Kaggle Bike Sharing Demand 데이터 분석
https://www.kaggle.com/c/bike-sharing-demand/data 의 데이터를 사용
데이터 분석에 필요한 라이브러리와, 경로 지정.
Data Fields는 다음과 같다.
datetime - hourly date + timestamp
season - 1 = spring, 2 = summer, 3 = fall, 4 = winter
holiday - whether the day is considered a holiday
workingday - whether the day is neither a weekend nor holiday
weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp - temperature in Celsius
atemp - "feels like" temperature in Celsius
humidity - relative humidity
windspeed - wind speed
casual - number of non-registered user rentals initiated
registered - number of registered user rentals initiated
count - number of total rentals
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import missingno as msno
#한글 폰트 설정, 축이나 라벨에 표시되는 -기호 깨짐 방지
plt.rc('font', family='Malgun Gothic')
plt.rc('axes', unicode_minus=False)
train = pd.read_csv("위치")
test = pd.read_csv("위치")
submission = pd.read_csv("위치.csv")train 데이터 프레임의 헤더를 확인해보면, 다음과 같다.
train.head()| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 |
train과 test의 datetime의 type이 object임으로 datetime으로 변경해주었다.
train['datetime'] = pd.to_datetime(train['datetime'])
test['datetime'] = pd.to_datetime(test['datetime'])train의 결측치를 확인해보면 다음과 같다.
datetime 0
season 0
holiday 0
workingday 0
weather 0
temp 0
atemp 0
humidity 0
windspeed 0
casual 0
registered 0
count 0
dtype: int64
없는것으로 확인된다.
기초통계량을 확인해보면
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 10886 | 10886.000000 | 10886.000000 | 10886.000000 | 10886.000000 | 10886.00000 | 10886.000000 | 10886.000000 | 10886.000000 | 10886.000000 | 10886.000000 | 10886.000000 |
| mean | 2011-12-27 05:56:22.399411968 | 2.506614 | 0.028569 | 0.680875 | 1.418427 | 20.23086 | 23.655084 | 61.886460 | 12.799395 | 36.021955 | 155.552177 | 191.574132 |
| min | 2011-01-01 00:00:00 | 1.000000 | 0.000000 | 0.000000 | 1.000000 | 0.82000 | 0.760000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 2011-07-02 07:15:00 | 2.000000 | 0.000000 | 0.000000 | 1.000000 | 13.94000 | 16.665000 | 47.000000 | 7.001500 | 4.000000 | 36.000000 | 42.000000 |
| 50% | 2012-01-01 20:30:00 | 3.000000 | 0.000000 | 1.000000 | 1.000000 | 20.50000 | 24.240000 | 62.000000 | 12.998000 | 17.000000 | 118.000000 | 145.000000 |
| 75% | 2012-07-01 12:45:00 | 4.000000 | 0.000000 | 1.000000 | 2.000000 | 26.24000 | 31.060000 | 77.000000 | 16.997900 | 49.000000 | 222.000000 | 284.000000 |
| max | 2012-12-19 23:00:00 | 4.000000 | 1.000000 | 1.000000 | 4.000000 | 41.00000 | 45.455000 | 100.000000 | 56.996900 | 367.000000 | 886.000000 | 977.000000 |
| std | NaN | 1.116174 | 0.166599 | 0.466159 | 0.633839 | 7.79159 | 8.474601 | 19.245033 | 8.164537 | 49.960477 | 151.039033 | 181.144454 |
datetime을 보면, 년 월 일 시간으로 구성되어 있는데, 추이를 분석하기에는 년과 월만 따로 column을 생성해줘도 충분할 거 같다.
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
test['year'] = test['datetime'].dt.year
test['month'] = test['datetime'].dt.year
train.head()| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | year | month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 | 2011 | 1 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 | 2011 | 1 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 | 2011 | 1 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 | 2011 | 1 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 | 2011 | 1 |
년도별로 비교해보면 다음과 같다.
sns.barplot(data = train, x='year', y='count')
2011년보다 2012년의 자전거 대여 수요가 더 많았다.
