용한다.
3) Analytic numbering function (번호 매기기)
- row의 순서에 따라 일련번호를 할당한다. 대표적으로 RANK(), DENSE_RANK(), ROW_NUMBER() 등이 있다.
3. 예제로 이해하기
예제로 사용할 테이블은 아래와 같다.
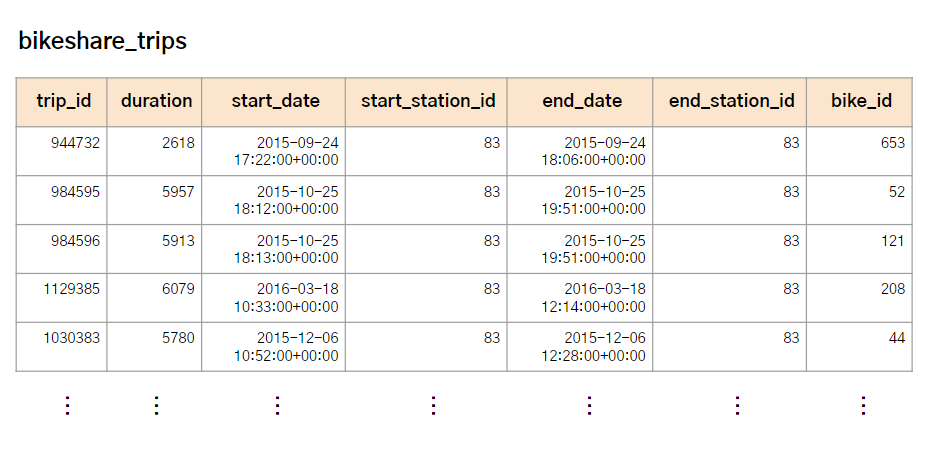
기본 정보
trip_id: 대여 기록 id (primary key)bike_id: 대여 자전거 id
시간 정보
duration: 대여 소요 시간start_date: 대여 시각end_date: 반납 시각
대여소 정보
start_station_id: 대여 정류소 idend_station_id: 반납 정류소 id
Q1) 2015년, 일별 자전거 누적 이용량 구하기.
-- (1) CTE : 2015년 데이터만 가져오기 (일별 자전거 이용량)
WITH trips_by_day AS (
SELECT
DATE(start_date) AS trip_date,
COUNT(*) AS num_trips
FROM
bikeshare_trips
WHERE
EXTRACT(YEAR FROM start_date) = 2015
GROUP BY
start_date
)
-- (2) 일별 누적 이용량 (cumulative_trips)
SELECT
*,
Sum(num_trips) OVER (
ORDER BY
trip_date ROWS BETWEEN unbounded preceding
AND CURRENT ROW
) AS cumulative_trips
FROM
trips_by_day- (1) 가독성을 위해 CTE로 2015년의 이용기록만 가져온다 (trips_by_day, 2015년 일별 자전거 이용량)
- (2) 그리고 새로운 SELECT 구문으로 cumulative_trips 열을 생성한다.
OVER 구문을 살펴보면, ORDER BY trip_date으로 행을 정렬하고, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW으로 누적값을 구하도록 설정했다.
여기서 partition은 따로 지정하지 않았다. 이처럼 partition을 따로 지정하지 않은 경우, 테이블의 모든 행이 하나의 single partition인 셈이다.
Q2) 한달간 자전거 이용량의 이동평균 구하기
자전거 이용의 수요를 분석하거나 예측하고 싶을 때, 이동평균을 활용하기도 한다. Window 함수를 이용하면 이동 평균을 쉽게 구할 수 있다.
2016년의 일별 이용 횟수의 평균을 구하고자 한다. (1년 동안 이용 데이터는 매일 기록되어있다고 가정한다.) 이때, 특정 날짜으로부터 15일 전부터 15일 이후의 범위에 해당하는 이동 평균(rolling average)를 구하려고 한다.
-- (1) CTE : 2016년 데이터만 가져오기 (일별 자전거 이용량)
WITH trips_by_day AS (
SELECT
DATE(trip_start_timestamp) AS trip_date,
COUNT(*) AS num_trips
FROM
bikeshare_trips
WHERE
trip_start_timestamp >= '2016-01-01'
AND trip_start_timestamp < '2017-01-01'
GROUP BY
trip_date
ORDER BY
trip_date
)
-- (2) 일별 이동 평균 구하기
SELECT
trip_date,
Avg(num_trips) OVER (
ORDER BY
trip_date ROWS BETWEEN 15 preceding
AND 15 following
) AS avg_num_trips
FROM
trips_by_day"Q1. 누적 이용량 구하기"와 과정이 유사하고, Window Frame을 지정하는 방식만 조금 다르다.
- (1) 가독성을 위해 CTE로 2016년의 이용기록만 가져온다 (trips_by_day, 2016년 일별 자전거 이용량)
- (2) 그리고 새로운 SELECT 구문으로 avg_num_trips 열을 생성한다.
OVER 구문을 살펴보면, ORDER BY trip_date으로 정렬하고, ROWS BETWEEN 15 PRECEDING AND 15 FOLLOWING 으로 특정 행을 기준으로 이전 15개의 행과 이후 15개의 행을 포함한 범위에서 AVG(num_trips) 으로 평균을 구한다.
Q3) 2015년 10월 25일, 각 자전거가 가장 마지막에 반납된 정거장을 구하기.
