프로젝트 : https://github.com/HoonInPark/ServerHyperion.git
본 포스트에 대한 내용은 feat/lockfree 브랜치에 있(었)다. 지금은 dev에 병합됐다.
문제
드미트리 뷰코프의 MPMC 순환큐를 내 프로젝트에 사용하고자 한다. 그런데 문제가 되는 건 IOCP 송신 코드였다.
bool SendMsg(const UINT32 _InSize, char* _pInMsg)
{
shared_ptr<stOverlappedEx> pSendOverlappedEx = m_SendDataPool.Acquire();
if (!pSendOverlappedEx)
{
printf("SendMsg Error in Client %d", m_Index);
return false;
}
// some write process...
m_SendDataQ.Enqueue(pSendOverlappedEx);
if (m_SendDataQ.Count() == 1)
{
SendIO();
}
return true;
}
void SendCompleted(const UINT32 dataSize_)
{
printf("[송신 완료] bytes : %d\n", dataSize_);
shared_ptr<stOverlappedEx> pSendOverlappedEx;
m_SendDataQ.Dequeue(pSendOverlappedEx);
// some process after packet sended...
m_SendDataPool.Return(pSendOverlappedEx);
if (!m_SendDataQ.IsEmpty())
{
SendIO();
}
}
private:
bool SendIO()
{
shared_ptr<stOverlappedEx> sendOverlappedEx;
m_SendDataQ.Peek(sendOverlappedEx);
DWORD dwRecvNumBytes = 0;
int nRet = WSASend(
m_Socket,
&(sendOverlappedEx->m_wsaBuf),
1,
&dwRecvNumBytes,
0,
(LPWSAOVERLAPPED)sendOverlappedEx.get(),
NULL);
//socket_error이면 client socket이 끊어진걸로 처리한다.
if (nRet == SOCKET_ERROR && (WSAGetLastError() != ERROR_IO_PENDING))
{
printf("[에러] WSASend()함수 실패 : %d\n", WSAGetLastError());
return false;
}
return true;
}참고로, SendMsg(...)는 워커 스레드에서 호출되고, SendCompleted(...)는 IO Thread에서 호출된다.
드미트리는 자신의 레포에서 다음과 같이 설명했다.
/**
* A 'lockless' bounded multi-producer, multi-consumer queue
*
* Has the caveat that the queue can *appear* empty even if there are
* returned items within it as a single thread can block progression
* of the queue.
*/큐의 비어있는지 여부를 관측하는 건 논리적으로 오류가 있다는 것.
왜냐하면, 드미트리의 순환큐에서 어떤 스레드가 enqueue_pos_나 dequeue_pos_를 수정하는 데에 속도가 느리다면, 다른 스레드가 해당 인덱스에 대해 이미 처리가 완료된 것으로 판정하기 때문.
그러면 해당 큐의 원소 갯수를 확인하는 건 문제가 있다.
원래 Send 로직에서 큐의 원소를 확인하는 건 피해야 한다.
해결
기존 송신 큐 동작 이해해 보기
튜닝을 하려면 먼저 기존 동작을 완전히 이해해야 한다.
- IOCP 서버는 사용자(나!)가 만든 메모리 공간을 OS에 노출시켜 송신이 완료되면 사용자에게 신호를 준다.
- 사용자(나!)가 만든 메모리 공간을 OS에 노출 -> 이게
SendIO(...)에 구현돼 있다. - 송신이 완료되면 사용자에게 신호를 준다 -> 이게 IO Thread에서 호출하는
SendCompleted(...)에 구현돼 있다. - 또, 게임 로직에서 호출하는
SendMsg(...)는 아직 송신 완료가 되지 않은 패킷을 쌓아두는 큐에 Enqueue한다.
이게 기본적인 구조인데, 이제 여기서 문제된 것은 SendIO(...) 호출 시 조건문이었다.
