논문: X-CLIP: End-to-End Multi-grained Contrastive Learning for
Video-Text Retrieval
X-CLIP은 CLIP4Clip에서 좀 더 발전된 형태라고 생각한다. CLIP4Clip이 단순히 video의 정보([class] token)과 caption(문장)의 cosine similarity를 계산하여 영상과 text의 연관성을 계산하였다면, X-CLIP에서는 저런 방식을 coarse-grained 방식이라고 부르고 쉽게 말해서 크게 크게 보는 경우인 것 같다.
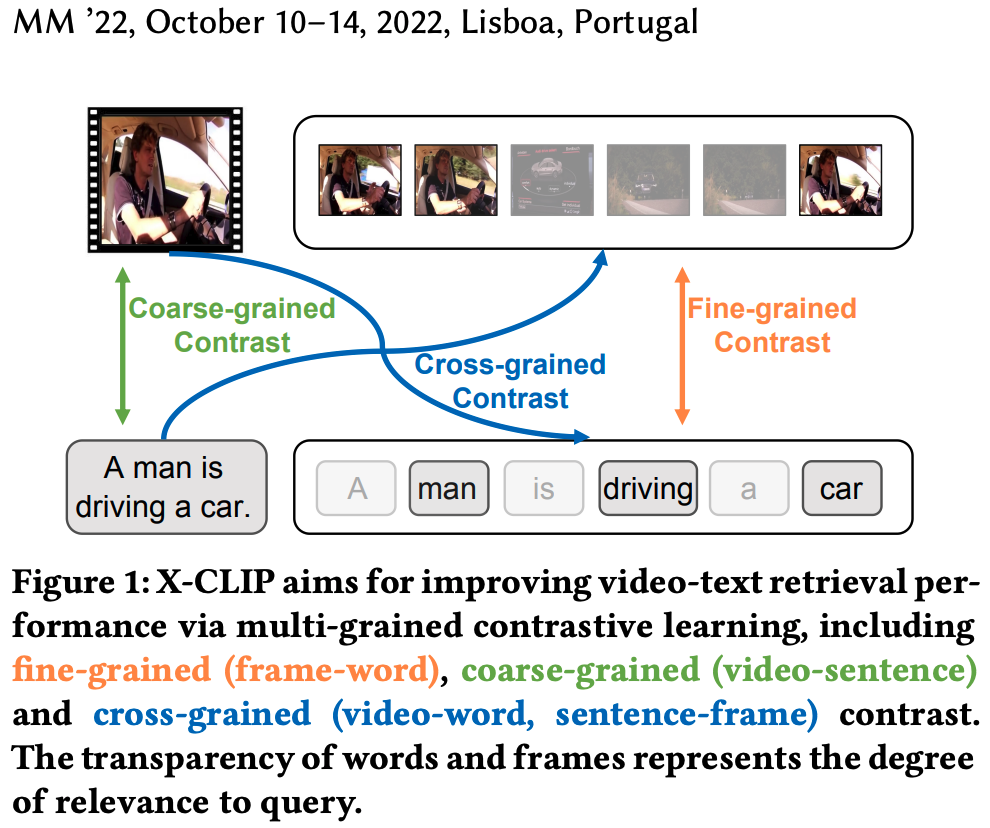
X-CLIP은 coarse-grained 뿐만 아니라, fine-grained(word-to-frame)과 cross-grained(word-to-video, frame-to-caption)사이의 similarity를 계산하여 연관성을 판단한다.
Abstract
필자는 현재의 video-text retrieval 기술은 coarse-grained & fine-grained contrast에 집중하고 있다고 하며, cross-grained contrast를 제시한다.
Cross-grained contrast는 이전의 2개와 달리 coarse-grained의 feature과 fine-grained의 feature 사이의 연관성을 계산한다.
=> 이렇게 해주면, 유사도 계산 중에 coarse-grained feature로 불필요한 fine-grained feature들을 걸러낼 수 있다고 한다.
그리고 X-CLIP이라고 이름 붙은 multi-grained contrastive model을 제시한다.
그리고 유사도 집계 문제가 있는데 => 이 문제는 fine-graine와 cross-grained의 유사도 행렬들을 하나의 인스턴스 수준 유사도로 통합하는 것을 목표로한다.
