퍼널 정의하고 로그 (다시) 설계하기
1. 프로젝트 소개
팀원들과 딥러닝 모델을 활용한 이미지 복원 서비스를 개발했던 적이 있습니다. 서비스 이용자가 이미지 편집 도중 느끼는 어려움을 파악하기 위해 설문조사를 실시하고, 이를 기반으로 '이미지에서 물체 지우기', '화질 개선하기', '흔들림 제거하기' 3가지 작업을 수행할 수 있는 서비스를 기획했습니다. (데모 영상을 포함한 깃헙 링크는 이곳에 있습니다.)
제가 맡은 역할 중 하나는 유저 로그를 정의하고 데이터베이스를 구축하는 일이었습니다. 데이터베이스를 구축한 목적은 다음과 같습니다.
- 딥러닝 모델을 활용한 서비스라, 배포 이후에 모델 성능을 개선하는 배치 서빙을 계획했습니다. (가능하다면) 사용자의 입력 데이터와 모델이 추론한 결과를 저장해, 추가 학습을 위한 데이터로 활용하고자 했습니다.
- 딥러닝 모델을 사용하려면 서버 자원이 필요했는데, 실제 배치 서빙을 할 수 있을 만큼 서버 자원을 빌릴 수 있는 기간이 길지 않았습니다. 그래도 배치 서빙을 할 수 있다고 가정하고, 모델 성능 개선이 목적인 데이터베이스를 구축했습니다.
2. 전체적인 흐름
'이미지에서 물체 지우기' 작업의 예시입니다.
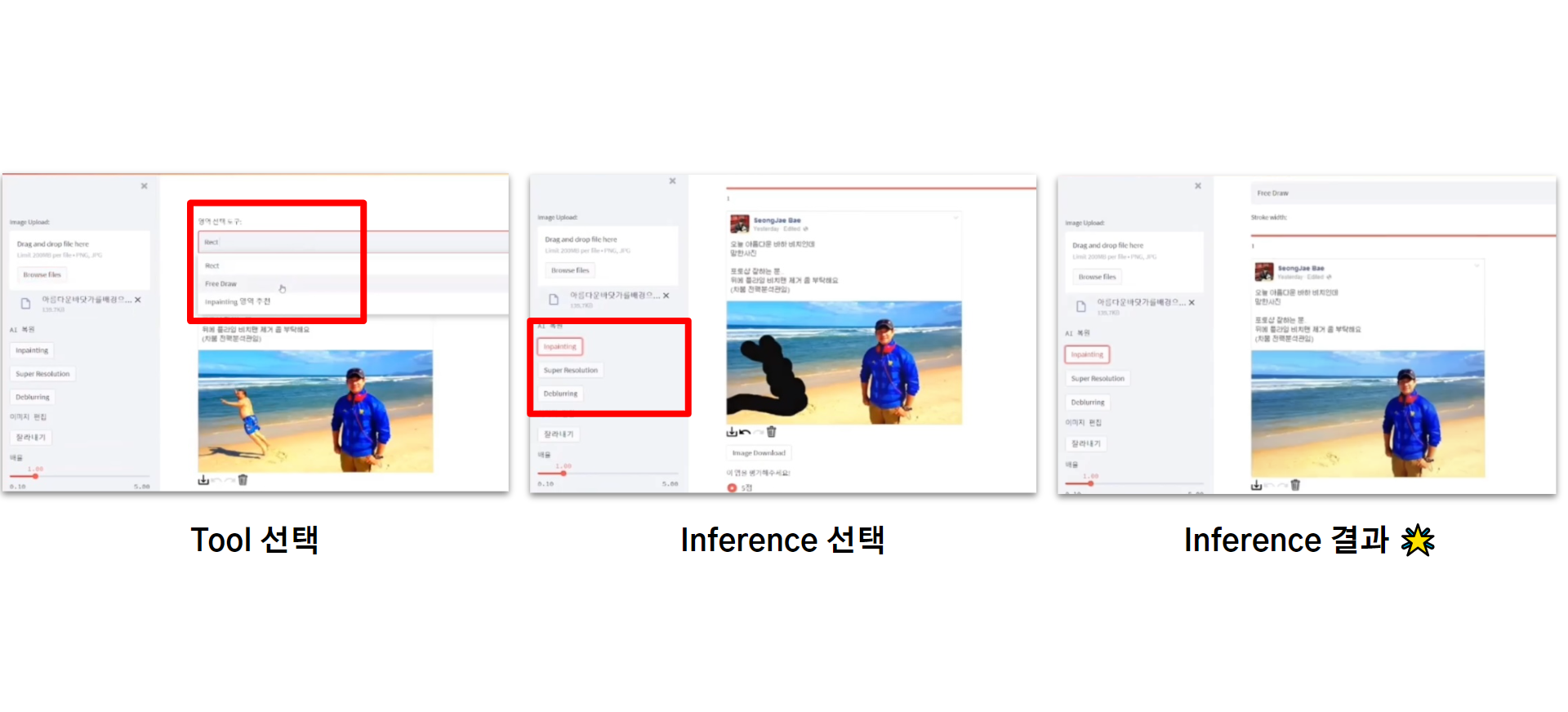
1) 사용자가 이미지를 업로드하면
2) Tool을 선택하고 (직사각형 그리기, 자유롭게 그리기 등)
3) 원하는 Inference 종류를 선택한다 (이미지에서 물체 지우기, 화질 개선하기, 흔들림 제거하기 등)
4) Inference 결과가 나오면 다운로드 버튼을 눌러 저장한다.
5) 결과에 대해 평점을 매긴다.
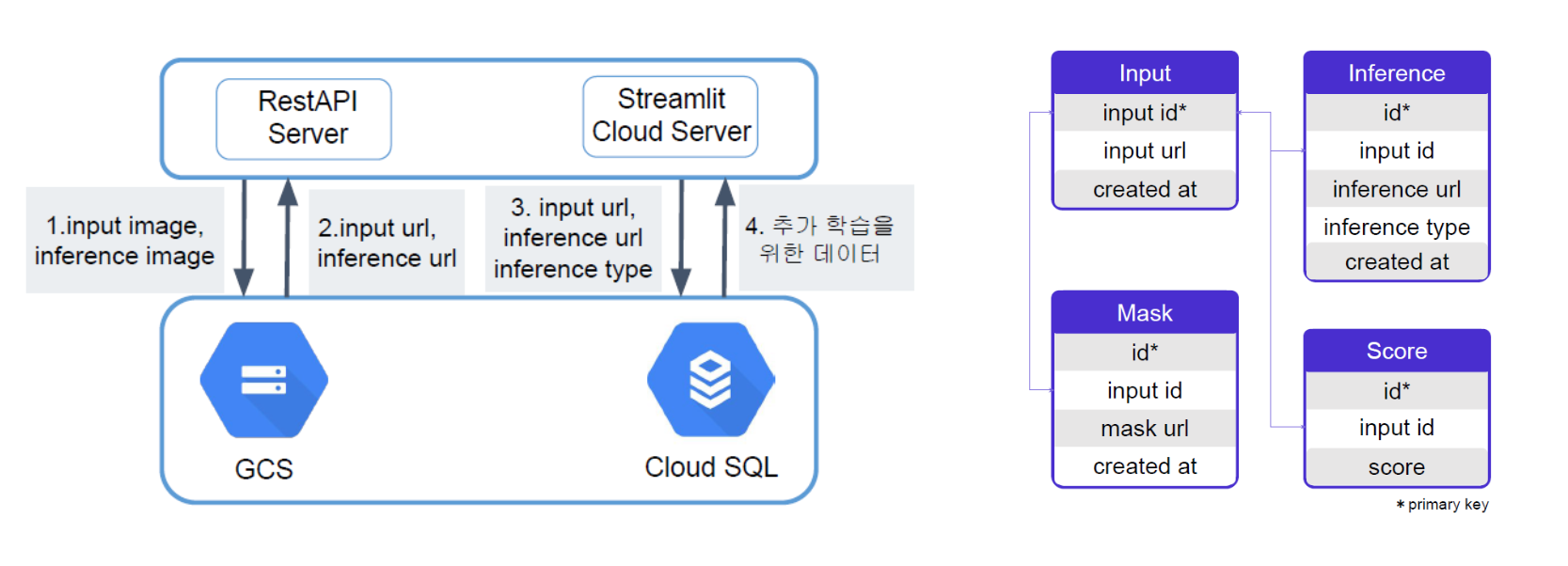
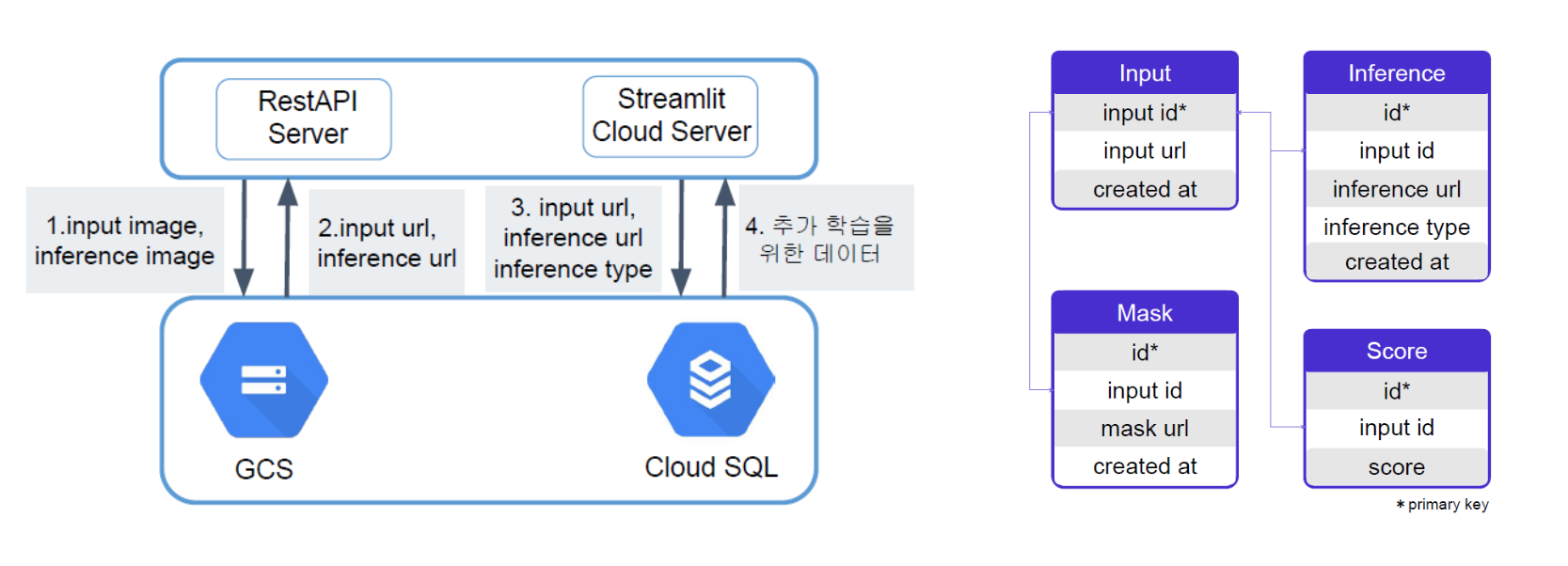
- 앱서버 : Streamlit Cloud
- 데이터베이스 서버 : GCP의 MySQL 인스턴스
- 모델 학습용 이미지 저장 스토리지 : GCP의 Google Cloud Storage
필요에 따라 서버를 각각 스케일업 할 수 있도록 앱서버(Streamlit Cloud Server), 데이터베이스 서버(Cloud SQL), 스토리지(GCS)로 분리하여 설계했습니다.
- 사용자가 이미지를 업로드하고, 원하는 Tool과 Inference를 선택하면
- Streamlit Cloud Server에서 이미지 데이터를 모델에 입력해 추론 결과 이미지가 생성됩니다.
- 추론이 완료될 때마다, Google Cloud Storage에 입력 이미지와 결과 이미지로 구성된 Pair Dataset이 저장됩니다.
- Storage에 이미지 파일이 업로드되면, 이미지 url이 생성됩니다. 입력 이미지 url과 결과 이미지 url을 앱서버에 보내고, inference 작업의 종류(Inference Type)을 함께 데이터베이스 서버에 보내 테이블에 기록했습니다.
