Clustering Enhancement
본 글은 최근 BERTopic을 사용해 진행하고 있는 프로젝트에서 얻은 여러가지 불만 또는 교훈을 정리한 글이다. 만약 유사한 상황에 놓인 사람이라면 공감할 수도 있을 수 있다. 완벽한 글을 위해 구조를 생각하다간 더 이상 글을 못 쓸 것 같아, 머릿속 흐름대로 작성해보고자 했다.
요약
- 클러스터링의 목적
- BERTopic, 문제점
- 해결 방법
Clustering의 목적
NLP 분야에서 Clustering은 입력 Corpus에 대해, 유사한 문서들끼리 군집화를 해주는 기법이다. 이는 2가지 종류로 나뉘는데, 사용자가 원하는 클러스터의 개수로 정확하게 나눠주는 방식과, 가장 적합한 군집 개수를 탐색한 뒤 클러스터링을 진행하는 경우이다.
개인적으로 클러스터링을 수행함에 있어 전자의 경우는 효용성이 적다고 생각한다. K개의 클러스터 개수를 정확하게 알고 있는 문서 Corpus 같은 경우는 연구 Scene에서만 등장할 수 있는 매우 한정적인 상황이기에, 활용 가치가 다소 적다고 느껴진다. 실제 사용자가 클러스터링을 원할 때는, 문서 집합을 분석하지 않고 바로 그 문서 집합의 의미를 파악하고자 할 때이기 때문이며, 전체 문서의 흐름을 파악해 다음 본 Task를 수행하기 위해서이기 때문이다.
따라서, 클러스터링을 위해서 나는 보통 HDBSCAN을 사용하며, 다소 Noisy한 결과를 주긴하지만 후처리를 통해 보완할 수 있으며, 가장 좋은 점은 k개를 설정하지 않아도 된다는 점이다. 물론 하이퍼 파라미터에 따라, 데이터 셋에 따라 k의 범위가 들쑥날쑥하지만 클러스터 개수 k를 일일이 하나씩 탐색하며 Metric으로 평가하는 대신 버튼 하나만 누르면 되는 편안함이 있다.
BERTopic, 문제점
이를 잘 묶어서 Topic Modeling으로 구현해낸 것이 BERTopic Module이다.
BERTopic은 입력 Corpus에 대해 UMAP 차원 축소 (차원이 지나치게 높으면 차원의 저주로 인해 클러스터링이 잘 안된다는 주장 - 그런데 그 어느 논문에서도 왜인지는 구체적으로 설명하지 않는다)를 거친 뒤, HDBSCAN으로 클러스터링을 한다. 그런 뒤, c-TFIDF, 클러스터를 하나의 문서로 간주한 뒤 TFIDF를 진행하는 기법을 적용해 문서들의 키워드를 나타내는 데, 영어에서는 잘 되는 줄 모르겠으나, 한국어로 진행했을 때는 다소 부족한 결과를 낸다. 클러스터링이 잘 됐다면, 단순히 c-TFIDF 대신 클러스터 내 단순 빈도로 진행하는 것이 더 좋을 수 있다. c-TFIDF가 다소 부족하다는 주장은 "Is Neural Topic Modelling Better than Clustering? an empirical study on clustering with contextual embeddings for topics" 에서도 강하게 표출하고 있다.
BERTopic의 구조는 꽤 잘 짜여진 편이다. 토픽 개수를 설정하지 않아도 바로 자신이 원하는 결과를 얻을 수 있다는 믿음이 있는데, 실제로 해보면 아쉽게도 그렇지 않다. 사람이 생각했을 때 비슷하다고 생각되는 문서들이 임베딩의 관점에서는 그렇지 않기 때문이다. 한국어 같은 경우는 더 문제가 큰데, '합니다'로 끝나는 문서들 끼리 비슷하게 뭉쳐, 개별 문서의 중요한 단어들에 집중하는 것이 아니라, 문서의 구조에 따라 묶이는 경우도 있다. 이를 방지하고자 BERTopic 에서는 문서 내의 단어들을 추출한 뒤 진행하라고 하지만, 명사구를 잘 뽑지 못한다면 이는 또다른 문제를 낳고 만다.
현재 이 문제를 해결하고자 다양한 후처리를 진행 중이지만, 최근에 진행해보고 있는 것은 Clustering Embedding Enhancement이다.
아무리 후처리를 열심히 한다고 해도 지속적으로 예외의 경우는 나타날 것이며, 토픽들의 클러스터링을 명확하게 해줄 수 있는 임베딩이 존재한다면 좋을 것이다. PLM의 임베딩을 Pretrain할 때 Clustering에 대한 훈련은 진행되지 않았기 때문에, 이에 대한 적용 시 원하는 결과를 얻기 힘들 것이라는 주장이 많다.
해결 방법
그래서 최근에 살펴보고 있는 논문은
"ClusTop: An unsupervised and integrated text clustering and
topic extraction framework (Chen et al., 2023)이다. Arxiv에 올라온 논문이며, 내용은 간단하다.
- BERTopic 절차를 수행해 먼저 Topic들을 구하여, 이를 Pseudo Label로 산출
- 해당 Pseudo Label을 Pretrained Model 위에 Classification Head를 붙여 훈련
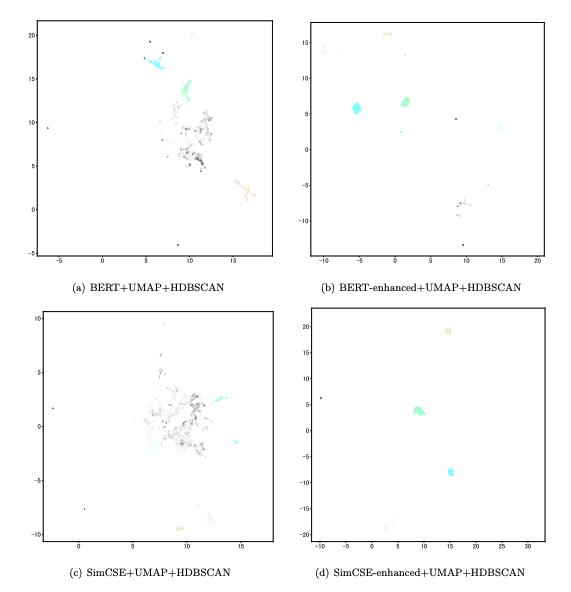
- 그림과 같이 Embedding의 Coherence가 높아져, Metric상 더 높은 결과를 나타냄
하지만 아쉽게도 해당 논문은 Github 구현체도 없고, Classification Head를 어떻게 구축했는지에 대한 설명이 없다. 단순히 [CLS]를 통해 분류 Head를 나타냈는지, Sentence Transformer의 Mean Pooling 방식으로 훈련했는지에 대한 언급이 하나도 없다. 위 아래로 논문을 털어봐도 정보가 등장하지 않아 어떻게 해당 결론이 도출 되었는 지 의심이 된다.
현재 [CLS]를 통한 훈련을 진행해보긴 했지만, 눈에 띄는 차이는 없었다. Topic Coherence / Silhoutte Score 등과 같은 Metric과 정성 평가에서 매우 유사한 결론만이 등장하였다.
따라서 이제 Clustering을 발전시킬 임베딩을 구하는 방법은
- PLM Classification을 Mean Pooling 방식으로 훈련
- 또는 PLM은 그대로 냅두고 BERT Whitening과 같이 Sentence Embedding 자체를 후처리하는 방식
을 시도해보는 것이 남았다.
