논문: CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip
Retrieval
이번에는 CLIP 개념을 도입하여 tex와 Image사이의 연관성을 넘어, text와 video 사이의 연관성에 관한 논문을 살펴보자.
Abstract
이번 논문 그리고 CLIP4Clip은 video-text retrieval(text로 영상 찾기)의 역할을 한다. CLIP의 발전을 토대로 이 모델 또한 end-to-end 방식으로 학습을 진행한다.
필자는 4개의 질문을 던진다.
- image feature이 video-text retrieval 기술에 충분할까?
- CLIP을 기반한 큰 규모의 video-text 데이터 셋에 대한 post-pretraining이 성능에 얼마나 영향을 줄까?
- video frame들 사이에 시간적 의존성을 모델링하기 위한 실용적인 mechanism은 무엇인가?
- video-text retrieval task에 대해 model의 hyper-parameter의 민감성.
Introduction
필자는 visual & language understanding에 대한 multi-modal을 위한 기본적인 연구 작업을 input을 기준으로 2가지로 나누고 있다.
- Raw video(pixel-level)
=> pixel-level의 접근은 raw video를 입력으로 Model을 학습한다. 이러한 접근은 video feature 추출기를 짝지어진 text와 함께 학습한다. 반대로 feature-level 접근은 적합한 feature 추출기에 의존해서 video encoder는 학습이 불가능 하다.- Video feature(feature-level)
=> => 대부분, pretrain model들은 video-text dataset들에 대해 학습되었기에, feature-level이라고 본다. 이 모델들의 입력은 사전학습된 비디오 feature 추출기를 통해 생성된 video feature들이 들어간다. 이러한 경우, 입력에 raw video가 들어가면 너무 느리고 실행 불가능하다. 그럼에도, 큰 규모의 dataset덕에 사전 학습된 모델들은 video-text retrieval에서 상당한 성능 향상을 보여준다.
그리하여, pixel-level 접근에 관심이 모였지만, 비디오 입력으로 인한 초과된 계산량을 줄이는게 문제였다. 이러한 해결책으로는 비디오를 부분적으로 sample하는 방법이 나왔었다. 실제로 효과도 있었다. 이미지에서부터 multi-frame들까지 학습하는 방법은 효과적이었다.
하지만, 필자는 새로운 video-text retrieval을 학습시키는 것이 아니기에, CLIP에서 어떻게 해야 vieo-text retrieval로 전이학습시킬 수 있을 지를 고민한다.(그래서 이름도 CLIP4Clip인 것이다.)
CLIP4Clip은 3가지 접근 법(parameter free type, sequential type, tight type, 뒤에서 얘기하겠다.)을 simliarity calculator을 고안한다. (video와 text의 유사도를 판단한여 retrieval task를 할 수 있도록 하려고)
필자가 강조하는 것은 자신들은 다른 논문들과 다르게 similarity calculator을 고안하였다고 주장한다.(end to end 방식 가능)
- 사전학습된 CLIP을 기반으로 similarity 계산에 대해 세가지 메커니즘
- CLIP을 큰 규모의 noisy video-language daaset에 학습시킴.
필자가 발견한 insights
- 하나의 single image는 video-text retrieval을 위한 video encoding에 부족하다.
- CLIP4Clip을 위해 큰 규모의 video-text 데이터셋에 대해 post-pretraining시키는 건 요구되고 zero shot 예측 즉 한번도 보지 않은 데이터에 대해서 예측하는 것에서도 좋은 성능을 보인다.
- 잘 학습된 CLIP을 가지면, 새로운 parameter들을 추가하는 것보다 작은 데이터셋들에 대해 video frame들을 mean pooling시키는게 낫다. 큰 데이터셋 들에 대해서는 시간적 의존성을 학습하기 위해 self-attention layer같은 더 많은 parameter들을 추가하는 것이 좋다.
- hyper parameter들을 잘 세팅했다.
Related work
관련된 작업들...
