HDBSCAN
최근 토픽 모델링에 관련된 업무를 진행하고 있어, 업무의 정리를 위해 본 글을 작성하고자 한다. 본 글을 읽고 나면 다음의 정보를 취득할 수 있다.
- 토픽 모델링
- 토픽 모델링의 현 상황
- HDBSCAN의 절차
토픽 모델링
토픽 모델링이란, 다수의 의견이 담긴 코퍼스에 대해 어떠한 토픽들이 존재하는지를 간략하고, Human Readable하게 정리하는 기술이다. 다수의 사용자가 작성한 의견의 핵심이 '토픽'이라고 말했을 때, 토픽 모델링은 핵심을 요약 정리하는 Task라고 할 수 있다. 예를 들자면, 특정 상품을 팔고 있는 회사에서 자신들의 상품이 고객들에게 어떤 평가를 받고 있는지 살펴보고 싶다면 토픽 모델링을 통해 다수의 토픽을 추출하면 되는 것이다.
즉, 다량의 코퍼스를 입력으로 토픽 모델링을 수행하게 되면 다음과 같은 산출물을 얻을 수 있다.
- 토픽: (토픽 1 = 제품 A 특성 / 토픽 2 = 제품 B 특성)
- 토픽에 포함되어 있는 문서 (토픽 1에 포함되어 있는 문서 리스트)
- 각 문서의 확률 (각 문서별로 토픽 1: 70% / 토픽 2: 30% ...)
토픽 모델링의 현 상황
토픽 모델링은 확실한 수요가 있는 분야라고 생각하지만, ChatGPT와 같은 LLM으로 인해 중요도가 많이 감소하였다. 사실 이전에도 큰 두각을 보인 장르는 아닌 것이 자연어 처리 분야와 같으면서도 데이터 사이언스 쪽의 느낌이 강하기 때문에 연구자들이 Deep Dive하는 것을 원치 않은 느낌이 있다. 이번에 방문한 EMNLP에서도 토픽 모델링에 대해서는 3개 정도의 논문 (Findings 포함)만이 Accept되었고, 매년 이와 같은 수치인 것으로 보아 연구자들의 관심이 느껴진다.
하지만 LLM으로는 토픽 모델링을 하기 어렵다.
- Input Length Limit: ChatGPT 3 / 4의 토큰 Limit은 4K ~ 32K인데 토픽 모델링을 수행하기 위해 보통 산정하는 문서의 개수는 10K 이상이기 때문에 전체 문서를 입력에 포함하기 힘들다.
- Information Leak: 만약 기업의 서베이와 같이 회사의 정보가 포함되어 있는 문서의 경우 ChatGPT에 넣는 것을 꺼리기 때문에 사용이 어렵다.
즉, LLM을 직접적으로 토픽 모델링에 활용하는 것은 어렵고, LLM 이전의 Small Embedder를 사용해야 하는데 가장 많이 활용하는 방식은 다음과 같다.
- Variational Auto Encoder (VAE)
- Clustering Based Topic Modeling: 다량의 코퍼스에서 Unsupervised Method로 토픽 모델링을 수행하여 자동으로 토픽을 나타내는 것은 문서들을 유사한 문서 군집으로 나누는 클러스터링과 유사하다. 따라서, 해당하는 분야에서도 클러스터링을 직접적으로 사용하는데
- 입력 문서들을 임베딩으로 표현한 뒤, 클러스터링 수행
- 클러스터에 포함된 문서들의 확률이 필요할 경우 표현
- Example
- BERTopic
HDBSCAN
HDBSCAN은 2013년, Density-Based Clustering Based on Hierarchical Density Estimates의 논문에서 제안되어서 사용되는 기법이지만 BERTopic을 포함해 아직까지 활용되고 있는 기법이다. 기본적으로 Clustering 기반 토픽모델링은
- 클러스터링을 더 원활하게 해줄 수 있는 임베딩 훈련법
- 클러스터링 이후 Post Processing을 어떻게 해야할 지
- 클러스터링 결과를 사용자가 원하는 관점으로 변경
의 관점으로 진행된다. 즉, Clustering 기법은 기존의 것 (머신러닝 기법)을 고수하고 입력과 후처리에 집중하는 것이다. 이후 설명할 BERTopic 또한 HDBSCAN을 클러스터링 알고리즘으로 사용하며, 다수의 연구들이 HDBSCAN 대신 다른 클러스터링으로도 수행을 해 성능의 향상을 도모했지만 아직까지 뚜렷한 Game Changer 는 없다.
