캐글의 SQL 튜토리얼을 공부하다 Nested, Repeated 데이터타입을 알게되었다.
관측치로 하나의 스칼라 값이 들어간 것이 아니라, 마치 dict 타입처럼 저장된 방식이었다. (위 예시에선 totals column처럼)
왜 이러한 형태로 저장하는지, 그리고 totals column에 들어 있는'visits','hits','pageviews' 데이터는 SELECT문으로 어떻게 조회할 수 있을지 정리했다.
글의 순서는 다음과 같다.
1. Nested Data란?
2. Repeated Data란?
3. Nested & Repeated Data란?
4. 데이터를 배열로 저장하는 이유
1. Nested Data
- datatype : RECORD (STRUCT 라고도 표현함)
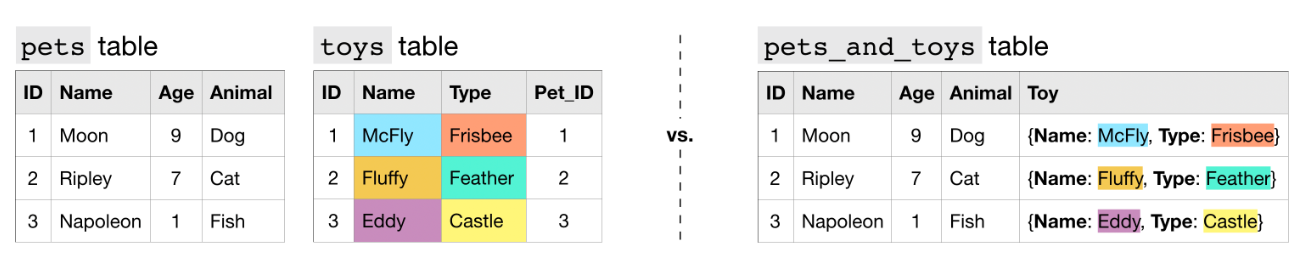
pets, toys 테이블이 있다고 가정하자.
pets는 동물 정보가 담긴 테이블이고,toys은 동물이 가지고 노는 장난감 정보가 있다.
이 두 테이블을 오른쪽처럼 하나의 테이블 pets_and_toys로 합칠 수 있다. pets_and_toys의 "Toy" 칼럼안에 Name, Type 필드가 동시에 포함된 형태를 "Nested 되어있다"고 표현한다.
-- "pets_and_toys" 테이블 생성
SELECT
p.ID,
p.Name,
p.Age,
p.Animal,
STRUCT(t.Name, t.Type) Toy
FROM
pets p
LEFT JOIN toys t ON p.ID = t.Pet_ID데이터 접근 방법
- Nested Data에 포함된 Name 값은,
Toys.Name의 형식으로 접근할 수 있다. - 예시

2. Repeated Data
- datatype : REPEATED
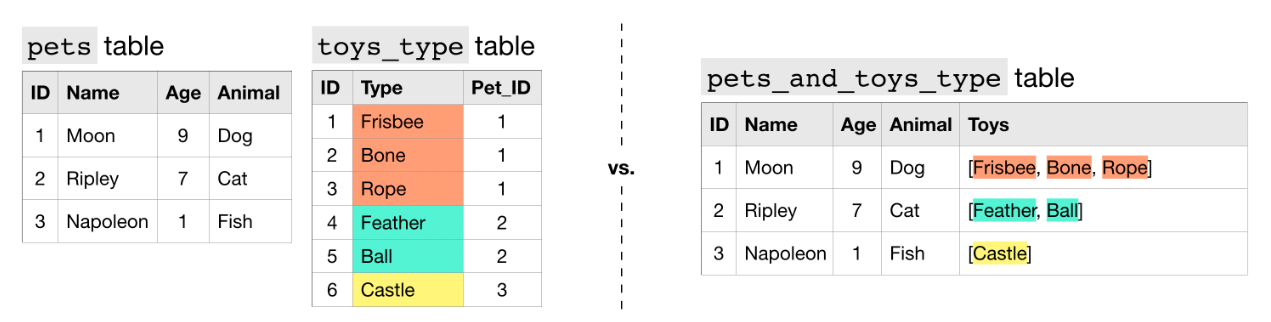
만약 동물(pets)마다 가지고 있는 장난감(toys)이 여러개라면? Repeated 타입을 쓸 수 있다. pets 테이블과 toys_type 테이블을 합쳐서, 오른쪽 pets_and_toys_type과 같은 테이블을 생성할 수 있다.
