진행하는 프로젝트 에서 INPUT에 대하여 이미지 유사도를 계산하여 비슷한 이미지를 뽑아줄 수 있는 딥러닝 기반의 이미지 추출 방안이 필요하여 멘토님께서 추천해주신 방법이다.
해당코드는 한 쪽에서는 이미지를 더 작은 차원으로 압축하도록 Autoencoder를 훈련시킨 다음 Auutoenconder의 Latent Space와 원하는 그림 사이의 유클리드 거리를 계산하여 Flipkart 이미지 데이터 세트에서 유사한 것을 찾을 수 있도록 구성되어 있다.
코드는 VGG16 기반으로 코드가 구성되어 있다.
해당 코드를 우리 작물 분류 프로젝트에 사용하기 위해서 데이터셋을 구성하고 진행해 보았다.
AutoEncoder 구조
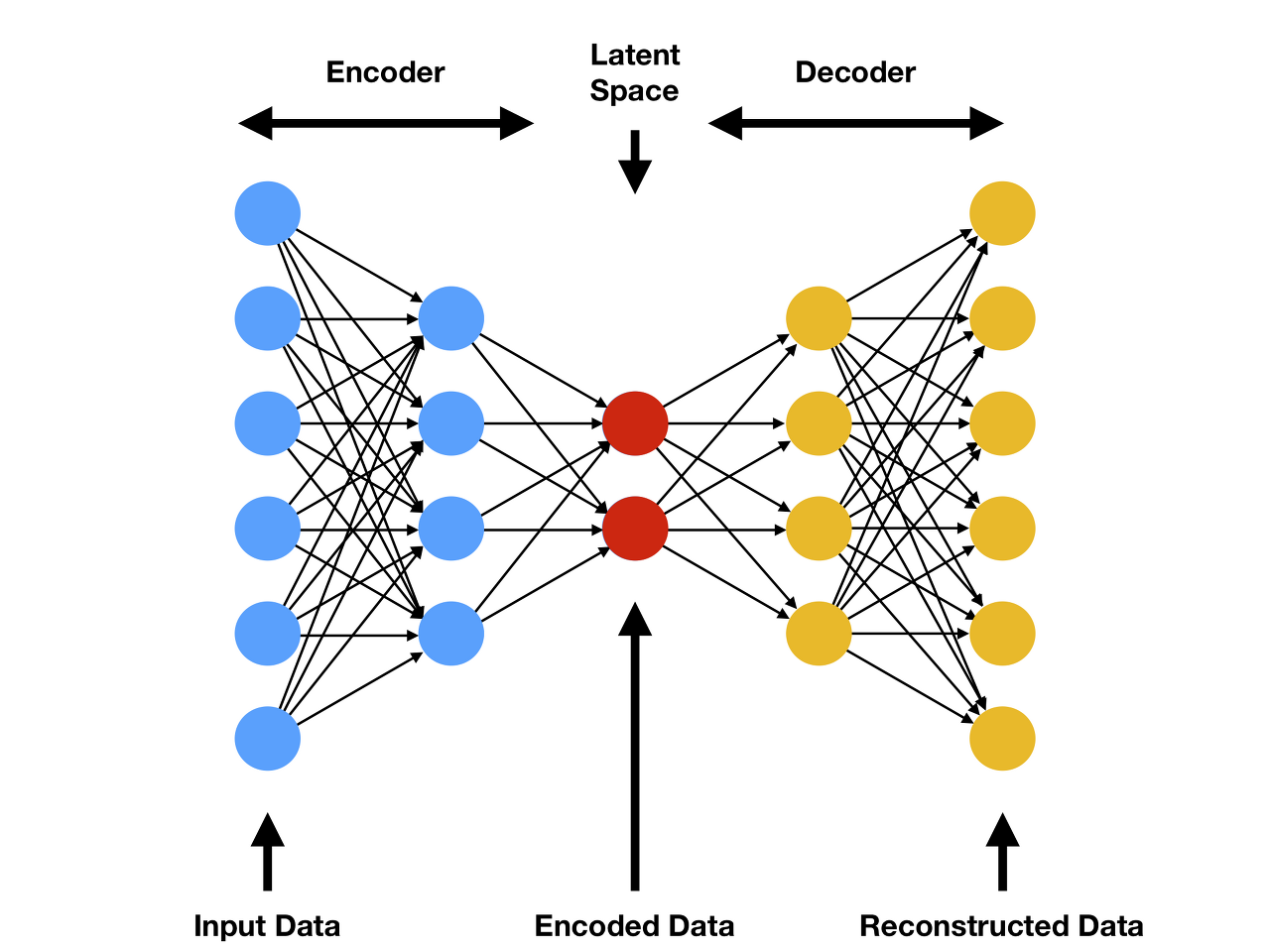
사양은 다음과 같다
- pandas
- numpy
- tqdm
- requests
- tensorflow==2.3.1
- pillow
- matplotlib
주피터 노트북 기반으로 코드를 사용하여 진행해 보았다.
