논문: TeachCLIP: Multi-Grained Teaching for Efficient Text-to-Video Retrieval
이번 논문은 X-CLIP을 좀 더 업그레이드한 버전의 논문이다.
이전에 X-CLIP은 multi-grained(coarse-grained, fine-grained, cross-grained)를 반영하여 성능을 올렸지만, 그만큼 계산량이 많아져서 속도가 느리다.
이 논문은 CLIP4Clip model을 X-CLIP 정도의 성능을 내면서 더 빠르게 동작할 수 있게끔 해준다.
그리하여, 이를 위해 Knowledge distillation(지식 증류)를 사용한다.
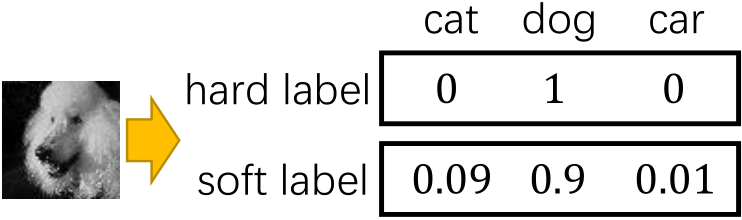
- Knowledge Distillation: 미리 학습시킨 Teacher network의 출력을 내가 사용하고자 하는 작은 모델인 student network가 모방하여 학습하게 해서, 더 적은 parameter로 성능을 올리는 방법.
- 나중에 나올 hard label과 soft label은 이런 식으로 생각하면 편하다.
그럼 이제 논문을 살펴보자.
Abstract
필자는 X-CLIP, TS2-Net 그리고 X-Pool과 같은 무거운 model들로부터 상대적으로 가벼운 모델인 CLIP4Clip을 학습시킴으로써 multi-grained을 가진 TeachCLIP 모델을 제안한다.
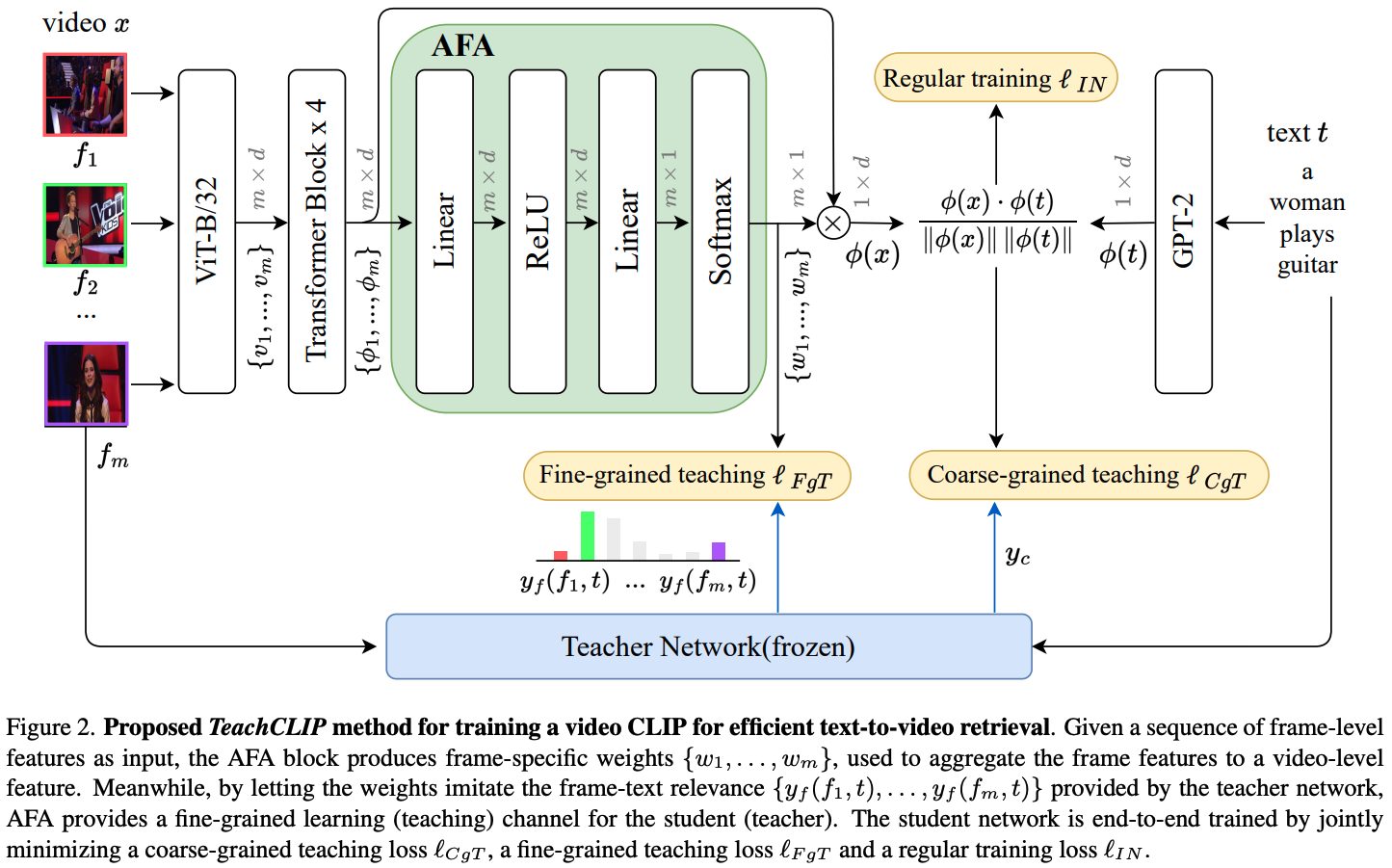
필자는 student(CLIP4Clip)의 학습 용량을 높이기 위해 Attentional frame-Feature Aggregation(AFA) block을 사용한다. => 애들은 탐색 단계에서 추가적인 용량이나 계산이 필요 없도록 설계됨.
-> AFA에서 생성된 가중치들은 공통적으로 frame-level feature들을 결합하기위해 사용된다. 그리고 teacher network에서 추정된 frame-text 연관성을 모방하게 하려고 사용된다.
- AFA => fine-grained channel을 제공함.
Introduction
CLIP(Image와 text를 같은 feature space로 Encoding) -> CLIP4Clip(frame와 text를 동일한 feature space로 Encoding)->X-CLIP, TS2-Net, X-Pool(더욱 fine-grained frame-text 유사도들을 고려, 그 대신 저장공간과 계산량이 매우 큼.)