-- "pets_and_toys_type" 테이블 생성
--- (1) 임시 테이블 repeated_toys 생성 : repeated column인 Toys 만들기
WITH repeated_toys AS(
SELECT
Pet_ID,
ARRAY_AGG(Type ORDER BY ID) Toys
FROM
toys_type
GROUP BY
Pet_ID
)
--- (2) LEFT JOIN
SELECT
p.ID,
p.Name,
p.Age,
p.Animal,
r.Toys
FROM
pets p
LEFT JOIN repeated_toys r ON p.ID = r.Pet_ID(1) 임시 테이블 repeated_toys 생성 : nested column인 Toys 만들기
- [Frisbee, Bone, Rope] 와 같은 Repeated Data를 생성하기 위해서
ARRAY_AGG(col)함수를 사용한다.ARRAY_AGG(col)는 ARRAY(배열)을 리턴한다.- Repeated 필드인 Toys에 입력된 값들은 ARRAY(배열) 데이터이다.
- 배열 데이터는 순서가 있고(ordered list), 동일한 datatype으로 구성되어있다.
- Pet_ID를 기준으로 배열 데이터(Repeated Data)를 생성하고자 하므로
GROUP BY Pet_ID구문이 필요하다.
(2) LEFT JOIN
- pets 테이블과 repeated_toys 테이블을 Pet_ID 를 기준으로 LEFT JOIN 한다.
데이터 접근 방법
- Toys 내부의 배열 데이터에 접근하려면,
UNNEST함수(in Bigquery)를 이용한다. (UNNEST함수는 이어지는 3장에서 정리) - 예시

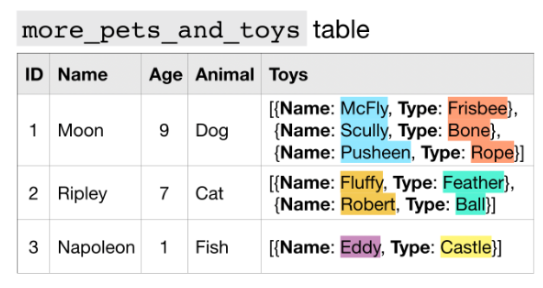
3. Nested and Repeated Data
- datatype : RECORD and REPEATED
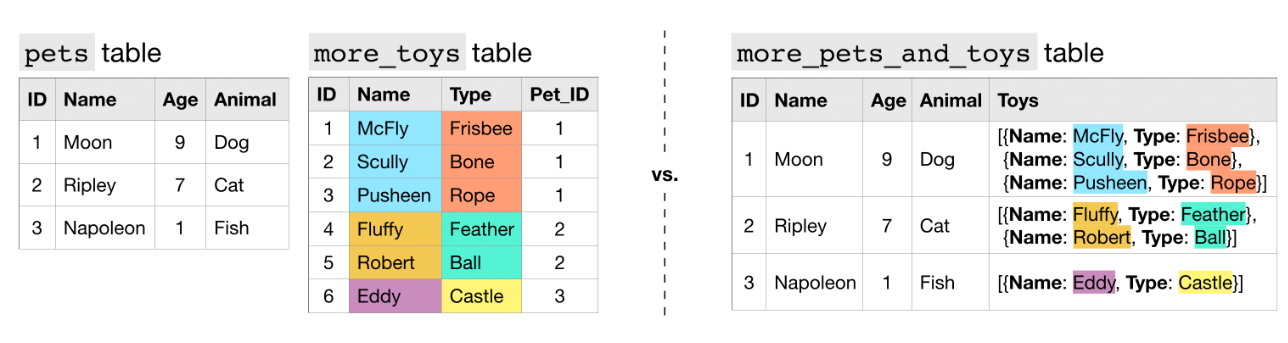
Nested 되어있으면서 Repeated 형태의 데이터 타입도 가능하다. 오른쪽 more_pets_and_toys 테이블의 Toys 필드는 Nested and Repeated Data이다.