HDBSCAN은 이름에서 알 수 있듯이 DBSCAN에 Hierarchical Information을 추가한 것이다. 따라서 전체적으로 DBSCAN과 HDBSCAN의 경계를 둬서 설명하지 않고 HDBSCAN을 설명하는 와중에서 DBSCAN의 내용이 자동적으로 포함되도록 설명해볼 것이다.
절차
- Transform the space¶: Density / Sparsity에 기반한 공간 변형
- Minimum Spanning Tree of Distance Weighted Graph 구성
- 연결된 Component들의 Cluster Hierarchy 구성
- Minimum Cluster Size에 기반해 Hierarchy 요약
- Condense the cluster tree¶: Condensed Tree로부터 Stable Cluster 추출
1. Transform the Space
클러스터링은 데이터의 바다에서 '육지'를 찾아내는 과정과 같다.
지구 전체를 데이터의 범위로 봤을 때, 육지를 클러스터, 그리고 바다를 이상치로 간주하는 것이다. 바다의 양이 줄어들게 되면 이상치가 줄어들어 육지가 명확하게 올라올 것이고, 바다의 양이 많아지게 되면 이상치가 많아져 육지가 줄어들 것이다.
공간을 변형시키는 과정은 바다의 높이를 낮추는 과정과 같은데, 이를 통해 클러스터가 더 두각을 보일 수 있도록 하는 것이다. 이는 단순한 비유이며 실제의 과정은 다음과 같다.
- 두 데이터의 거리를 나타내는 Method 적용 (Any Distance Method)
- 해당 Distance를 Mutual Reachability Distance (MRD)로 변형
MRD 같은 경우는 수식은 위와 같은데, 한 마디로 다음의 목적을 갖는다.
가까운 데이터는 그대로 유지, 먼 데이터는 더 멀게 거리를 변경
2. Build the minimum spanning tree (MST)
이제 클러스터링을 더 잘해줄 수 있는 공간 변형을 마치면 각 데이터들을 새로운 공간에 맞춘 거리에 대하여 Node를 데이터 / Edge를 거리로 산정한 Weighted Graph를 구성한다.
- MST는 존재하는 노드들을 연결할 때 최소의 간선을 활용하는 Tree이다.
- MST는 최소의 간선 개수를 유지하면서, Edge의 가중치 합이 최소인 Tree 이다.
- N개의 노드를 가지는 그래프는 n-1 개의 간선만을 사용해야 한다.
이제 이 Tree를 큰 수에서 부터 작은 수의 Threshold를 기준으로 Edge를 잘라 나가면 되는데 이는 n^2의 Edge를 제거해나가기 때문에 비효율적이며, 극복할 수 있는 방법은 Prim's Algorithm이다. 이는 다 만들어진 Tree에서 Edge를 잘라나가는게 아니라 반대로 각 노드들에 대하여 지속적으로 Edge를 더해나가는 과정이다.
3. Build the cluster hierarchy
MST를 구성하면 이제 Hierarchy를 구성해야 한다. 이는 Dendogram으로 구성하는데 아래의 그림과 같다. 이는 Robust Single Linkage로 구성하며 아래에서부터 한 Pair 씩 묶어 가면서 진행된다.
