참고 영상: CLIP: Image-Text 대용량 데이터로 Contrastive learning하면 zero-shot transfer가 가능하다! | OpenAI Blog 2021 | 김희은
논문: Learning Transferable Visual Models From Natural Language Supervision
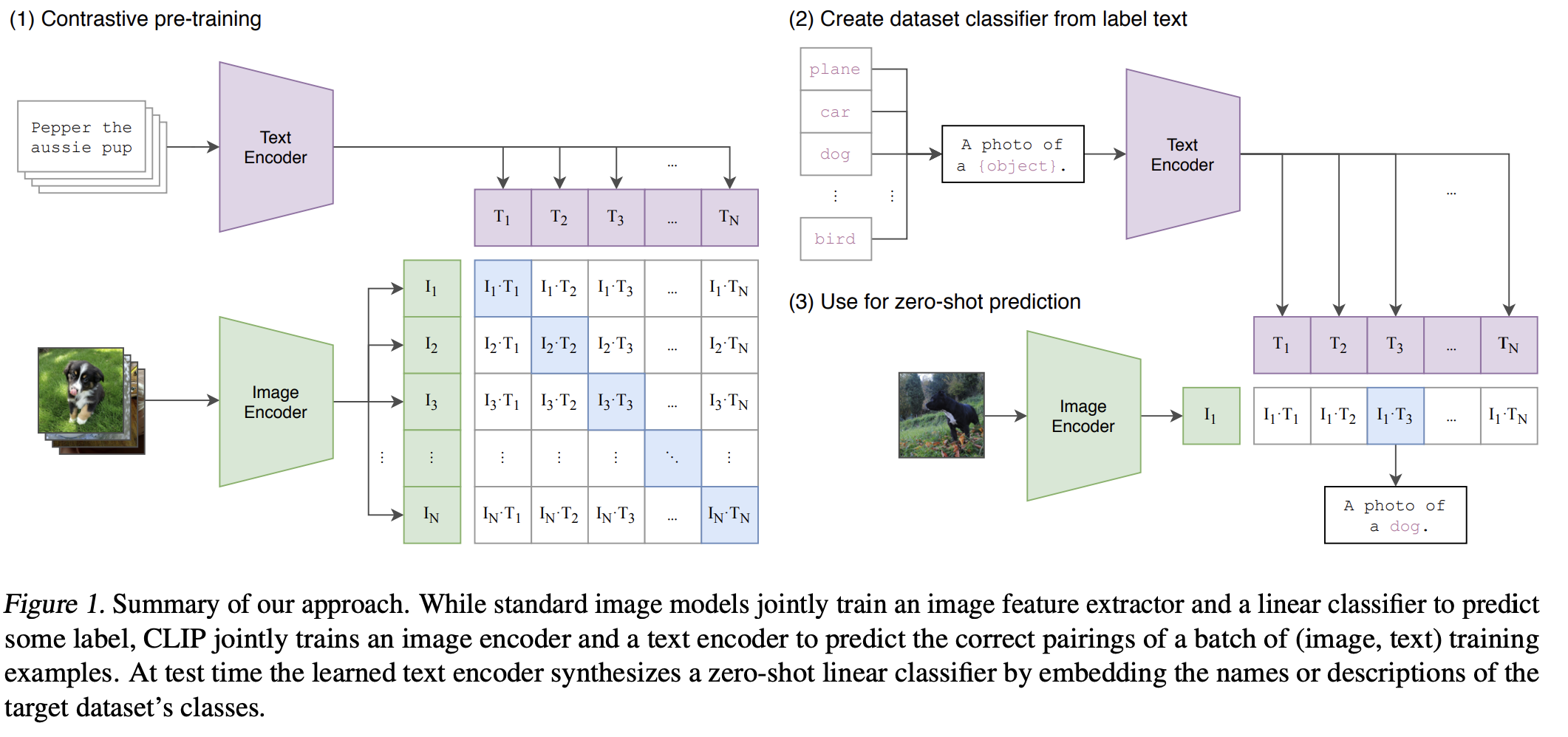
CLIP의 기본 개념은 text로 부터 supervision을 얻어서 이미지 classification을 하는 model을 좀 더 잘 훈련시켜보자의 취지이다.
