Kaggle Bike Sharing Demand 데이터 분석
https://www.kaggle.com/c/bike-sharing-demand/data 의 데이터를 사용
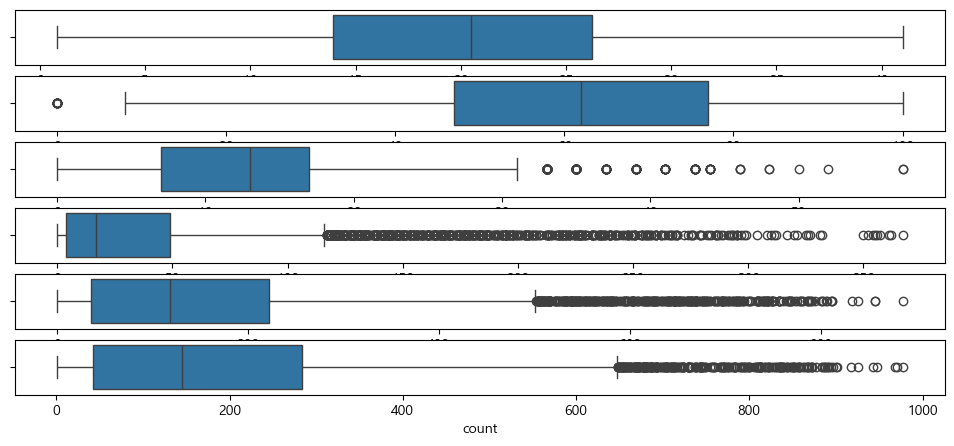
연속형 변수들의 이상치를 확인하기 위해서, boxplot을 이용해서 시각화 해보면, humidity, windspeed, casual, registered, count에 이상치가 존재하는것으로 보인다.
fig, axes = plt.subplots(6, 1, figsize = (12,20))
sns.boxplot(data = train, x="temp", ax=axes[0])
sns.boxplot(data = train, x="humidity", ax=axes[1])
sns.boxplot(data = train, x="windspeed", ax=axes[2])
sns.boxplot(data = train, x="casual", ax=axes[3])
sns.boxplot(data = train, x="registered", ax=axes[4])
sns.boxplot(data = train, x="count", ax=axes[5])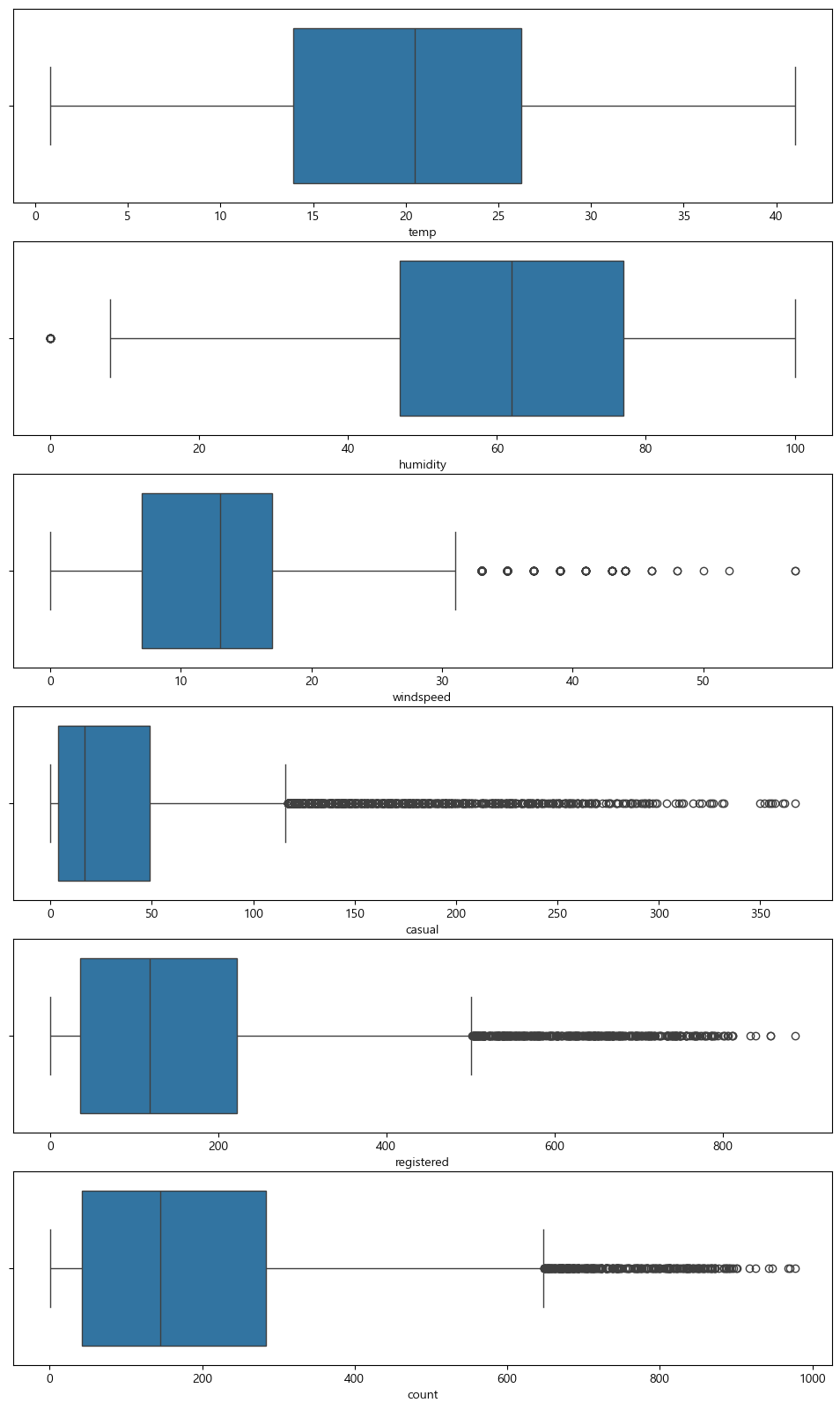
이상치를 제거하기 위해서 간단하게 함수를 구성해주고, 사분위 수를 이용하여서 제거하게 되면, 이상치가 제거된 모습을 볼 수 있다.
def del_outlier(df, columns):
for col in columns:
mean = df[col].mean()
std = df[col].std()
lower_bound = mean - 3*std
upper_bound = mean + 3* std
df = df[(df[col] >= lower_bound) & (df[col] <= upper_bound)]
return df
columns = ['humidity', 'windspeed', 'casual', 'registered', 'count']
train = del_outlier(train, columns)
모델링에 적합하도록 범주형인 변수들을 category 형으로 바꿔 주었다.
cols = ['season', 'holiday', 'workingday', 'weather', 'year', 'month', 'year-month', 'hour']
for col in cols:
train[col] = train[col].astype('category')
test[col] = test[col].astype('category')
train.info()모델링에 들어서기 전에 앞서, count column의 변수들의 분포가 정규분포를 따르는지 확인해보면, 정규분포와는 조금 먼것으로 보이나, 모델링에 직접 적용해서 log나 sqrt를 취해주면서 어떤것이 더 적합한지 판단하는게 좋아보인다.