-- "more_pets_and_toys" 테이블 생성
--- (1) 임시테이블 nested_repeated_toys 생성
WITH nested_repeated_toys AS(
SELECT
Pet_ID,
ARRAY_AGG(
STRUCT(Name, Type)
ORDER BY
ID
) Toys
FROM
more_toys
GROUP BY
Pet_ID
)
--- (2) LEFT JOIN
SELECT
p.ID,
p.Name,
p.Age,
p.Animal,
n.Toys
FROM
pets p
LEFT JOIN nested_repeated_toys n ON p.ID = n.Pet_IDToys 칼럼의 datatype은,
- RECORD :
Name,Type값이 Nested 되어있다. - REPEATED :
Toys.Name과Toys.Type은 각각 ARRAY이다.
데이터 접근 방법
- 예시

UNNEST(col) 는?
- Repeated 칼럼을 Flatten 하는 함수다.
- 인자로 들어가는 col은 ARRAY 타입이어야한다. (
[]로 감싸진 형태)- 가능 (O) 예시 :
[{'Name':'A', 'Type':1}, {'Name':'B', 'Type':2}] - 가능 (X) 예시 :
{'Name':['A','B'], 'Type':[1, 2]}
- 가능 (O) 예시 :
- UNNEST 함수는 FROM 절에서 사용한다.
- Alias를 쓰면 값을 조회하기 편하다.
- 위 예시에는 Alias를 t로 세팅했고, SELECT 문에서
t.Name,t.Type형태로 조회했다.
- 위 예시에는 Alias를 t로 세팅했고, SELECT 문에서
Nested and Repeated Data 예시
WITH nested_repeated_toys AS( SELECT Pet_ID, ARRAY_AGG( STRUCT(Name, Type) ORDER BY ID ) Toys FROM more_toys GROUP BY Pet_ID )예시 1:
[{'Name':'A', 'Type':1}, {'Name':'B', 'Type':2}]
예시 2:{'Name':['A','B'], 'Type':[1, 2]}
nested_repeated_toys테이블의 Toys 칼럼은 <예시 1> 형태다.- STRUCT 함수와 ARRAY_AGG 함수의 순서에 따라 <예시 1>이 될 수도 있고, <예시 2>가 될 수도 있다.
- Nested and Repeated Data의 예시를 살펴보면 <예시 1>의 형태가 더 많은데, 왜 그럴까?
- (추측으로) <예시 2>라면 조회하기 어려워서 그런 것 같다. <예시 2>는 배열이 두 개 ('Name'과 'Type'에 각각 하나씩) 있기 때문에, 각각의 배열을 Flatten하기 위해 UNNEST 함수를 두 번 써야한다. 반면, <예시 1>은 UNNEST를 한 번만 쓰면 된다.
4. 데이터를 배열로 저장하는 이유
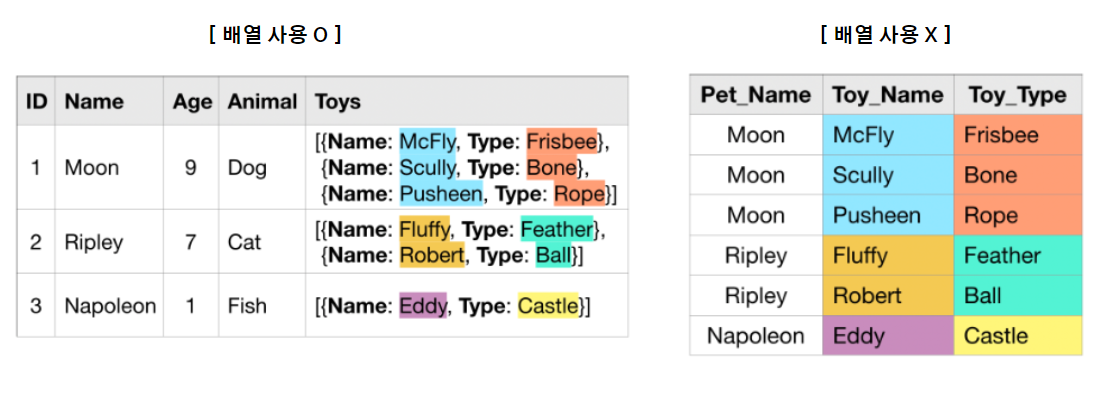
왼쪽 테이블은 Toys 칼럼에 배열을 사용했고, 총 3개 행으로 이루어져 있다.
오른쪽 테이블은 배열을 사용하지 않았고, 총 6개 행으로 이루어져있다.