필요 패키지 IMPORT
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
from tensorflow.keras.models import Model, load_model
from tensorflow.keras.layers import Flatten, Conv2D, Conv2DTranspose, LeakyReLU, BatchNormalization, Input, Dense, Reshape, Activation, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ModelCheckpoint
import tensorflow.keras.backend as K
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook as tqdm
import pickle
import pandas as pd
from difflib import SequenceMatcher
import os
Data 구성
먼저 데이터셋을 구성해 주었다.
각각의 클래스 마다 200장씩 병해 데이터를 넣어주었다.
filekart/ images_2안에 폴더를 구성해주고 코드를 실행하면
자동적으로 trainset과 testset을 구성해 준다.
img_size와 batch_size를 컴퓨터 사양에 맞게 잘 구성해주자, gpu 메모리에 오류가 뜰 수 있다.
Load images
img_height = 256
img_width = 256
channels = 3
batch_size = 16
train_datagen = ImageDataGenerator(#rotation_range=40,
#width_shift_range=0.2,
#height_shift_range=0.2,
rescale=1./255,
#shear_range=0.2,
#zoom_range=0.2,
#horizontal_flip=True,
#fill_mode='nearest',
validation_split=0.2)
training_set = train_datagen.flow_from_directory(
'./flipkart/images_2',
target_size = (img_height, img_width),
batch_size = batch_size,
class_mode = 'input',
subset = 'training',
shuffle=True)
validation_set = train_datagen.flow_from_directory(
'./flipkart/images_2',
target_size = (img_height, img_width),
batch_size = batch_size,
class_mode = 'input',
subset = 'validation',
shuffle=False)
Found 1280 images belonging to 9 classes.
Found 320 images belonging to 9 classes.모델 구성
VGG 16 기반으로 해당 모델을 구성해본다
Define the autoencoder
input_model = Input(shape=(img_height, img_width, channels))
# Encoder layers
encoder = Conv2D(32, (3,3), padding='same', kernel_initializer='normal')(input_model)
encoder = LeakyReLU()(encoder)
encoder = BatchNormalization(axis=-1)(encoder)
encoder = Conv2D(64, (3,3), padding='same', kernel_initializer='normal')(encoder)
encoder = LeakyReLU()(encoder)
encoder = BatchNormalization(axis=-1)(encoder)
encoder = Conv2D(64, (3,3), padding='same', kernel_initializer='normal')(input_model)
encoder = LeakyReLU()(encoder)
encoder = BatchNormalization(axis=-1)(encoder)
encoder_dim = K.int_shape(encoder)
encoder = Flatten()(encoder)
# Latent Space
latent_space = Dense(16, name='latent_space')(encoder)
# Decoder Layers
decoder = Dense(np.prod(encoder_dim[1:]))(latent_space)
decoder = Reshape((encoder_dim[1], encoder_dim[2], encoder_dim[3]))(decoder)
decoder = Conv2DTranspose(64, (3,3), padding='same', kernel_initializer='normal')(decoder)
decoder = LeakyReLU()(decoder)
decoder = BatchNormalization(axis=-1)(decoder)
decoder = Conv2DTranspose(64, (3,3), padding='same', kernel_initializer='normal')(decoder)
decoder = LeakyReLU()(decoder)
decoder = BatchNormalization(axis=-1)(decoder)
decoder = Conv2DTranspose(32, (3,3), padding='same', kernel_initializer='normal')(decoder)
decoder = LeakyReLU()(decoder)
decoder = BatchNormalization(axis=-1)(decoder)
decoder = Conv2DTranspose(3, (3, 3), padding="same")(decoder)
output = Activation('sigmoid', name='decoder')(decoder)
# Create model object
autoencoder = Model(input_model, output, name='autoencoder')
# Model Summary
autoencoder.summary()모델 실행
모델을 컴파일 해주고,
earlystopping 사용해서 과적합이 방지되도록 해준다.
# Compile the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
history = model.fit_generator(
training_set,
steps_per_epoch=training_set.n // batch_size,
epochs=50
validation_data=validation_set,
validation_steps=validation_set.n // batch_size,
callbacks = [ModelCheckpoint('models/image_vgg_2.h5', monitor='val_loss', verbose=0, save_best_only=True, save_weights_only=False),
EarlyStopping( monitor='val_loss', min_delta=0, patience=5, restore_best_weights=True)])
# Save model
#autoencoder.save('models/image_autoencoder_2.h5')Loss 값 시각화
# Plot Accuracy and Loss
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training Loss')
plt.plot(epochs, val_loss, 'r', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()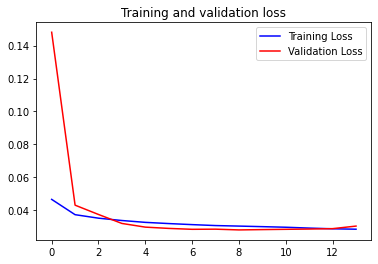
모델을 로드하고 유사한 이미지를 확인해 보자
모델로드
# Create model with latent space layer
autoencoder = load_model('models/image_autoencoder_2.h5', compile=False)
latent_space_model = Model(autoencoder.input, autoencoder.get_layer('latent_space').output)유사도를 계산하기 위해서 이미지들을 로드하고 정규화, Flatten해주고 Pickle로 저장해 준다.
