
서울시 관서별 5대 범죄 현황 데이터 분석
서론
EDA 파트로 들어가서 이제 기존처럼 코드가 3~40줄로 끝나는게 아닌 ipynb 파일로 바뀌고 전체 코드를 가져 오기도 애매한 상황이라 github에 그때 그때 업로드하는 방법으로 진행 할려고 합니다. 겸사겸사 잡초심기 따라서 이제부터는 수업 들으면서 중요했던 포인트만 정리하는 방식으로 진행하겠습니다.
흐름 정리
지난번 서울시 cctv 비율에 이어서 이번에는 서울에서 발생하는 5대 범죄에 대해서 데이터를 시각화하는 과정을 정리하였습니다.
1. 데이터 정리
우선 주어진 데이터셋을 불러와 확인을 해보면
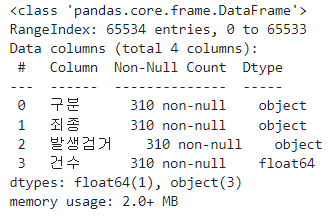
다음과 같이 값이 들어있는 데이터는 310개씩 존재 하나 65534개의 인덱스가 존재한다고 하니 이것을 notnull() 기능을 사용하여 NAN으로 되어있는 결측값을 제거한 데이터를 crime_raw_data에 새로 대입 해줍니다.

thousands=','를 사용하는 이유
숫자 데이터를 불러올 때 1000이 넘어가는 숫자의 경우 ','가 들어가게 되는데 보기에는 가독성이 좋지만 데이터를 가공할 때는 방해가 되므로 해당 명령을 사용하여 제거 하였다.
2. 서울시 범죄 현황 데이터 정리
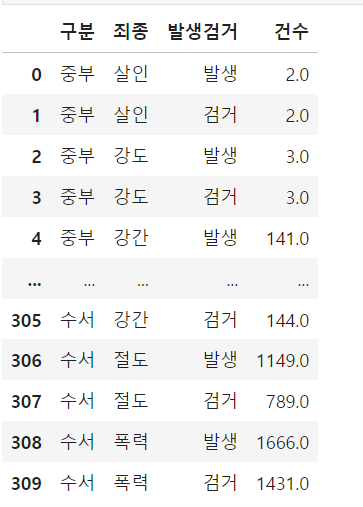
데이터를 불러왔으나 다음과 같이 가독성이 너무 떨어지는데 이럴때 pivot_table 기능을 사용하여 다음과 같이 구분 컬럼을 기준으로 죄종과 발생검거를 기준으로 재정렬을 해줍니다.
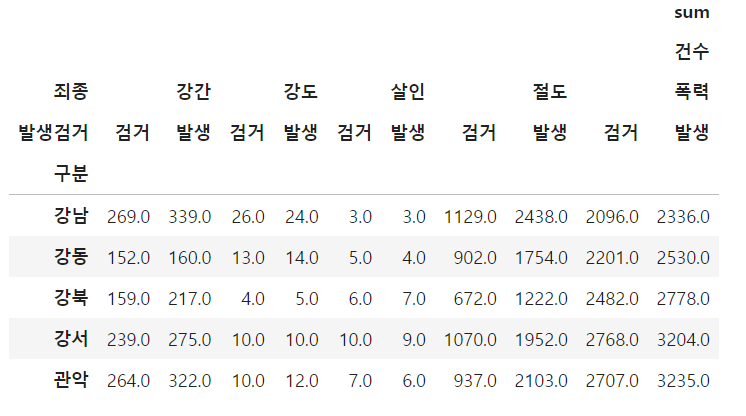
그러면 다음과 같이 꼬다리(?) 같은게 생기게 되는데 이는 '검거' '발생'의 위치가 'sum', '건수', '강도', '검거' 와 같이 잡히 때문인데 이럴때 droplevel()기능을 사용하여 해당 부분을 제거 해주면 다음과 같이 바뀌게 됩니다.