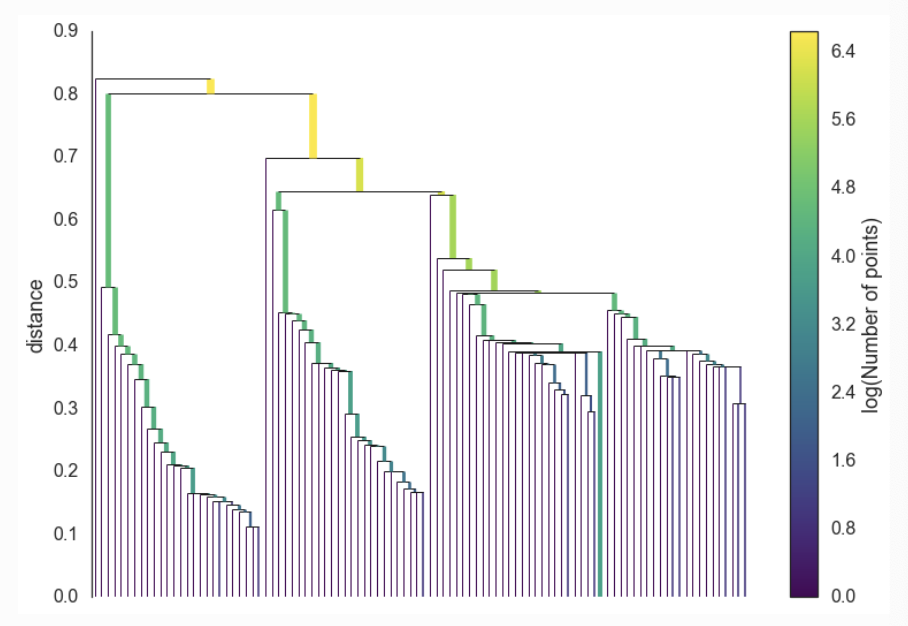
계층을 구성하게 되면 Flat Cluster를 구성한다. 이는 계층으로 보이는 구조에서 1..N 클러스터를 정의하는 과정이다. DBSCAN에서는 이를 위해 특정 Threshold를 준비해 수평선으로 계층을 자르고 자른 계층에서 묶이지 않은 클러스터를 '이상치' / 묶여 있는 클러스터를 판단한다.
이를 위해 HDBSCAN은 Robust Single Linkage에 대해 차이점을 부여한다.
4. Condense the cluster tree
- 위의 Tree에서 큰 노드부터 조금씩 부스러기들을 제거해나간다.
- 맨 위에서부터 분기를 했을 때 하나의 굵직한 클러스터로부터 부스러기들이 떨어져나간다고 생각하면 된다.
- 이 때 Minimum Cluster Size라는 새로운 파라미터가 등장하게 되는데 새롭게 분리가 된 클러스터가 MCS보다 더 작은지를 물어본다.
- 만약 MCS보다 더 작다면, 떨어져나가는 클러스터와 그 거리가 어떻게 되는지를 기록하고 본체를 유지한다.
- 그런데 두 클러스터 모두 MCS보다 더 크다면 두 클러스터 모두 Tree에 유지한다.

5. Extract the clusters
(이 부분부터는 설명이 많이 생력되어 있는데, 직접 번역을 해보면서 한땀한땀 이해하려 했습니다)
위의 그림을 보면 조금씩 Cluster가 작아지는 것을 볼 수가 있는데, 이는 클러스터가 지속적으로 떨어져 나가서이다. Y축을 봤을 때, Lambda가 커지는 것을 볼 수가 있는데 이는 distance의 역수이기 때문에 맨처음 Dendogram에서 거리가 위로 갈 수록 커지고 그것을 역수를 취했을 때 Lambda라는 숫자가 작아지는 것이다.
Lambda 같은 경우 Lambda-Birth / Lambda-Death로 나눌 수 있는데 이는 클러스터의 분기가 일어났을 때와 다시 분리되었을 때의 Lambda를 의미한다.