1. 왜 SendMsg(...)에서는 송신큐에 Enqueue한 다음 큐 크기가 1이면 SendIO(...)를 호출할까? -> 송신큐는 2의 과정에 의해 순환하는데, 여기서 송신큐에 방금 Enqueue한 원소만 있다면 순환이 끊겼다는 얘기.
2. 송신큐가 비어있지 않은 경우 계속 SendIO(...)가 호출되며 순환한다. 만약 더이상 보낼 메시지가 없어서 큐 원소가 고갈되면 이 순환이 끊긴다.
수정된 로직 설명
난 전역에서 접근할 수 있는 배열을 하나 만들었다.
이 배열은 현재 송신 중인 shared_ptr<stOverlappedEx> 값을 저장 중이고, 각 인덱스는 그걸 송신한 세션 인덱스와 일치한다.
(vector<atomic< shared_ptr<stOverlappedEx >>>로 구현해 보려 했으나, vector 내에서 복사를 사용하기에 컴파일이 안되는 문제가 있었음.)
atomic< shared_ptr<stOverlappedEx >>* m_SendBufVec;세션을 초기화할 때 그 세션 인덱스에 해당하는 m_SendBufVec 원소를 넘겨준다.
stClientInfo(atomic< shared_ptr<stOverlappedEx >>& _InOverlappedEx)
: m_OverlappedEx(_InOverlappedEx)
{
// ...
}그러므로 수정된 로직은,
1. m_OverlappedEx가 nullptr이면 SendMsg(...)에서 SendIO(...)를 호출하여 순환을 시작시킨다.
2. SendCompleted(...)는 m_OverlappedEx를 가져와서 처리가 끝나면 다시 풀에 반환한다. 또, 만약 송신큐에 남아 있으면 SendIO(...)를 호출하여 순환하고, 아닐 경우 그냥 m_OverlappedEx에 nullptr 대입.
수정된 코드는 다음과 같다.
bool SendMsg(const UINT32 _InSize, char* _pInMsg)
{
shared_ptr<stOverlappedEx> pSendOverlappedEx;
if (!m_pSendDataPool->dequeue(pSendOverlappedEx))
{
printf("SendMsg Error in Client %d", m_Index);
return false;
}
// some write process...
m_pSendBufQ->enqueue(pSendOverlappedEx);
if (nullptr == m_OverlappedEx.load(memory_order_relaxed))
{
shared_ptr<stOverlappedEx> pFirstSendOverlappedEx;
if (m_pSendBufQ->dequeue(pFirstSendOverlappedEx))
{
m_OverlappedEx.exchange(pFirstSendOverlappedEx, memory_order_acq_rel);
SendIO(pFirstSendOverlappedEx);
}
}
return true;
}
void SendCompleted(const UINT32 dataSize_)
{
printf("[송신 완료] bytes : %d\n", dataSize_);
shared_ptr<stOverlappedEx> pSendOverlappedEx = m_OverlappedEx.load(memory_order_relaxed);
// some process after packet sended...
m_pSendDataPool->enqueue(pSendOverlappedEx);
shared_ptr<stOverlappedEx> pNextSendOverlappedEx;
if (m_pSendBufQ->dequeue(pNextSendOverlappedEx))
{
m_OverlappedEx.exchange(pNextSendOverlappedEx, memory_order_acq_rel);
SendIO(pNextSendOverlappedEx);
}
else
{
m_OverlappedEx.store(nullptr, memory_order_release);
}
}
private:
bool SendIO(const shared_ptr<stOverlappedEx> _pInSendOverlappedEx)
{
DWORD dwRecvNumBytes = 0;
int nRet = WSASend(
m_Socket,
&(_pInSendOverlappedEx->m_wsaBuf),
1,
&dwRecvNumBytes,
0,
(LPWSAOVERLAPPED)_pInSendOverlappedEx.get(), // 구조체는 연속된 메모리 공간에 할당된다 -> 첫번째 멤버의 주소는 곧 그 구조체의 시작지점. 따라서 캐스팅 가능. ㅁㅊ...