=> 사실 이 말은 듣기로는 쉬운데 뭔가 원리적으로 접근하자니 애매하다.
- 내 생각: 기본적인 image classification은 CNN기반으로 하는데, CNN은 convolution을 통해 우리가 보는 이미지를 인공지능이 이해할 수 있는 형태의 데이터로 만들어준다. 그리고 정답에 그 데이터를 비교해서 최대한 비슷하게 끔, 이미지를 잘 encoding시킨다. 근데 이제 이 정답이 주어진 label이 아닌 raw text에서 직접 뽑아오겠다는 말인 것 같다.
그럼 이제 이게 어떻게 가능한 지 알아보자.
Abstract
먼저 논문에서는, 이미지에 대한 raw text로 학습된 모델은 다른 fine-tuning 작업 없이도 downstream task(자신이 목표로 한 task)에 적용할 수 있다고 한다. 한마디로 일반화가 정말 잘된다고 볼 수 있다.
1. Introduction and Motivating Work
대규모 text-to-text 모델들이 발전되면서 task-agnostic한 작업들이 성능이 향상되었다.
=> autoregressive와 masked language방법은 특정한 테스크를 학습하지 않아도, 문맥 정보를 학습한다.
이러한 기술들의 발전으로 이제는 web에서 긁어온 NLP dataset이 사람이 직접 labeling한 데이터셋 능가한다. 논문의 저자는 이런 web에서 긁어올 수 있는 대량의 데이터를 vision 모델에 학습시켜 성능을 올리고자 이 모델 구조를 만들었다.
1999년에, image 검색 기술은 발견되었다. model이 image들과 일치하는 text documents에서 단어들과 형용사들을 예측하도록 훈련시켰다.
2007년에는 이미지와 연관된 caption들에서 단어들을 예측하도록 훈련된 분류기의 가중치 공간에서 maniford learning을 통해 이미지 표현에 대한 더 많은 데이터를 학습시키는 것이 가능하다는 것을 발견했다.
2012년에는 저차원의 image feature고 text tag feature들에 대해 깊은 표현학습이 가능하다는 것을 발견했다.
2016년에는 image caption들에서 단어들을 예측하도록 학습된 CNN들은 이미지 표현을 학습하는데 더 유용하다는 것을 입증하였다.
=> 이미지의 제목, 설명 그리고 hastag metadat을 단어 집합 기반의 다중 라벨 분류 과제로 전화시킴. 그리고 이러한 label들을 예측하도록 Alex Net을 학습시켰는데 놀랍게도 ImageNet 기반으로 학습된 애들과 비슷한 성능을 냈다.
2017년에는 이러한 작업을 단어에서 n-grams의 구를 예측하도록 확장했고 이것 또한 이미지 분류에 사용했다.
그리고 2020년에 text로 이미지를 학습하는 작업들의 잠재력을 입증했다. => ViT인듯?
근데 이러한 text로 이미지를 학습하는 모델은 범위는 좁지만 목적에 잘 맞춘 weakly supervised 학습이 더 적합하다. 그래서 제한된 수의 정답이 있는 감독 학습 데이터와 무제한의 비지도학습 텍스트(raw text) 사이에서 현실적인 타협점이 필요하다.
NL은 더 넓은 범위의 시각적 개념들을 표현 가능하며(얘 자체가 표현력이 뛰어나다고 함), 그래서 지도학습이 가능하다. 근데 기존 접근 방식은 고정된 클래스에 대한 softmax 분류기를 사용해서 예측을 수행한다. => 모델의 유연성을 떨어뜨리고 zero-shot 성능 감소.
그래서 이러한 weakly supervised와 원래의 방법의 차이는 규모에 있다.
저자는 인터넷에서 가져와서 4억개의 dataset 쌍을 가져온다. 그리고 ConVIRT의 단순화된 버전을 처음부터 학습시키고, 이걸 CLIP이라고 부르고, 자연어를 supervision으로 사용하여 학습하는게 효율적인 방법이라는 걸 보여줌.