그렇다면, 월별로는 어떨까? 해당년도의 월별로 관찰하기 위해, 위에서 year와 month로 나눠준것을 다시 year-month라는 column을 새로 생성하기로 하였다.
train['year-month'] = train['year'].astype(str) + '-' + train['month'].astype(str).str.zfill(2)
해당코드를 사용하니 시각화 과정중, dataframe이 아니라서 생기는 문제가 발생했다 그래서 코드를 다음과 같이 수정
train['year-month'] = pd.to_datetime(train['year'].astype(str) + '-' + train['month'].astype(str),
format='%Y-%m').dt.strftime('%Y-%m')| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | year | month | year-month | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 | 2011 | 1 | 2011-01 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 | 2011 | 1 | 2011-01 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 | 2011 | 1 | 2011-01 |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 | 2011 | 1 | 2011-01 |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 | 2011 | 1 | 2011-01 |
이를 시각화해보면2011년에서 2012까지 전체적으로 증가하는 추세라는 것을 파악할 수 있다.
plt.figure(figsize=(20,5))
sns.barplot(data=train,x='year-month',y='count', palette='pastel')
월별로 다시 확인해보면, 12월~3월 가장 추운 기간동안, 수요가 감소하는것으로 보인다.
sns.barplot(data=train,x='month',y='count', palette='pastel')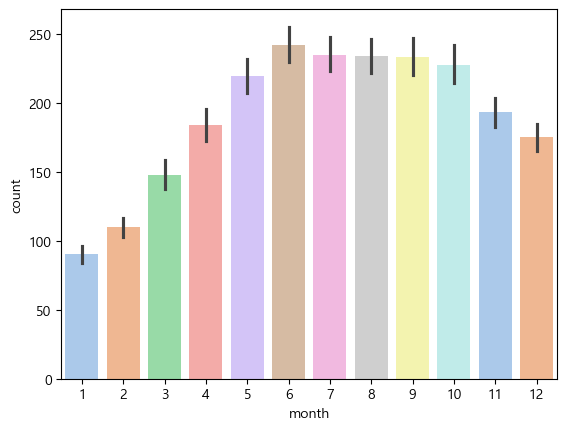
train 자체 계절로 확인해보면, 봄에 가장 수요가 적은것으로 보인다.
(*1~3월 봄, 4~6 여름, 7~9 가을, 10~12 겨울 -> 변경이 필요해보임)
sns.barplot(data=train,x='season',y='count', palette='pastel')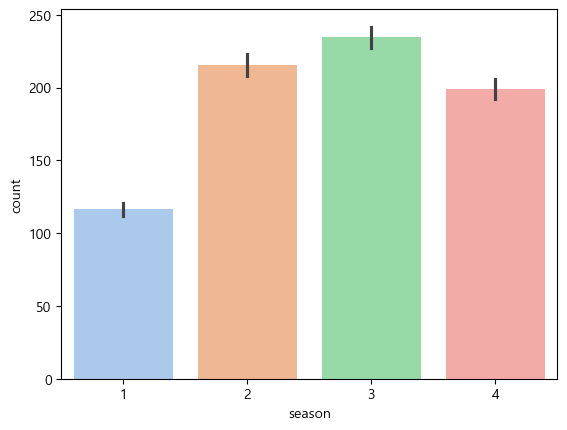
temp에 따른 그럼 변화가 꽤 있을까? 를 보면, 연속형 변수라 오류막대가 길게 나오기도 하고, 정확한 분석은 아닌거 같다. (humidity, windspeed도 마찬가지라 뒤에서 다시 분석하겠다.)
plt.figure(figsize=(30,4))
sns.barplot(data=train,x='temp',y='count', palette='pastel')
평일과, 휴일에 따라 큰 변동이 있을줄 알았는데, 그렇지는 않았다.