NULL);
//socket_error이면 client socket이 끊어진걸로 처리한다.
if (nRet == SOCKET_ERROR && (WSAGetLastError() != ERROR_IO_PENDING))
{
printf("[에러] WSASend()함수 실패 : %d\n", WSAGetLastError());
return false;
}
return true;
}앞으로 해볼 것
전역으로 정의된 m_SendBufVec는 현재 시점의 각 세션의 상태를 담고 있다.
한 프레임에 대한 서버 단에서의 디버그나, 서버 권위 모델에서의 물리 엔진 Tick과 연결시키는 데에 쓸 수 있을 것이다.
다만 그러려면 한 프레임을 관측하는 동안 해당 포인터가 풀로 반환되어 다시 다른 정보가 Write되면 안된다.
이건 Lock을 걸어야 하나?
아토믹만으로는 안되나?
비상!
Smarter Cpp Atomic Smart Pointers에서 atomic<shared_ptr<T>>가 매우 비효율적이라고 이야기했다.
해당 변수를 '읽을 때' (즉, load()를 호출할 때) 참조 카운트를 변경하는데, 이게 그래프 형식으로 이 메모리 위치를 참조한 변수들을 모두 순회하며 이루어지기에 비효율적이라는 것.
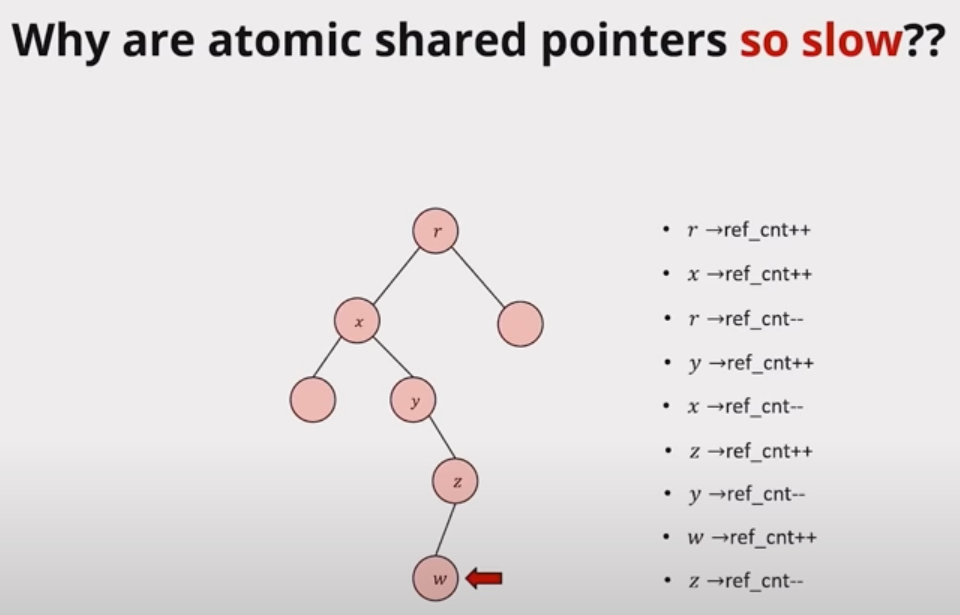
앞으로 전역 배열 m_SendBufVec은 물리엔진과도 연동될 예정인데, 읽기 성능이 떨어지면 안된다.
어쩌지?
unique_ptr은 복사를 못하게 하고, 오로지 이동만 가능하게 한다.
아토믹에서 지원하는 함수들은 내부에서 복사를 한다.
따라서 atomic<unique_ptr<T>>는 안된다.
진짜 어쩌지?