- instance level: 이건 결국 결과, 한마디로 하나의 유사도 점수를 video-text 쌍에 대한 점수로 잘 합치는게 중요하다는 말.(이게 결과거등)
이 문제를 해결하기 위해, 필자는 AOSM(Attention Over Similarity Matrix)module을 제안한다.(필수적인 frame들과 word들 사이에 contrast에 집중할 수 있도록)
Introduction
CLIP과 CLIP4Clip은 전체 문장과 image/video를 textual 그리고 visual 표현으로 embed한다. => fine-grained 상호성을 놓침.
fine-grained 그리고 fine-grained & coarse-grained 두개를 다 적용한 모델들도 있지만, 필자는 cross-modality semantic contrast가 여전히 필요하다고 말한다.
- Video: 많은 frame들로 구성(불필요한 frame들이 있을 수 있음)
- Sentence: 몇개의 단어들로 구성(불필요한 word들 존재 가능)
그리고 위의 괄호 안에 있는 애들은 query에 대해 낮은 연관성을 유발할 수도 있음.
-> 렇기에 cross-grained가 필요한 거지
-
coarse-grained contrast: video 수준의 feature들과 sentence 수준의 feature들 사이의 유사도 계산.
-
fine-grained contrast: frame 수준의 feature들과 word 수준의 feature들 사이의 유사도 계산.
=> 이 둘다 불필요한 frame들과 단어들을 거르기엔 불충분하다고 함. -
cross-grained contrast: coarse-grained feature들과 각각의 fine-grained feature사이의 유사도 점수를 계산.
=> 역시나 instance수준의 유사도 점수들에 대한 유사도 행렬들을 통합하는데에는 어려움이 있음.
쉬운 방법으로는 Mean-Max 방법을 사용한다.