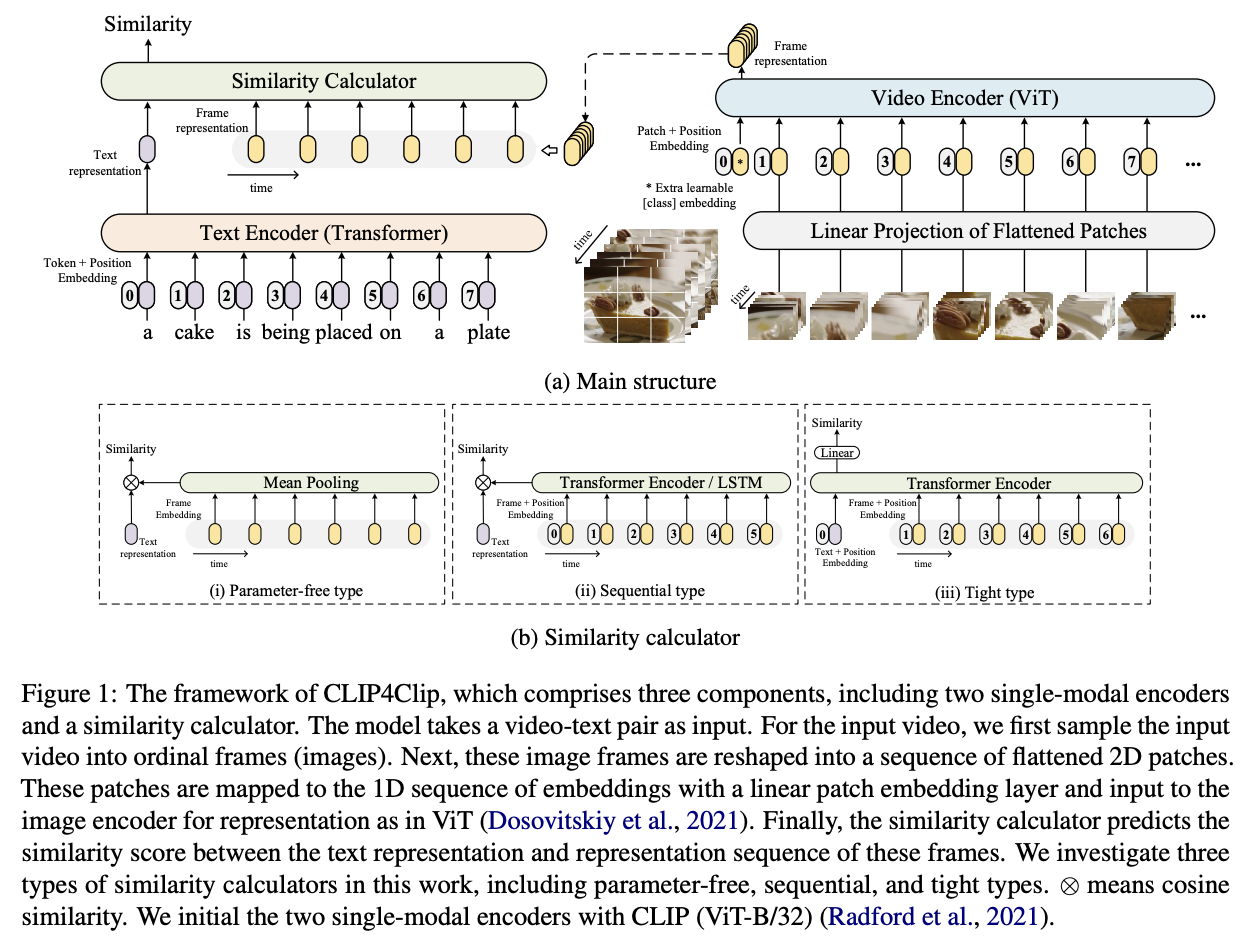
Frame work
- : video 집합(는 에 속하는 video 하나)
- : caption 집합(는 에 속하는 caption 하나)
필자의 목표는 video와 caption사이의 유사도를 계산하기 위해 function 를 학습하는 것.
- text-to-video retrieval: 주어진 문장(query caption)에 대해서 유사도 점수에 따라 모든 video들을 정렬하는 것이 목표.
- video-to-text retrieval: 주어진 영상(or Clip)에 대해 유사도 점수에 따라 모든 caption들을 정렬하는 것이 목표.
한마디로, 의 목표는 연관된 video-text쌍에는 높은 유사도를 관련 없는 쌍에는 낮은 유사도를 주는 것이다.
(는 연속된 frame들로 나타남. , 이렇게 frame들이 직접 input으로 들어가니 E2E방식으로 학습되는 거임.)
Video Encoder
video 표현을 얻기 위해,
video clip에서 frame들 추출 -> frame들을 video encode로 encoding -> 연속된 feature들을 얻음
- Video Encoder: 12개의 layer들을 갖고 32 patch size를 갖는 VIT-B/32(Pretrained CLIP)
- ViT
- 겹치지 않게 image patch들을 추출
- patch들을 1차원 토큰들로 linear projection시킴.