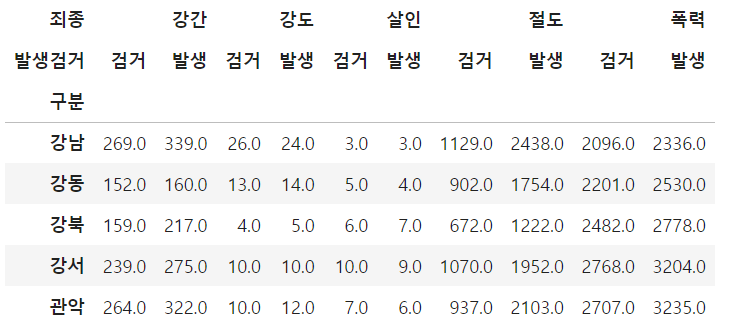
3. Google Map Api 활용
위에서 정리한 데이터를 바로 CCTV데이터와 합치면 좋겠지만 위의 데이터의 구분은 해당 지역이 아닌 경찰서의 이름이기 때문에 대응되는 지명으로 바꿔줘야 할 필요가 생깁니다. 이를 위해 구글맵 API를 사용하여 경도, 위도, 지역 데이터를 불러와줍니다.
[{'address_components': [{'long_name': '동작구',
'short_name': '동작구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']}],
'formatted_address': '대한민국 서울특별시 동작구',
'geometry': {'bounds': {'northeast': {'lat': 37.51762799999999,
'lng': 126.9853836},
'southwest': {'lat': 37.4753761, 'lng': 126.9031979}},
'location': {'lat': 37.4988794, 'lng': 126.9516345},
'location_type': 'APPROXIMATE',
'viewport': {'northeast': {'lat': 37.51762799999999, 'lng': 126.9853836},
'southwest': {'lat': 37.4753761, 'lng': 126.9031979}}},
'partial_match': True,
'place_id': 'ChIJgYYqF3iffDURmGQzSoStNBU',
'types': ['political', 'sublocality', 'sublocality_level_1']}]동작구경찰서의 위치정보를 불러오면 다음과 같은 값을 불러 올 수 있게되는데 1개의 리스트안에 들어가 있는 딕셔너리 형태이므로 [0]로 감싼다음 get으로 각각의 value값을 가져올수있도록 합니다. 강의 대로 진행시 여기서 오류가 날 수 있으니 하단 참조
count = 0
for idx, rows in crime_station.iterrows():
station_name = '서울' + str(idx) + '경찰서'
# print(station_name)
tmp = gmaps.geocode(station_name, language='ko')
tmp_gu = tmp[0].get('formatted_address').split()[2]
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
crime_station.loc[idx, '구별'] = tmp_gu
count += 1
print(count)4. 데이터프레임 정리
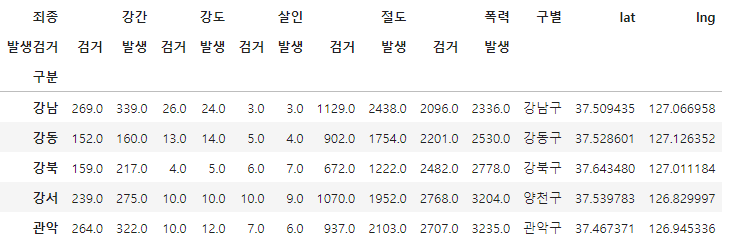
위 그림과 같은 강도 검거 발생 처럼 가독성이 떨어지는 데이터프레임을 하단 코드를 사용하여 한줄로 볼수있도록 다듬어줍니다.