- 상단 우측 그림과 같이 총 4개의 테이블을 정의했습니다.
Input: 입력 ID, 입력 이미지 url, 업로드 시간Inference: ID, 입력 ID, 결과 이미지 url, 작업 종류(Inference Type), 결과 이미지가 생성된 시간Mask: 유저가 이미지의 어떤 영역을 지우려고 했는지 기록. 생성 모델의 입력으로 필요.Score: 추론 결과에 대한 유저의 평가점수를 함께 기록.
- 추후에 이미지 자체를 집계하거나 조회할 필요가 없었으므로 데이터베이스에 저장하지 않고 Storage에 따로 저장했습니다. (이미지를 Byte String으로 변환하면 테이블에도 저장 가능하긴 합니다.)
- 상단 우측 그림과 같이 총 4개의 테이블을 정의했습니다.
- 모델을 재학습하는 시점에는 Target Date 기간에 해당하는 데이터를 불러와 배치서빙할 수 있도록 SELECT 문을 작성했습니다.
3. 문제점 혹은 고민 지점
Streamlit 프레임워크를 사용해 빠르게 프로토타입을 만든 후, 직접 테스트하다 보니 몇 가지 문제점을 발견했습니다. 마우스로 일일이 물체를 마스킹하다 보니 시간이 오래 걸렸고, 유저가 물체의 경계를 타이트하게 지울 경우, 모델 추론 결과가 얼룩덜룩한 문제가 있었습니다.
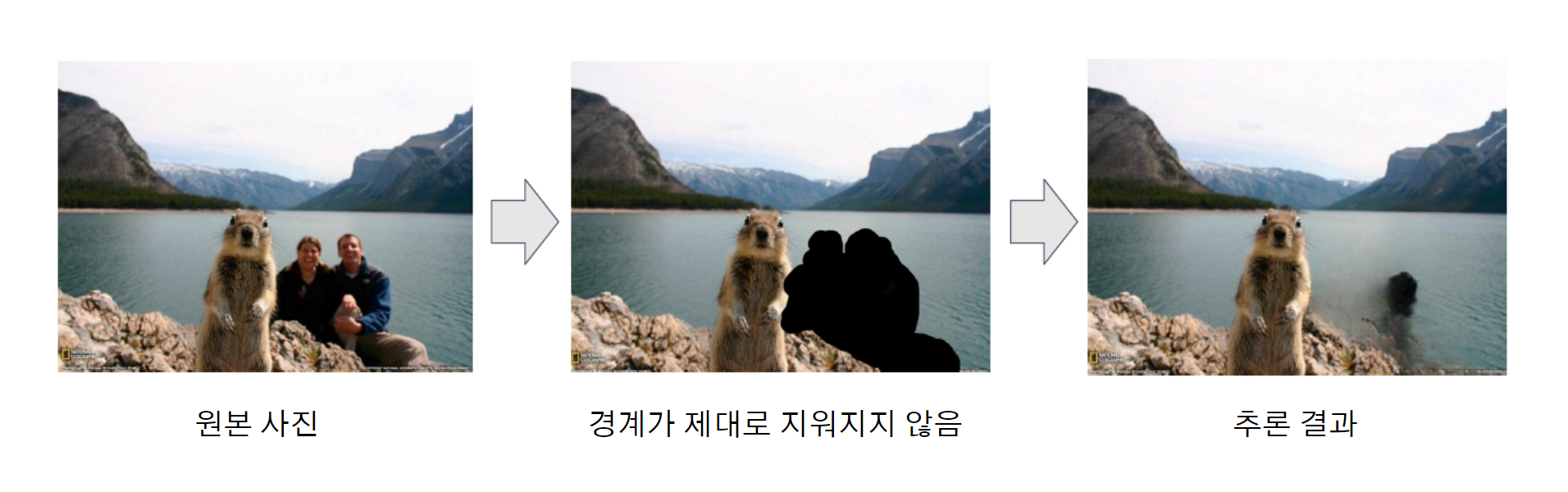
개선 : Segmentation Tool 추가
이 문제를 개선하기 위해, 마우스로 직접 마스킹하는 대신 유저가 지울법한 영역을 Segmentation 모델이 대신 추천해주는 기능을 추가하기로 했습니다. 아래처럼 Segmentation Tool을 사용하면 유저가 이미지에서 지울법한 영역을 제안해주고, 유저는 원하는 영역을 고르기만 하면 되는 식이었습니다.

