LAG와 LEAD는 주로 시계열 데이터를 분석할 때 많이 쓴다고 배웠다. 그런데 정작 쿼리 연습할 때 이 함수들을 사용해본 경우가 드물었는데, 사용 예시를 정리해두면 나중에 적용하기 편하겠다는 생각이 들었다. 함수 정의와 예시는 BigQuery를 기준으로 작성했다.
1. LAG 함수 정의
LAG(expression [,offset][, default_value]) OVER over_clause
- expression : 칼럼명
- offset : 기본값은 1. window frame 상에서 몇 번째 이전 행의 값을 반환할지 결정.
- default_value : 이전 행이 존재하지 않을 때 대체할 값. 기본값으 NULL
- over_clause : PARTITION BY나 ORDER BY 를 Optional하게 사용 가능
over_clause와 window frame 구문에 대한 자세한 설명은 이곳에
2. 목적
사용한 데이터
BigQuery의 공개 데이터 중 "san_francisco" Dataset에서 "bikeshare_trips" Table을 사용했다. 2015-01-01부터 2016-08-31까지 샌프란시스코 지역의 자전거 대여/반납 내역이 기록된 테이블이다.
-
스키마
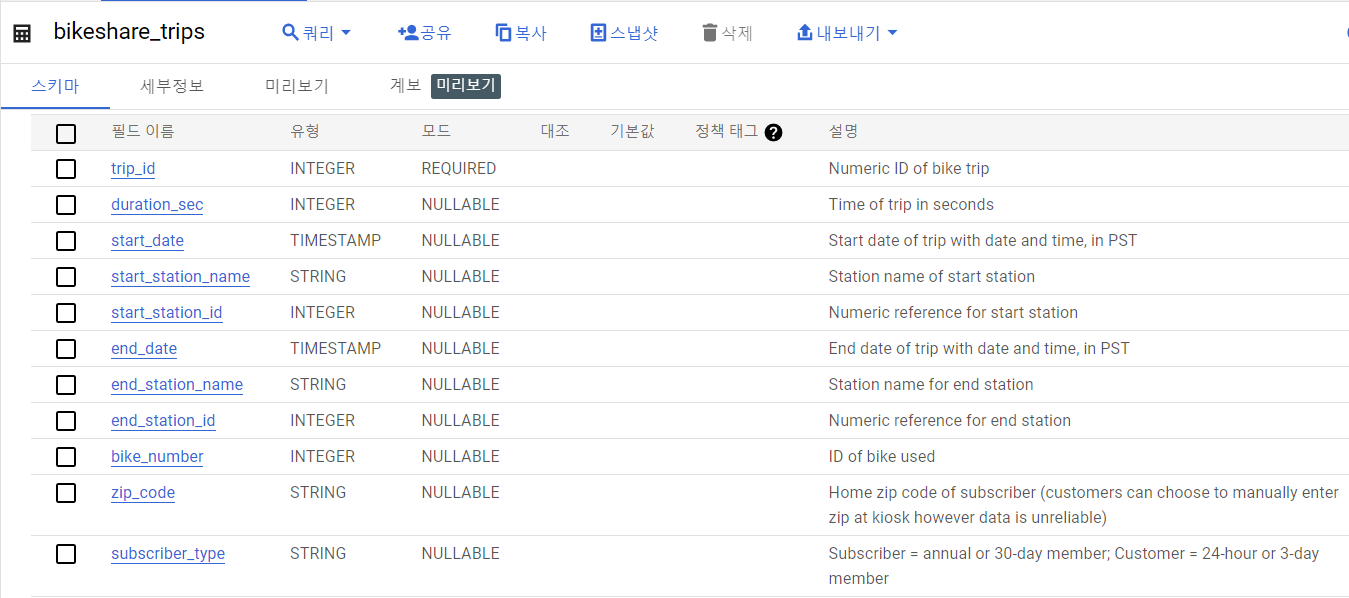
-
미리보기
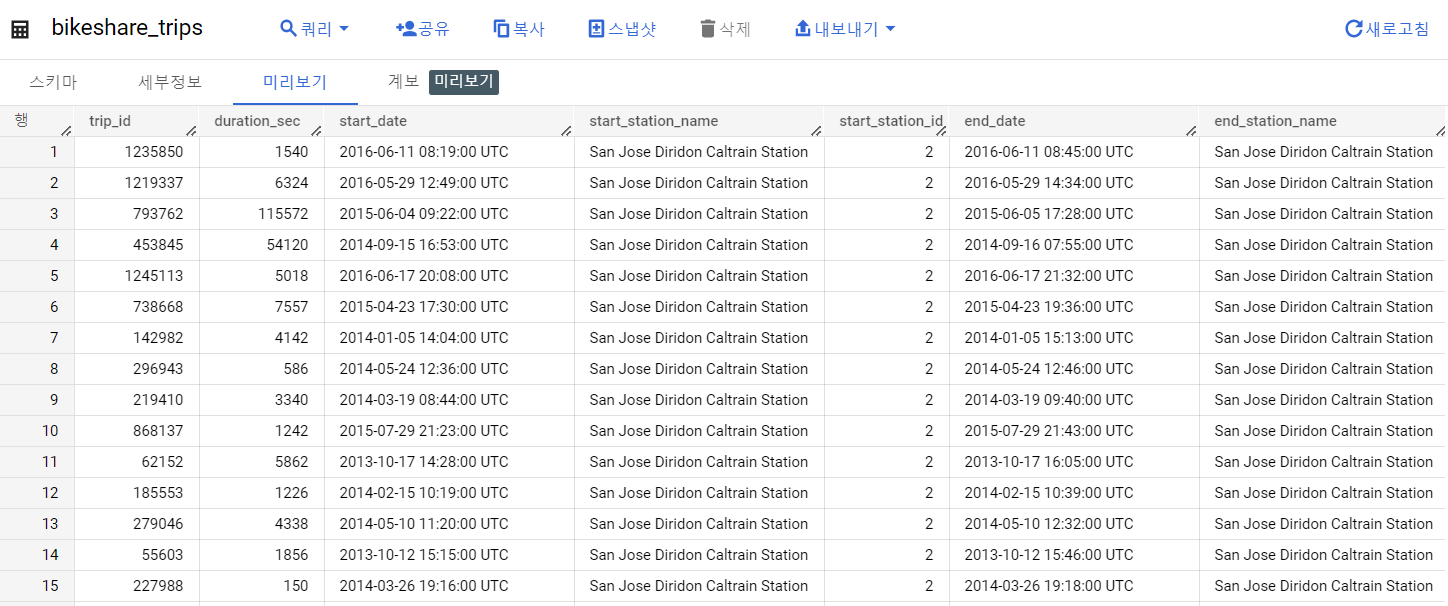
목적 1. 지난주 이용량과 이번주 이용량 비교하기
테이블의 칼럼 값이 정렬된 상태에서 LAG함수로 n번 이전 행에 해당하는 값을 가져올 수 있다. 예를 들어 다음과 같은 분석이 가능하다.
- 자전거 이용량의 요일별 패턴 분석
- 월별 이용량이 증가한 요인을 분석할 때, 전년 동기에도 비슷한 현상이 있었는지 확인할 때
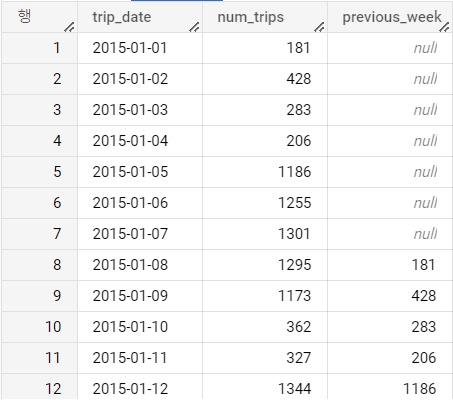
다음은 2015년 자전거 이용량의 요일별 패턴을 분석하고자, 지난주 이용량(previous_week)과 이번주 이용량(num_trips)을 비교한 결과다.