import scipy.stats as stats
figure, axes = plt.subplots(1,2, figsize=(12,8))
sns.histplot(train['count'], ax=axes[0])
stats.probplot(train['count'], dist='norm', fit=True, plot=axes[1])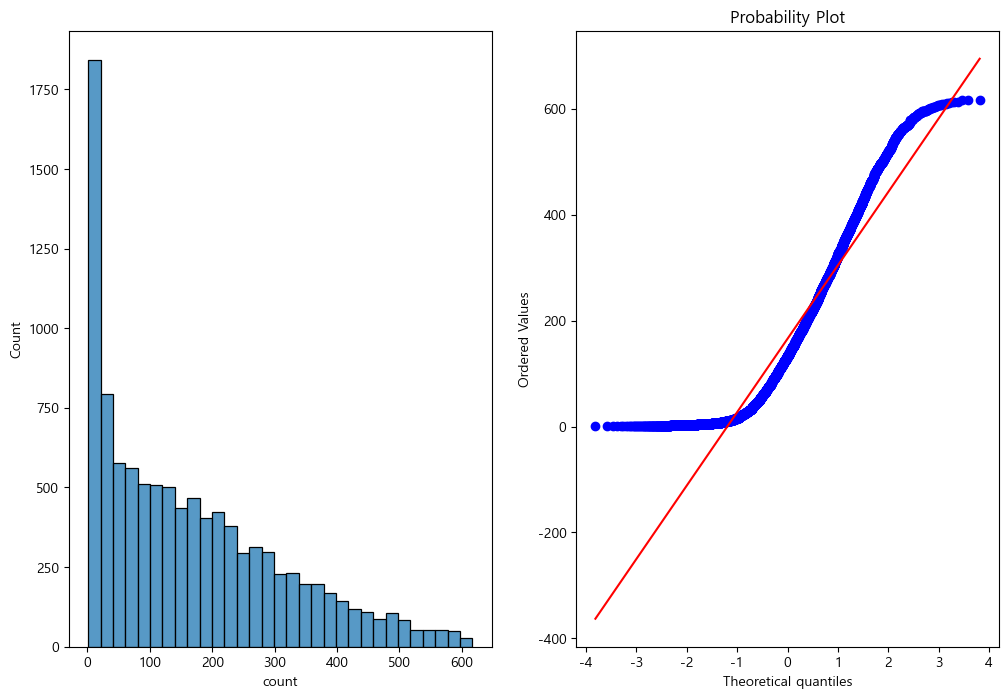
해당 Kaggle은 회귀 평가 지표중 하나인 RMSLE(Root Mean Squared Logarithmic Error) Score로 평가한다. 따라서 모델 적합성을 평가하기 위한 RMSLE 함수를 하나 구현하였다.
def RMSLE(true_value, pred_value):
# Log-transform the true and predicted values (add 1 to avoid log(0))
log_true = np.log1p(true_value)
log_pred = np.log1p(pred_value)
# Calculate squared differences
squared_diff = (log_true - log_pred) ** 2
# Compute the RMSLE
rmsle_value = np.sqrt(np.mean(squared_diff))
return rmsle_value변수들을 p-value 검정을 통해서 통계적으로 유의한 변수들을 모델에 적용하기 위해 연속형 변수들은 피어슨 상관계수를, 카테고리형 변수들은 스피어만 상관계수를 적용하여 확인하여 보면, holiday, weather는 0.05보다 큰 값을 가지므로 귀무 가설(즉, 두 변수 사이에 관계가 없다)을 기각할 수 없으므로, 통계적으로 유의하지 않다고 판단한다.
-> 시각화 할때는, weather이라는 column이 영향을 미친다고 생각했는데, 생각해보니 날씨가 안 좋을때는 대여를 하지 않아서 데이터 값 자체가 존재하지 않는데, 아마 이 부분을 따로 적용할 방법을 찾거나 일단은 모델링에서 제외했을 때와 넣어 봤을때의 score차이를 보면 좋지 않을까 생각한다.
또한 temp와 atemp는 사실상 같은 변수로 볼 수 있으므로, 상관계수에서도 거의 같은 값을 가졌기 때문에 역시, 2개를 다 넣어봤을때, 교차로 넣어봤을때를 비교해 봐야할거 같다.
registered와 casual 역시 우리가 예측 해야할 test df에는 없는 변수이므로 이들을 제거해준다.