# Load all images and predict them with the latent space model
X = []
indices = []
img_list = os.listdir('./flipkart/images_2/')[2:]
for j in img_list:
for i in range(len(os.listdir(f'./flipkart/images_2/{j}/'))):
try:
img_name = os.listdir(f'./flipkart/images_2/{j}/')[i]
img = load_img(f'./flipkart/images_2/{j}/{img_name}', target_size = (256, 256))
img = img_to_array(img) / 255.0
img = np.expand_dims(img, axis=0)
pred = latent_space_model.predict(img)
pred = np.resize(pred, (16))
X.append(pred)
indices.append(img_name)
# Export the embeddings
if i in [1,10,100,500,1000,2000,3000,4000,5000,6000,7000,8000,9000,10000,12000,13000,14000,15000,16000,17000,18000,19000]:
embeddings = {'indices': indices, 'features': np.array(X)}
pickle.dump(embeddings, open('./flipkart/image_embeddings_2.pickle', 'wb'))
except:
print(img_name)
img_list = os.listdir('./flipkart/images_2/')[2:]
show_list = []
labels_list = []
for i in img_list:
cnt_list = len(os.listdir(f'./flipkart/images_2/{i}'))
lab_list = i[-1]
for j in range(cnt_list):
show_list.append(os.listdir(f'./flipkart/images_2/{i}')[j][:-4])
labels_list.append(lab_list)메타 데이터 구성
matadata = pd.DataFrame({"id":show_list, "category": labels_list})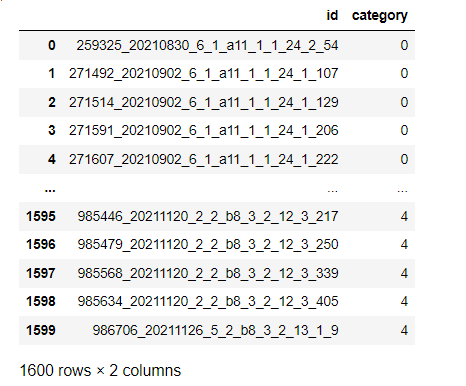
matadata["category"].value_counts()Out[40]:
0 200
2 200
1 200
6 200
8 200
3 200
5 200
4 200
Name: category, dtype: int64
이미지 유사도 함수 정의
유클리드와 카테고리 유사도를 계산해 준다
def eucledian_distance(x,y):
eucl_dist = np.linalg.norm(x - y)
return eucl_dist
def category_similarity(x,y):
return SequenceMatcher(None, x, y).ratio()
# Load embeddings
embeddings = pickle.load(open('./flipkart/image_embeddings_2.pickle', 'rb'))
# Load images metadata
metadata = pd.DataFrame({"id":show_list, "category": labels_list})넣을 INPUT 이미지를 정의 해준다.
# Get image name
img_name = os.listdir('./flipkart/images_2/class5/')[55]
img = load_img('./flipkart/images_2/class5/{}'.format(img_name), target_size=(256, 256))
유사도를 계산하여 하고 유사도 기준 정렬하여 거리가 가까운 데이터를 보여줌
# Calculate eucledian distance
img_similarity = []
cat_similarity = []
# Get actual image embedding
img = img_to_array(img) / 255.0
img = np.expand_dims(img, axis=0)
pred = latent_space_model.predict(img)
pred = np.resize(pred, (16))
img_cat = metadata.query("id == '{}'".format(img_name.replace('.jpg','')))['category'].values[0]
print('Image Category: {}'.format(img_cat))
for i in range(len(embeddings['indices'])):
img_name = embeddings['indices'][i]
# Calculate vectors distances
dist = eucledian_distance(pred,embeddings['features'][i])
img_similarity.append(dist)
# Calculate categoy similarity
cat = metadata.query("id == '{}'".format(img_name.replace('.jpg','')))['category'].values[0]
cat_sim = category_similarity(img_cat, cat)
cat_similarity.append(cat_sim)
imgs_result = pd.DataFrame({'img': embeddings['indices'],
'euclidean_distance': img_similarity,
'category_similarity': cat_similarity})
imgs_result = imgs_result.query('euclidean_distance > 0').sort_values(by='euclidean_distance', ascending=True).reset_index(drop=True)
imgs_result = imgs_result.iloc[0:20,:].sort_values(by='category_similarity', ascending=False).reset_index(drop=True)
# Show 10 first similar images
for i in range(10):
image = load_img('./flipkart/images_2/class5/{}'.format(imgs_result['img'].values[i]))
category = metadata.query("id == '{}'".format(imgs_result['img'].values[i].replace('.jpg','')))['category'].values[0]
# Show image
plt.imshow(image)
plt.show()
print('Image Category: {}'.format(category))
print('Euclidean Distance: {}'.format(imgs_result['euclidean_distance'].values[i]))
print('Category Distance: {}'.format(imgs_result['category_similarity'].values[i]))
몇개 실험을 해보았는데, 그래도 유사도 기반으로 가까운 값들이 잘 출력 되엇다.