내가 생각한 해결책으로는...
unique_ptr<OverlappedEx> m_pAliveOvlpdEx; // not to deleted when ref cnt go to zoro
atomic<OverlappedEx*>& m_pAtomicOvlpdEx;m_pAliveOvlpdEx는 SendIO(...) 함수가 반환됐을 때 unique_ptr<OverlappedEx>는 참조 카운트가 0이 되지 않도록 막고, 진행중인 송신 로직에서 사용된다.
이건 절대 세션 객체 외부에서 관측하면 안된다.
신뢰할 수 있는 포인터 값은 thread-safe해야 하기에 m_pAtomicOvlpdEx에 저장된다.
이건 외부에서 참조해서 해당 프레임의 세션 객체 상태를 볼 수 있다.
또, m_pAtomicOvlpdEx는 내부에서 m_pAliveOvlpdEx를 사용할 때 안전장치 역할을 한다.
이런 구조가 가능한 이유는,
1. 세션 하나의 동작만 봤을 때, 송신 중인 메시지는 언제나 한개다. 이미 우리는 SendMsg(...)가 언제나 하나의 스레드에서만 호출되도록 개발에 있어서 제한을 걸어뒀다.
2. 세션 객체 외부에서 관측한 m_pAtomicOvlpdEx의 값이 내부의 m_pAliveOvlpdEx와 값이 다를 수 있지만, 그래봤자 한두 프레임 차이이기에 리니어한 데이터 변화를 그려내기엔 부족함이 없다.
이걸 기반으로 위 세 함수를 고치면 된다...
bool SendMsg(const UINT32 _InSize, char* _pInMsg)
{
unique_ptr<OverlappedEx> pSendOvlpdEx;
if (!m_pSendDataPool->dequeue(pSendOvlpdEx))
{
printf("[SendMsg] : Error in Client %d", m_Index);
return false;
}
// some write process...
m_pSendBufQ->enqueue(pSendOvlpdEx);
// If there are no messages currently in the process of being sent
if (nullptr == m_pAtomicOvlpdEx.load(memory_order_relaxed))
{
if (m_pSendBufQ->dequeue(m_pAliveOvlpdEx))
{
m_pAtomicOvlpdEx.store(m_pAliveOvlpdEx.get(), memory_order_release);
SendIO(m_pAliveOvlpdEx);
}
else
{
printf("[SendMsg] : Error while dequeue from send buf q, data race is suspected");
return false;
}
}
return true;
}
void SendCompleted(const UINT32 dataSize_)
{
printf("[송신 완료] bytes : %d\n", dataSize_);
// some process after packet sended...
m_pSendDataPool->enqueue(m_pAliveOvlpdEx);
if (m_pSendBufQ->dequeue(m_pAliveOvlpdEx))
{
m_pAtomicOvlpdEx.exchange(m_pAliveOvlpdEx.get(), memory_order_acq_rel);
SendIO(m_pAliveOvlpdEx);
}
else
{
m_pAliveOvlpdEx = nullptr;
m_pAtomicOvlpdEx.exchange(nullptr, memory_order_release);
}
}
private:
bool SendIO(const unique_ptr<OverlappedEx>& _pInSendOverlappedEx)
{
DWORD dwRecvNumBytes = 0;
int nRet = WSASend(
m_Socket,
&(_pInSendOverlappedEx->m_wsaBuf),
1,
&dwRecvNumBytes,
0,
(LPWSAOVERLAPPED)_pInSendOverlappedEx.get(), // 구조체는 연속된 메모리 공간에 할당된다 -> 첫번째 멤버의 주소는 곧 그 구조체의 시작지점. 따라서 캐스팅 가능. ㅁㅊ...
NULL);
//socket_error이면 client socket이 끊어진걸로 처리한다.
if (nRet == SOCKET_ERROR && (WSAGetLastError() != ERROR_IO_PENDING))
{
printf("[에러] WSASend()함수 실패 : %d\n", WSAGetLastError());
return false;
}
return true;
}