그런데 프로젝트를 회고하다 보니, 실제로 얼만큼의 개선이 있었는지 확인할 지표가 없었다는 것을 알게 되었습니다. 데이터베이스를 설계한 목적이 '모델의 추가 학습'이었기 때문에, 기능을 추가했을 때 서비스가 개선되었는지 확인할 수 있는 지표, 그리고 지표를 계산하기 위한 유저 로그가 부족하다는 생각이 들었습니다.
프로젝트 이후 프로덕트 분석 기법을 공부하다 '퍼널'이라는 개념을 새로 알게 되었고, 퍼널 개념을 적용하여 유저 로그를 새로 정의해보기로 했습니다.
4. 퍼널 설계
퍼널 분석이란, 유저가 서비스 최초 유입부터 최종 목적지까지 미리 설계한 흐름대로 잘 도착하고 있는지 분석하는 기법입니다. '이미지에서 물체 지우기' 작업의 퍼널은 다음과 같이 정의했습니다.
- 이미지 업로드
- Tool 선택
- Inference 선택
- 이미지 저장
- 스코어 입력
퍼널 설계를 바탕으로 테이블을 다시 정의해보았습니다.
5. 테이블 재정의
중복을 피하기 위해 Fact Table과 Dimension Table로 구분해 정의했습니다. Fact Table은 집계에 기반이 되는 테이블이며 시간이 함께 기록됩니다 (Table 1~ Table 4). Dimension Table은 주로 데이터를 분류하기 위한 속성값이 기록되고 상황에 따라 수정될 수 있기 때문에 따로 분리했습니다 (Table 5, Table 6).
Table 1) Input 이미지 : 유저가 이미지 업로드 시 INSERT
input_id: 입력 ID (입력한 이미지에 해당하는 UUID)input_url: 입력 이미지 urlserver_time: 업로드 시각
Table 2) Tool 클릭 : 유저가 Tool 클릭 시 INSERT
idinput_id: 입력 IDtool_id: Tool IDserver_time: Tool 클릭 시각
Table 3) Inference 클릭 : 유저가 Inference 클릭 시 INSERT
idinput_id: 입력 IDinference_id: 추론 작업 IDinference_url: 추론 이미지 urlmask_url: (모델 학습에 필요한) mask 이미지 urlserver_time: Inference 클릭 시각
Table 4) Save 클릭 : 유저가 Save 클릭 시 INSERT
idinput_id: 입력 IDserver_time: Save 클릭 시각
Table 5) Tool 분류 : 마스터 테이블
tool_id: Tool ID (int)tool_name: Tool 이름 (string)tool_type: Tool 카테고리 (string)
Table 6) Inference 분류 : 마스터 테이블
Inference_id: Inference ID (int)Inference_name: Inference 이름 (string)Inference_type: Inference 카테고리 (string)
6. 분석을 위한 테이블 만들기
데이터를 기록하는 단계에선 위와 같이 Fact Table과 Dimension Table로 분리해두고, 분석하는 단계에서는 분석에 필요한 테이블들을 결합해 비정규화 테이블을 만듭니다.
Segmentation Tool을 추가했을 때, 유저의 작업 시간이 실제로 감소하는지 확인하기 위해 분석을 수행하고자 합니다. Tool 클릭 테이블, Inference 클릭 테이블, Save 클릭 테이블을 결합해 다음과 같은 비정규화 테이블을 생성해보겠습니다.
