문제
- 더미 클라이언트로 스트레스 테스트하기를 해봤지만, 당시 발견했던 문제는 그대로였다.
메인 루프가 느려서 객체 풀이 고갈되는 거였다.
전송이 완료되면 메시지unique_ptr을 담은 풀로 반환되는데,
이 때 접속자 수에 따라 고갈되는 속도가 달랐고, 고갈되지 않는 경우도 있었다.
최악의 경우 상시 접속 n명으로 했을 때 객체 풀 고갈이 하루에 1개씩 되다가 몇달 뒤에 서버가 다운되는 경우도 있을 것이다.
이걸 잡아내는 방법을 마련해야 한다.
그래야 서버가 감당할 수 있는 접속자 수를 구할 수 있다. - 예전 코드의 메인 루프와 지금 코드의 메인 루프의 성능 비교를 해보고 싶다.
해결
시각적으로 스레드 내 루프 실행과 종료를 보여주기 위해 tracy라는 오픈 소스를 이용할 것이다.
우선 tracy 소스를 받는다. ->tracy
cmake-ui로, 소스 코드 경로를 tracy/profiler로, 빌드 결과물을 저장할 곳으로 tracy/profiler/build로 정하고 Configure한 뒤 Generate.
tracy/profiler/build에 생긴 .sln 파일로 Visual Studio를 열고 빌드한다.
다 됐으면, 내 프로젝트에서 속성->추가 포함 디렉터리에서 다음과 같이 추가.
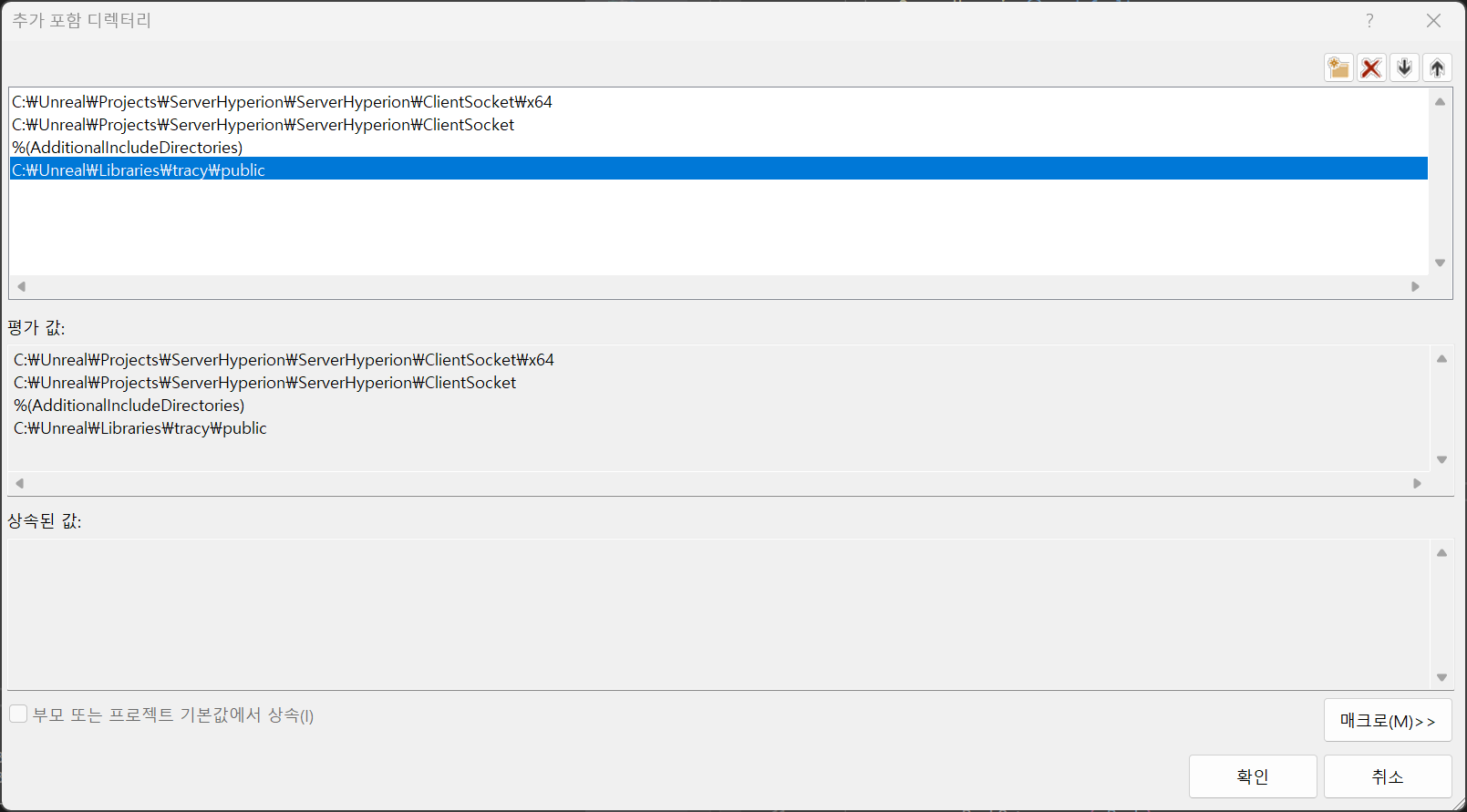
난 제일 상위 클래스 파일에 다음과 같이 포함시켰다.
