
📌 DataFrame
Pandas에서 주로 다루는 단위Spreadsheet와 같은 개념Structured Data,Panel Data또는Tabular Data
데이터프레임 특징
- 행과 열로 만들어지는 2차원 배열 구조
- 2차원 행렬 데이터에 인덱스를 붙인 것
- R의 데이터프레임에서 유래
- 데이터프레임의 각 열은 시리즈로 구성
📌 DataFrame 생성
DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
data: array-like, Iterable, dict, or scalar valueindex: index or array-likecolumns: index or array-likedtype: dtype- Pandas DataFrame Docs 참조
1️⃣ 리스트 활용 DataFrame 생성
DataFrame([[list1],[list2], ... [list3]])- 각
list는 한 행으로 구성 - 행의 원소 개수가 다르면
None값으로 저장
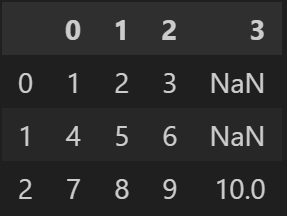
# 마지막 리스트 길이가 달라 해당 인덱스에는 NaN 저장
df2 = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9, 10]])
df2- 출력
2️⃣ 딕셔너리 활용 DataFrame 생성
- 딕셔너리의
key값이column으로 설정된다.
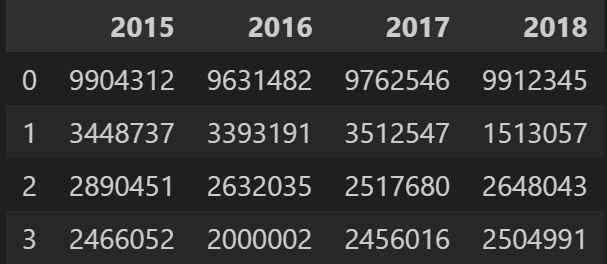
예시 데이터
data = {
'2015': [9904312, 3448737, 2890451, 2466052],
'2016': [9631482, 3393191, 2632035, 2000002],
'2017': [9762546, 3512547, 2517680, 2456016],
'2018': [9912345, 1513057, 2648043, 2504991]
}
datadf3 = pd.DataFrame(data=data)
df3- 출력
3️⃣ 시리즈 활용 DataFrame 생성
- 시리즈의
index가column으로 설정된다.