-- (1) 일별 이용량 집계
WITH updates AS(
SELECT
DATE(start_date) AS trip_date,
COUNT(*) AS num_trips
FROM `bigquery-public-data.san_francisco.bikeshare_trips`
WHERE EXTRACT(YEAR FROM start_date) = 2015
GROUP BY 1
)
-- (2) 이번주와 지난주 이용량 비교
SELECT
trip_date,
num_trips,
LAG(num_trips, 7)
OVER(
ORDER BY trip_date
) AS previous_week
FROM updates
ORDER BY 1- (1) updates 테이블 : 2015년 데이터만 가져와 일별 자전거 이용량을 집계했다.
- (2) LAG 함수로 7일 전 이용량을 가져왔다. 7일전 날짜 데이터가 없는 경우 NULL값 처리되었다.
목적 2. 결측(Missing Value) 확인
그런데 앞서 작성한 쿼리에는 문제가 있다. trip_date이 연속되지 않을 수 있다. 즉, 자전거 대여 기록이 매일 누락 없이 기록되었으라는 보장은 없다. 데이터를 수집하는 과정에서 얼마든지 결측이 발생했을 수 있다. 이를 확인하기 위해 LAG함수를 사용할 수 있다.
-- (1) 일별 이용량 집계
WITH updates AS(
SELECT
DATE(start_date) AS trip_date,
COUNT(*) AS rows_added
FROM `bigquery-public-data.san_francisco.bikeshare_trips`
WHERE EXTRACT(YEAR FROM start_date) = 2015
GROUP BY 1
),
-- (2) 업데이트된 기록 간격 구하기
num_days_update AS(
SELECT
trip_date,
DATE_DIFF(
trip_date,
LAG(trip_date, 1)
OVER(
ORDER BY trip_date
),
DAY
) AS days_since_last_update
FROM updates
)
-- (3) 결측 날짜 확인
SELECT * FROM num_days_update WHERE days_since_last_update > 1- (1) updates 테이블 : 일별 이용량 집계
- (2) num_days_update : 업데이트된 기록 간격 구하기. LAG함수로 이전 행과 현재 행의 날짜 간격 계산함.
- (3)
days_since_last_update가 n일 초과인 경우 확인. 임계값 기준 n은 정하기 나름. 예시에선 1일 초과된 경우를 확인했다.
쿼리 결과는 다음과 같다.
2015년 일별 이용량 데이터는 days_since_last_update 칼럼 값이 모두 1이다. (모두 1일 간격으로 업데이트 되었다.)
LAG(num_trips, 7)) 값이 7일 전의 값이 되려면 "num_trips가 하루도 누락없이 매일 기록되었다" 라는 전제가 있어야 한다.
매일 기록되어야 했을 자전거 대여 기록에서 누락이 발견된다면? 이상 징후로 Alert하고, 데이터 계보 그래프를 확인해야한다. 만약 선행 테이블이 있다면 선행 테이블의 기록 과정에서 발생한 문제인지 확인이 필요하다.
3. 예시
2015년 샌프란시스코의 자전거 대여량 추세를 확인한다고 하자. 이를 위해 monthly_average_num_trips을 계산해 시각화하려 한다.