처음에는 왜 굳이 배열 데이터를 써야하는지 이해가 잘 가지 않았다. 애초에 데이터가 이미 배열 형태로 저장되어있는 경우라면, UNNEST 와 같은 함수를 이용해서 데이터를 조회가능하다는 것은 이해가 갔다.
하지만 데이터를 저장하는 관점에서는, 배열을 사용하는 것이 더 복잡도가 높아질 것이라고 생각했다. (만약 Repeated and Nested and Repeated and Nested, ... 형태라면..? SELECT문으로 조회하려면 굉장히 복잡해질 것 같다..)
<구글 빅쿼리 완벽 가이드> 책에서 관련 내용을 찾아보니, 배열 형태로 데이터를 저장하는 몇 가지 상황을 알게 되었다.
4.1 데이터의 순서가 중요한 경우
분석 작업을 위해 데이터를 가공해 테이블로 저장해두었다고 했을 때, 나중에 그 테이블을 읽을 때 정렬이 유지된다는 보장이 없다. 분석 작업에서 데이터의 순서가 중요하다면, 순서를 저장하기 위해 배열을 사용하기도 한다. (위의 예시의 경우, Toy_Name과 Toy_Type은 순서가 크게 중요하지 않아보인다.)
4.2 반복 가능성 있는 값들을 단일 행에 저장하기
(오른쪽과 달리) 왼쪽 테이블은 pet_ID마다 하나의 행이 보장된다. 배열을 사용하면, 컬럼 간에 일대일 관계를 유지할 수 있다.
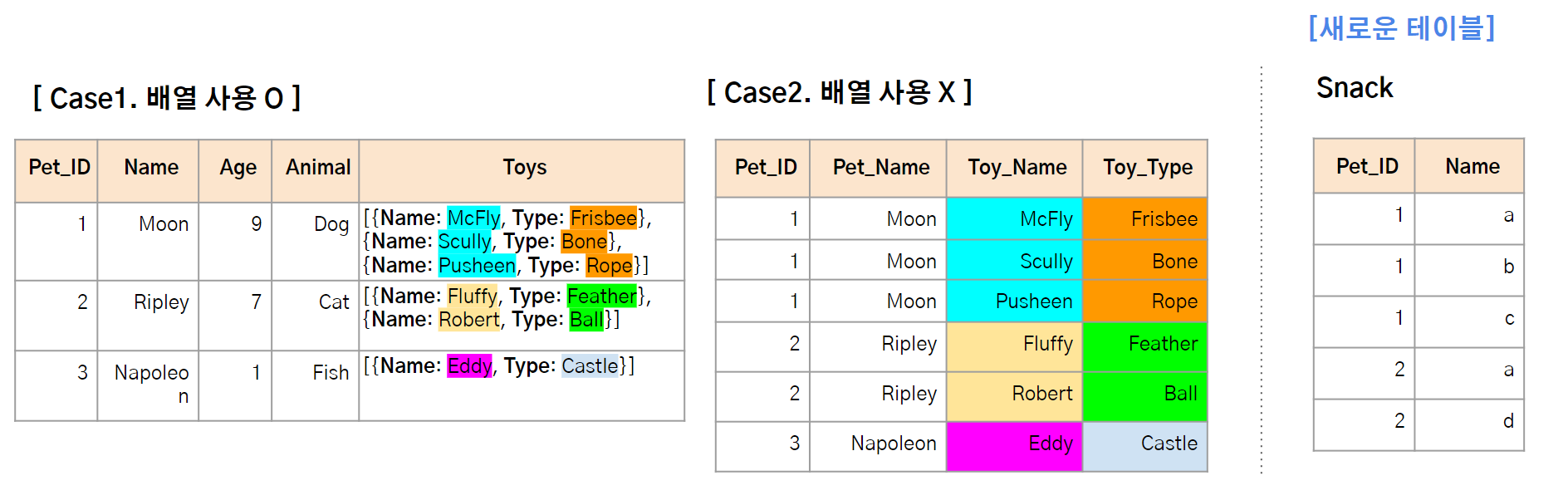
단일 행으로 저장하면 JOIN을 사용할 때도 편하다. 위 두 테이블에 각각 새로운 테이블 Snack을 JOIN 한다고 가정해보자. (key값 : Pet_ID)
- Case 1의 경우, 1:N 대응으로 JOIN을 수행할 수 있지만
- Case 2의 경우, N:N 대응으로 JOIN을 수행해야한다. Pet_ID를 기준으로 Snack Name을 매칭한 결과, 행의 개수가 크게 늘어날 것이다.