Mean-Max strategy: 여러 개의 유사도 행렬이 있을 때, 최대값을 뽑거나 평균값을 구해서 그걸 하나의 인스턴스 수준의 유사도 점수로 통합하는 방법.
하지만, Mean 방식은 모든 frame들과 단어들에 같은 weight를 부여하기에, 불필요한 frame과 중요하지 않은 단어를 거르기에는 좋은 방법이 아니다.
Max 방식 또한, 가장 중요한 frame과 단어만을 고려하기 때문에, 다른 중요한 frame들과 단어들은 무시되므로 좋은 방법이 아니다.
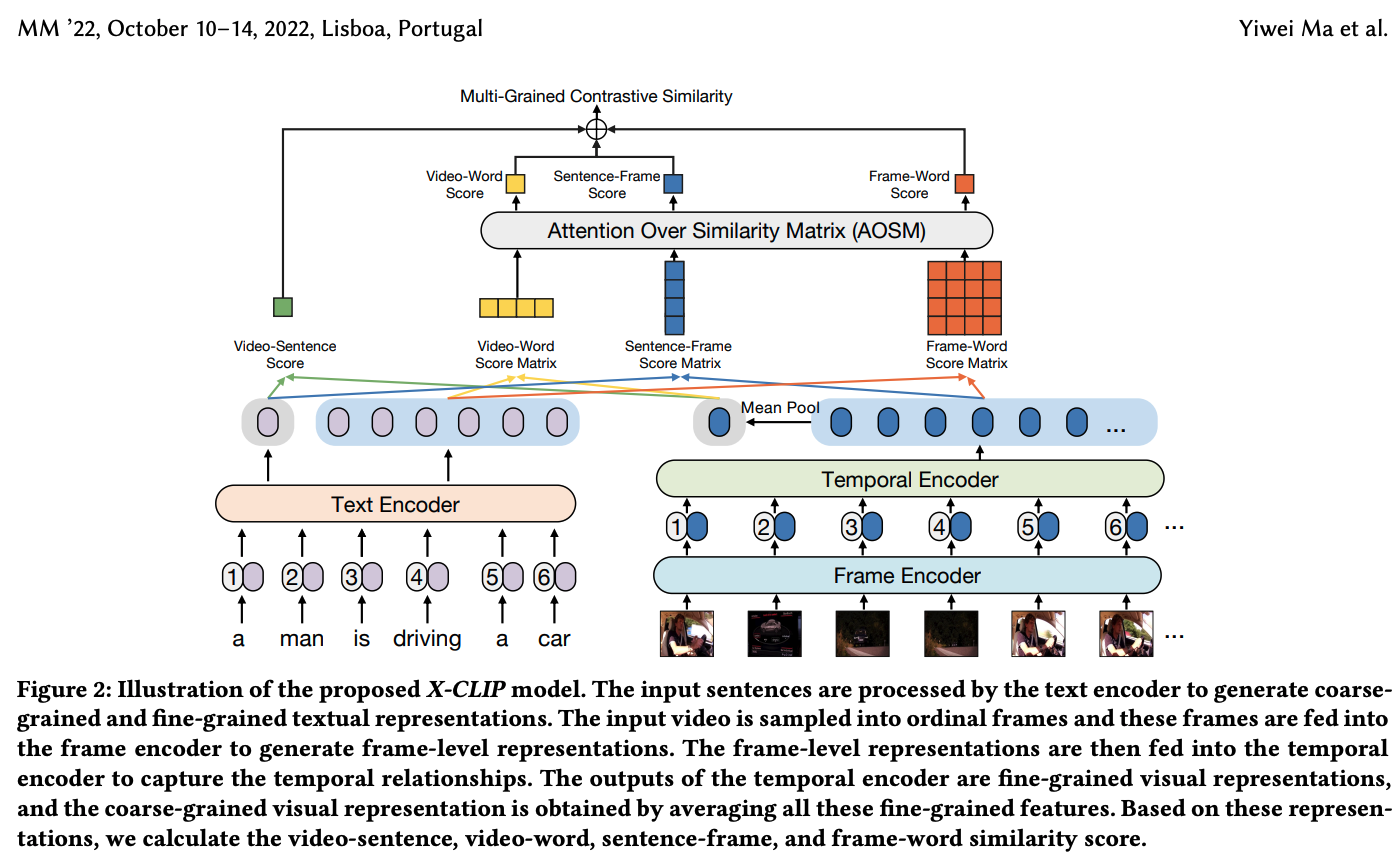
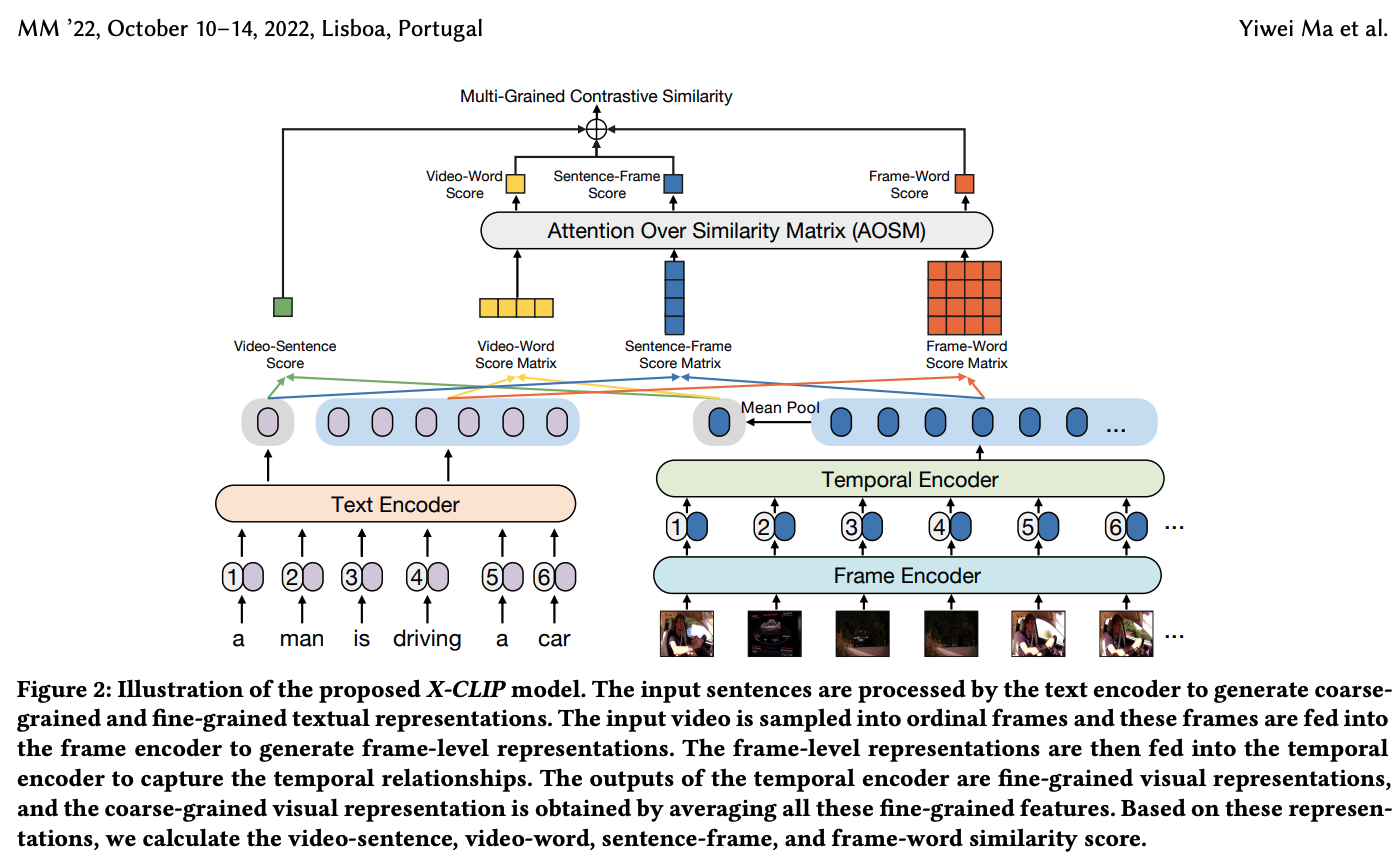
그래서, X-CLIP은 multi-grained visual & textual 표현들을 생성하는 modality-specific encoder(데이터 종류에 따라 사용하는 인코더)들을 적용한다. 그리고, feature들(video-sentence(coarse-grained), video-word(cross-grained), sentence-frame(cross-grained), frame-word(fine-grained))의 multi-grained contrast를 고려한다. => multi-grained 점수, 벡터, 행렬들을 얻을 수 있음.
X-CLIP의 AOSM module은 유사도 벡터들과 행렬들에 대해 attention mechanism을 수행한다.
Mean-Max와 달리, video에 각 frame과 문장에 각 단어의 중요도를 동적으로 고려한다. => 이렇게 필터링 하는 것.
Related Work
Vision-Language Pre-Training, Video-Text Retrieval, Multi-Grained Contrastive Learning
=> Contrastive Learning은 간단하게 생각해서 관련된 데이터는 가까이 관련없는 데이터는 멀리하면서 학습.
Methodoglogy
Feature Representation
Frame-level Representation
필자는 먼저, 초당 1개의 프레임으로 sampling한다.