tmp = [
crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
tmp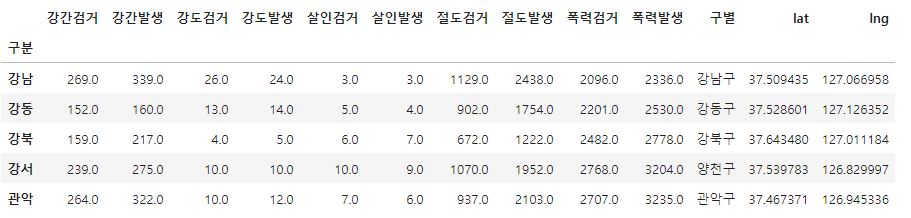
5. 데이터 합치기
지난번에 정리했던 CCTV 데이터를 불러와 구별 컬럼이 인덱스가 되도록 pivot_table을 만들어줍니다. 또 사용하지 않을 위도 경도 데이터를 제거해줍니다.
crime_anal_gu = pd.pivot_table(crime_anal_station, index='구별', aggfunc=np.sum)
del crime_anal_gu['lat']
crime_anal_gu.drop('lng', axis=1, inplace=True)
crime_anal_gu.head()
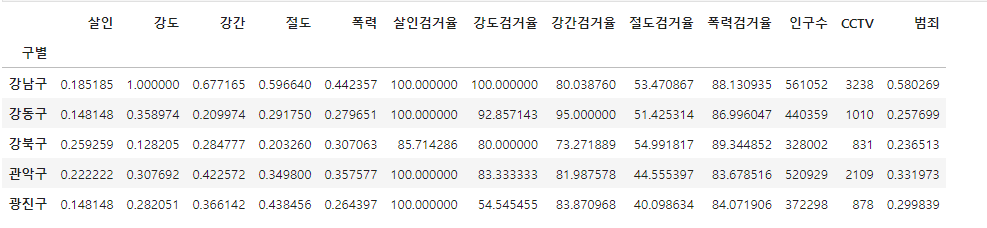
target = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100
crime_anal_gu.head()검거율을 퍼센트로 나타내기위해 검거 컬럼을 발생 컬럼으로 나눠주고 검거데이터들을 삭제하고 발생 컬럼의 이름을 재정의 해줍니다.
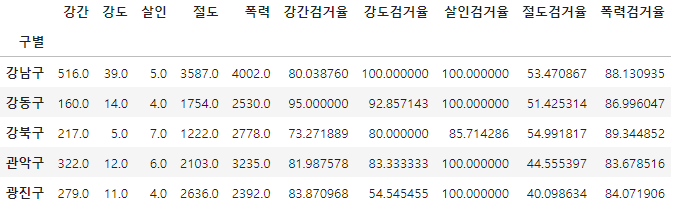
6.범죄데이터 정렬을 위한 데이터 정리
이제 이 데이터들을 그래프로 나타내야하는데 어떤 데이터는 0~10 정도의 값을 가지는데 어떤 데이터는 0~3000정도를 가지고 있으면 데이터의 차이를 쉽게 비교하기 어렵기 때문에 여기서는 각 컬럼에서 가장 큰 값을 전체 컬럼의 데이터에 나눠주어 정규화 하였습니다. 음수가 썩여있을때는 안됌!!
col = ['살인', '강도', '강간', '절도', '폭력']
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm.head()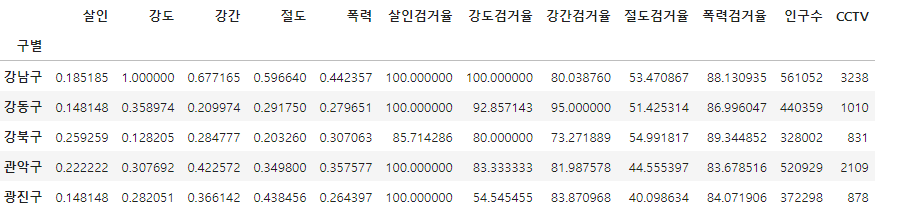
이제 범죄검거율의 평균을 구해 범죄 컬럼에 추가해줍니다.
