RAG 기본
참고 논문: Retrieval-Augmented Generation for Large Language Models: A Survey
-
모델 파라미터에만 의존해 생성하는 것이 아니라 외부 정보도 활용하여 생성하는 시스템
-
논문에서는 QA를 위해 사용되었지만 LLM 활용 대화 시스템에도 최근 많이 사용되는듯
-
기존 대화 시스템이나 LLM만을 사용했을 때 보다 확장성, 유연성, 정확성이 향상됨
-
확장성: LLM이나 파인튜닝된 모델은 학습이 종료된 시점에 멈추게 됨, 최신 정보 활용이 불가하지만 RAG는 실시간 검색이 가능하므로 데이터 변동성이 큰 경우 효과적
-
유연성: 최신 문서나 정책 업로드를 통해 사용자 맞춤형 답변 생성 가능
-
정확성: 외부 소스 사용을 통한 할루시네이션 최소화 가능
RAG vs Fine-tuning
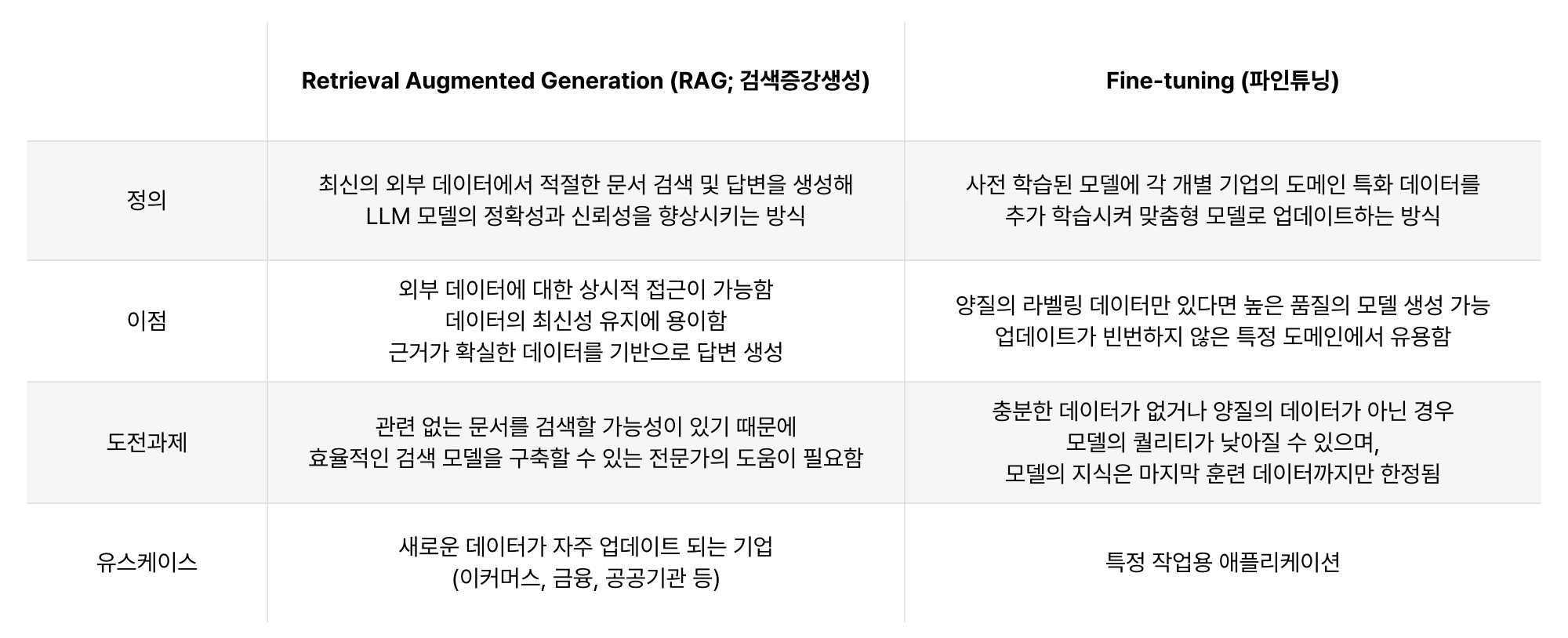
- 파인 튜닝 모델은 품질에 의존적, 최신 상태 업데이트하기 어려움, 따라서 변화가 잦은 데이터에 대해서는 RAG를 사용하는 것이 유리
RAG 심화