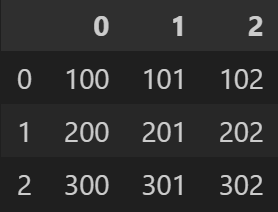
인덱스 없는 경우
s1 = pd.Series(data=[100, 101, 102])
s2 = pd.Series(data=[200, 201, 202])
s3 = pd.Series(data=[300, 301, 302])
pd.DataFrame(data=[s1, s2, s3])- 출력
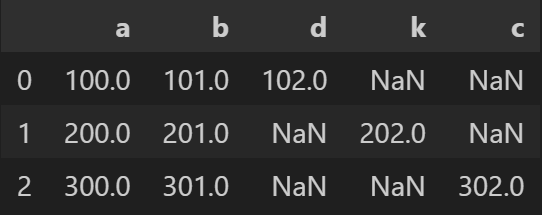
인덱스 있는 경우
s1 = pd.Series(data=[100, 101, 102], index='a b d'.split())
s2 = pd.Series(data=[200, 201, 202], index='a b k'.split())
s3 = pd.Series(data=[300, 301, 302], index='a b c'.split())
pd.DataFrame(data=[s1, s2, s3])- 출력
데이터프레임 인덱스 설정
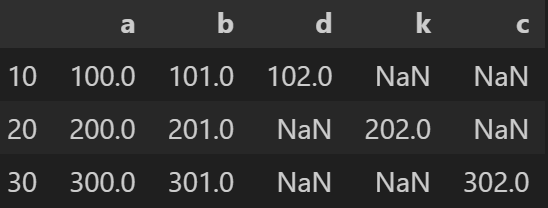
pd.DataFrame(data=[s1, s2, s3], index=[10, 20, 30])- 출력
4️⃣ CSV 데이터 활용 DataFrame 생성
- 데이터 분석을 위해
dataframe을 생성하는 가장 일반적인 방법 - 데이터 소스로부터 추출된
csv(comma separated values) 파일로부터 생성 pandas.read_csv()함수 사용
pd.read_csv()
sep: 각 데이터 값을 구별하기 위한 구분자(separator) 설정header:header를 무시할 경우,None설정index_col:index로 사용할column설정usecols: 실제로dataframe에 로딩할columns만 설정
예시 데이터
- Kaggle 의 대표적인 데이터인
Titanic데이터 - Titanic 데이터 다운로드 링크
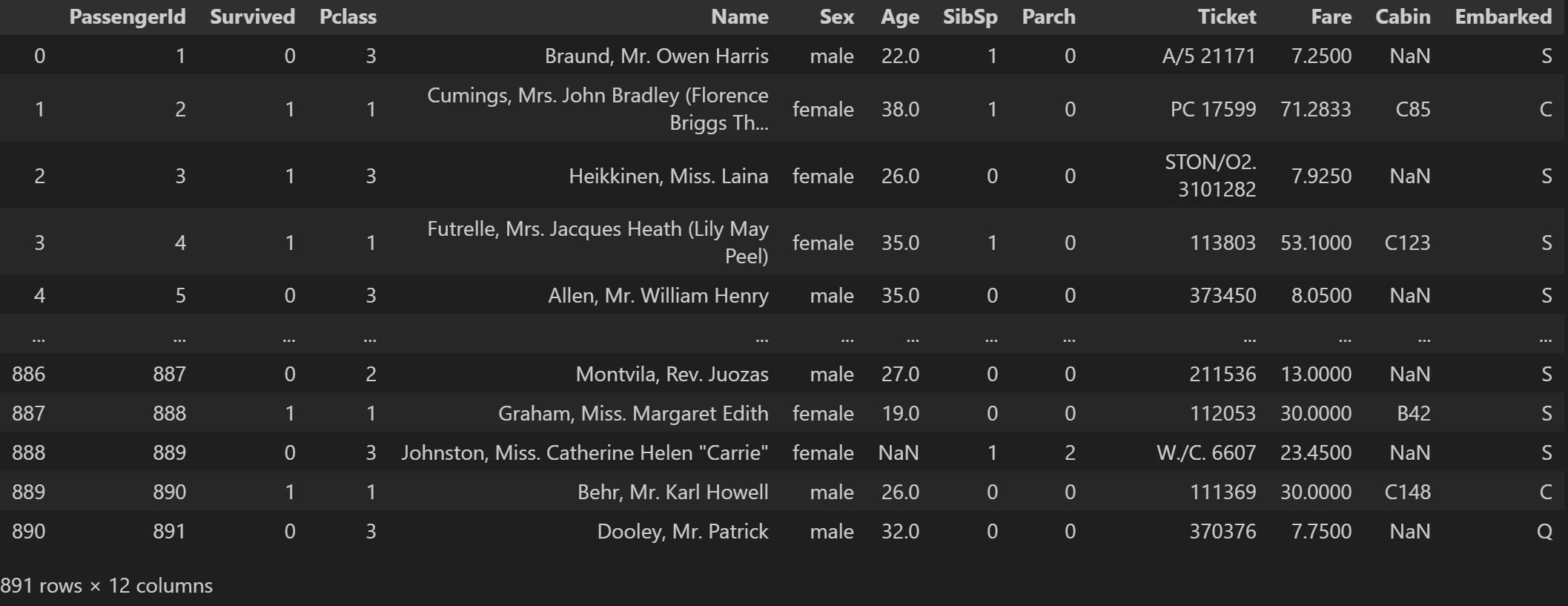
df_tit = pd.read_csv('data/train.csv')
df_tit- 출력
각 컬럼의 데이터 개수
NaN값이 아닌 데이터 개수를 출력한다.