#모델링에 필요한 라이브러리 불러오기
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_validate
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import AdaBoostRegressor
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import make_scorer
# 입력과 타겟변수 만들기
features = ['season', 'workingday', 'temp', 'humidity', 'windspeed', 'year', 'month', 'hour']
train_input = train[features].values
train_target = train['count'].values
# 모델 객체 생성
model = GradientBoostingRegressor()
# KFold 교차 검증 설정
cv = KFold(n_splits=5, shuffle=True, random_state=42)
# 교차 검증 점수 계산
score = cross_validate(model, train_input, train_target, return_train_score=True, cv=cv, n_jobs=1)
print("Train Score:", np.mean(score['train_score']))
print("Test Score:", np.mean(score['test_score']))
#RSMLE 점수 계산
RMSLE_score = make_scorer(RMSLE, greater_is_better=False)
rmsle_score = cross_val_score(model, train_input, train_target, cv=cv, scoring=RMSLE_score, n_jobs=1)
print("RMSLE:", -np.mean(rmsle_score)) # 음수로 출력되므로 부호를 반대로 바꿔줌
# 모델 학습
model.fit(train_input, train_target)season: p-value = 0.00000
holiday: p-value = 0.54628
workingday: p-value = 0.00000
weather: p-value = 0.99936
temp: p-value = 0.00000
atemp: p-value = 0.00000
humidity: p-value = 0.00000
windspeed: p-value = 0.00000
casual: p-value = 0.00000
registered: p-value = 0.00000
year: p-value = 0.00000
month: p-value = 0.00000
year-month: p-value = 0.00000
hour: p-value = 0.00000
GradientBoostingRegressor같은 경우는 정확도 자체는 높게 나오는 반면에, 실제로 test값을 예측해보면 음수가 생기는 문제가 발생했다. 이를 해결하기 위해서 count 자체에 log를 씌워주고 마지막에 역으로 변환해주는 과정을 해서 제출했다.
Train Score: 0.9129945132266515
Test Score: 0.9076741044933165
RMSLE: 0.13230575664175626

2차 시도는, RandomForestRegressor을 사용하였다.
Train Score: 0.9875964855803124
Test Score: 0.9125490618827132
RMSLE: 0.3684396314835847
Score 자체도 괜찮게 나오는 편이라, Kaggle에 제출 해보면

생각보다 점수가 아쉽게 나오는것을 확인 할 수 있다.
temp, atemp를 함께 넣었을때 점수는 동일하며, atemp만 넣었을때는 성능이 떨어지는 것을 보아, temp만 넣는것이 적절해 보인다는 결론을 얻었고, count에 log를 씌워서 비교를 해보면, 좀더 성능이 좋아지는 것을 확인했다. 아마 count가 정규분포에 가까워지면서 모델 적용에 좀 더 적합화 되는거 같다.
train['count'] = train['count'].map(lambda i:np.log(i) if i > 0 else 0)해당 코드를 넣어서 다시 점수를 비교해보면, 좀 더 점수가 좋아진다.
Train Score: 0.9900311255062876
Test Score: 0.9293007589191944
RMSLE: 0.12414553629298872
그리고, 직관적으로는 weather이라는 column이 count에 영향을 미치는것으로 보여, 넣어보면 RMSLE 점수는 좋아지지만, Train Score와 Test Score는 떨어지는것으로 보아 역시 p-value 검정에서 기각한것이 더 좋음을 알 수 있다.
Train Score: 0.9840067463100765
Test Score: 0.8880580803870103
RMSLE: 0.1131639998813331
나는 0.3점대나 0.4점대를 목표로 하였지만, 실패했던 이유를 한번 정리해보면
-
FE 과정 중 잘못된 변수선택이나, 새로운 Column을 통한 모델 fit을 제공할 수 있었을것이다.
-
GradientBoostingRegressor 모델에서 상당히 높은 점수가 나왔었는데, 실제로 모델에 적용하면서 count 예측값에 음수인 값들이 생기면서 Kaggle 점수를 받지 못하였는데 이부분은 어떻게 해결해야할지 생각했는데, count에 log를 씌우는 과정을 거치고 이를 다시 역변환 할때 손실이 생기면서 모델 Score가 낮아졌었다. 다음부터는 GBR에 음수값이 나올때는 HistGradientBoostingRegressor나 XGBoost 모델에도 적용해봐야겠다.
-
windspeed column에서 0으로만 나오는 값들이 실제로 바람의 영향이 count에 없기 때문이라고 생각했는데, 다시 살펴보면 0~6까지의 값이 측정되지 않아 0에 극단적으로 변수가 몰리는거 같았다. 0인 값들을 0~6사이로 모델이나, 랜덤함수를 이용하여 값을 넣어줘서 학습 시켰으면 결과가 더 좋았을거 같다.