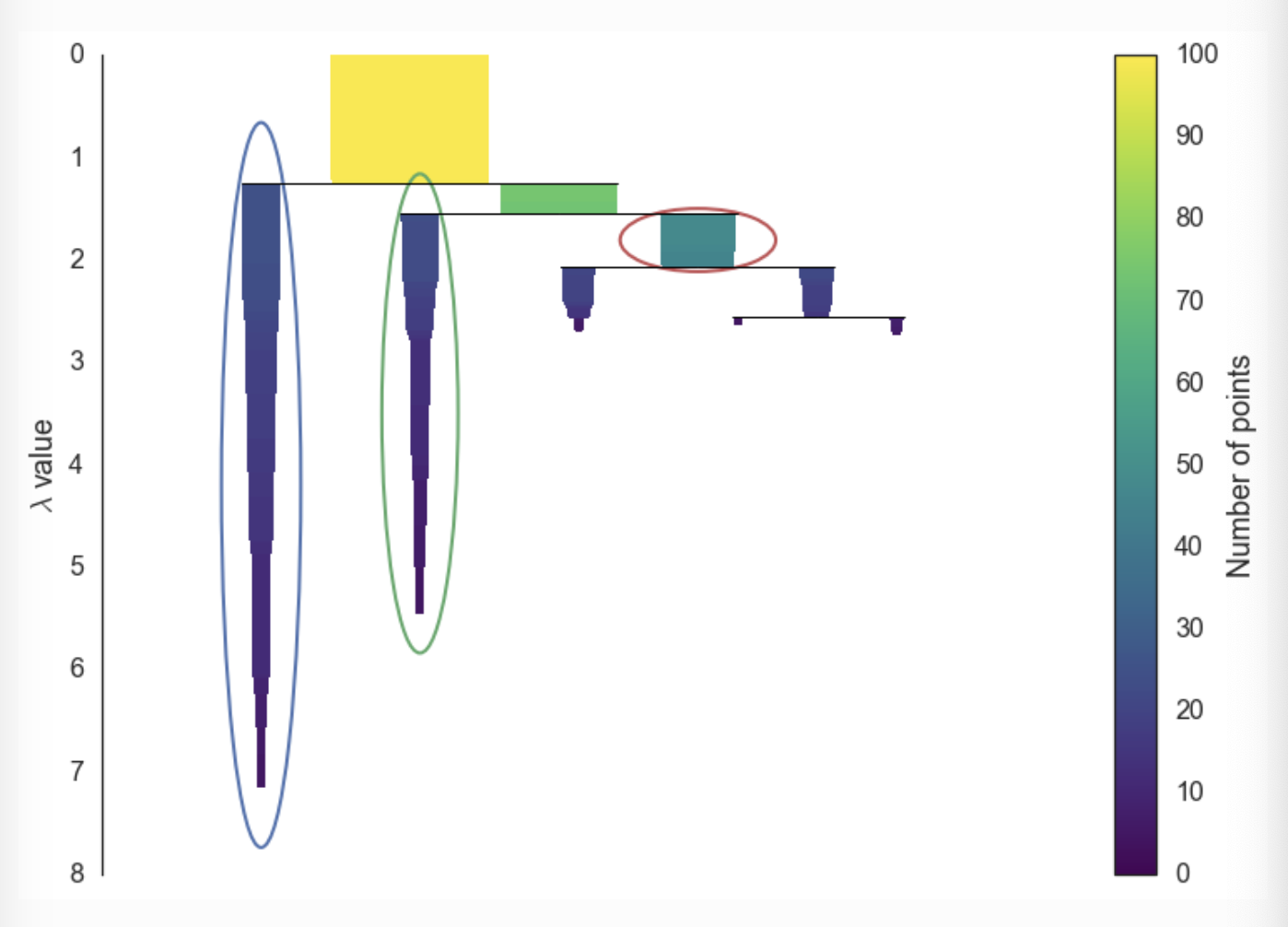
위의 그림에서 볼 수 있듯, Lambda를 활용해 각 클러스터의 면적을 구하고, Child의 면적이 Parent보다 작으면 Parent의 Cluster를 Flat Cluster로 활용하는 듯 하다.
너무 깊게 들어가서 시간 낭비하는 것보다, HDBSCAN의 절차의 큰 틀만 알면 될 것같다. 자료 조사를 하던 중
이 더 내용적으로는 풍부하게 정리해둔 것 같아, 나는 여기까지 작성한다.