#define TRACY_ENABLE
#include "TracyClient.cpp"
#include "tracy/Tracy.hpp"이제 코드에 프로파일링 매크로를 추가하면 된다.
매크로 종류가 많으니 자세한 건 공식문서 찾아보시라.
1. 객체 풀 고갈을 모니터링하는 법
내가 쓰고 있는 드미트리 뷰코프의 링버퍼는 내부에 몇개의 원소가 있는지 관측할 수 없다.
성능을 위해 그걸 포기한 측면이 있다.
다만 현재까지 테스트한 결과로는,
1. 34명의 접속자는 2시간 동안 동접이 유지될 때, 아무런 문제 없이 돌아갔다.
2. 50명의 접속자는 30분동안 동접이 유지될 때, 아무런 문제 없이 돌아갔다. 더 많은 시간 동안 테스트는 해보지 않았다.
3. 66명의 접속자는 몇분 뒤 객체 풀 고갈로 클라이언트가 보여주는 캐릭터의 움직임이 버벅거렸다.
당장 떠오르는 방법은, pool에서 빼서 사용하는 시간과 사용한 뒤 반환되기까지의 시간을 비교하는 것이다.
이를 비교하는 방법은, pool에서 빼서 사용하는 SendMsg(...) 함수와 사용한 뒤 반환하는 SendCompleted(...) 함수의 호출 타이밍을 검사하는 것이다.
프로파일링 없이 실험해 본 위 1 ~ 3 케이스에 대해 어떻게 수치가 나오는지 살펴보자.
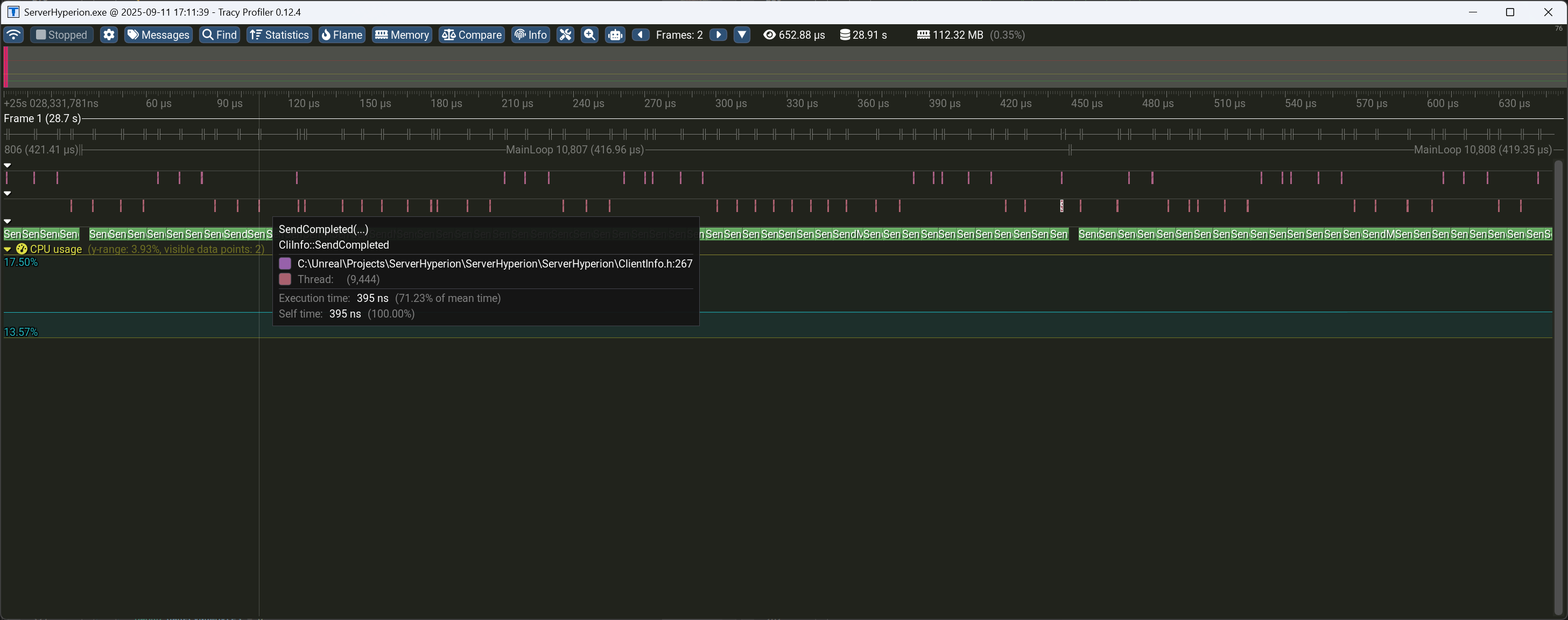
회색 글씨로 MainLoop가 표시돼 있고