- 그리고 각 patch간의 상호성을 파악하기 위해 transformer 구조를 사용
- 이렇게 나온 애들이 representation이 됨.
- [class] token: 얘는 맨 앞에 무작위로 임베딩 되는 token으로 이미지 patch들의 전반적인 요약본이라고 생각됨.
이렇게 (video)에서 생성된 표현을 저자는
로 나타낸다.
필자는 2가지 linear projection방법에 대해서도 얘기하는데,
- 2D linear
- 각 2D frame patch를 독립적으로 embed한다.
- 그래서, frame들 간의 시간 정보를 무시한다.(뭐가 먼저 들어온 frame인 지에 대한 구분이 없음)
- 3D linear
- 시간 정보까지 포함해서 embed함.
- 3D convolution을 사용.(kernel=[h x w]->[t x h x w], t: time, h: hegiht, w: width)
Text Encoder
-> CLIP에 있는 거 그대로 사용한다(cpation representation 만들어줌.)
- Transformer
- 12개의 layer, 임베딩 차원은 512, 8개의 attention head.
- transformer 마지막 layer에 [EOS]token에 출력을 caption 의 feature representation으로 사용.
그래서 필자는 (caption)에서 생성된 표현을
로 나타낸다.
Similarity Calculator
- video representation:
- caption representation:
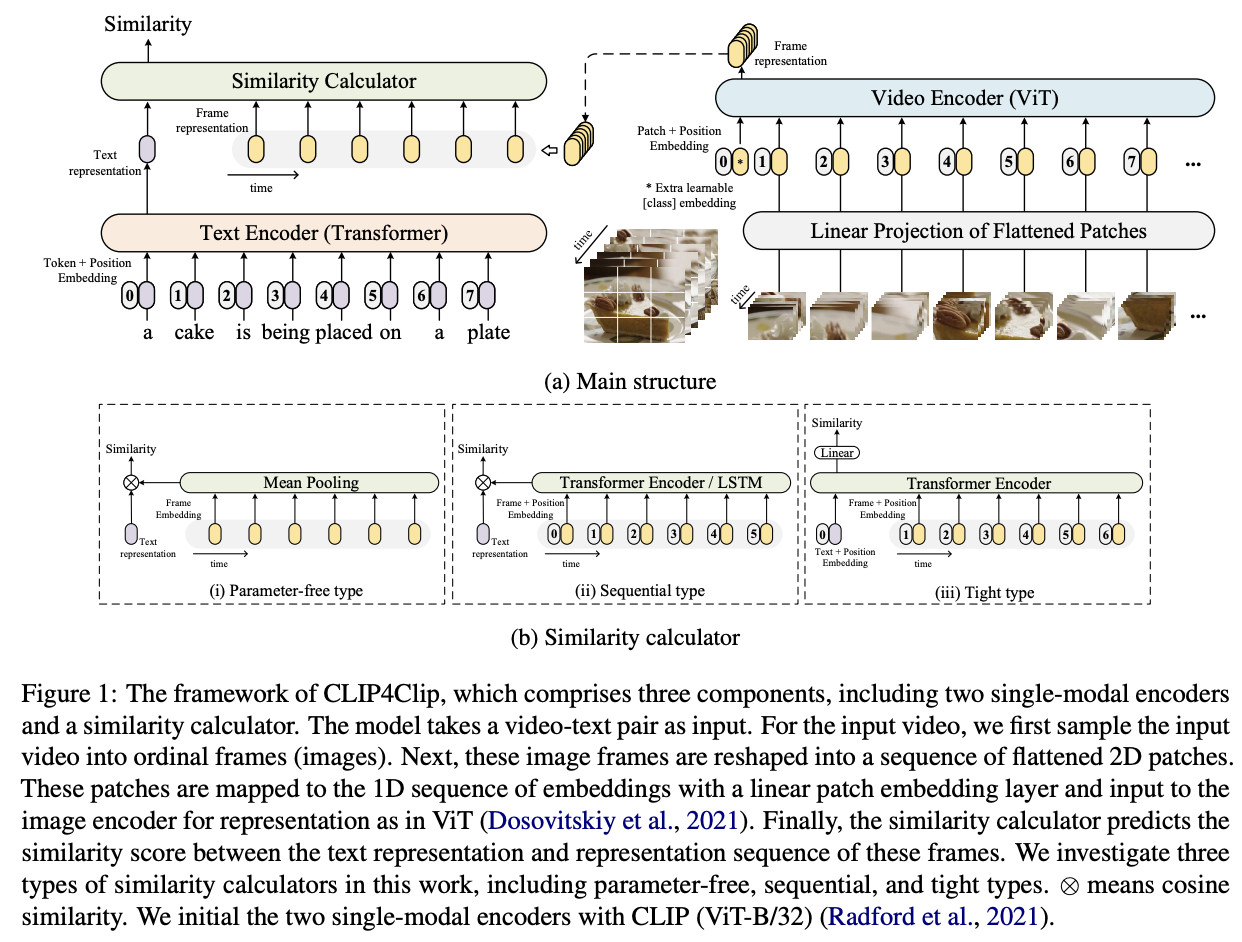
안정적으로 유사도를 계산하기 위해, module이 새로운 parameter을 추가하는 지 안하는 지에 따라 세가지 category로 계산법을 나눈다.