2. Approach
2.1. Natural Language Supervision
일단 natural language로 학습하는 것은 기존의 image 분류를 위해 labeling 하는 것보다 더 확장하기 쉽다. 게다가 annotaition 안해도 되고 인터넷에서 대량의 데이터를 가져올 수 있다.
그리고 natural language로 부터 학습하는 것은 대부분의 자기 지도학습이나 비지도학습 보다 중요한 이점들을 갖는데, 표현을 학습할 뿐만 아니라 그 표현을 자연어와 연결시킬 수 있다는 것이다. => 한마디로 이미지에서 나온 표현들과 자연어의 연결성을 확인해볼 수 있다는 것 같다.
2.2. Creating a Sufficiently Large Dataset
원래는 MS-COCO, Visual Genome, YFCC100M이라는 데이터셋을 사용해왔음.
MS-COCO와 Visual Genome은 사람들이 직접 라벨링한 질 좋은 데이터 셋이지만, 적다.
그리고, YFCC100M은 1억게의 사진들이 있는데에 반해 image의 metadata(title, description etc..)가 거의 없거나 다양한 quality로 되어있는게 문제임.
그래서 영어로 되어있는 title과 description을 가진 이미지만 골라내면 1500만개로 6배는 줄어든다.
근데 자연어로 학습하기 위해선 많은 양의 데이터가 필요하므로 필자는 인터넷에서 데이터를 가져오는 방식을 택한다. 그래서 4억개의 데이터셋을 구축한다.
필자들은 wikipedia 에서 500,000개의 query를 가져오고 각 query당 최대 20,000개의 (image, text)pair을 붙여주었다. 그리고 이러한 dataset에 WIT(WebImageText)라는 이름을 붙였다.(구려..)
2.3. Selecting an Efficient Pre-Training Method
필자들은 효율적인 pretraining 방법으로 뭘 택했을까?
초기에 image CNN + text transformer을 택함. 근데 생각보다 너무 별로임.
이러한 방법은 이미지에 대한 정확한 words를 예측하느라 어려움. 그래서 필자들은 이미지와 text 쌍이 서로 다른지 비슷한 지를 비교하는 contrastive objective를 활용하기로 했다. 한마디로 이미지에 맞는 단어 하나하나를 고르는 것보단 이미지에 맞는 문장을 선택하는 것이 좀 더 효율적이고 성능도 비슷하다는 것.
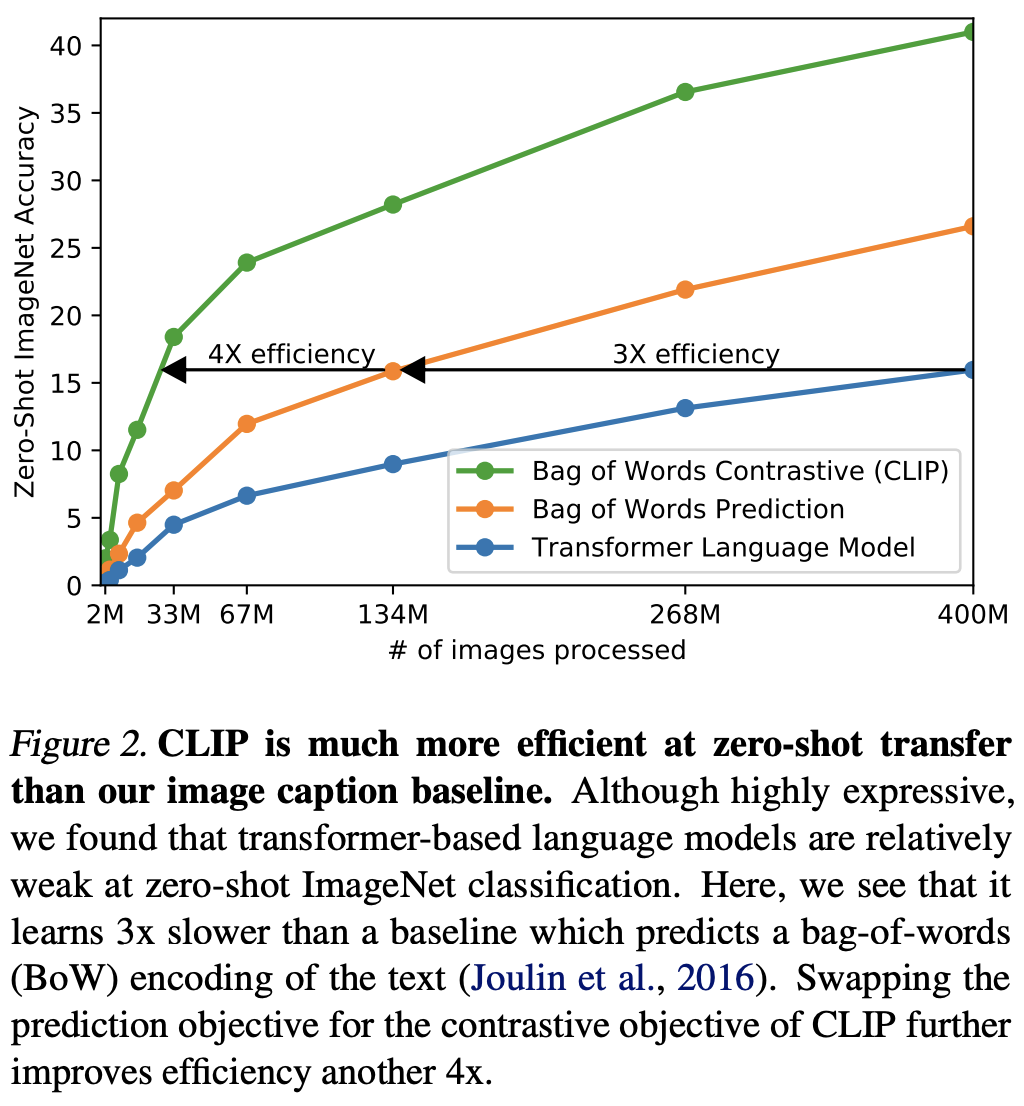
이 방법으로 효율성이 4배정도 증가했다고 함.