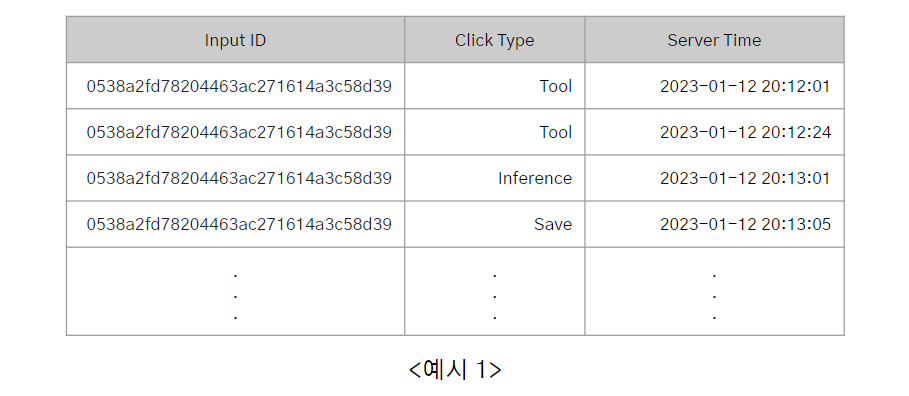
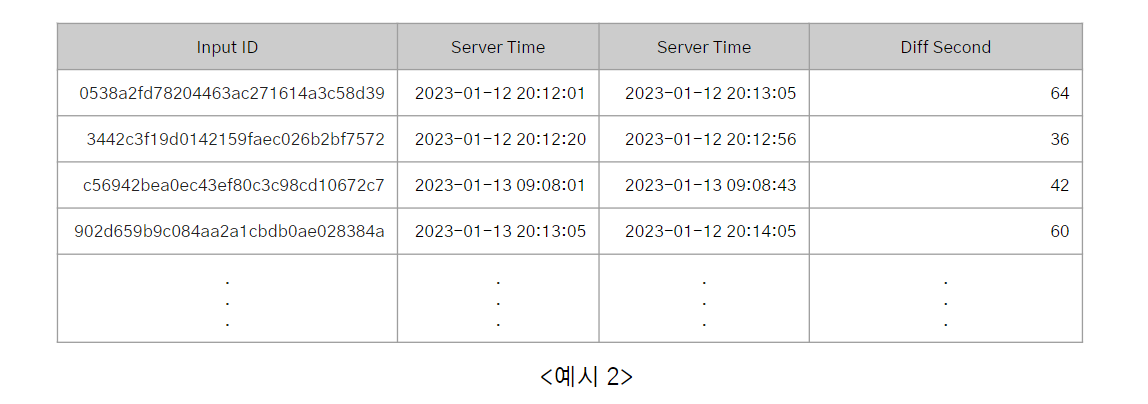
<예시1>은 입력 이미지마다 Tool을 처음으로 클릭하고, 모델에 입력하고, 추론된 결과 이미지를 저장하기까지의 시간 기록을 가져온 테이블입니다. 이 때 Input ID별로 "제일 처음 Tool을 클릭한 시간"과 "이미지를 저장한 시간"을 구하고, Input ID별로 두 시간의 차이(=총 작업 시간 "Diff Second")을 초단위로 집계할 수 있습니다. <예시2>
기존 서비스와 Segmentation Tool을 새로 추가한 서비스의 Diff Second의 평균을 비교해 유저의 작업 시간이 실제로 감소했는지, 감소했다면 어느정도 감소했는지를 집계할 수 있습니다.
7. 정리하며
과거에 진행했던 프로젝트에서 '기능을 추가하여 문제를 개선했다'라고만 정리하고, 지표로 확인하기 위한 로그 정의를 제대로 하지 않았다는 것을 발견했습니다. 퍼널을 기준으로 로그를 다시 정의했고, 팩트 테이블과 디멘전 테이블로 구분해 테이블을 재정의했습니다.
클릭 이벤트 위주로 아주 간단히 로그를 정의해보았는데, 더 다양한 이벤트 파라미터를 고려해볼 수 있을 것 같습니다. AB테스트를 고려한다면 한 명의 유저가 대조군과 실험군에 동시에 들어가면 안 되기 때문에 유저 로그를 더 상세히 정의해야할 것 같습니다. 이밖에 데이터 QA를 자동화하는 방법에 대해서도 더 공부해야할 것 같습니다...!
8. 참고한 자료
- 빅데이터를 지탱하는 기술 / 니시다 케이스케 지음 / 정인식 옮김 / 제이펍