분홍색 막대가 SendCompleted(...)가 호출된 시점과 종료에 걸리는 시간이다. (잘 보면 두개의 스레드에서 실행되고 있다.)
그리고 메인루프의 범위 내에서 초록색 막대 SendMsg(...)가 호출되고 있다.
위 그림은 두번째 케이스에 대한 프로파일링 결과다.
잘 보면, 흩뿌려져 있는 분홍 막대는 항상 초록 막대 범위 안에 있다.
즉, 객체 풀에서 Dequeue와 Enqueue가 균형 있게 이루어진다는 의미다.
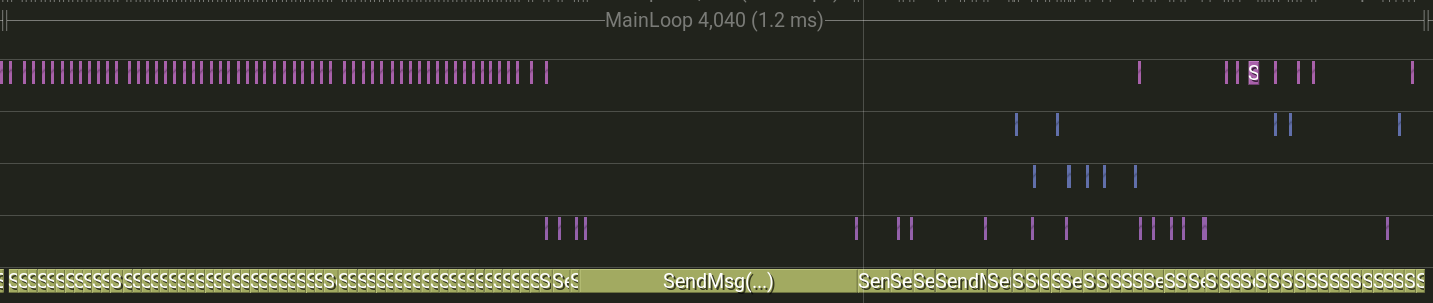
그럼 서버가 다운되는 3번의 경우를 한번 실험해 보자.

초록색으로 줄지어 있는 막대가 SendMsg(...)이고, 그 이외 흩어져 있는 것들이 SendCompleted(...)이다.
잘 세어 보면, 메인 루프 내에서 전자가 빈도가 많다.
풀이 고갈될 때 쯤엔 다음과 같은 그림이 나온다.
2. 바뀐 코드로 성능 비교하기
main 브랜치의 01c42ac8c57cfebdb0f3449e9529f9314df61e9e가 예전 코드,
main 브랜치의 95e1391b80b2875be4babca9207945433168a0dc가 현재 코드이다.
둘의 성능 비교를 해볼 것이다.
다음은 가장 많은 접속자인 50명 기준으로 테스트한 결과이다.
예전 코드의 성능분석

현재코드의 성능 분석

1.54ms에서 0.4149ms로, 약 3배 향상된 속도다.
훨씬 빨라졌다!