그 후, frame encoder은 frame 수준의 feature들을 얻기 위해 이러한 frame들을 작업한다.(이 Encoder은 12개의 layer을 갖는 ViT을 사용한다.)
그리고 이전의 작업(CLIP4Clip)을 따라, CLIP의 checkpoint로 frame encoder을 초기화한다.(ViT는 transformer이지만, 이미지/frame의 패치를 하나의 token으로 받음)
- [CLS] token: Transformer의 마지막 layer에서 옴. frame수준의 feature들로써 추출된다.(프레임 하나를 대표하는 token이라고 생각하면 될듯),
Visual Representation
은 각각의 frame들에서 추출된다.-> frame들간의 상호관계는 생각하지 않는다.
temporal encoder(temporal position을 P로 임베딩, 사전 정의됨.)-> 시간적 관계를 모델링함.(프레임들 사이의 temporal relationship을 모델링한다는 말이야)
temporal encoder 역시 3 layer로 이루어진 하나의 standard transformer이다.
그래서 공식으로 살펴보면,
- =>얘가 video 에 최종 frame수준의 visual feature들임.(n은 비디오 에 있는 frame의 개수)
그리고, vidoe수준의 visual feature인 을 구하기 위해선, 비디오 의 모든 frame수준의 feature들을 평균화 시킨다.
Textual Representation
문장이 주어졌을때, 필자는 textual 표현을 생성하기 위해 직접적으로 CLIP의 text encdoer을 사용한다.
- transformer: layer 12개, attention head 8개로 이루어짐, query, key & value feature들의 차원은 512
- tokenizer: lower-cased byte pair encoding(49,152 vocab size를 갖음.)
textual token sequence는 [BOS]로 시작하고 [EOS]로 끝남.