sns.barplot(data=train,x='workingday',y='count', palette='pastel')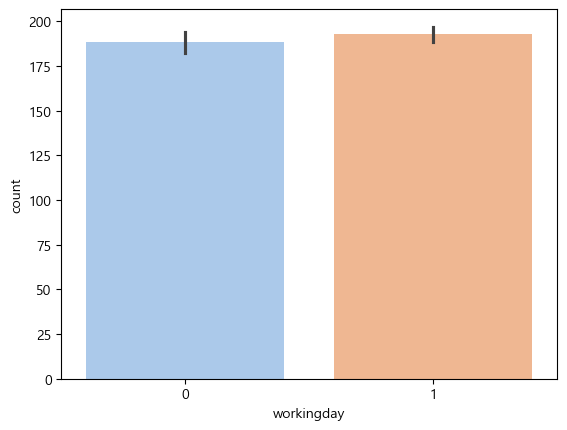
시간대 별로 파악을 위해 hour이라는 column을 추가해주고, 이를 시각화 해보면 출퇴근 시간에 가장 많은 수요가 있는것으로 파악된다.
train['hour'] = train['datetime'].dt.hour
sns.pointplot(data=train, x='hour', y='count')
그렇다면, 휴일과 평일과 시간대 수요는 차이가 있을까?
휴일과 평일 시간대에 따른 수요차이를 시각화 해보면, 휴일에는 가장 활동량이 많은 낮에 수요가 많고, 평일에는 역시 출,퇴근 시간대가 가장 많은것으로 보인다.
sns.pointplot(data=train, x='hour', y='count', hue='workingday', palette='pastel')
날씨에 따른 시간대별 수요를 파악해보면, 역시 날씨가 좋을수록 높은 추세이며, 2번날씨까지는 큰 영향을 안받는거 같다. (심한 비가와도 누군가는 퇴근하고 싶어서 자전거를 탄 모양이다..)
#weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy
#2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
#3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
sns.pointplot(data=train, x='hour', y='count', hue='weather', palette='pastel')
주요 요인이 될 변수들의 시각화는 이정도면 된거 같고, 그렇다변 변수간의 상관관계는 어떻게 될까?
corr_train = train[["temp", "atemp", "humidity", "windspeed", "casual", "registered", "count"]]
corr_train.corr()
sns.heatmap(corr_train.corr(), annot=True)| temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|
| temp | 1.000000 | 0.984948 | -0.064949 | -0.017852 | 0.467097 | 0.318571 | 0.394454 |
| atemp | 0.984948 | 1.000000 | -0.043536 | -0.057473 | 0.462067 | 0.314635 | 0.389784 |
| humidity | -0.064949 | -0.043536 | 1.000000 | -0.318607 | -0.348187 | -0.265458 | -0.317371 |
| windspeed | -0.017852 | -0.057473 | -0.318607 | 1.000000 | 0.092276 | 0.091052 | 0.101369 |
| casual | 0.467097 | 0.462067 | -0.348187 | 0.092276 | 1.000000 | 0.497250 | 0.690414 |
| registered | 0.318571 | 0.314635 | -0.265458 | 0.091052 | 0.497250 | 1.000000 | 0.970948 |
| count | 0.394454 | 0.389784 | -0.317371 | 0.101369 | 0.690414 | 0.970948 | 1.000000 |

생각보다, temp, windspeed와 humidity의 영향을 받는것으로 보여서, 이들 값의 분포를 확인해보면, windspeed의 경우에 결측값이 없던 이유가 아마 0으로 값이 대체된거 같다. 그치만 과연 낮은 바람의 속도가 자전거 수요에 영향을 끼쳤을까?는 잘 모르겠다.
해당 Kaggle의 discussion을 참고해도 비슷한 맥락이다.
https://www.kaggle.com/competitions/bike-sharing-demand/discussion/10431
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(12, 5))
sns.regplot(data = train, x='temp', y='count', ax = ax1)
sns.regplot(data = train, x='windspeed', y='count', ax = ax2)
sns.regplot(data = train, x='humidity', y='count', ax = ax3)