2015년 10월 25일의 대여 기록 중, 각 자전거 id 마다 어느 정류소에서 최종 반납되었는지 확인해보자.
SELECT
DISTINCT bike_id,
Last_value(end_station_id) OVER (
PARTITION BY bike_id
ORDER BY
start_date ROWS BETWEEN unbounded preceding
AND unbounded following
) AS last_station_id
FROM
bikeshare_trips
WHERE
DATE(start_date) = '2015-10-25'- 자전거마다 최종 반납된 정거장을 확인하고 싶으므로
PARTITION BY bike_id으로 지정했다. - partition 안에서는 start_date를 기준으로 정렬을 해준 다음, Window frame의 범위는 파티션 전체로 지정했다. (
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) - 여기서
LAST_VALUE()구문을 이용하면 partition마다 마지막 순서의 관측치를 가져올 수 있다. 같은 원리로FIRST_VALUE()구문을 이용하면 partition 별 첫번째 순서의 관측치를 가져올 수 있다.
Q4) 각 대여소에서 대여 시간이 가장 긴 3개의 행 구하기.
-- (1) CTE : 대여소마다 대여시간 순서로 순위 매기기
WITH longest_trips AS (
SELECT
start_station_id,
duration,
ROW_NUMBER() over(
partition BY start_station_id
ORDER BY
duration DESC
) AS nth_longest
FROM
bikeshare_trips
)
-- (2) 대여시간 순위 상위 3개만 가져오기
SELECT
start_station_id,
duration
FROM
longest_trips
WHERE
nth_longest <= 3
LIMIT
10(1) CTE : 대여소마다 대여시간 순서로 순위 매기기
- 대여소로 partition을 나누고 (
PARTITION BY start_station_id) - partition마다 대여 시간으로 내림차순 정렬했다. (
ORDER BY duration DESC) - 이때 RANK() 함수는 파티션 내부의 정렬 기준을 바탕으로 관측치의 순위를 매겨준다.
(2) 대여시간 순위 상위 3개만 가져오기
- 임시테이블 (longest_trips) 에서 상위 순위 3개까지만 가져온다. (
WHERE nth_longest <= 3)
Q. 만약 중복 값이 있을 때는 어떻게 rank 값을 정할까?
A. BigQuery에선 순위를 매기는 함수로 RANK()말고도 DENSE_RANK(), ROW_NUMBER()도 지원한다. 세 함수의 차이점은 중복 값을 다루는 방식에 있다.
- 예시
WITH example AS (SELECT 'A' AS NAME, 32 AS age UNION ALL SELECT 'B', 32 UNION ALL SELECT 'C', 33 UNION ALL SELECT 'D', 33 UNION ALL SELECT 'E', 34) SELECT NAME, age, Rank() OVER ( ORDER BY age) rank, Dense_rank() OVER ( ORDER BY age) dense_rank, Row_number() OVER ( ORDER BY age) row_number FROM example
- RANK()는 순위가 중복되면 숫자를 건너뛰는 반면,
- DENSE_RANK()는 순위가 중복되어도 숫자를 연결해서 할당한다.
- 반면 ROW_NUMBER()는 정렬된 순서대로 행마다 고유한 숫자를 할당한다.
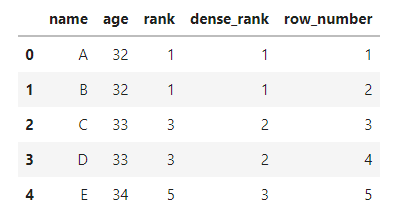
Q5) 어떤 자전거의 다음 대여 시간 찾기.
-- 예시 (1) : LAST_VALUE(value) 사용
SELECT
start_date,
end_date,
LAST_VALUE(start_date) OVER(
PARTITION BY bike_id
ORDER BY
start_date ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING
) AS next_rental_start
FROM
bikeshare_trips
LIMIT
10- 자전거마다 Partition을 나누고, 대여시각을 기준으로 정렬한다.
- 그리고 현재 행과 그 다음 행 1개를 Window frame으로 지정한다. (
ROWS BETWEEN CURRENT ROW 1 FOLLOWING) - 해당 윈도우에서 마지막 행의 start_date을 찾으면, 다음 번에 대여한 시각을 구할 수 있다.
LAST_VALUE(value)를 사용하는 대신, LEAD(value, n) 를 사용할 수도 있다.
-- 예시 (2) : LEAD(value, n) 사용
SELECT
start_date,
end_date,
LEAD(start_date, 1) OVER(
PARTITION BY bike_id
ORDER BY
start_date
) AS next_rental_start
FROM
bikeshare_trips
LIMIT
10LEAD(value, n) 함수의 두번째 파라미터인 n은 건너뛸 행의 수이다. LEAD 함수를 사용하면, 예시(1) 처럼 Window frame을 지정해줄 필요 없어 좀 더 간결하다. 참고로, FIRST_VALUE() 함수 대신에는 LAG() 함수를 쓸 수 있다.
4. ref
참고한 자료
- kaggle advanced SQL course
참고한 서적
- 빌리아파 락쉬마난, 조던 티가니 지음 / <구글 빅쿼리 완벽 가이드> / 변성윤, 장현희 옮김 /
- 가사키 나가토, 다미야 나오토 지음 / <데이터 분석을 위한 SQL 레시피> / 윤인성 옮김