그리고, sentence 수준의 textual feature인 와 word 수준의 textual feature들인 은 각각 [EOS] token의 출력이되고 text encoder의 마지막 layer에서 해당하는 word token들의 출력이 된다. (m = 문장의 길이)
Multi-Grained Contrastive Learning
필자는 cross-grained contrast가 비디오와 문장에 불필요한 정보를 걸러주는데 탁월하다는 것을 한번 더 강조한다.
Video-Sentence Contrast
video 수준의 표현인 와 문장 수준의 표현인 이 주어질 때, 비디오와 문장의 유사도를 평가하기위해 필자는 matrix multiplication을 사용한다.
- => video-sentence 유사도 점수.
Video-Word Contrast
video 수준의 표현인 와 word 수준의 표현인 vector 이 주어질 때, 비디오 표현과 각각의 단어 표현 사이의 유사도를 계산하기위해 matrix multiplication을 수행한다.
- => video와 각 단어 사이의 유사도 vector.
Sentence-Frame Contrast
Video-Word Contrast와 유사하게, 문장 수준의 표현인 와 frame 수준의 표현인 사이의 유사도를 matrix multiplication을 이용해 계산할 수 있다.
- => 문장과 각 프레임 간의 유사도 vector
Frame-Word Contrast
그리고, word 수준의 표현과 frame 수준의 표현 사이의 유사도 matrix도 역시 matrix multiplication을 이용하여 구한다.
Attention Over Similarity Matrix(AOSM)
instance수준의 유사도를 얻기 위해, 필자는 위 의 식중 video-word, sentence-frame, frame-word의 결과로 나온 유사도 vector/matrix들을 합친다.
Mean-Max 방식을 사용하면 다른 frame들과 word들의 중요도는 무시하기 때문에, AOSM 방식을 사용하자.
=> 통합하는 동안, 유사도 vector/matrix들에 점수들에 다른 가중치값들을 부여한다.
특히, 와 의 유사도 vector을 고려해보면,
필자는 처음에 유사도 vector들의 가중치를 얻기 위해서 Softmax를 사용한다.(query와 연관된 fine-grained feature들의 점수에는 높은 가중치가 주어지는 식으로, query = Sentence or Video)
그 후, 이런 가중치가 부여된 유사도 점수들을 통합한다.
- => : i번째 단어가 전체 video와 얼마나 유사한 지
- => : i번째 frame이 전체 문장과 얼마나 유사한 지
여기까지가, cross-grained의 instance 수준의 유사도를 구하는 방법
fine-graine의 instance 수준의 유사도를 구히려면, 일단 => n개의 frame들과 m개의 word들의 유사도 점수를 포함하기 때문에,
matrix에 대해 두번 attention operation을 수행한다.(프레임 기준 한 번, 단어 기준 한 번, 하나만 하면 정보가 한 방향으로만 집중되기 때문에. 두번해줘야 중요한 프레임가 중요한 단어를 동시에 추출할 수 있다는 말임)
- => : i번째 프레임이 모든 단어와 얼마나 유사한 지
- => : i번째 단어가 모든 프레임과 얼마나 유사한 지
- => 영상과 m개의 단어들 사이의 유사도 점수
- -> 문장과 n개의 frame들 사이의 유사도 점수
필자는, fine-grained의 instance 수준의 유사도를 구하기 위해, 비디오 수준의 vector인 와 sentence 수준의 vector인 두 번째 attention operation을 수행한다.
- => : 비디오와 문장의 i번째 word의 유사도
- => : 문장과 비디오의 i번째 frame의 유사도
- , => instance수준의 유사도.
결과적으로, 필자는 fine-grained 유사도 점수를
로 구한다.
Similarity Calculation
이러한 multi-grained 방법을 통해 필자는 최종 유사도 점수 를
로 게산한다.
Objective Function
B batch개의 video-text 쌍을 고려하여, B x B의 유사도 행렬을 생성한다.
필자는 symmetric InfoNCE loss를 적용시킨다.
로 계산한다.
Conclusion
결국 필자는 새로운 end-to-end방식의 multi-grained contrastive model, X-CLIP을 소개한다.
Multi-grained contrast와 AOSM 모듈은 불필요한 frame들과 중요하지 않은 단어들을 걸러준다.