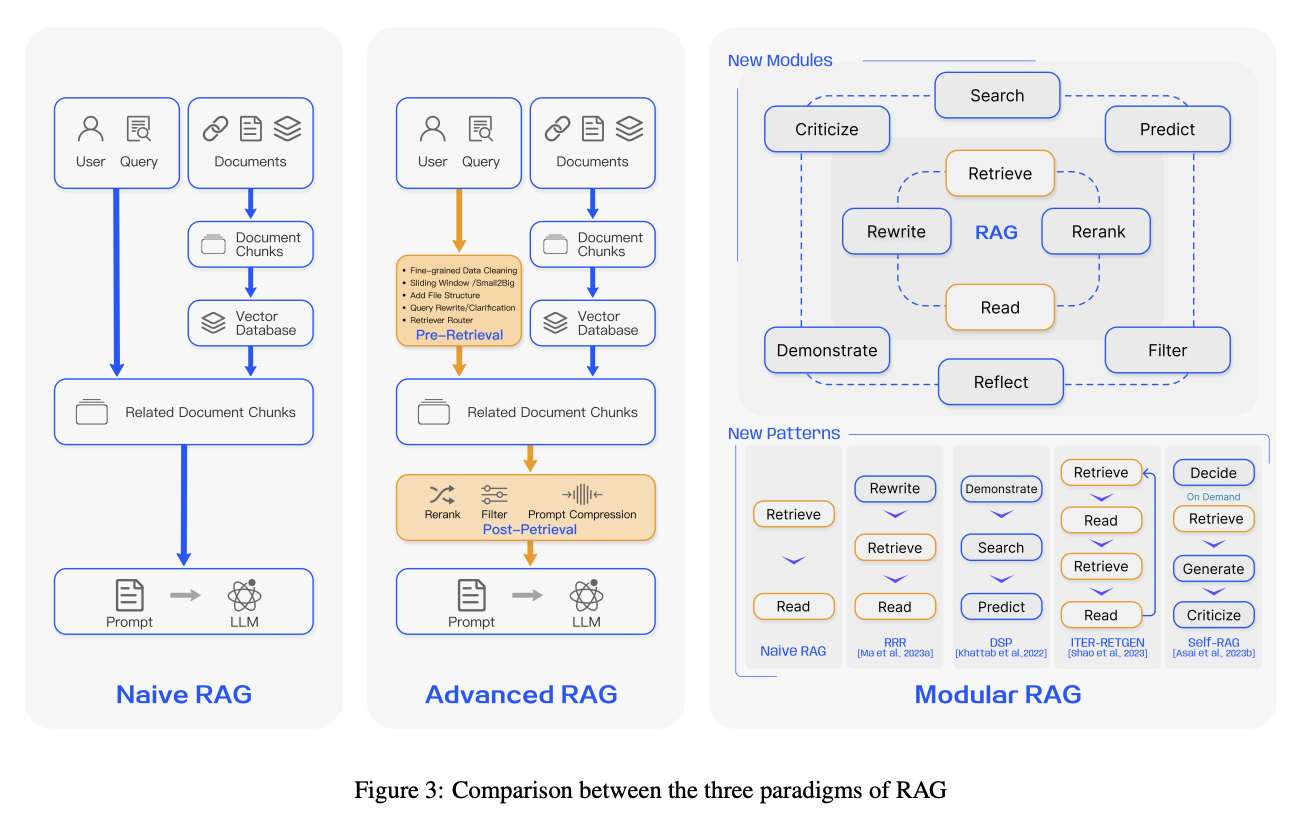
Naive RAG
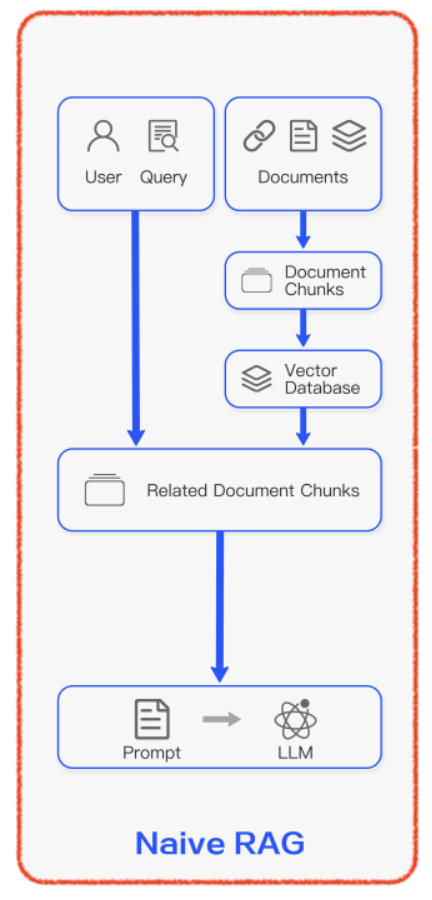
-
전통적인 인덱싱, 검색 및 생성 과정으로 구성
-
낮은 검색 정확도, 응답 생성의 낮은 품질, 증강 과정의 어려움에 따라 발생하는 반복, 부정확, 잘못된 문맥의 통합 등의 발생 가능
인덱싱
-
데이터 인덱싱: 데이터 소스에서 데이터를 얻고 원본 데이터를 정제, 추출
-
청크 분할: 데이터를 청크로 나눔, 언어 모델 입력 한계 때문에 가능한 작은 텍스트 청크를 생성해야하며 검색 과정에서 모델이 처리할 수 있는 데이터의 양을 최적화
-
임베딩 및 인덱스 생성: 텍스트를 벡터로 인코딩, 계산된 벡터는 질문 벡터와 유사성을 계산하는 데 사용됨, 청크-임베딩을 키-값 쌍으로 저장
검색
- 사용자 입력을 벡터화, 문서 청크 벡터들 간 유사성을 계산하여 상위 K 청크 선택
생성
- 질문 + 검색된 청크 -> 프롬프트 -> LLM 생성
Advanced RAG
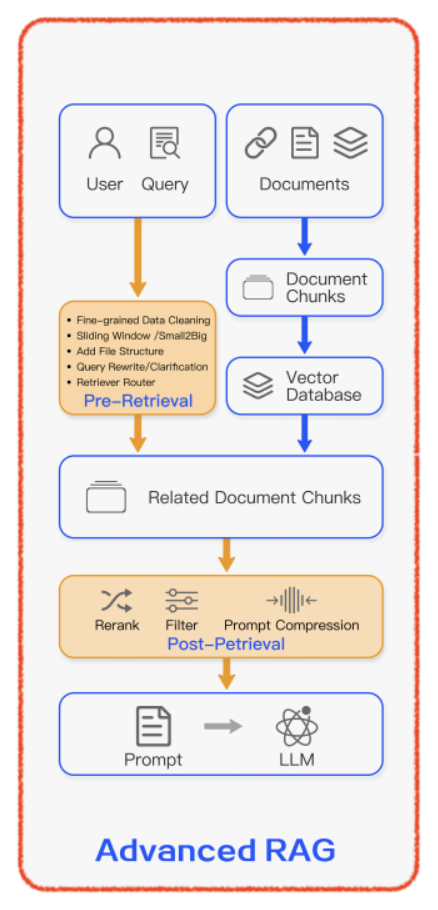