이후에는 파트 2에서 이어서 작성합니다~!!
read_excel 오류 - 1
엑셀 파일을 불러올려고 하면 오류가 날 것이다.
pip install openpyxl
아래 코드를 주피터 노트북에 한번 딸깍 해주자 해결 될 것
Google Map API 오류 - 2
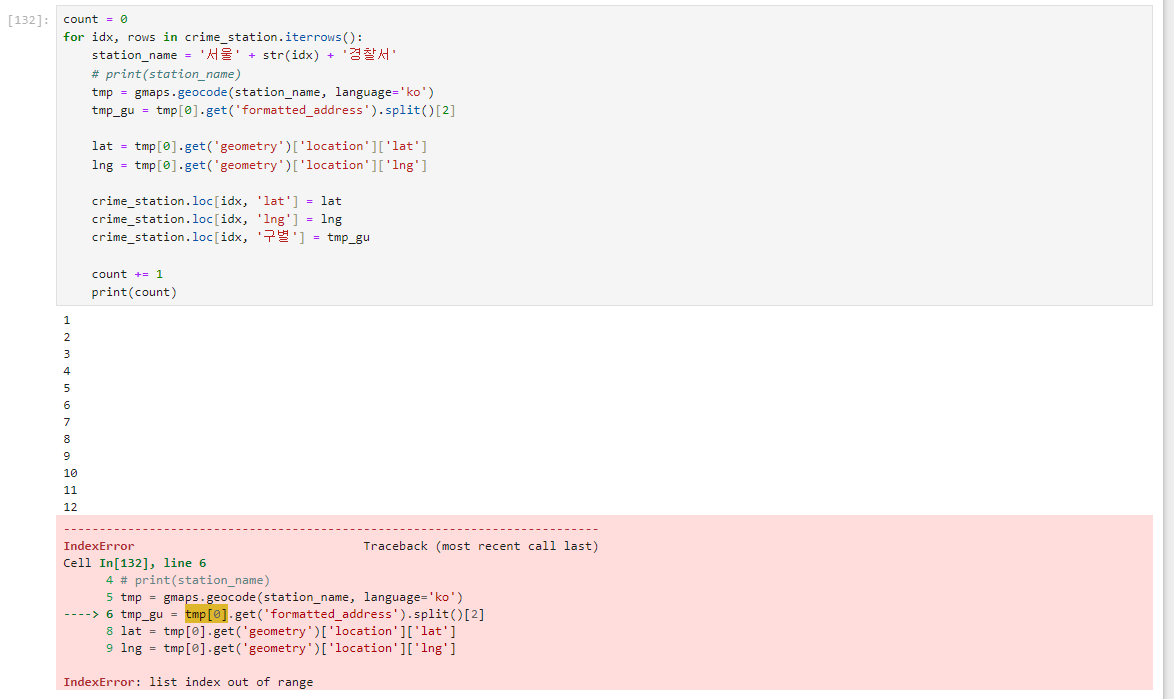
경도 위도 구별 데이터를 불러올때 다음과 같은 오류가 발생하게 되는데 이유는 다양하겠지만 추측을 해보자면 이름 데이터가 업데이트 되서 그렇다고 생각됩니다.
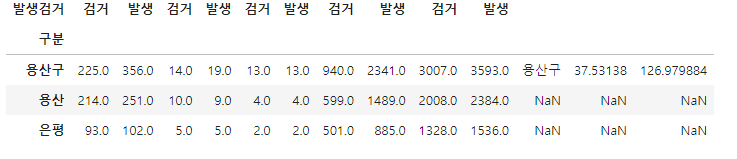
그러니 용산구 라고 되어 있지 않고 용산이라고 되어있어서 용산이라고 되어있는 부분과 동작구 부분인 index 12 23번을 아래 코드와 같이 rename해주면 강의대로 진행할수 있게됩니다.
crime_station.rename(index={crime_station.index[12]: '동작구'})
crime_station.rename(index={crime_station.index[23]: '용산구'})전체 코드