- parameter-free 접근(meaning pooling)
- 2개의 다른 접근법(sequential type, tight type)
- parameter-free & sequential type => loose type(비디오와 텍스트를 각각 독립적으로 encoding하고, 최종 벡터끼리의 유사도만 계산)
- tight type => 텍스트와 비디오 프레임을 같은 transformer에 넣고 linear projection을 사용해서 similarity를 계산한다.(이를 위해, 새로운 weight를 학습해야함)
Parameter-free type
일단, mean pooling을 사용하여 모든 frame들의 feature을 average frame을 얻기 위해 통합한다.
그 후, cosine similarity를 사용하여 유사도 함수 를 정의한다.
Sequential type
mean-pooling은 frame들 간의 sequential 정보를 무시하는 경향이 있다.
필자는 이러한 방법에 대해 2가지를 제시한다.
- LSTM
=> - Transformer encoder(with position embedding P)
=>
=> 이렇게 하면 는 이미 temporal information을 내포한다.
이후에, parameter-free type과 같은 방법으로 와 를 구한다.
Tight type
위의 2개와 다르게 Tight type은 multimodal interaction을 위해 Transformer Encoder을 사용한다. 그리고, linear layer을 사용하여 유사도를 구한다.
처음에, Transformer Encoder은 caption representation()와 frame representation()를 연결한다.
-
- P: position embedding
- T: 텍스트인지 비디오인지 구분하는 embedding
그후, 출력 첫번째 token()에 2개의 linear projection layer와 하나의 활성화 함수를 해줘서 유사도 점수를 구한다.
Training Strategy
Loss Function
- : (video, text) or (video clip, text)쌍
한마디로 video B개, text B개의 유사도를 구해야한다.(B x B)
필자는 여기서 이러한 유사도 점수들에 대해 symmetric cross entropy loss를 사용한다고 한다
- video-to-text:
- text-to-video:
=> 전체 식만 보면, 직관적으로 와닿지 않을 수 있으니 조금의 설명을 보태자면 일단 video-to-text의 값은 결국 video가 주어졌을 때, 전체 text에 대해서 연관된 text의 비율(?)을 구함 그리고, 아래는 text가 주어졌을 때, 전체 video에 대해서 연관된 video의 비율(?)을 구하고 이 2개를 더한게 결국 손실값이 되는 거다. 결국 이 손실값을 최소로 하기 위해서는 연관된 text와 video의 similarity값이 커져야하는 것이다.
Frame Sampling
frame을 직접적으로 입력해주는 것만큼, frame sampling 전략은 중요하다.
이걸 위해서, 필자는 정보의 충분성과 계산의 복잡성(특히 메모리 사용량) 사이의 균형을 고려한다.
영상의 sequential information을 고려하여, uniform sampling strategy를 선택한다.(1초당 하나씩 뽑기)
Pre-training
video에서 temporal feature을 학습하는 것은 필수이기에, 필자는 Howto100M dataset으로 CLIP4Clip model을 post-pretraining 시켰다.
Experiments
놀랍게도, 3D patch linear이 2D patch linear보다 더 안좋은 성능을 보인다. 3D patch linear은 영상의 temporal information도 포함하는데 왜 이렇게 되는 걸까?
=> 필자는 아마 CLIP이 2D linear 로 학습되었기에, 이를 transfer한 CLIP4Clip 모델도 2D linear projection이 더 성능이 좋았다고 판단한다.