- Naive RAG의 단점 개선을 위해 개발, 검색/생성의 질을 향상시키기 위한 검색 사전/사후 추가 절차를 포함
Pre-Retrieal Process
데이터 인덱싱 최적화
- 데이터 세분화 강화, 인덱스 구조 최적화, 메타데이터 정보 추가, 정렬 최적화, 혼합 검색
임베딩
- 정밀 조정 임베딩, 동적 임베딩
Post-Retrieval Process
- ReRank, Prompt Compression
RAG Pipeline Optimization
- Hybrid Search, Recursive Retrieval and Query Engine, StepBack-prompt, Subqueries, Hypothetical Document Embeddings
Modular RAG
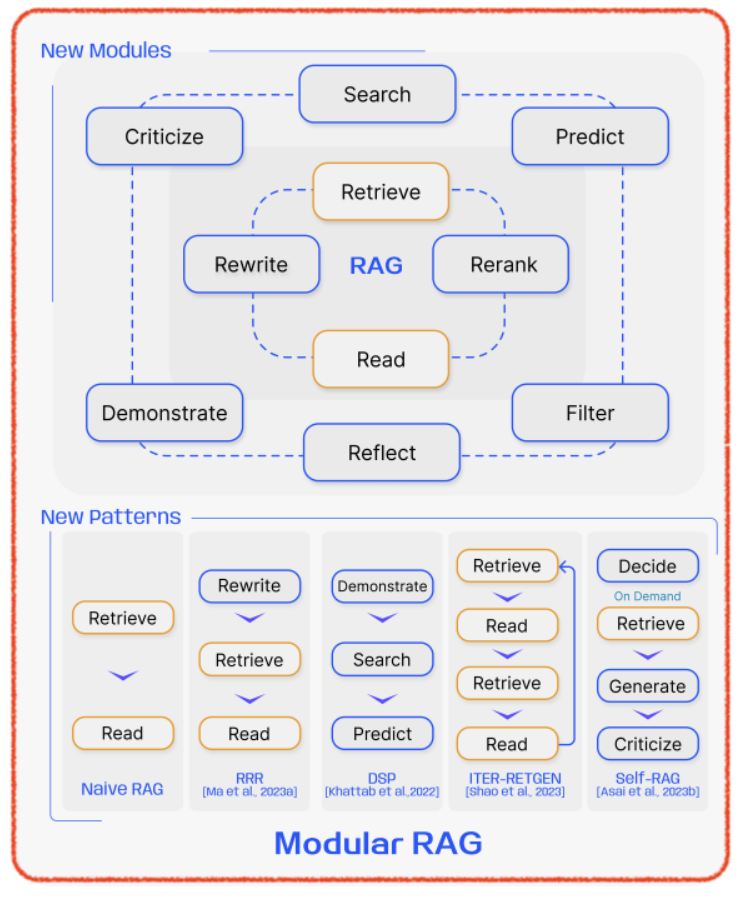
-
모듈과 기능을 통합하여 더 큰 다양성과 유연성 제공
-
검색 모듈, 메모리 모듈, 추가 생성 모듈, 태스크 적응 모듈, 정렬 모듈, 검증 모듈
-
모듈 추가 또는 교체, 모듈 간 조직적 흐름 조정을 통해 시스템 구성