그래서 필자는, CLIP4Clip과 최근 CLIP 기반의 연구들과의 차이를 줄이기로 생각했다. => knowledge distillation을 통해
TeachText - T2VR(video 수준의 지식 증류를 위해 고안되어서 fine-grained 유사도를 효율적으로 구하는 법은 모름.)
CLIP4Clip은 vidoe 수준과 frame 수준의 soft label들이 필요하다.(탐색 단계에서는 추가적인 공간이나 계산량이 필요없을)
=> 이걸 위해서, 필자는 Attentional frame-Feature Aggregation(AFA)를 제안했다.(결국, 이 개념이 핵심인 것)
- input: a sequence of frame-level features
- AFA=> frame-specific 가중치들을 만듦.(frame feature들을 video수준의 feature로 통합하기위해 사용됨.)
이러한 block은 새로운 것은 아닌데, 필자는 이 block이 frame feature들에 attentive weights를 부여해줄 뿐만 아니라, 그 가중치들이 teacher network에서 추정된 frame-text 연관성을 모방하게 해주었다.
=> 고로, AFA는 fine-grained learning channel을 제공해주는 거임.
논문에서 나오는 3가지 기여
- 필자는 CLIP4Clip과 가장 최신의 CLIP기반 방법들의 성능 차이를 줄이려는 연구를함.
- 필자는 CLIP4Clip에 탐색 단계에서 추가적인 저장공간이나 계산량이 추가되지 않는 AFA block을 추가하여 CLIP4Clip이 상대적으로 무겁지만 성능은 좋은 X-CLIP, TS2-Net, X-Pool모델들로부터 학습할 수 있도록 함.
- 다양한 데이터셋으로 실험함.
Related Work
T2VR(Text-to-Video Retrieval), Knowledge Distillation
Proposed TeachCLIP Method
Problem Setup
필자는 일단 시작으로 2가지 종류의 CLIP-based T2VR 모델들을 제공받는다.
- 첫 번째 종류 => video-text matching을 위해 video 수준의 feature들을 사용함(저장공간과 검색 속도에 효율적이다.)
- 두 번째 종류 => fine-grained cross modal matching에 의존함(첫번째 것보다 더 정확함, 그 대신 당연히 더 무겁다.)
그래서 필자는 첫 번째 것을 student로 두 번째 것을 teacher로 본다. 그래서 teacher에서 나오는 multi-grained soft labele들로 student를 학습시켜 성능을 향상시킨다.
