이전 챕터에서 다룬 PageRank의 다른 version approach를 소개하기 위해 Recommendation application을 소개합니다.
1. Recommendation
1.1. Goal?
- Given User/Item으로 분리되는 bipartite graph가 주어졌을 때
- Goal Proximity(근접성) on graphs
- 왜 이런 목표를 설정하는가?
- Q, P 항목을 구매한 사용자가 있을 때, Q를 구매한 사용자에게 P를 추천하는 데에 이용할 수 있음
- 왜 이런 목표를 설정하는가?
1.2. Proximity에 대한 직관
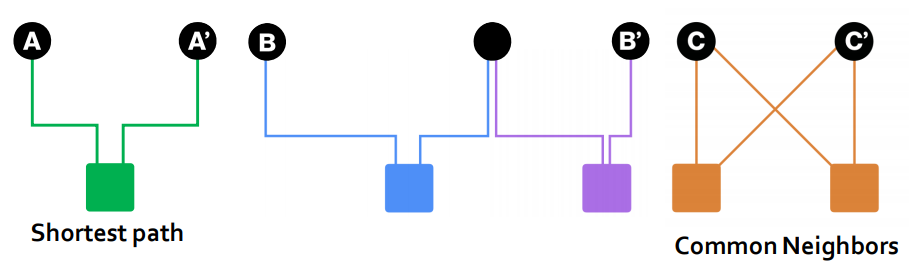
- A와 A', B와 B'중 어떤 것이 더 근접한가?(연관되어있는가?)
- shortest path 관점에서 A와A'> B와B', but C와C'은?
- Common neighbor 관점에서 공통이웃이 2개라는 점은 동일하지만, 전체 이웃 대비 비율로 생각했을 때 C와C'>D와D'이라 할 수 있음
1.3. Proximity on graphs
- PageRank는?
- 중요도를 계산하여 노드에 순위를 매김
- 네트워크 안의
어떤 노드로든, 균등확률로 순간이동 함
- Personalized PageRank
- node 집합 의 하위 노드로만 순간이동!
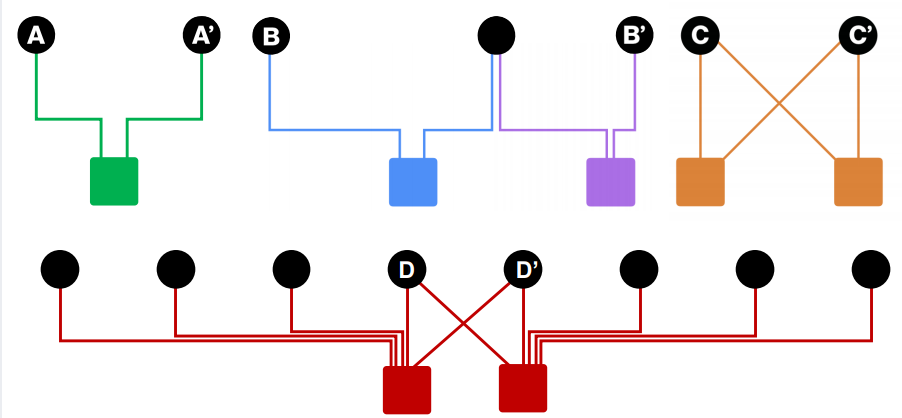
- Proximity on graphs
- Item Q와 가장 연관된 아이템은 무엇인가?
- node 집합 가
단일노드라면? 순간이동을 결정할때마다 항상 시작점 로 점프하게 됨 - 이 개념을 Random walks with Restarts라 칭함
- 즉, 순간이동을 결정할 때,
시작노드로 이동
- 즉, 순간이동을 결정할 때,
2. Random walks with restarts
2.1. Idea
-
기본적인 아이디어 : pagerank와 동일
- 모든 노드는 어느정도 중요도를 가짐
- 중요도가 균등하게 분할되어 모든 에지로 전이됨
-
랜덤워크를 시뮬레이션해본다면?
- Given 쿼리노드(set of QUERY_NODES=) 집합이 주어질 때:
- 임의의 노드로 이동하고, visit count를 기록
- 임의의 확률 ALPHA에 따라 어떤 QUERY_NODES에서 다시 재시작
- 이를 반복했을 때, 가장 높은 visit count를 가진 노드가 QUERY_NODES에 가장 근접하다고 판단할 수 있음
- 👇 psudo code & 간단한 예제
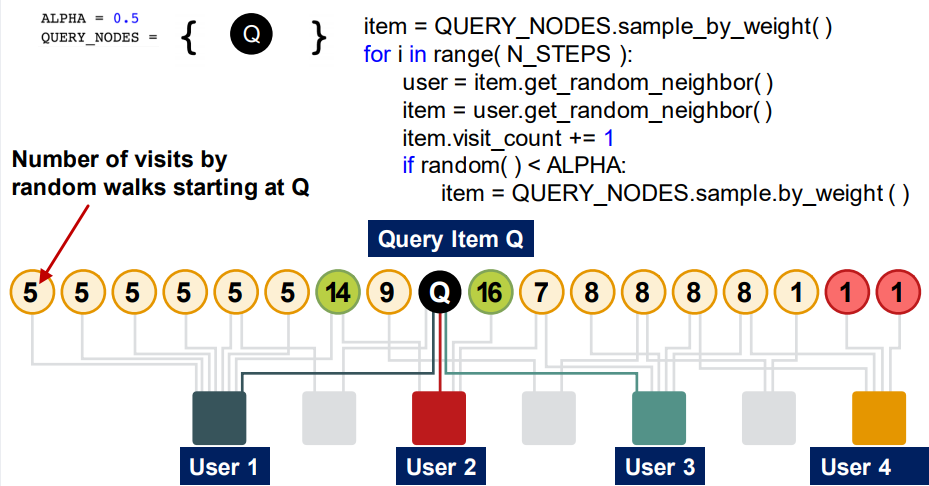
Query Item 에서 시작하여, random walk를 통해 visit count 를 측정한 결과가 높은 item (=14, 16의 visit count를 갖는 item) 들이 유사한 item이라고 판단할 수 있음
- Given 쿼리노드(set of QUERY_NODES=) 집합이 주어질 때:
-
이것은 이해를 돕기 위한 시뮬레이션이며, Page Rank에서와 같이 인접행렬의 거듭제곱을 연산하여 유사도를 효율적으로 측정할 수 있음
2.2. Benefits
- 유사도를 고려할 때 아래의 요소들이 함께 고려됨
- 한 쌍의 노드 사이에 몇 개의 에지(혹은 경로)가 있는지를 고려,
- 직접 연결, 간접 연결의 여부도 함께 고려되고,
- 경로 상의 노드의 degree들도 고려
- 구현이 쉬우며, 확장성이 뛰어나다는 장점!

hongd