책에 언급된 또 다른 예시는 아래와 같다.
A지역에 위치한 기관들의 세금 신고 기록 데이터가 있다고 하자.
매년 한 번 세금을 신고하는 기관이 있는 반면, 같은 해 여러 번 세금을 신고하는 기관도 있다. 만일 다음 번에 이 테이블을 조회할 때, 같은 해에 여러 번 세금을 신고하는 기관도 있다는 사실을 잊어버리면 문제가 생길 수가 있다.
어떤 문제가 발생할 수 있을까? 다시 Pets,Toys 테이블로 돌아와 간단한 예시를 들어보겠다.
어느날 예기치 못한 사고(?) 로 동물들이 가지고 있던 장난감을 모두 잃어버렸다. 그리고, Toys 정보에 Toys_Onsale 이라는 정보를 추가했다고 하자.
Toys_Onsale: 장난감이 현재 쇼핑몰에 판매중인지 여부 (구매가능:1, 구매불가:0)
동물들마다 원래 가지고 있던 장난감을 다시 사주려고 한다. 이때, 가지고 있던 장난감이 모두 단종(Toys_Onsale=0)된 동물이 있을까?
배열 사용 (X) 경우
[ 테이블 명: example ]
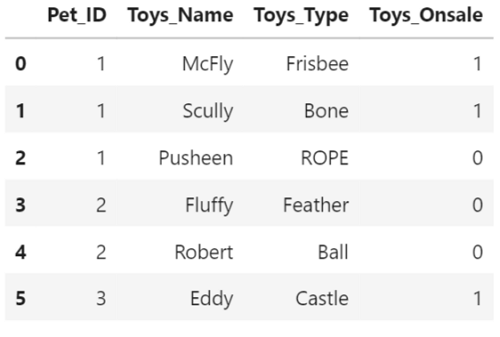
장난감이 구매불가한 조건은 Toys_Onsale = 0 이다.
간단하게는 다음과 같은 쿼리를 작성할 수 있을 것이다.
SELECT
DISTINCT Pet_ID
FROM
example
-- pets가 가지고 있는 toy가 구매 불가한 경우(Toys_Onsale=0)
WHERE
Toys_Onsale = 0 - 결과

하지만 일부 동물은 구매가능한 장난감과 구매불가한 장난감을 동시에 가지고 있기도 하다. (Pet_ID가 1인 동물은 구매가능한 장난감 2개, 구매불가능한 장난감 1개를 가지고 있다.)
"모든 장난감이 구매 불가한 동물"을 찾기 위해서는 어떻게 해야할까? 다음과 같이 배열을 사용해서 확인할 수 있다.
배열 사용 (O) 경우
-- "nested_repeated_toys" : Toys 칼럼에 배열을 사용
WITH nested_repeated_toys AS (
SELECT
Pet_ID,
ARRAY_AGG(
STRUCT(Name, Type, On_sale)
ORDER BY
ID
) Toys
FROM
more_toys
GROUP BY
Pet_ID
)
-- 장난감이 모두 구매 불가 상태인 Pet_ID 조회
SELECT
DISTINCT Pet_ID
FROM
nested_repeated_toys
WHERE
1 NOT IN (
SELECT
On_sale
FROM
UNNEST(Toys)
)WHERE 절에 있는 서브쿼리 SELECT On_sale FROM UNNEST(Toys) 는 아래와 같다. 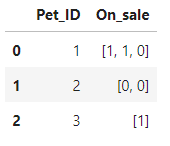
여기서 On_sale에 1이 포함되지 않은 Pet_ID는 2뿐이므로 최종 결과는 아래와 같다.
- 결과

5. 마무리하며
요약하면 데이터를 배열로 저장하는 상황은 1)데이터를 순서대로 저장하는 것이 중요한 경우이거나, 2)반복 가능성이 있는 값들을 단일 행에 저장하기 위함이다. 특히 두 번째 이유는 데이터 무결성 개념과도 연결된다고 하니, DB 개념을 더 공부해야할 것 같다..
6. ref
참고한 자료
- Kaggle Advanced SQL course
참고한 서적
- 빌리아파 락쉬마난, 조던 티가니 지음 / <구글 빅쿼리 완벽 가이드> / 변성윤, 장현희 옮김