The Student Network
- Student Network: CLIP4Clip
x: (m은 frame의 개수)
x => CLIP4Clip(ViT) -> (size: m x d) => Transformer blocks(4 layer, position encoding) -> => mean-pooling -> : video feature
근데, 이전에도 말했듯이 mean-pooling 방식은 각각의 frame들을 동일하게 보기 때문에, 이 mean-pooling을 Attention frame-Feature Aggregation(AFA)으로 바꿔줄 필요가 있음.
고로,
=> AFA -> (m-dimensional nonnegative weight)
- 는 frame 의 중요도를 반영한다.

- Total Flow
vido-to-frames(x) -> => ViT -> => 4 Transformers(Positional embedding) -> => AFA -> => -> : video feature
결국, 어떻게 보면 frame feature들의 평균값을 구해서 그걸 Video feature로 구하는 개념이지만, 중간에 어떤 frame이 좀 더 가중치를 가져갈 지(fine-grained)를 teacher모델을 통해서 알 수 있기에 multi-grained 방식으로 보여진다.
Multi-grained Teaching
제안된 mutli-grained teaching(MgT)는 기존의 SGD(stochastic gradient descent)절차를 따른다.
b개의 vidoe-text 쌍()에서 mini-batch B는 주어진 학습 데이터셋에서 무작위로 sample된다.
이러한 무작위성이 각 video와 연관 없는 text들을 고려하게 해준다.
결국 필자는 (와 의 cosine 유사도)를 갖는다. (아래가 i면 Video, j면 text임)
고로, i번째 행인 는 video 와 모든 batch에서 b개의 text들 사이의 유사성 점수를 저장한다.
MgT를 하기 위해서 video 와 text 을 고려하는 teacher network로 부터 2개의 출력을 원한다.
즉, 와 의 coarse-grained relevance score 와 frame당 fine-grained relevance score 을 원한다.
-> 와 둘 다 이전에 말했던 모델들로부터 얻을 수 있음.
필자는 에 softmax를 적용한다고 가정한다.
Coarse-grained Teaching
Coarse-grained Teaching은 teacher network에서 예측된 video수준의 soft label들로 student network를 지도 학습 시키는 방법이다.
원래는 TeachText의 huber loss를 사용하였는데, 이 방법은 괜히 knowledge distillation의 어려움만 증가시키기 때문에,
이 대신, student의 출력과 teacher의 출력사이의 Pearson's distance 를 최소화 시키는 방법을 택한다.
=> 이유는 Pearson's distance는 입력값의 규모나 위치의 변화에도 변함이 없는데, 이러한 성질 덕분에 student network의 유사도 점수와 teacher network의 유사도 점수가 아예 똑같지 않아도 각 Video-text 쌍의 유사도 점수의 순서는 같게 할 수 있기 때문이다.
필자는 이러한 를 coarse-grained teaching loss인 를 사용하여 최적화 한다. (CgT: Coarse-grained Teaching)
특히, video 의 loss는 로 계산된다.(: softmax)
같은 방식으로 text 의 loss는 로 계산된다.
그래서, 손실함수는 결국
으로 나타낼 수 있다.
Fine-grained Teaching
자 이제, frame 수준의 feature들()에 곱해줄 m개의 attention weight들()을 만들어주는 AFA block에 대해서 살펴보자.
네트워크가 스스로 학습하게 하는 것 대신, 필자는 teacher network의 fine-grained relevance information으로 weights와 연관된 학습 과정을 따라가게 한다.(위에서 말했던 것)
=> 직관적으로는, 주어진 text와 더 연관된 frame에는 더 많은 가중치를 주도록 하는 것이다.
그래서 필자는 각 연관된 video-text pair 당 teaching loss 를 계산한다.(AFA 블록이 만든 프레임별 가중치들과 teacher이 제공했던 frame-text 유사도사이의 cross entropy loss를 계산한다.)
고로, batch-level의 손실은 주어진 batch에서 b개의 연관 쌍들에 평균을 함으로써 얻어진다.
(또한, 필자는 텍스트 쪽에서의 fine-grained teaching은 고려하지 않는다. video의 key frame은 영상을 표현할 수 있지만, 하나의 단어가 문장 전체를 표현할 수는 없다고 판단하였음.)
결국, stduent network는 세 개의 loss()의 합을 최소화시키는 방향으로 학습한다.

Conclusion
필자는 효율적인 T2VR을 위해 multi-grained teaching을 갖는 TeachCLIP을 제안한다.
student의 성능과 teacher의 성능은 비례한다.
고로, 더 낳은 teacher model은 더 좋은 student model을 이끌어낼 수 있는 것이다.
또한, coarse-grained teaching과 fine-grained teaching을 합쳐서 사용하는 MgT는 best이다.