df_tit.count()- 출력
PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64특정 컬럼 사용 데이터프레임 생성
index_col: 인덱스로 사용할 컬럼 설정usecols: 사용할 컬럼 선정
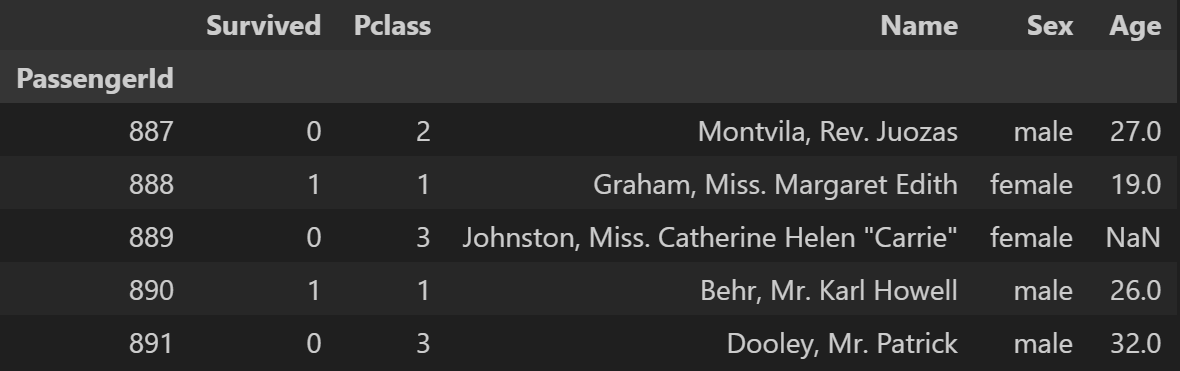
df_tit2 = pd.read_csv('data/train.csv', index_col='PassengerId',
usecols=['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age'])
df_tit2.tail() - 출력
데이터프레임 CSV 파일 저장
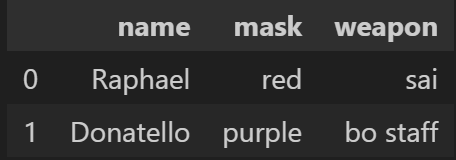
df4 = pd.DataFrame({'name': ['Raphael', 'Donatello'],
'mask': ['red', 'purple'],
'weapon': ['sai', 'bo staff']})
df4- 출력
df.to_csv(filepath): 저장할 경로를 지정data폴더 안에csv파일로 저장된 것을 확인할 수 있다.
df4.to_csv('data/sample.csv')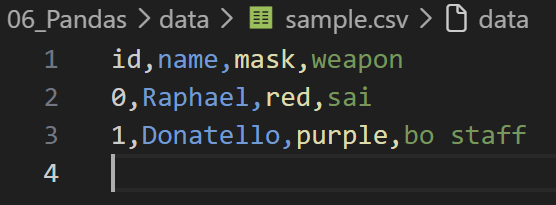
📌 DataFrame 구조
인덱스(index)
index속성- 각 아이템을 특정할 수 있는 고유의 값을 저장
- 복잡한 데이터의 경우, 멀티 인덱스로 표현 가능
컬럼(columns)
columns속성- 각각의 특성(feature)을 나타냄
- 복잡한 데이터의 경우, 멀티 컬럼으로 표현 가능
1️⃣ 행/열 인덱스 출력
열 인덱스
df4.index- 출력
RangeIndex(start=0, stop=2, step=1, name='id')행 인덱스
df4.columns- 출력
Index(['name', 'mask', 'weapon'], dtype='str')2️⃣ 행/열 인덱스 이름 설정
index.namecolumns.name
df4.index.name
df4.columns.name = 'attr'
df4- 출력
'id'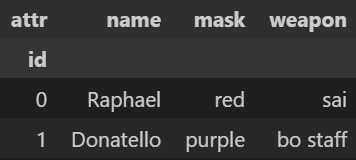
3️⃣ 데이터프레임 값 접근
df.values
df4.values- 출력
array([['Raphael', 'red', 'sai'],
['Donatello', 'purple', 'bo staff']], dtype=object)