monthly_average_num_trips: 최근 30일간의 평균 이용량
1단계 : 일별 이용량 집계
WITH updates AS(
SELECT
DATE(start_date) AS trip_date,
COUNT(*) num_trips
FROM `bigquery-public-data.san_francisco.bikeshare_trips`
WHERE EXTRACT(YEAR FROM start_date)=2015
GROUP BY 1
)2단계 : 일별 이용량에 누락된 날짜가 있는지 확인
WITH num_days_update AS(
SELECT
trip_date,
DATE_DIFF(
trip_date,
LAG(trip_date, 1)
OVER(
ORDER BY trip_date
),
DAY
) AS days_since_last_update
FROM updates
)
-- 마지막으로 업데이트 된 기록이
SELECT * FROM num_days_update WHERE days_since_last_update > 1- 기록이 누락된 날짜가 없음을 확인
3단계 : 최근 30일간 평균 이용량 구하기
- monthly_average_num_trips : x일 기준으로 최근 30일간 평균 이용량 계산
- next_num_trips : LEAD함수로 (x+1) 일에 해당하는 이용량 가져옴
SELECT
trip_date,
AVG(num_trips)
OVER(
ORDER BY trip_date
ROWS BETWEEN 29 PRECEDING AND
CURRENT ROW
) AS monthly_average_num_trips,
LEAD(num_trips, 1)
OVER(
ORDER BY trip_date
) AS next_num_trips
FROM updates
ORDER BY 14단계 : 시각화
쿼리를 실행하고 나면 쿼리 결과 테이블을 바로 Google Colab으로 가져올 수 있다.
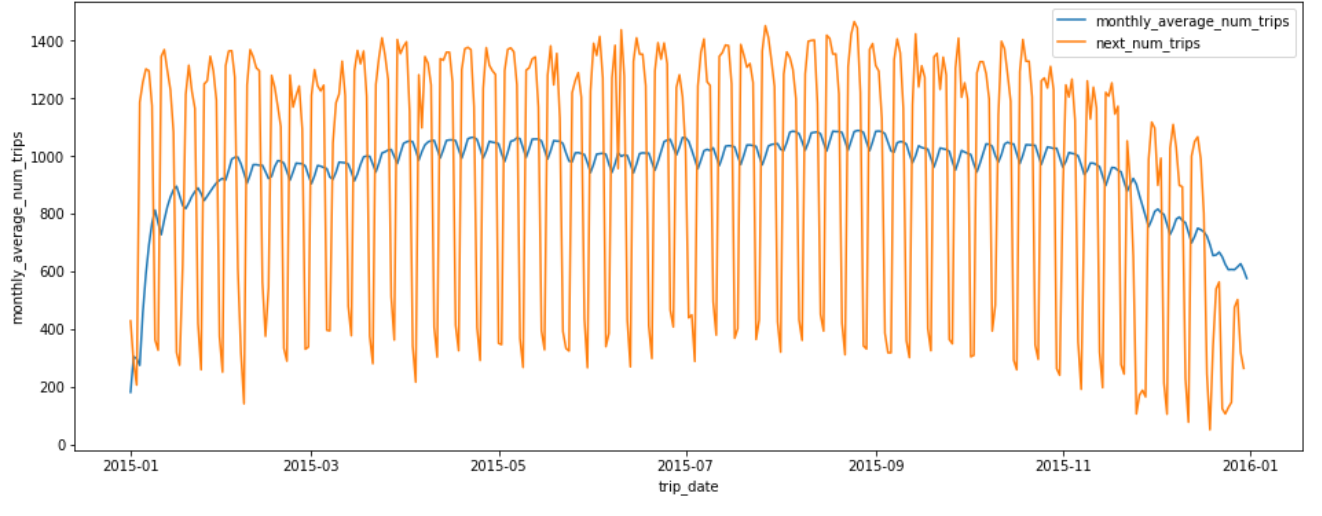
monthly_average_num_trips의 추이를 시각화 한 결과, 2015년 11월 이후로 자전거 이용량이 감소했음을 파악할 수 있다.
최근 30일간 평균 이용량(monthly_average_num_trips, 파랑색)으로 다음날 이용량(next_num_trips, 주황색)을 예측할 수 있을까? 자전거 이용량은 요일별 패턴이 강하다보니 monthly_average_num_trips는 예측 목적으로는 적절하지 않아보인다.
4. 참고한 자료