그래서 CLIP은 N(image, text)쌍이 주어졌을 때, N x N의 가능한 쌍중 맞는 쌍들을 예측하는 식으로 학습한다.
이걸 위해, image encoder와 text encoder가 N개의 진짜 쌍의 image data와 text data의 임베딩된 값들의 cosine similarity를 최대화하고, 나머지 개의 다른 쌍들에 대해서는 cosine similarity를 최소화하는 방법으로 학습하는 방법으로 multi-modal embedding space를 학습한다.
- 필자는 이러한 similarity에 대해 symmetric cross entropy loss를 최적화한다.
- 필자는 이 논문에서 deep metric learning을 사용한다.
Deep Metric Learning: 딥러닝 모델로 거리 공간을 학습한다.
- CLIP에서는 비선형 projection과 선형 projection 사이의 성능 차이가 별로 없어서 필자는 선형 projection을 선택함(좀 더 가벼워서)

2.4. Choosing and Scaling a Model
이미지 Encoder
- Modified Resnet-50: ResNetD + antialised blur pooling + global average pooling -> attention pooling(이미지 전체에서 feature의 평균을 내는 것이 아닌 어디가 중요한지를 학습해 그 부분에 더 집중, Query == global average pooling)
- ViT: 최소한의 수정 => 합쳐진 patch들에 대한 추가적인 layer normalization + transformer전에 positional embedding + 초기화 방법 다름.
텍스트 Encoder
- Transformer: 6300만개 paremter + 12-layer 512-hidden size(512차원의 hidden vector) + 8개의 attention heads.
49,152개의 voca를 byte pair encoding에 대해 동작함(BPE: 자주 같이 나오는 문자나 단어 조각을 묶어서 새로운 서브 워드 토큰으로 만듦)
2.5. Training
ResNet 5개: ResNet-50, ResNet-101, EfficeintNet-Style의 ResNet(width, height, resolution을 균등하게 늘린 애들, 4x, 16x, 64x 연산량 사용).
ViT 3개: ViT-B/32, ViT-B/16, ViT-B/14
Optimizer: Adam optimizer
Mixed-precision: 학습 가속화 하고 memory를 아껴준다.(FP32->FP16으로 바꿔서 메모리 최적화)
